






Apache Spark中,对Block的查询、存储管理,是通过唯一的Block ID来进行区分的。所以,了解Block ID的生成规则,能够帮助我们了解Block查询、存储过程中是如何定位Block以及如何处理互斥存储/读取同一个Block的。
可以想到,同一个Spark Application,以及多个运行的Application之间,对应的Block都具有唯一的ID,通过代码可以看到,BlockID包括:RDDBlockId、ShuffleBlockId、ShuffleDataBlockId、ShuffleIndexBlockId、BroadcastBlockId、TaskResultBlockId、TempLocalBlockId、TempShuffleBlockId这8种ID,可以详见如下代码定义:
@DeveloperApi
case class RDDBlockId(rddId: Int, splitIndex: Int) extends BlockId {
override def name: String = "rdd_" + rddId + "_" + splitIndex
}
// Format of the shuffle block ids (including data and index) should be kept in sync with
// org.apache.spark.network.shuffle.ExternalShuffleBlockResolver#getBlockData().
@DeveloperApi
case class ShuffleBlockId(shuffleId: Int, mapId: Int, reduceId: Int) extends BlockId {
override def name: String = "shuffle_" + shuffleId + "_" + mapId + "_" + reduceId
}
@DeveloperApi
case class ShuffleDataBlockId(shuffleId: Int, mapId: Int, reduceId: Int) extends BlockId {
override def name: String = "shuffle_" + shuffleId + "_" + mapId + "_" + reduceId + ".data"
}
@DeveloperApi
case class ShuffleIndexBlockId(shuffleId: Int, mapId: Int, reduceId: Int) extends BlockId {
override def name: String = "shuffle_" + shuffleId + "_" + mapId + "_" + reduceId + ".index"
}
@DeveloperApi
case class BroadcastBlockId(broadcastId: Long, field: String = "") extends BlockId {
override def name: String = "broadcast_" + broadcastId + (if (field == "") "" else "_" + field)
}
@DeveloperApi
case class TaskResultBlockId(taskId: Long) extends BlockId {
override def name: String = "taskresult_" + taskId
}
@DeveloperApi
case class StreamBlockId(streamId: Int, uniqueId: Long) extends BlockId {
override def name: String = "input-" + streamId + "-" + uniqueId
}
/** Id associated with temporary local data managed as blocks. Not serializable. */
private[spark] case class TempLocalBlockId(id: UUID) extends BlockId {
override def name: String = "temp_local_" + id
}
/** Id associated with temporary shuffle data managed as blocks. Not serializable. */
