






Python爬虫:唯美girl,charles解决反调试
Python爬虫:唯美girl,不让F12,我就要!
前言
夜黑风高夜,寂寞的我打开了唯美女生,打算下载些高清的美女图片度过寂寞难耐的夜晚。
1.目标简要说明
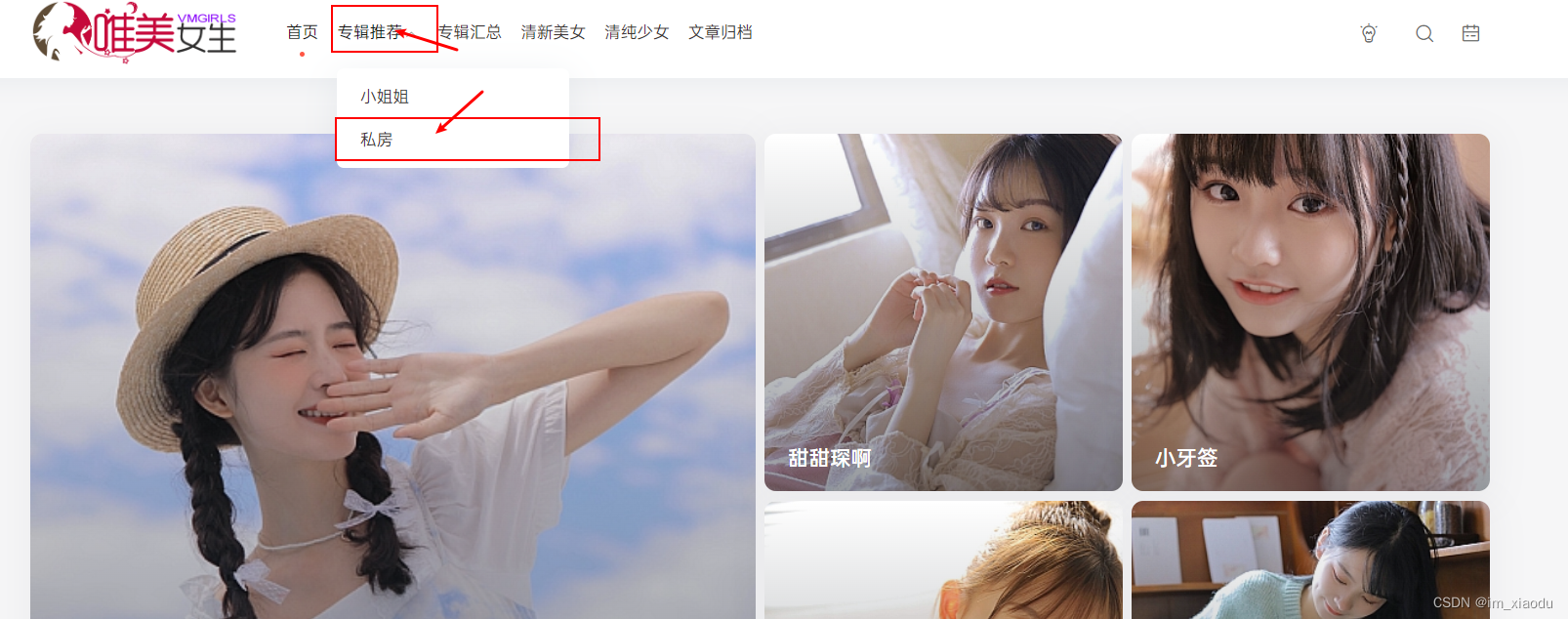
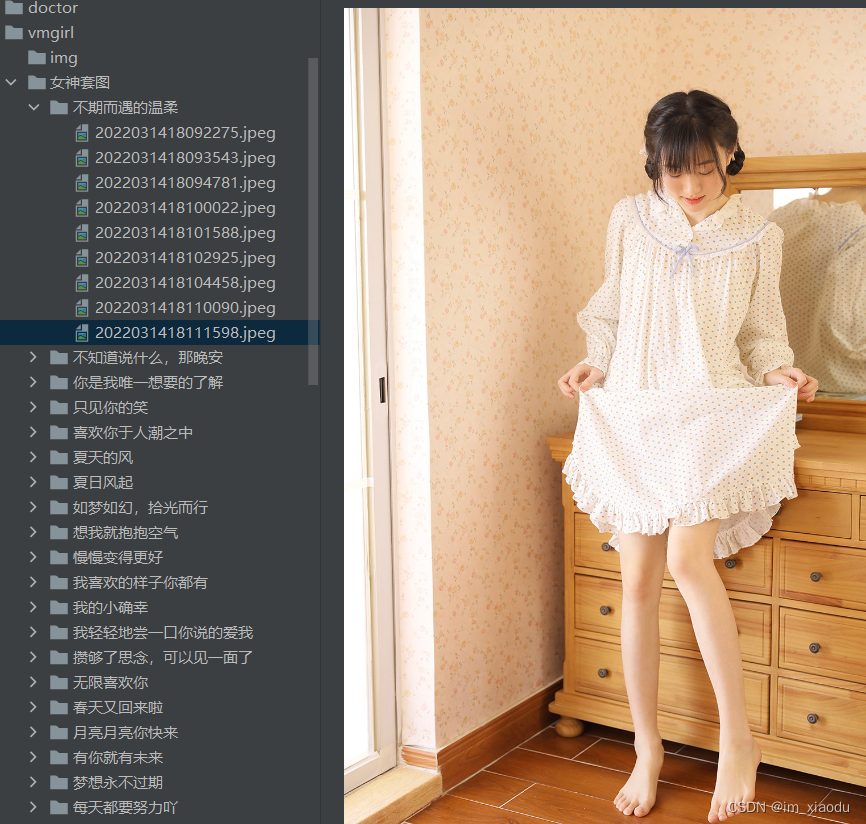
