







找遍全网无奈只能自己开发某博热点评论数据爬取与用户情感分析平台,这就是技术人的创新!
最近想看一下微博热点评论的用户人群情感趋势,想到的就是去爬取某博的评论数据,然后进行一个可视化的情感分析。想想吧,这个项目肯定网上一大堆,然后呢,自己去搜索,可把我气的。Github和csdn居然没有一个能够参考的好项目,不是拉下来跑不了。就是一些过时的程序,早都被反爬了。这可把我气的,花了两天时间自己研究琢磨了一个平台。现在免费提供给大家,希望大家多多收藏。相信我,你以后一定会用到的!
前言
为了能让小白能够看懂我先来介绍一下我使用到的一些技术
- 前端为layui和echart
- 后端为python flask框架
- MYSQL数据库
- 情感分析NLP
- 爬虫技术
一、layui介绍
Layui是一个基于Web界面的前端UI框架,提供了丰富的组件和接口,并且易于使用和定制。它被广泛应用于Web开发项目中,可以帮助开发者快速搭建出美观、高效的用户界面。Layui采用了模块化的设计方式,使得开发者可以根据需要选择需要的组件,同时也可以方便的自定义扩展组件。它的主要特点包括简洁、易用、减少样式冲突、响应式设计。
二、echart介绍
Echart是一种用于数据可视化的JavaScript图表库,它支持多种图表类型,如折线图、柱状图、饼图、散点图等,并且具有动态交互性和可定制性。Echart可以通过简单的JavaScript代码来实现丰富的数据可视化效果,适用于不同领域的数据分析与展示。
