






前言
本次分享的爬虫案例,目标是获取一个动漫网站各个项目的评论信息,涉及到js逆向,MD5加密。
一、目标
这次爬虫目标url是:** https://zhongchou.modian.com/all/top_time/all/**
获取上述页面每个动漫项目的标题,及进入详情页后的第一条评论信息,评论人用户名,并输出。
二、关键思路分析
-
从进入主url,查看网络源代码,
可以发现主页面是一个静态网页,每个动漫项目的标题,详情页对应url可以轻松获取。 -
进入第一个详情页url,并点击评论信息,通过查看网络源代码,ctrl+f 搜索不到相关评论信息,即评论信息是通过异步加载得到的。
-
F12 打开浏览器抓包根据,点击netword,刷新网页抓包,逐个包分析返回信息,发现如下图的包返回评论信息。
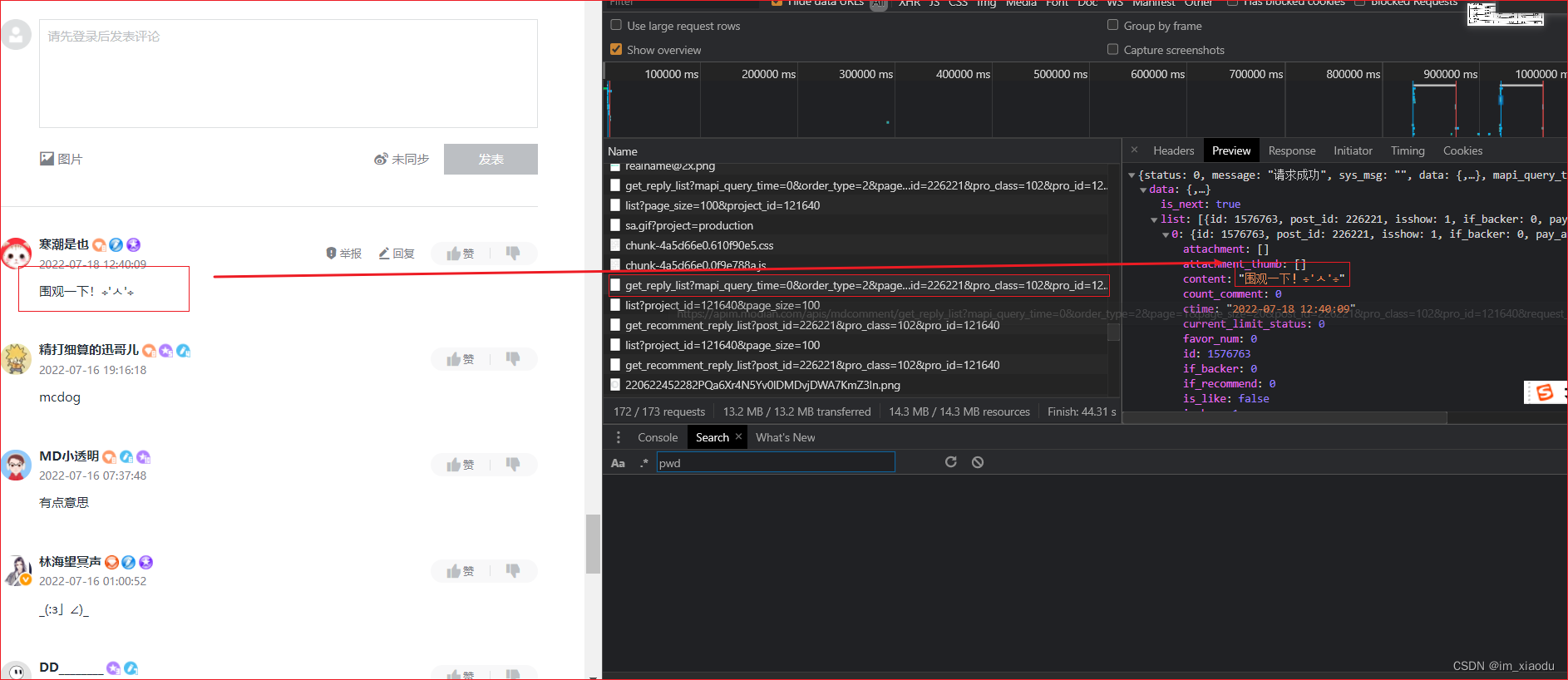
-
即分析上述返回评论信息的包
4.1 请求参数如下:
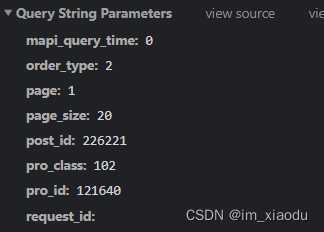
通过对比不同的动漫项目的请求参数,可以知道只有pro_id,post_id是不同的,page与page_size 代表页码和每页评论数量,其余参数固定。
pro_id及post_id很容易找到,它们对应于不同的动漫项目,可以在不同动漫项目详情页的网页源代码中解析得到。
4.2 请求头参数分析:
请求头参数很多,这里就没有截图,但通过多次刷新对比,并在python程序测试,中间只有两个参数变化,分别是:
mt: 1658148613;
sign: c3500d1d032d14b935a32766ff0bfcc6;
mt是一个时间戳,sigh长度32位其实就可以猜测md5加密了。
4.3 逆向sigh参数
点击initiator逐个分析该请求的调用栈,在下图第三个调用栈发现发送了ajax请求
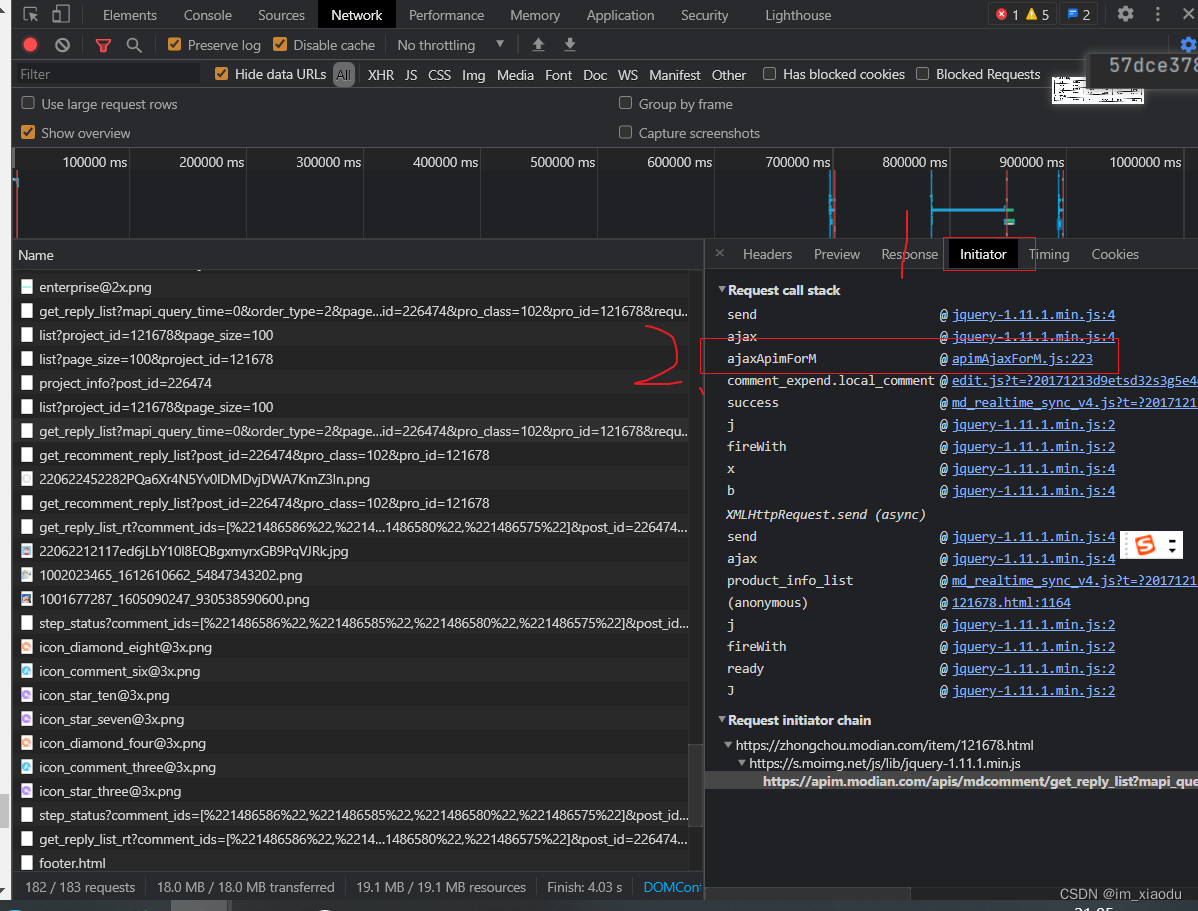
下图是第三个调用栈截图:打下断点进行调试得到如下图