没错,此次的目标就是唯美女生,如下图抓取里面的子页面的漂亮小姐姐的图片。
2.解决无法打开浏览器开发者工具
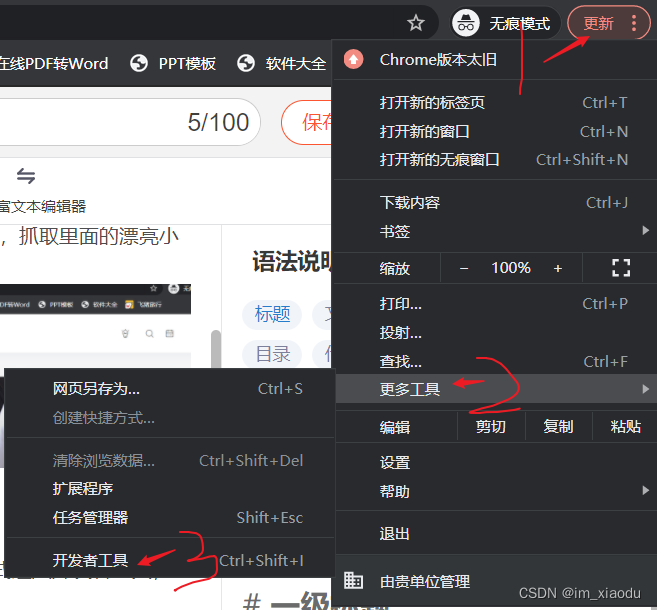
进入目标网页,发现右键没反应,狂击F12也没用,利用如下图片的方式进入开发者工具,也会直接闪退。这不让我看网页源代码,该如何抓取?