三、开发过程
3.1 后端设计
3.1.1 使用flask web框架快速搭建
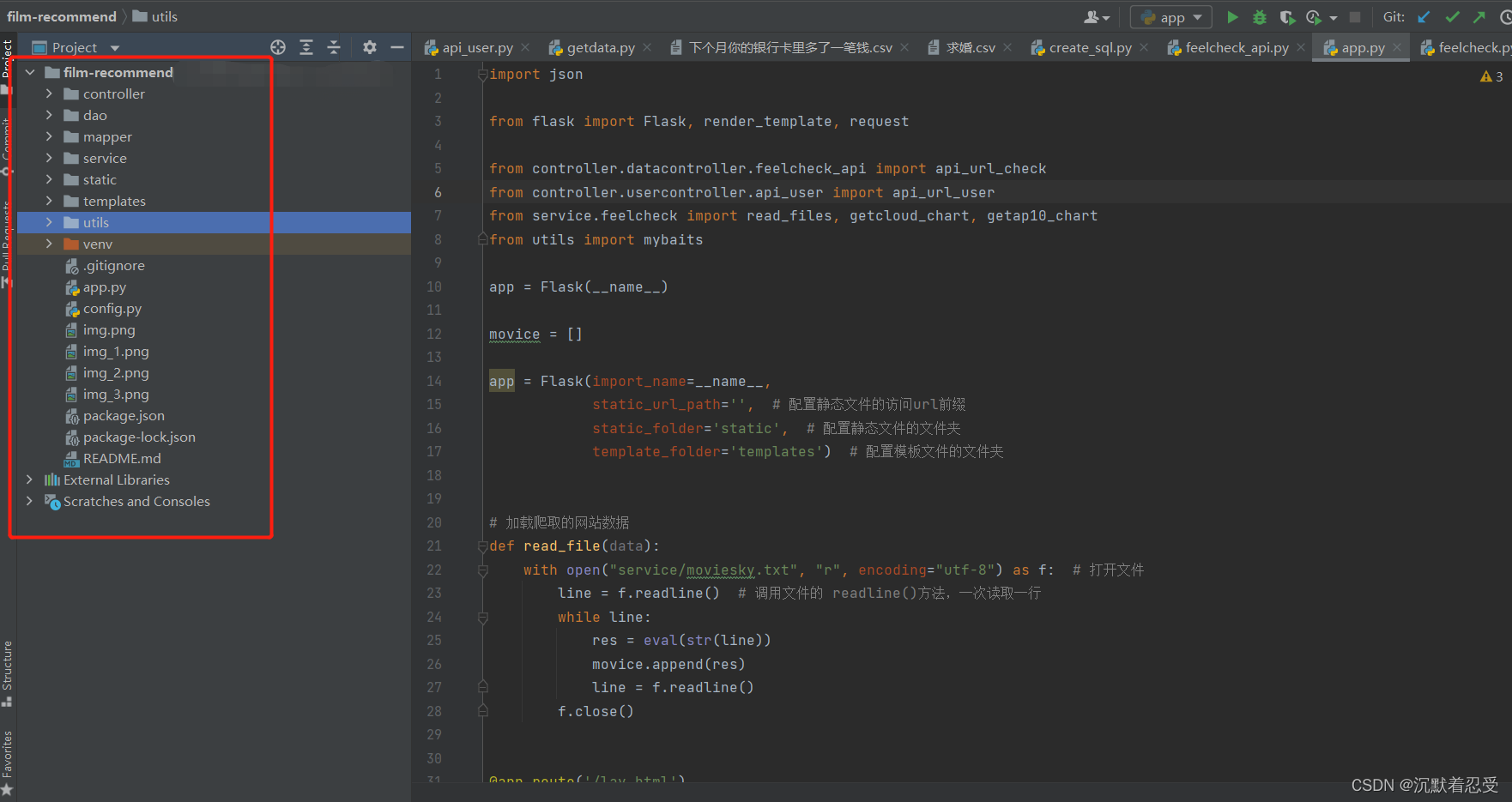
- Controller里面是和前端交互的API。
- Dao里面是与数据库连接的映射接口实体
- Mapper里面是与数据库连接的接口
- Service里面实现爬虫数据逻辑
- Static里面存放静态资源数据
- Templates存放前端HTML文件里面集成了类UI
- Utils是我自己分装的一些工具实体,里面有一些词云生成器和数据库脚本一键生成工具。数据库脚本一键生成工具,下期我再介绍。