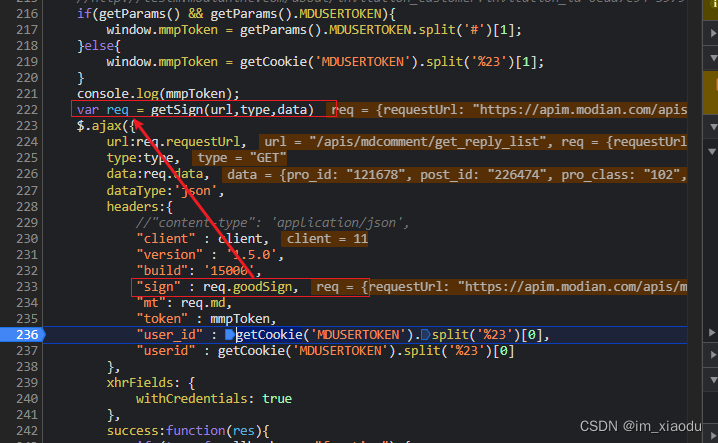
通过上述js代码,可以发现sign的值由req对象的goodsign属性得到,而定义req的语句就在上方,为getsigh函数,进入getsigh。如下图是getsigh函数部分代码截图
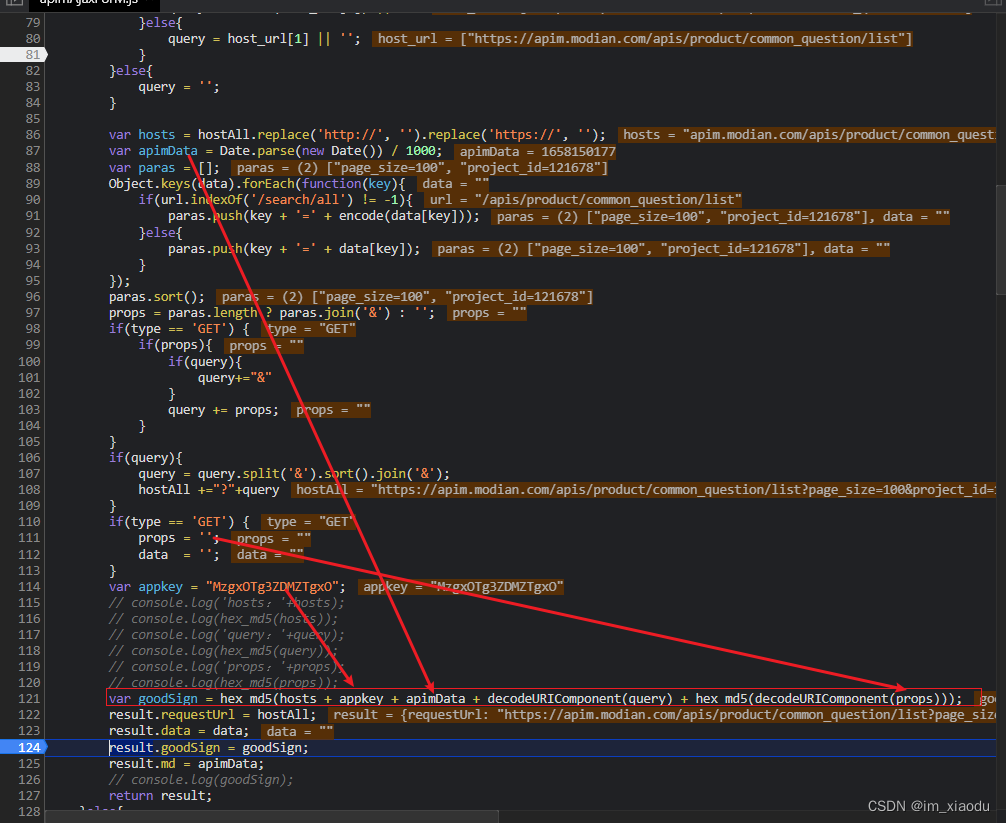
可以发现 sigh 确实是md5 加密,且MD5需要的host ,appkey,props均为固定,apimdate为13位时间戳,query为4.1节请求参数按键排序拼接得到的如下字符串:“mapi_query_time=0&order_type=2&page=1&page_size=20&post_id=226221&pro_class=102&pro_id=121640&request_id=” -
故此所有请求参数分析完毕,编写爬虫代码
完整代码
import requests
from lxml import etree
from hashlib import md5
import time
import math
import os
import csv
# 获得网页源代码
def get_res(url):
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/95.0.4638.69 Safari/537.36'
}
resp = requests.get(url, headers=headers)
resp.encoding = 'utf-8'
return resp.text
# md5加密
def get_miwen_md5(minwen):
obj = md5()
obj.update(minwen.encode("utf-8"))
miwen = obj.hexdigest()
return miwen
# 获得sigh
def get_sign(t, p):
k = "MzgxOTg3ZDMZTgxO"