2.1解决思路
- 利用charles抓包,如下图可看到网页源代码
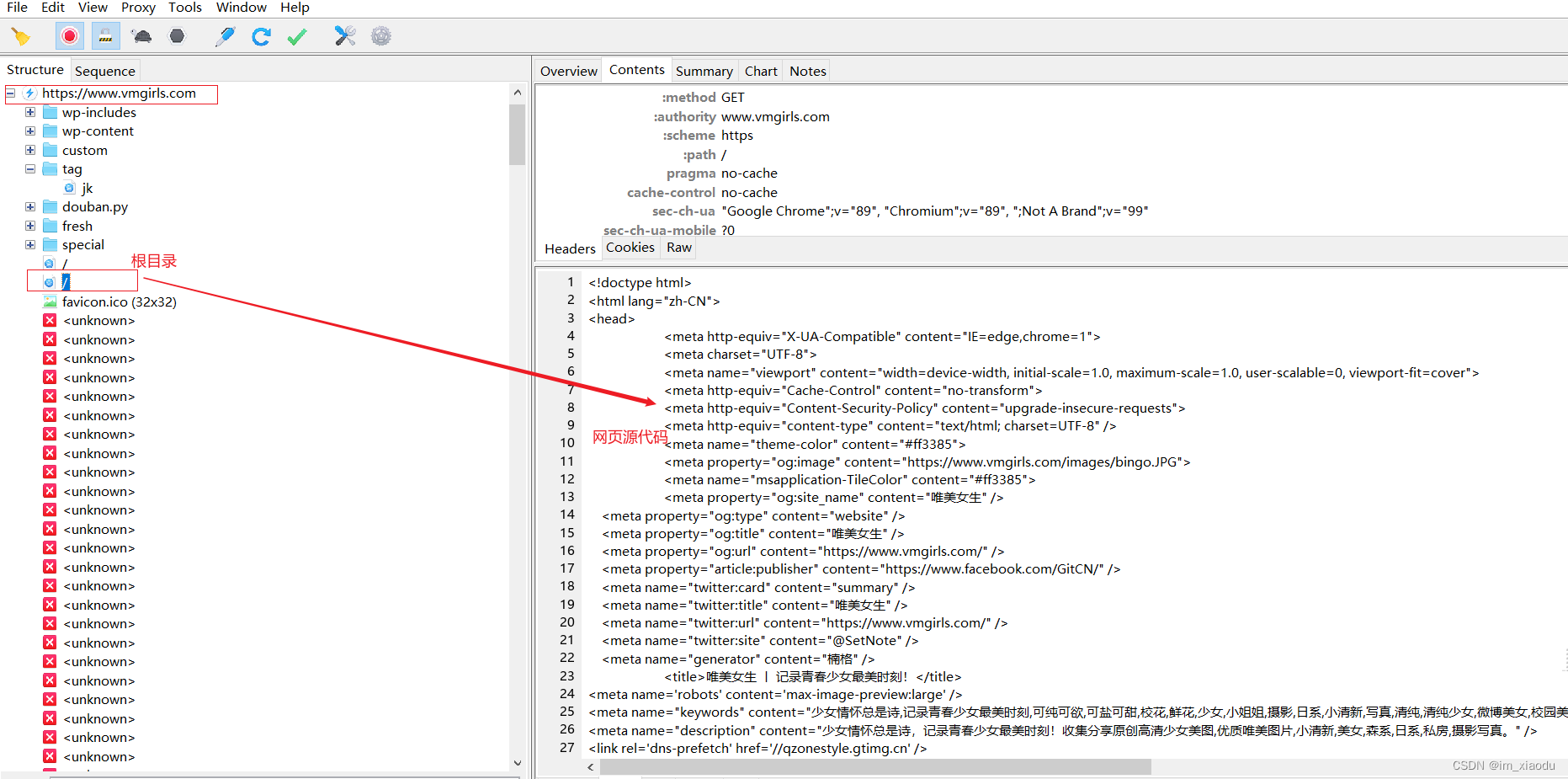
- 为便于观察代码,分析何种原因不让我们使用开发者工具,在pycharm内创建一个html文件,将返回得到的网页源代码复制进该文件。仔细检查网页源代码,如下图的一行代码十分可疑。

原因是:英文devtool 代表浏览器开发者工具,disable-devtool就代表不让使用浏览器开发者工具,故如果将上面截图