private[spark] case class TempShuffleBlockId(id: UUID) extends BlockId {
override def name: String = "temp_shuffle_" + id
}我们以RDDBlockId的生成规则为例,它是以前缀字符串“rdd_”为前缀、分配的全局RDD ID、下划线“_”、Partition ID这4部分拼接而成,因为RDD ID是唯一的,所以最终构造好的RDDBlockId对应的字符串就是唯一的。如果该Block存在,查询可以唯一定位到该Block,存储也不会出现覆盖其他RDDBlockId的问题。
下面,我们通过分析MemoryStore、DiskStore、BlockManager、BlockInfoManager这4个最核心的与Block管理相关的实现类,来理解Spark对Block的管理。全文中,我们主要针对RDDBlockId对应的Block数据的处理、存储、查询、读取,来分析Block的管理。
MemoryStore
先说明一下MemoryStore,它主要用来在内存中存储Block数据,可以避免重复计算同一个RDD的Partition数据。一个Block对应着一个RDD的一个Partition的数据。当StorageLevel设置为如下值时,都会可能会需要使用MemoryStore来存储数据:
MEMORY_ONLY
MEMORY_ONLY_2
MEMORY_ONLY_SER
MEMORY_ONLY_SER_2
MEMORY_AND_DISK
MEMORY_AND_DISK_2
MEMORY_AND_DISK_SER
MEMORY_AND_DISK_SER_2
OFF_HEAP所以,MemoryStore提供对Block数据的存储、读取等操作API,MemoryStore也提供了多种存储方式,下面详细说明每种方式。
- 以序列化格式保存Block数据
def putBytes[T: ClassTag](
blockId: BlockId,
size: Long,
memoryMode: MemoryMode,
_bytes: () => ChunkedByteBuffer): Boolean首先,通过MemoryManager来申请Storage内存,调用putBytes方法,会根据size大小去申请Storage内存,如果申请成功,则会将blockId对应的Block数据保存在内部的LinkedHashMap[BlockId, MemoryEntry[_]]映射表中,然后以SerializedMemoryEntry这种序列化的格式存储,实际SerializedMemoryEntry就是简单指向Buffer中数据的引用对象:
private case class SerializedMemoryEntry[T](
buffer: ChunkedByteBuffer,
memoryMode: MemoryMode,
classTag: ClassTag[T]) extends MemoryEntry[T] {
def size: Long = buffer.size
}如果无法申请到size大小的Storage内存,则存储失败,对于出现这种失败的情况,需要使用MemoryStore存储API的调用者去处理异常情况。
- 基于记录迭代器,以反序列化Java对象形式保存Block数据
private[storage] def putIteratorAsValues[T](
blockId: BlockId,
values: Iterator[T],
classTag: ClassTag[T]): Either[PartiallyUnrolledIterator[T], Long]这种方式,调用者希望将Block数据记录以反序列化的方式保存在内存中,如果内存中能放得下,则返回最终Block数据记录的大小,否则返回一个PartiallyUnrolledIterator[T]迭代器,其中对应如下2种情况:
第一种,Block数据记录能够完全放到内存中:和前面的方式类似,能够全部放到内存,但是不同的是,这种方式对应的数据格式是反序列化的Java对象格式,对应实现类DeserializedMemoryEntry[T],它也会被直接存放到MemoryStore内部的LinkedHashMap[BlockId, MemoryEntry[_]]映射表中。DeserializedMemoryEntry[T]类定义如下所示:
private case class DeserializedMemoryEntry[T](
value: Array[T],
