






2016年,SDCC·中国软件开发者大会相继走进了上海、深圳、成都、杭州各地。11月18日-20日将在北京完美收官,届时年度最受欢迎的企业、讲师将在这里齐聚一堂,约百位讲师将围绕电商架构、编程语言、前端开发、微信开发、视频直播、推荐算法、Spark实践等方面,总结分享过去一年感触最深、最具参考价值的实践探索,并畅想未来,把脉市场发展先机,是软件开发者、广大互联网人士及行业相关人士最具价值的交流平台。
双十一火爆来袭,不管是销售战绩还是用户体验,这次全民购物狂潮注定会再次刷新过去的所有记录。而在狂欢背后,需要稳定高效的数据平台系统来提供有力支持。为此,我们在11月18日-20日中国软件开发者大会上开设了基于Spark的大数据系统设计专题,涉及监控系统和广告跟踪系统中的Spark Streaming应用、金融大数据整合、Spark图计算、千亿社交网络研究、Spark SQL等议题内容。
日前主办方也披露了该专题的议题和日程,以及嘉宾阵容,详情如下:
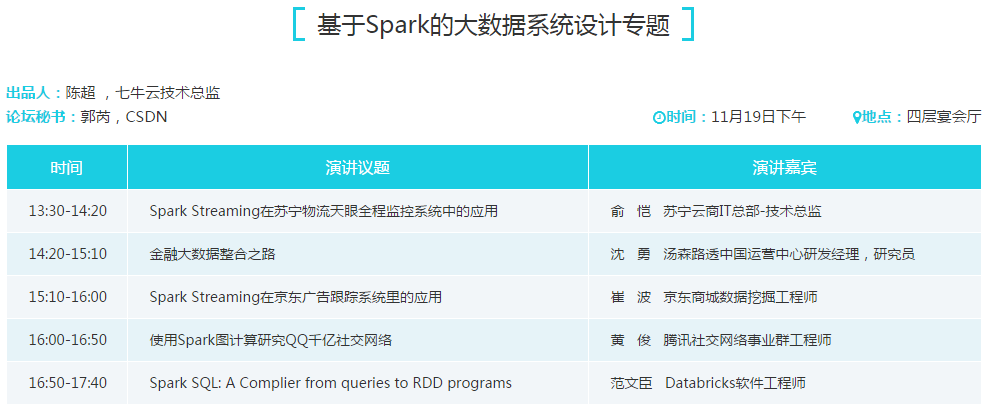
基于Spark的大数据系统设计专题出品人:陈超 七牛云技术总监

全面负责七牛所有数据产品的设计与研发,近年来一直专注于分布式计算与机器学习等领域。有非常丰富的分布式系统设计与实现的经验,在分布式数据库方面也有深入研究。
俞恺 苏宁云商IT总部-技术总监

苏宁云商IT总部技术总监,主要负责苏宁物流大数据系统的开发工作,其中主要主导了物流大数据从传统数据仓库到分布式数据仓库的架构升级,主导了苏宁物流实时大数据系统的搭建和升级等工作,致力于推广大数据在企业生产运营各领域的应用。
演讲主题:Spark Streaming在苏宁物流天眼全流程监控系统中的应用
Spark Streaming是基于Spark的实时计算框架,它通过将输入数据流以时间片为单位拆分成一个个小的RDD,从而支持流式、批处理和交互试查询应用。本次演讲将以苏宁天眼全流程监控系统为案例,介绍如何通过spark streaming与kafka、redis等技术整合,解决实时数据采集、计算、展示的问题。
听众受益:了解Spark Streaming流式计算的特点和实现原理;掌握如何通过Spark Streaming与Kafka,Redis等技术的整合,构建数据采集、计算、展示的整体解决方案。
沈勇 汤森路透中国运营中心研发经理,研究员