src中的服务端返回的disable-devtool-js文件替换我们本地的一个空的js文件,再交给浏览器,是不是就可以调试了,故开始尝试。
2.2思路具体实现
- 在本地创建一个空的js文件,我这放在桌面,命名为 vmgirl.js
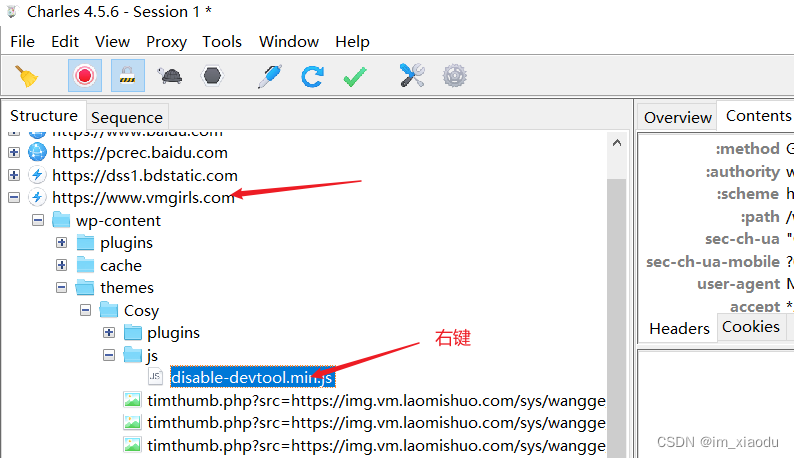
- 打开charles进行抓包,找到
https://www.vmgirls.com/域名下的disable-devtool-js请求,并右键。如下图