size: Long,
classTag: ClassTag[T]) extends MemoryEntry[T] {
val memoryMode: MemoryMode = MemoryMode.ON_HEAP
}它与SerializedMemoryEntry都是MemoryEntry[T]的子类,所有被放到同一个映射表LinkedHashMap[BlockId, MemoryEntry[_]] entries中。
另外,也存在这种可能,通过MemoryManager申请的Unroll内存大小大于该Block打开需要的内存,则会返回如下结果对象:
Left(new PartiallyUnrolledIterator( this, unrollMemoryUsedByThisBlock,
unrolled = arrayValues.toIterator, rest = Iterator.empty))上面unrolled = arrayValues.toIterator,rest = Iterator.empty,表示在内存中可以打开迭代器中全部的数据记录,打开对象类型为DeserializedMemoryEntry[T]。
第二种,Block数据记录只能部分放到内存中:也就是说Driver或Executor上的内存有限,只可以放得下部分记录,另一部分记录内存中放不下。values记录迭代器对应的全部记录数据无法完全放在内存中,所以为了保证不发生OOM异常,首选会调用MemoryManager的acquireUnrollMemory方法去申请Unroll内存,如果可以申请到,在迭代values的过程中,需要累加计算打开(Unroll)的记录对象大小之和,使其大小不能大于申请到的Unroll内存,直到还有一部分记录无法放到申请的Unroll内存中。 最后,返回的结果对象如下所示:
Left(new PartiallyUnrolledIterator(
this, unrollMemoryUsedByThisBlock, unrolled = vector.iterator, rest = values))上面的PartiallyUnrolledIterator中rest对应的values就是putIteratorAsValues方法传进来的迭代器参数值,该迭代器已经迭代出部分记录,放到了内存中,调用者可以继续迭代该迭代器去处理未打开(Unroll)的记录,而unrolled对应一个打开记录的迭代器。这里,PartiallyUnrolledIterator迭代器包装了vector.iterator和一个迭代出部分记录的values迭代器,调用者对PartiallyUnrolledIterator进行统一迭代能够获取到全部记录,里面包含两种类型的记录:DeserializedMemoryEntry[T]和T。
- 基于记录迭代器,以序列化二进制格式保存Block数据
private[storage] def putIteratorAsBytes[T](
blockId: BlockId,
values: Iterator[T],
classTag: ClassTag[T],
memoryMode: MemoryMode): Either[PartiallySerializedBlock[T], Long]这种方式,调用这种希望将Block数据记录以二进制的格式保存在内存中。如果内存中能放得下,则返回最终的大小,否则返回一个PartiallySerializedBlock[T]迭代器。
如果Block数据记录能够完全放到内存中,则以SerializedMemoryEntry[T]格式放到内存的映射表中。如果Block数据记录只能部分放到内存中,则返回如下对象:
Left(
new PartiallySerializedBlock(
this,
serializerManager,
blockId,
serializationStream,
redirectableStream,
unrollMemoryUsedByThisBlock,
memoryMode,
bbos.toChunkedByteBuffer,
values,
classTag))类似地,返回结果对象对调用者保持统一的迭代API视图。
DiskStore
DiskStore提供了将Block数据写入到磁盘的基本操作,它是通过DiskBlockManager来管理逻辑上Block到物理磁盘上Block文件路径的映射关系。当StorageLevel设置为如下值时,都可能会需要使用DiskStore来存储数据:
DISK_ONLY
DISK_ONLY_2
MEMORY_AND_DISK