现任汤森路透中国运营中心研发经理,研究员。曾参与大型网络管理项目的管理设计和实施。对大型通讯网络有深刻认识。曾参与实施联通,网通,总参的核心网管系统的设计和实施。曾任职BEA中国研发中心,参与金融分布式中间件Tuxedo的开发和维护,并参与WebLogic的开发和维护。对于中间件和分布式事务有深刻的理解。并且熟悉银行业中间件的应用案例。在汤森路透的工作中,曾领导实时数据分析系统核心组件的设计与开发。现在负责金融大数据和机器学习项目的落地实施。具有长期的金融数据分析处理的经验。在企业级内容平台的搭建过程中承担重要的基础架构工作。企业级内容平台能够应对金融数据对效率,实时性,准确性和多样性的苛刻要求。沈勇是Thomson Reuters的实施数据处理技术专家,编译器技术专家和大数据技术专家。在Spark应用中,建立了基于Spark Catelyst的新的处理语言,大大增强了现有Spark SQL对层级化数据的支持。
演讲主题:金融大数据整合之路
针对金融数据的多样性,实时性,和对准确性的要求。Thomson Reuters应用大数据技术整合现有数据的过程中遇到了诸多挑战,并且积累了自己独特的经验。这次演讲将总结一些现有的经验并和听众讨论一些可行性。
- 案例分析。分析现有企业内部对数据处理的挑战。主要针对应用案例的复杂性,进行全面的分析,和方案选择。
- 自动化数据格式转换, 如何使用规则定义进行数据的自动化转换。在Spark中,数据转换同时支持Batch & Streaming。
- 半结构化数据的处理,如何在Spark的基础上构建非结构化数据处理的DSL,我们将深入Spark SQL Catalyst的实现并且结合ANTLR构建一种新的编程语言。
- 图数据库的使用案例,如何引入图数据库,并且构建分布式大型图数据库实现。
听众受益:
- 了解大型企业数据处理系统大数据转型的考虑和方案。
- 了解Spark的内部机理和应用案例如Data Set,Catelyst,UDF等。
- 了解编译器技术和Spark SQL的对接方案。
崔波 京东商城数据挖掘工程师

京东广告部门负责广告效果跟踪项目,在大数据方面有比较多的经验,搭建过基于Storm,Kafka,Spark等的大数据实时处理系统。
演讲主题:Spark Streaming在京东广告跟踪系统里的应用
广告跟踪系统需要实时在海量用户信息中提取关键信息并准确判断订单跟广告之间的关系,我们搭建的Spark Streaming系统在可靠性跟稳定性与实时性上遇到很多坑积累很多经验,也总结出一些有效的实践,分享给大家。
听众受益:
- Spark Streaming系统的最佳实践;
- Spark系统跟外部系统的整合;
- 一个大型系统的设计取舍,运维实践。
黄俊 腾讯社交网络事业群工程师

腾讯QQ社交网络事业群数据挖掘工程师,主导或参与过社交关系链挖掘,LBS挖掘,推荐系统等多个项目。负责对千亿QQ社交关系链的计算,分析和挖掘工作,历经腾讯图计算从Hive到Spark的演变。
演讲主题:使用Spark图计算研究QQ千亿社交网络
本演讲介绍腾讯在千亿QQ关系链使用Spark图计算进行分析和挖掘的探索。以共同好友和平均距离两个社交网络指标的计算为例,从应用场景开始,介绍超大规模图计算面对的难点和对应的解决方法。
听众受益:
希望听众能够了解大规模图计算能够用在什么地方,实现的时候会遇到什么问题,以及Spark在解决问题的时候能够发挥的作用。
范文臣 Databricks软件工程师

Apache Spark Committer,Spark SQL 开发团队成员。2013年从浙江大学毕业后,一直在进行分布式系统相关的工作。2014年开始接触Spark,并成为最活跃的代码贡献者之一。2015年正式加入Databricks,成为Databricks中国分部(筹建中)的第一名员工,主要负责开源社区方面的工作,例如:审查其他社区成员提交的PR,主导Spark SQL 一些主要功能的设计和研发,定期审计项目代码质量等。
演讲主题:Spark SQL: A Complier from queries to RDD programs
为了让Spark能处理结构化数据,Spark SQL应运而生。随着Spark SQL的不断发展,它已成为目前最快的SQL on Hadoop 系统之一。它提供的DataFrame/Dataset接口,也已代替RDD成为Spark新一代的用户接口。演讲将回顾Spark SQL的历史,从源头开始深入介绍Spark SQL的设计理念以及实现细节,从而能让大家在实践中更好地运用Spark SQL。
听众受益:
了解Spark SQL的技术原理,在做技术选型的时候能够做出更适合需求的选择,在使用Spark SQL的时候能够心里有底,更好地运用Spark SQL的特性。
让我们一起畅游Spark技术海洋,我们在SDCC 2016·北京站等你。目前门票火热销售八折优惠中,5人以上团购立减800元,点击这里注册参会。
















 1147
1147

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