- 在右键弹出的菜单,点击
Map Local
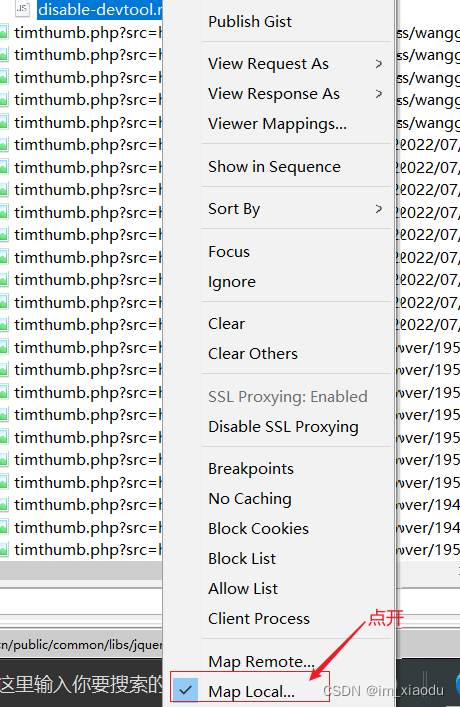
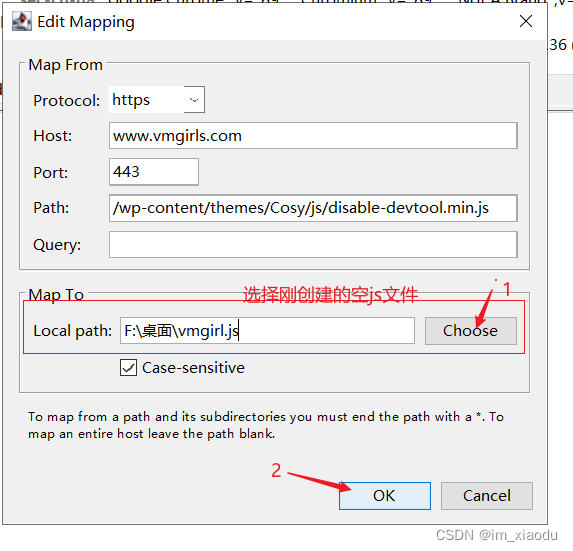
- 在弹出的
Edit Mapping窗口,配置下图红色框内的内容,其余的信息默认填好,并点击ok。
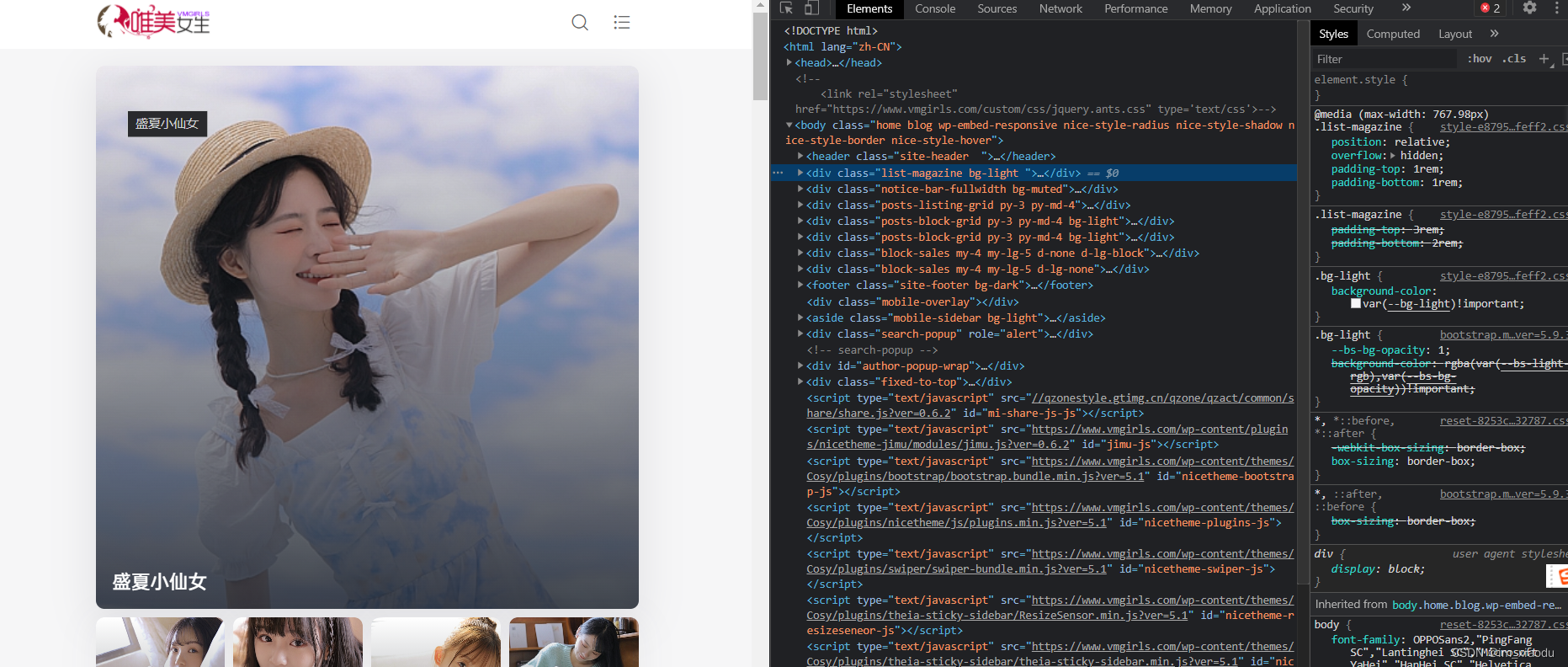
- 故此尝试打开浏览器开发者工具,如下图,成功!!