先看效果图:
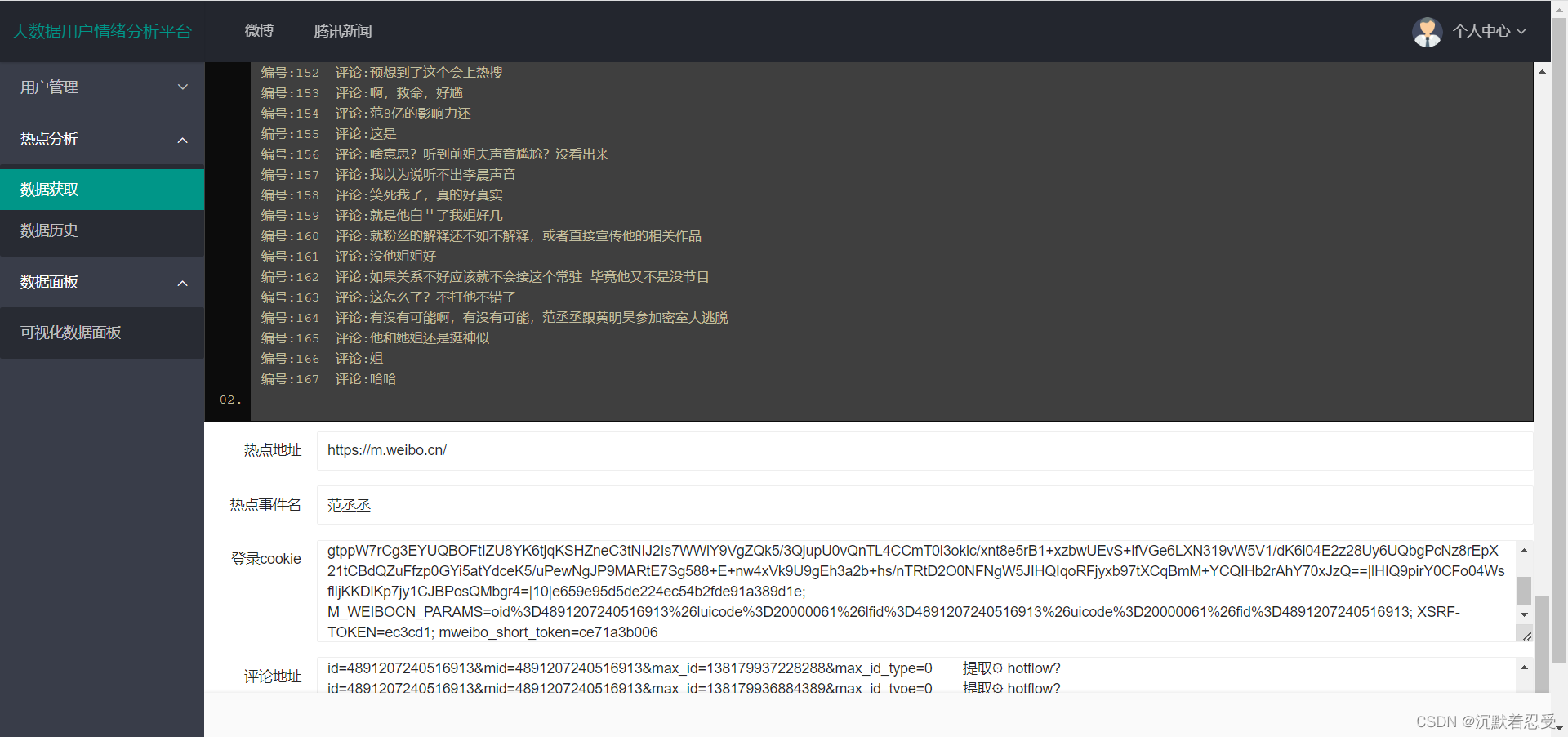
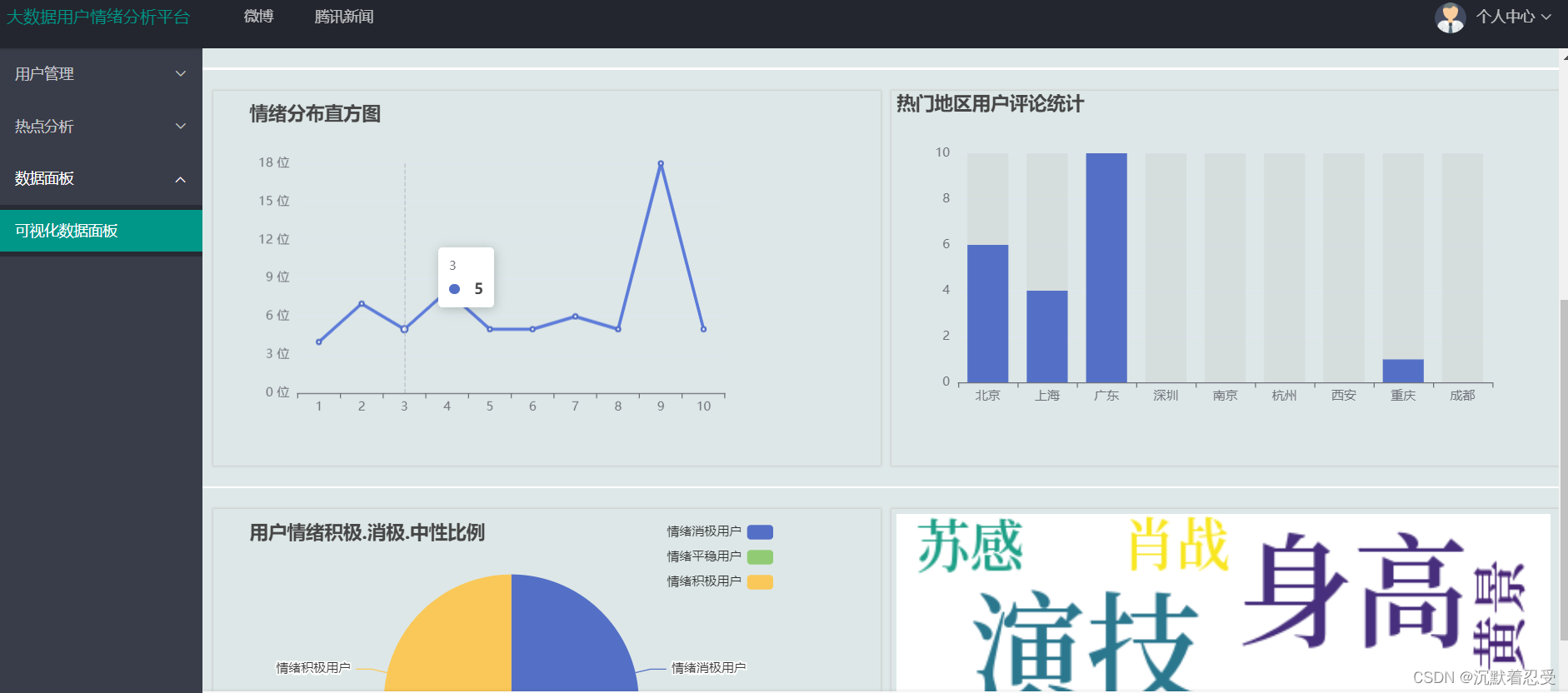
3.1.2 某博热点数据爬取
爬取思路,大神勿喷:
3.1.2.1 登录某博网页
登录地址为:微博地址
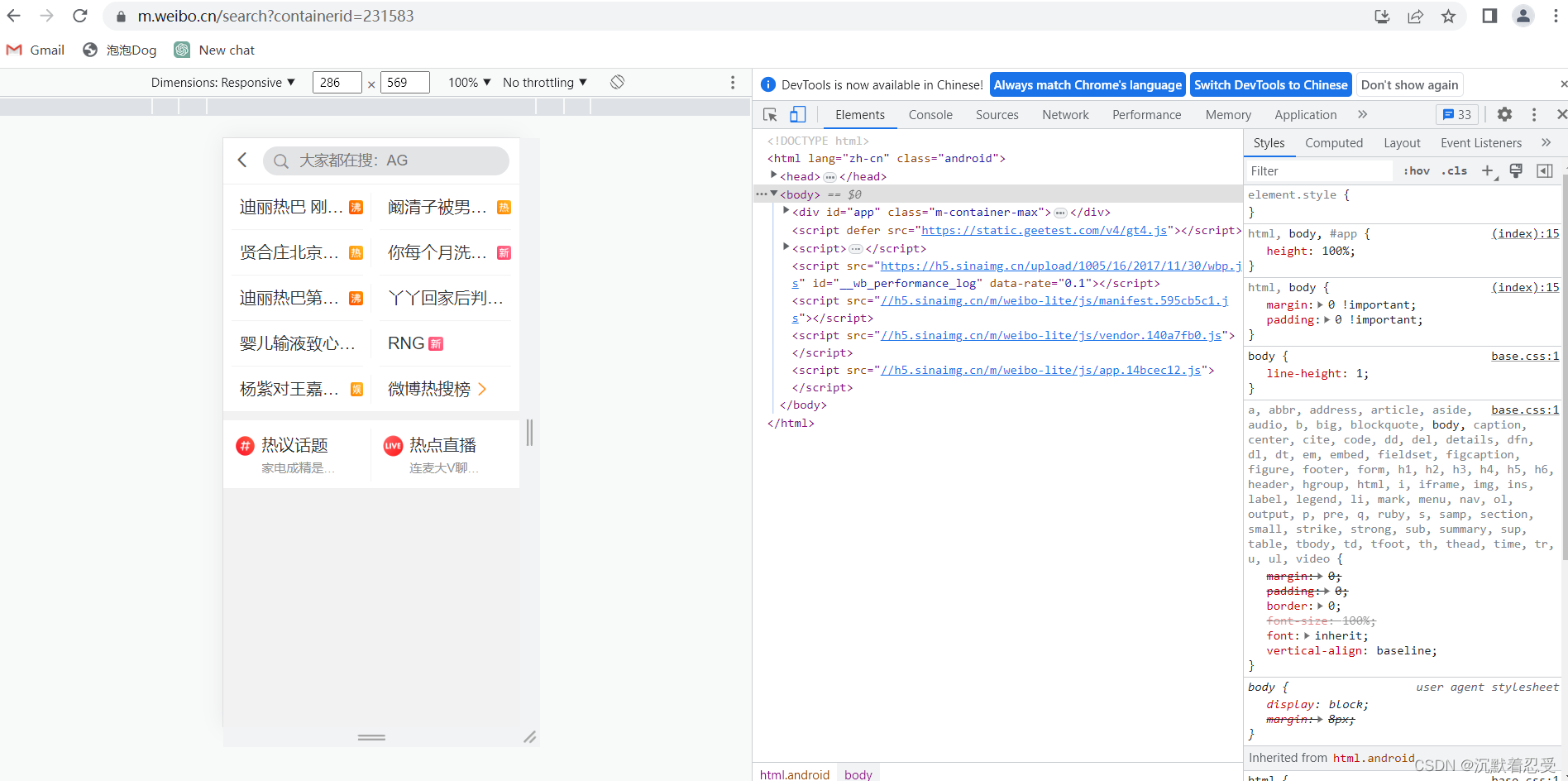
如果没有登录记得登录,登录成功后进入微博的H5页面。
3.1.2.2 点击进入你要爬取的热点事件
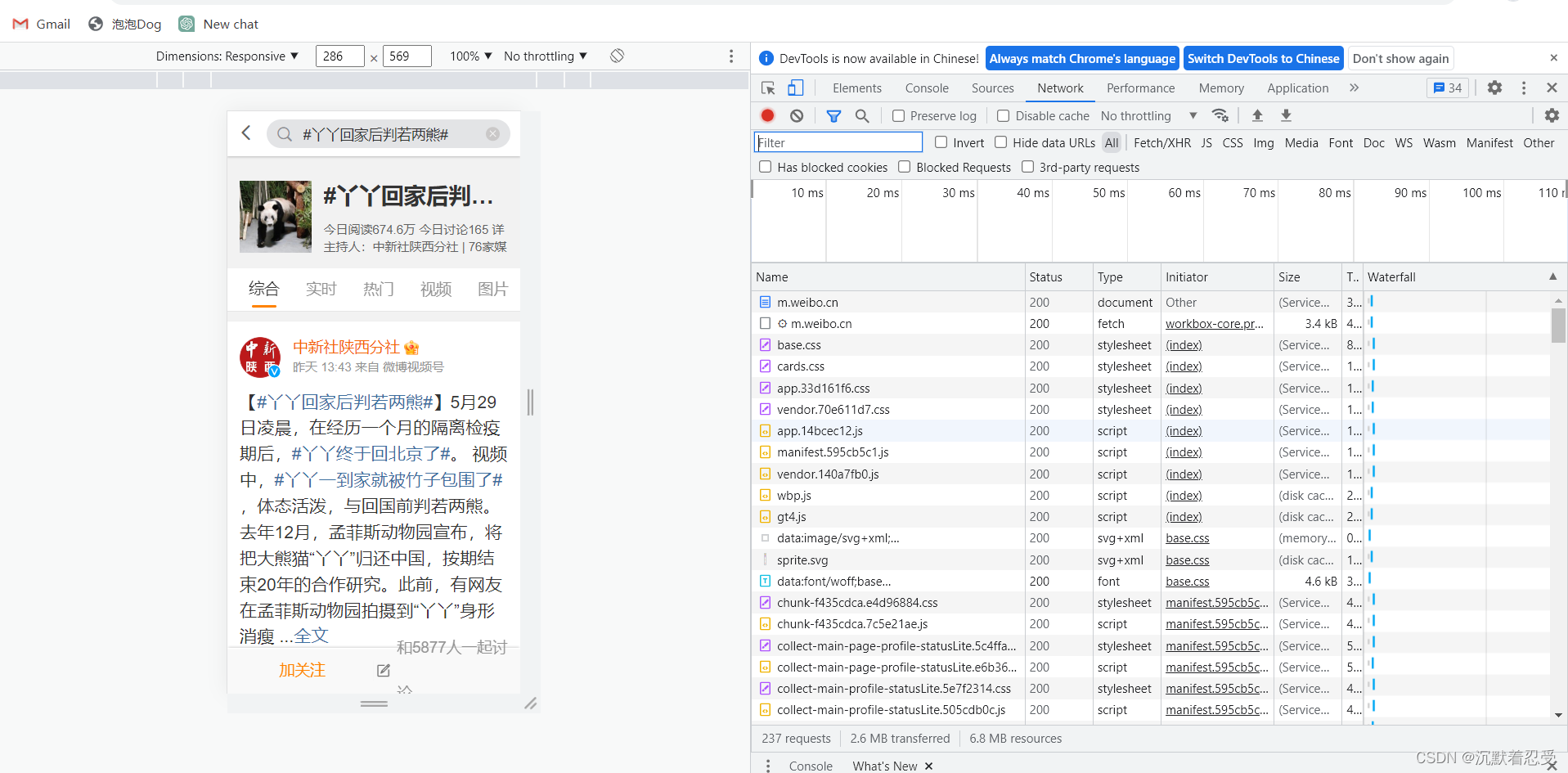
- 要注意现在需要获取一下网站的cookie
