






代码
https://github.com/NEUIR/ConAE.
论文
https://arxiv.org/pdf/2205.03284.pdf
EMNLP 2022
Abstract
稠密向量的检索器对查询和文档进行编码,并使用预先训练过的语言模型将它们映射到嵌入空间中。这些嵌入需要是高维的,以拟合训练信号,并保证稠密向量检索器的检索有效性。然而,这些高维嵌入会导致更大的索引存储和更高的检索延迟。为了降低密集检索的嵌入维数,本文提出了一种条件自编码器(ConAE)对高维嵌入进行压缩,以保持相同的嵌入分布,更好地恢复排序特征。实验表明,ConAE在压缩嵌入方面是有效的,它实现了与教师模型相当的排名性能,使检索系统的效率提高。ConAE可以缓解仅使用一个线性层的稠密向量检索嵌入的冗余性。
方法
ConAE的尺寸压缩
encoder
首先从现有的密集检索器中获得查询q和文档d的初始表示hq和hd。
然后,这些k维嵌入可以被压缩为具有两个不同的线性层的低维嵌入
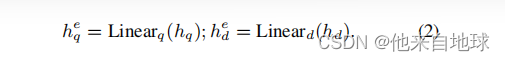
维数L可以是256、128或64,远低于hq和hd的维数K
然后,我们使用KL发散来调节编码嵌入,来模拟查询和文档的初始嵌入分布:
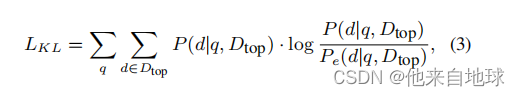
其中,Pe(d|q,Dtop)用压缩的hq计算。
使用编码的嵌入heq和hed。Dtop由排名最高的文档组成,
由教师检索器如Ance搜索。
decoder
解码器解码器模块通过将压缩后的嵌入heq和hed与hq和hd对齐,将编码后的嵌入heq和hed映射到原始的嵌入空间中。它的目的是优化编码器模块,以最大限度地维护来自查询和文档的初始表示hq和hd的排序特征。
首先,我们使用一个线性层将heq和hed投影到k维嵌入,ˆhq和ˆhd:
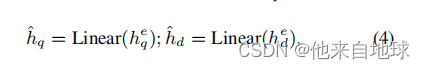
然后,我们分别训练解码后的嵌入数据ˆhq和ˆhd在原始嵌入空间中与hq和hd对齐。在之前的研究中,最大边际损失在以往的研究中被广泛用于优化排名分数
第一个损失Lq用于优化解码的 查询(query)表示ˆhq:
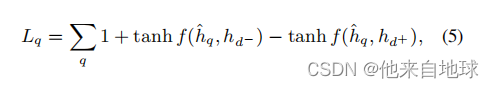
我们还可以用第二个损失函数Ld优化解码的文档(doc)表示ˆhd:
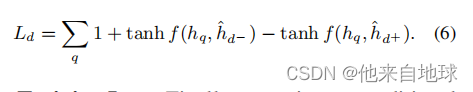
训练损失。最后,我们用以下损失L来训练我们的条件自动编码器模型:
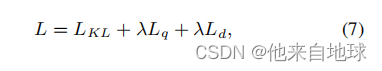
结果
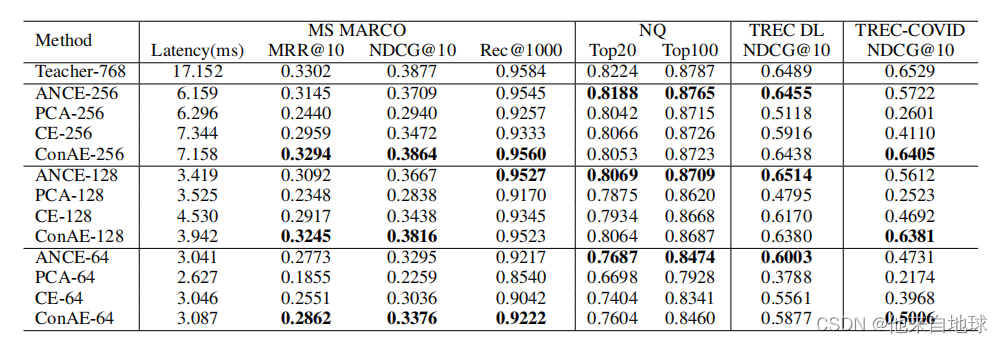 部分数据集取得sota,其中召回数越少提升越明显。速度更慢。
部分数据集取得sota,其中召回数越少提升越明显。速度更慢。
分析
使用降维方法提高效果是本文出发点,但本文通过将维度拉低再拉高的简单操作就能提高模型效果,出乎我的意料。















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