3. 爬取私房图片
目标网址:唯美女生私房图片
目标网址可翻页,包含30的页面,url规律为:只要改变如下方的红色page就可
https://www.vmgirls.com/special/littlesex/page/page/
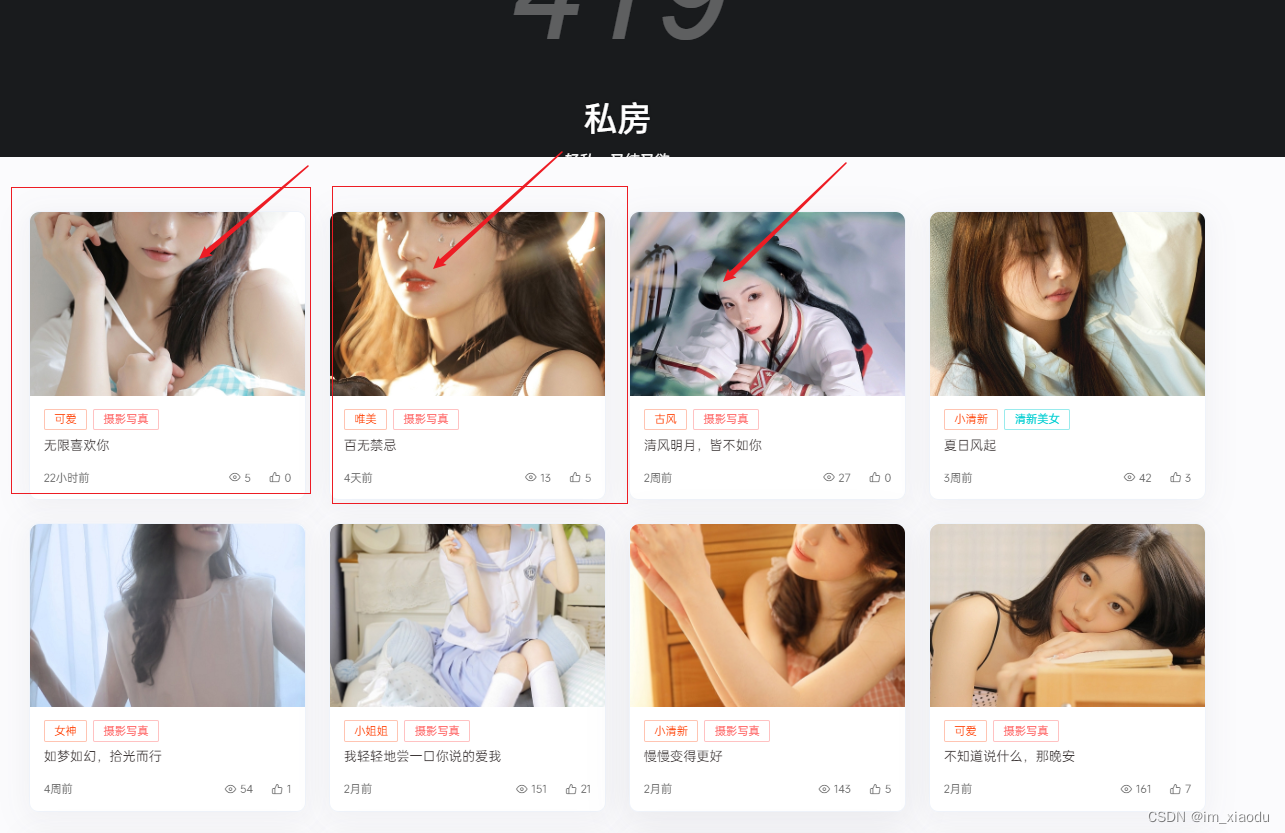
点击上图中红框进入详情页,可以发现每个详情页内展示了多张图片,下载图片耗时,故考虑多线程处理,每一个详情页下载的图片作为线程的一个任务。
故思路就可确定:
- 解析得到所有详情页url
- 在每一个详情页url下载图片
3.1 解析得到所有页面的详情页
# 得到某一页内所有详情页的url
# 输入参数:为某一页的url
# 返回参数:为该页所有详情页url的一个列表
def get_one_page_detail_url(url):
pagetext1 = get_res(url)
tree1 = etree.HTML(pagetext1)
href_list = tree1.xpath('//main[@class="site-main h-v-75"]/div[@class="container"]/div[1]/div[not(@id)]//a[@class="media-content"]/@href')
return href_list
all_detailurl = [] #存放各个详情页url列表
for page in range(1, 3):
url = f'https://www.vmgirls.com/special/littlesex/page/{page}/'
# 得到某一页的详情页url
href_list = get_one_page_detail_url(url)
# 将不同页的详情页url放到一个列表中
all_detailurl += href_list
3.2 下载某一详情页的图片
# 输入参数:某一个详情页url
def download_img(href):
# 得到详情页页面源代码
pagetext2 = get_res(href)
tree2 = etree.HTML(pagetext2)
# 解析得到详情页图片链接列表
img_src_list = tree2.xpath('//div[@class="nc-light-gallery"]/a/img/@src')
# 解析得到详情页图片写真的名称,用于创建文件夹,作为文件夹名称
name = tree2.xpath('//h1[@class="post-title mb-3"]/text()')[0]
# 创建文件夹,存放图片
os.mkdir(r'./女神套图/{}'.format(name))
for img_src in img_src_list:
# 图片链接结尾当做图片的名称
img_name = img_src.split('/')[-1]
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/95.0.4638.69 Safari/537.36'
}
# 下载图片
img_data = requests.get(url=img_src, headers=headers, verify=False).content
# 存放图片
with open(r'./女神套图/{}/{}'.format(name, img_name), 'wb') as f:
f.write(img_data)
# print(f'成功下载图片:{img_name}')
print('成功下载:女神套图/{}!!'.format(name))
3.3 完整代码
import requests
from lxml import etree
import os
import time
from concurrent.futures import ThreadPoolExecutor
## 忽略verify=False导致控制台输出的警告
requests.packages.urllib3.disable_warnings()
# 多次获取网页源代码,故封装成函数,方便写代码
def get_res(url):
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/95.0.4638.69 Safari/537.36'