- 获取方式为如下:
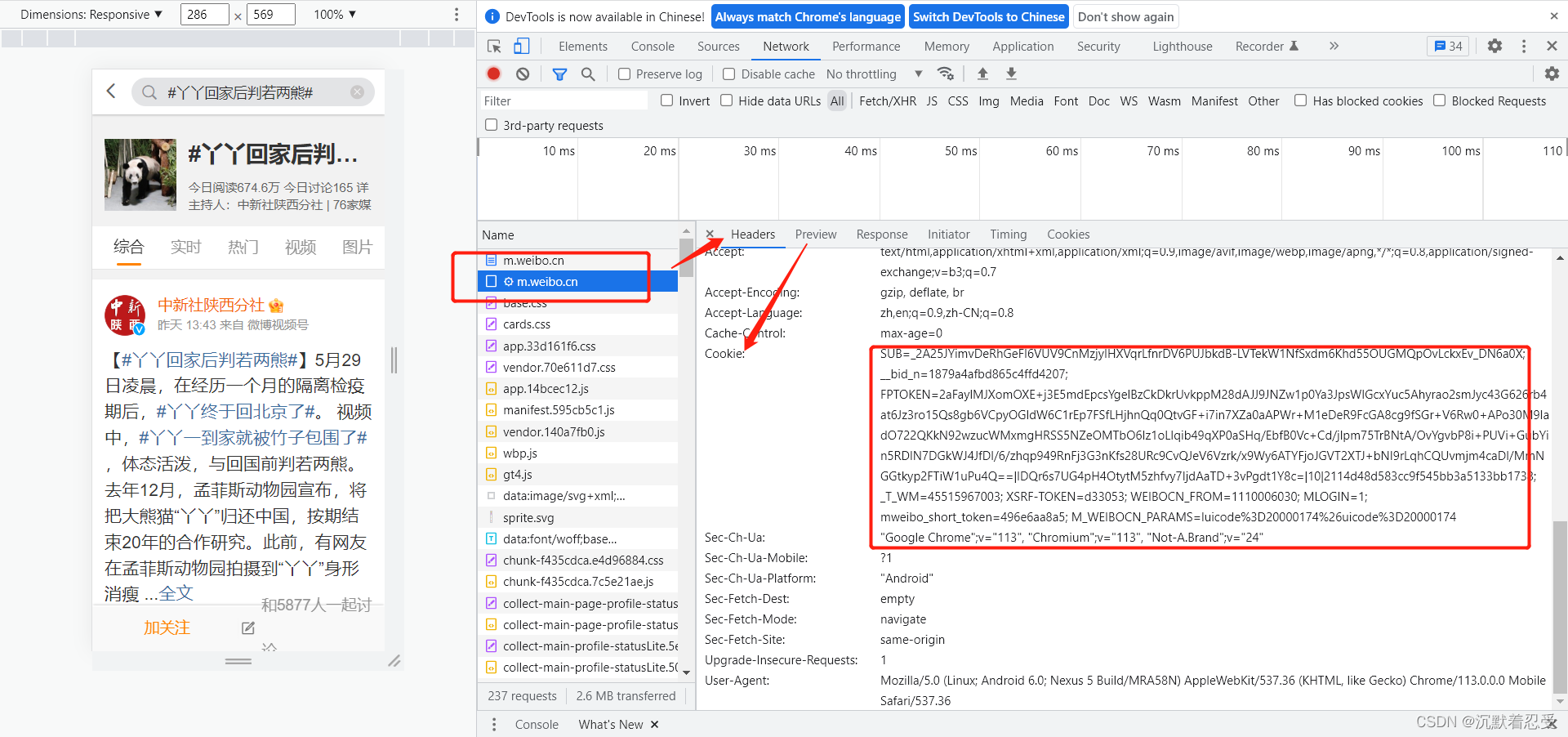
3.1.2.3 点击进入你要爬取的评论目标
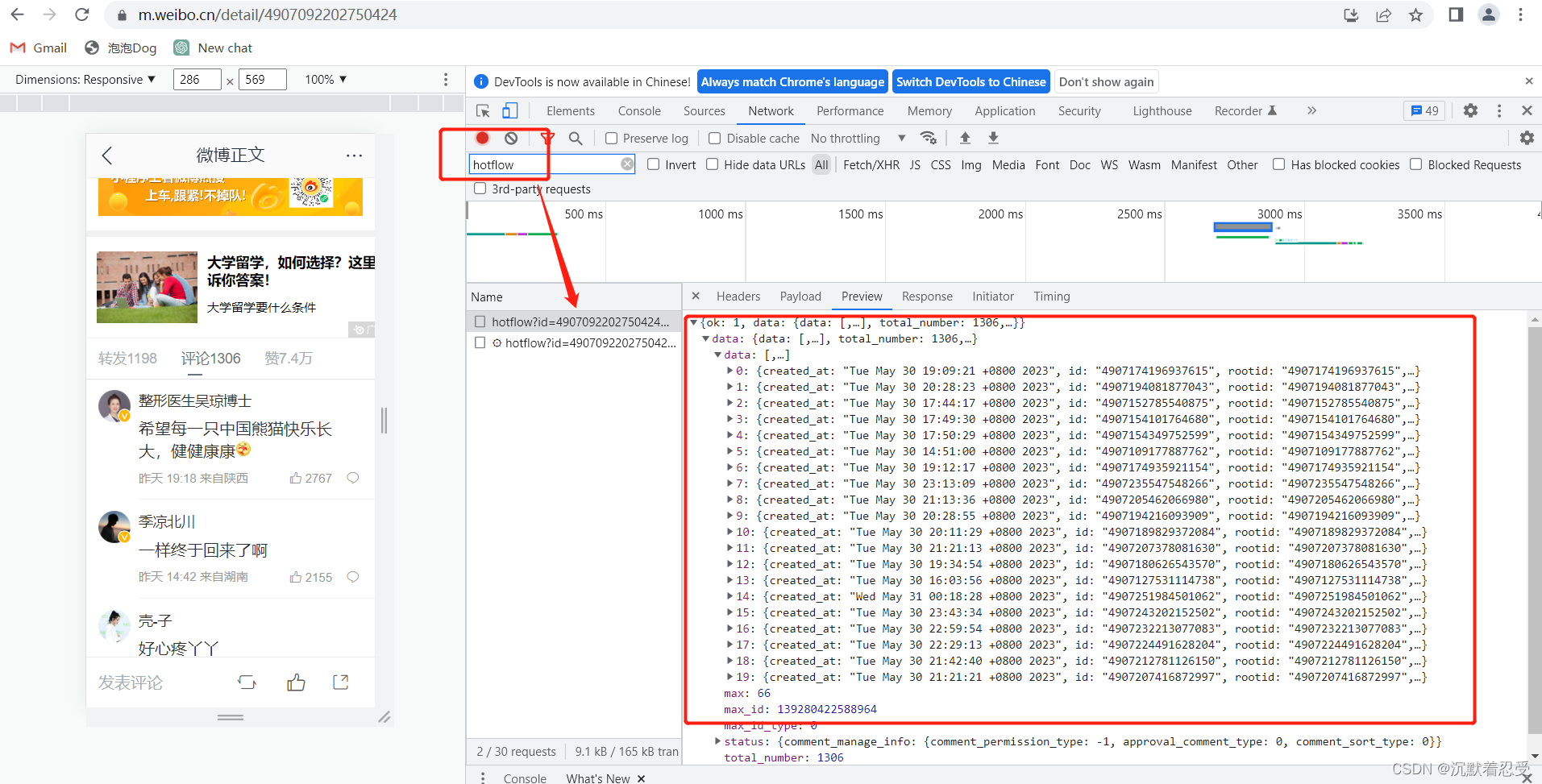
评论链接:评论链接
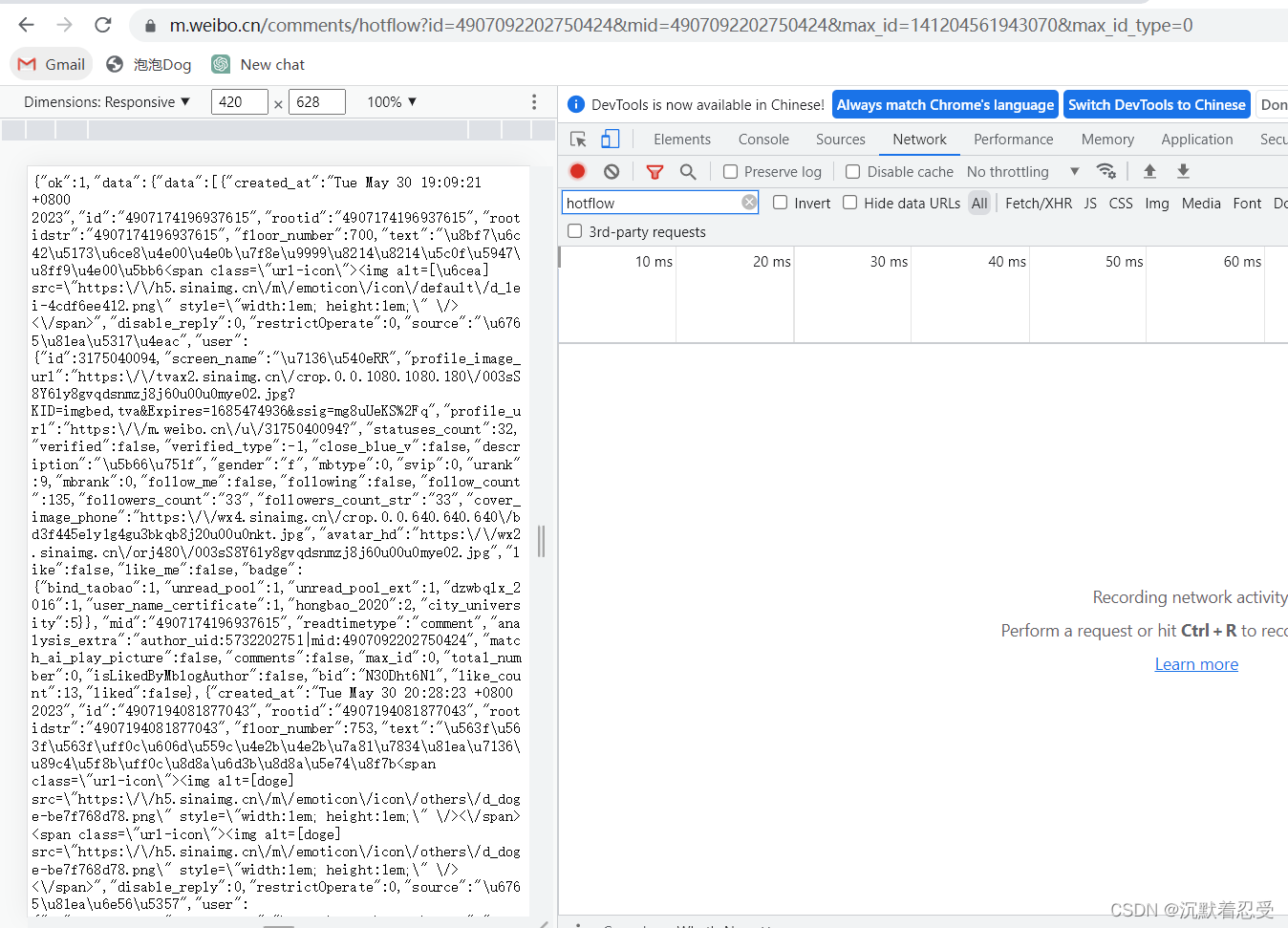
有个恶心的问题是爬取这个链接根本不是固定的,需要我们自己手动翻页收集,这里应该是人家的反扒策略。
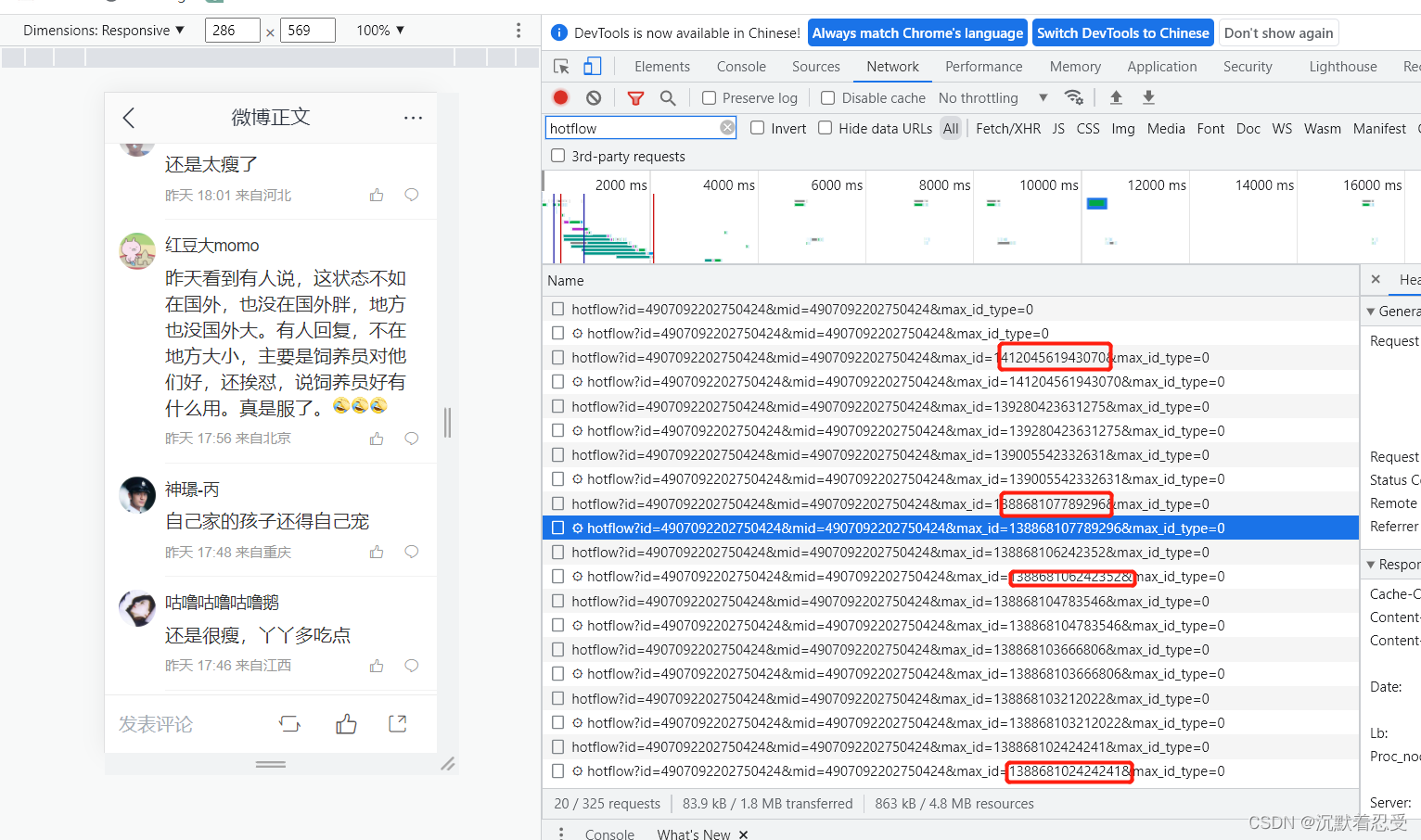
所以我只能将所有链接复制填写到输入框中进行遍历。遍历时要进行字符串处理
# 识别多页评论数据
def get_readUrl(data_url):
data = data_url
data_goods = []
str_data = data.split("hotflow")
for k in str_data:
if len(k) > 10:
data = k[:78]
print(data)
data_goods.append(data)
return data_goods
3.1.2.4 抓取评论url并且获取cookie
代码如下:
# 爬取微博热点评论
# 获取当前热搜信息
import json
import time
import requests
from service.feelcheck import write
# 获取某个信息
def get_data(hot_band_url, data_goods, cookie, name):
mydata_pa = []
headers = {
'user_agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/112.0.0.0 Safari/537.36 Edg/112.0.1722.39',
'cookie': cookie,
'Accept': 'application/json, text/plain, */*'
}
id = 0
try:
for k in data_goods:
print(hot_band_url + k)
data = requests.get(hot_band_url + k, headers=headers) # 请求
# time.sleep(1) # 防止被监控
data = data.json()
data = data['data']['data']
for k in data:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 546
546











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