MEMORY_AND_DISK_2
MEMORY_AND_DISK_SER
MEMORY_AND_DISK_SER_2
OFF_HEAPDiskBlockManager管理了每个Block数据存储位置的信息,包括从Block ID到磁盘上文件的映射关系。DiskBlockManager主要有如下几个功能:
- 负责创建一个本地节点上的指定磁盘目录,用来存储Block数据到指定文件中
- 如果Block数据想要落盘,需要通过调用getFile方法来分配一个唯一的文件路径
- 如果想要查询一个Block是否在磁盘上,通过调用containsBlock方法来查询
- 查询当前节点上管理的全部Block文件
- 通过调用createTempLocalBlock方法,生成一个唯一Block ID,并创建一个唯一的临时文件,用来存储中间结果数据
- 通过调用createTempShuffleBlock方法,生成一个唯一Block ID,并创建一个唯一的临时文件,用来存储Shuffle过程的中间结果数据
DiskStore提供的基本操作接口,与MemoryStore类似,比较简单,如下所示:
- 通过文件流写Block数据
该种方式对应的接口方法,如下所示:
def put(blockId: BlockId)(writeFunc: FileOutputStream => Unit): Unit参数指定Block ID,还有一个写Block数据到打开的文件流的函数,在调用put方法时,首先会从DiskBlockManager分配一个Block ID对应的磁盘文件路径,然后将数据写入到该文件中。
- 将二进制Block数据写入文件
putBytes方法实现了,将一个Buffer中的Block数据写入指定的Block ID对应的文件中,方法定义如下所示:
def putBytes(blockId: BlockId, bytes: ChunkedByteBuffer): Unit实际上,它是调用上面的put方法,将bytes中的Block二进制数据写入到Block文件中。
- 从磁盘文件读取Block数据
对应方法如下所示:
def getBytes(blockId: BlockId): ChunkedByteBuffer通过给定的blockId,获取磁盘上对应的Block文件的数据,以ChunkedByteBuffer的形式返回。
- 删除Block文件
对应的删除方法定义,如下所示:
def remove(blockId: BlockId): Boolean通过DiskBlockManager查找到blockId对应的Block文件,然后删除掉。
BlockManager
谈到Spark中的Block数据存储,我们很容易能够想到BlockManager,他负责管理在每个Dirver和Executor上的Block数据,可能是本地或者远程的。具体操作包括查询Block、将Block保存在指定的存储中,如内存、磁盘、堆外(Off-heap)。而BlockManager依赖的后端,对Block数据进行内存、磁盘存储访问,都是基于前面讲到的MemoryStore、DiskStore。
在Spark集群中,当提交一个Application执行时,该Application对应的Driver以及所有的Executor上,都存在一个BlockManager、BlockManagerMaster,而BlockManagerMaster是负责管理各个BlockManager之间通信,这个BlockManager管理集群,如下图所示:
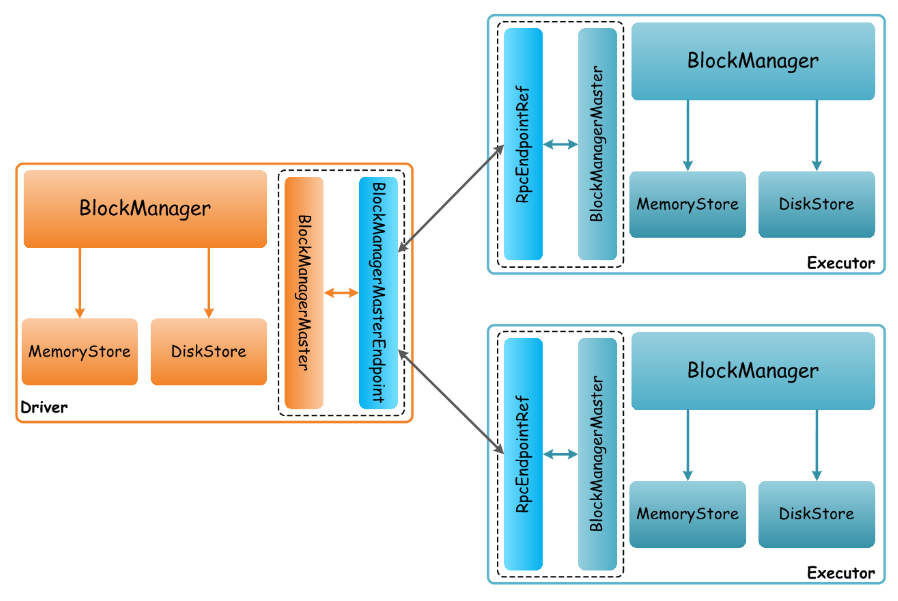
关于一个Application运行过程中Block的管理,主要是基于该Application所关联的一个Driver和多个Executor构建了一个Block管理集群:Driver上的(BlockManagerMaster, BlockManagerMasterEndpoint)是集群的Master角色,所有Executor上的(BlockManagerMaster, RpcEndpointRef)作为集群的Slave角色。当Executor上的Task运行时,会查询对应的RDD的某个Partition对应的Block数据是否处理过,这个过程中会触发多个BlockManager之间的通信交互。我们以ShuffleMapTask的运行为例,对应代码如下所示:
override def runTask(context: TaskContext): MapStatus = {
// Deserialize the RDD using the broadcast variable.