}
resp = requests.get(url, headers=headers, verify=False)
resp.encoding = 'utf-8'
return resp.text
# 得到某一页内所有详情页的url
# 输入参数:为某一页的url
# 返回参数:为该页所有详情页url的一个列表
def get_one_page_detail_url(url):
pagetext1 = get_res(url)
tree1 = etree.HTML(pagetext1)
href_list = tree1.xpath('//main[@class="site-main h-v-75"]/div[@class="container"]/div[1]/div[not(@id)]//a[@class="media-content"]/@href')
return href_list
# 输入参数:某一个详情页url
def download_img(href):
# 得到详情页页面源代码
pagetext2 = get_res(href)
tree2 = etree.HTML(pagetext2)
# 解析得到详情页图片链接列表
img_src_list = tree2.xpath('//div[@class="nc-light-gallery"]/a/img/@src')
# 解析得到详情页图片写真的名称,用于创建文件夹,作为文件夹名称
name = tree2.xpath('//h1[@class="post-title mb-3"]/text()')[0]
# 创建文件夹,存放图片
os.mkdir(r'./女神套图/{}'.format(name))
for img_src in img_src_list:
# 图片链接结尾当做图片的名称
img_name = img_src.split('/')[-1]
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/95.0.4638.69 Safari/537.36'
}
# 下载图片
img_data = requests.get(url=img_src, headers=headers, verify=False).content
# 存放图片
with open(r'./女神套图/{}/{}'.format(name, img_name), 'wb') as f:
f.write(img_data)
# print(f'成功下载图片:{img_name}')
print('成功下载:女神套图/{}!!'.format(name))
def main():
#计算程序花费时间
starttime = time.time()
all_detailurl = [] #存放各个详情页url列表
# 翻页处理
for page in range(1, 3):
url = f'https://www.vmgirls.com/special/littlesex/page/{page}/'
# 得到某一页的详情页url
href_list = get_one_page_detail_url(url)
# 将不同页的详情页url放到一个列表中
all_detailurl += href_list
print(len(all_detailurl))
# 下载图片费时,每一个详情页url作为一个任务交给线程池分配
with ThreadPoolExecutor(10) as t:
# 会将all_detailurl内的每一个url传递给download_img处理
t.map(download_img, all_detailurl)
endtime = time.time()
print('花费时间{}'.format(starttime-endtime))
# print(pagetext1)
if __name__ == '__main__':
main()
效果
最后保存的数据格式就是:
女神套图
---- 写真名称
------- 图片
------- 图片
------- 图片
---- 写真名称
---- 写真名称














 696
696











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