h = "apim.modian.com/apis/mdcomment/get_reply_list"
q = ''
return get_miwen_md5(h+k+str(t)+p+get_miwen_md5(q))
# 解析详情页,获得pro_id及post_id
def parse_id(detail_url):
res = get_res(detail_url)
tree = etree.HTML(res)
post_id = tree.xpath('//input[@name="post_id"]/@value')[0]
pro_id = tree.xpath('//span[@id="common_comment_count"]/@comment_count')[0]
return post_id, pro_id
# 得到评论信息
def get_comment(post_id, pro_id):
t = int(time.time())
params = {
'mapi_query_time': 0,
'order_type': 2,
'page': 1,
'page_size': 20,
'post_id': post_id,
'pro_class': '101',
'pro_id': pro_id,
'request_id': '',
}
query = '&'.join(['{}={}'.format(x[0], x[1]) for x in sorted(params.items(), key=lambda e: e[0], reverse=False)])
headers2 = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/95.0.4638.69 Safari/537.36',
'mt': str(t),
'sign': str(get_sign(t, query)),
}
comment_url = 'https://apim.modian.com/apis/mdcomment/get_reply_list'
comment_dic = requests.get(url=comment_url, headers=headers2, params=params).json()
# print(comment_dic)
com_list1 = comment_dic['data']['list'][0]
nickname = com_list1['user_info']['nickname']
comment = com_list1['content']
return nickname, comment
# 运行主函数
def main():
url = 'https://zhongchou.modian.com/all/top_time/all'
page_text = get_res(url)
tree = etree.HTML(page_text)
li_list = tree.xpath('//ul[@class="pro_ul clearfix"]/li')
for li in li_list:
href = li.xpath('./a/@href')[0]
name = li.xpath('./div/a/h3/text()')[0]
post_id, pro_id = parse_id(href)
# print(post_id, pro_id)
nickname, comment = get_comment(post_id, pro_id)
print("动漫项目名称:{},第一个评论用户名:{},评论内容:{}".format(name, nickname, comment))
if __name__ == '__main__':
main()
效果

补充
大家还自行完善代码,比如多爬取写字段,翻页,子评论,数据库存储等等。















 1017
1017











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