val deserializeStartTime = System.currentTimeMillis()
val ser = SparkEnv.get.closureSerializer.newInstance()
val (rdd, dep) = ser.deserialize[(RDD[_], ShuffleDependency[_, _, _])](
ByteBuffer.wrap(taskBinary.value), Thread.currentThread.getContextClassLoader)
_executorDeserializeTime = System.currentTimeMillis() - deserializeStartTime
var writer: ShuffleWriter[Any, Any] = null
try {
val manager = SparkEnv.get.shuffleManager
writer = manager.getWriter[Any, Any](dep.shuffleHandle, partitionId, context)
writer.write(rdd.iterator(partition, context).asInstanceOf[Iterator[_ <: Product2[Any, Any]]]) // 处理RDD的Partition的数据
writer.stop(success = true).get
} catch {
case e: Exception =>
try {
if (writer != null) {
writer.stop(success = false)
}
} catch {
case e: Exception =>
log.debug("Could not stop writer", e)
}
throw e
}
}一个RDD的Partition对应一个ShuffleMapTask,一个ShuffleMapTask会在一个Executor上运行,它负责处理RDD的一个Partition对应的数据,基本处理流程,如下所示:
- 根据该Partition的数据,创建一个RDDBlockId(由RDD ID和Partition Index组成),即得到一个稳定的blockId(如果该Partition数据被处理过,则可能本地或者远程Executor存储了对应的Block数据)。
- 先从BlockManager获取该blockId对应的数据是否存在,如果本地存在(已经处理过),则直接返回Block结果(BlockResult);否则,查询远程的Executor是否已经处理过该Block,处理过则直接通过网络传输到当前Executor本地,并根据StorageLevel设置,保存Block数据到本地MemoryStore或DiskStore,同时通过BlockManagerMaster上报Block数据状态(通知Driver当前的Block状态,亦即,该Block数据存储在哪个BlockManager中)。
- 如果本地及远程Executor都没有处理过该Partition对应的Block数据,则调用RDD的compute方法进行计算处理,并将处理的Block数据,根据StorageLevel设置,存储到本地MemoryStore或DiskStore。
- 根据ShuffleManager对应的ShuffleWriter,将返回的该Partition的Block数据进行Shuffle写入操作
下面,我们基于上面逻辑,详细分析在这个处理过程中重要的交互逻辑:
- 根据RDD获取一个Partition对应数据的记录迭代器
用户提交的Spark Application程序,会设置对应的StorageLevel,所以设置与不设置对该处理逻辑有一定影响,具有两种情况,如下图所示:
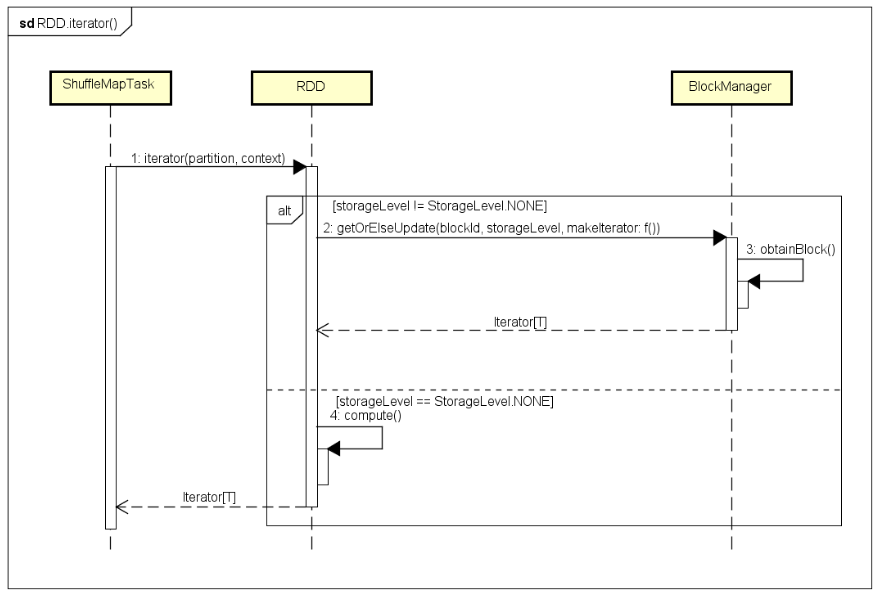
如果用户程序设置了StorageLevel,可能该Partition的数据已经处理过,那么对应的处理结果Block数据可能已经存储。一般设置的StorageLevel,或者将Block存储在内存中,或者存储在磁盘上,这里会尝试调用getOrElseUpdate()方法获取对应的Block数据,如果存在则直接返回Block对应的记录的迭代器实例,就不需要重新计算了,如果没有找到对应的已经处理过的Block数据,则调用RDD的compute()方法进行处理,处理结果根据StorageLevel设置,将Block数据存储在内存或磁盘上,缓存供后续Task重复使用。
如果用户程序没有设置StorageLevel,那么RDD对应的该Partition的数据一定没有进行处理过,即使处理过,如果没有进行Checkpointing,也需要重新计算(如果进行了Checkpointing,可以直接从缓存中获取),直接调用RDD的compute()方法进行处理。
- 从BlockManager查询获取Block数据
每个Executor上都有一个BlockManager实例,负责管理用户提交的该Application计算过程中产生的Block。很有可能当前Executor上存储在RDD对应Partition的经过处理后得到的Block数据,也有可能当前Executor上没有,但是其他Executor上已经处理过并缓存了Block数据,所以对应着本地获取、远程获取两种可能,本地获取交互逻辑如下图所示:
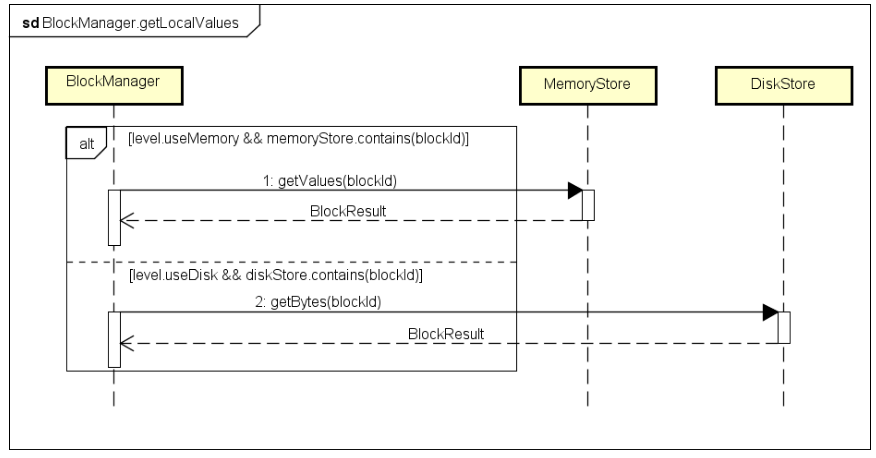
从本地获取,根据StorageLevel设置,如果是存储在内存中,则从本地的MemoryStore中查询,存在则读取并返回;如果是存储在磁盘上,则从本地的DiskStore中查询,存在则读取并返回。本地不存在,则会从远程的Executor读取,对应的组件交互逻辑,如下图所示:
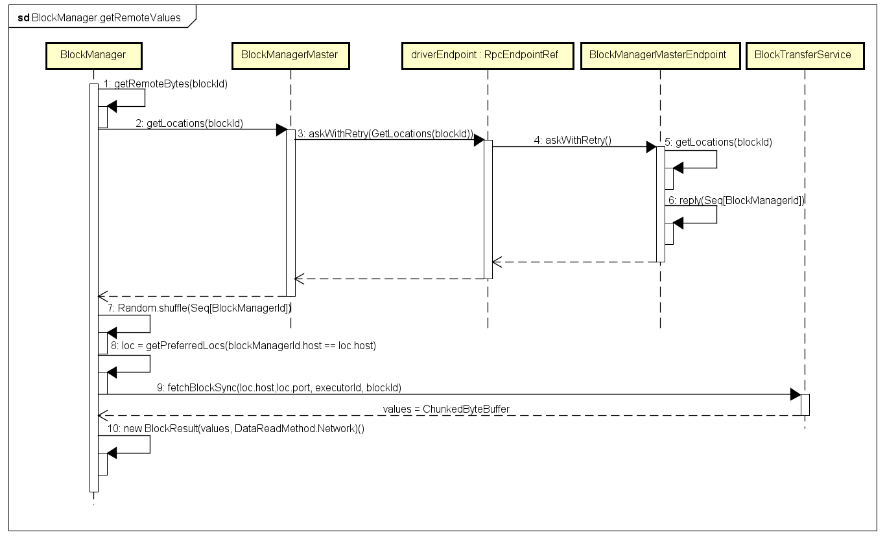
远程获取交互逻辑相对比较复杂:当前Executor上的BlockManager通过BlockManagerMaster,向远程的Driver上的BlockManagerMasterEndpoint查询对应Block ID,有哪些Executor已经保存了该Block数据,Dirver返回一个包含了该Block数据的Location列表,如果对应的Location信息与当前ShuffleMapTask执行所在Executor在同一台节点上,则会优先使用该Location,因为同一节点上的多个Executor之间传输Block数据效率更高。
这里需要说明的是,如果对应的Block数据的StorageLevel设置为写磁盘,通过前面我们知道,DiskStore是通过DiskBlockManager进行管理存储到磁盘上的Block数据文件的,在同一个节点上的多个Executor共享相同的磁盘文件路径,相同的Block数据文件也就会被同一个节点上的多个Executor所共享。而对应MemoryStore,因为每个Executor对应独立的JVM实例,从而具有独立的Storage/Execution内存管理,所以使用MemoryStore不能共享同一个Block数据,但是同一个节点上的多个Executor之间的MemoryStore之间拷贝数据,比跨网络传输要高效的多。
BlockInfoManager
用户提交一个Spark Application程序,如果程序对应的DAG图相对复杂,其中很多Task计算的结果Block数据都有可能被重复使用,这种情况下如何去控制某个Executor上的Task线程去读写Block数据呢?其实,BlockInfoManager就是用来控制Block数据读写操作,并且跟踪Task读写了哪些Block数据的映射关系,这样如果两个Task都想去处理同一个RDD的同一个Partition数据,如果没有锁来控制,很可能两个Task都会计算并写同一个Block数据,从而造成混乱。我们分析每种情况下,BlockInfoManager是如何管理Block数据(同一个RDD的同一个Partition)读写的:
- 第一个Task请求写Block数据
这种情况下,没有其他Task写Block数据,第一个Task直接获取到写锁,并启动写Block数据到本地MemoryStore或DiskStore。如果其他写Block数据的Task也请求写锁,则该Task会阻塞,等待第一个获取写锁的Task完成写Block数据,直到第一个Task写完成,并通知其他阻塞的Task,然后其他Task需要再次获取到读锁来读取该Block数据。
- 第一个Task正在写Block数据,其他Task请求读Block数据
这种情况,Block数据没有完成写操作,其他读Block数据的Task只能阻塞,等待写Block的Task完成并通知读Task去读取Block数据。
- Task请求读取Block数据
如果该Block数据不存在,则直接返回空,表示当前RDD的该Partition并没有被处理过。如果当前Block数据存在,并且没有其他Task在写,表示已经完成了些Block数据操作,则该Task直接读取该Block数据。
















 592
592

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









