







wsl!wsl!wsl!
你是否因为win系统bug太多而痛苦!
你是否因为linux环境流畅跑通而羡慕!
wsl!win上的linux!拯救win10!从我做起!
简介:ChatTTS是目前最火的语音生成模型,特别适用于对话式音频和视频介绍等应用。它支持中文和英文,在语音合成中表现出超高质量和流畅度。
目录
1.wsl2安装+cuda11.8+cudnn8.9.7,基础环境部署请看该文章:
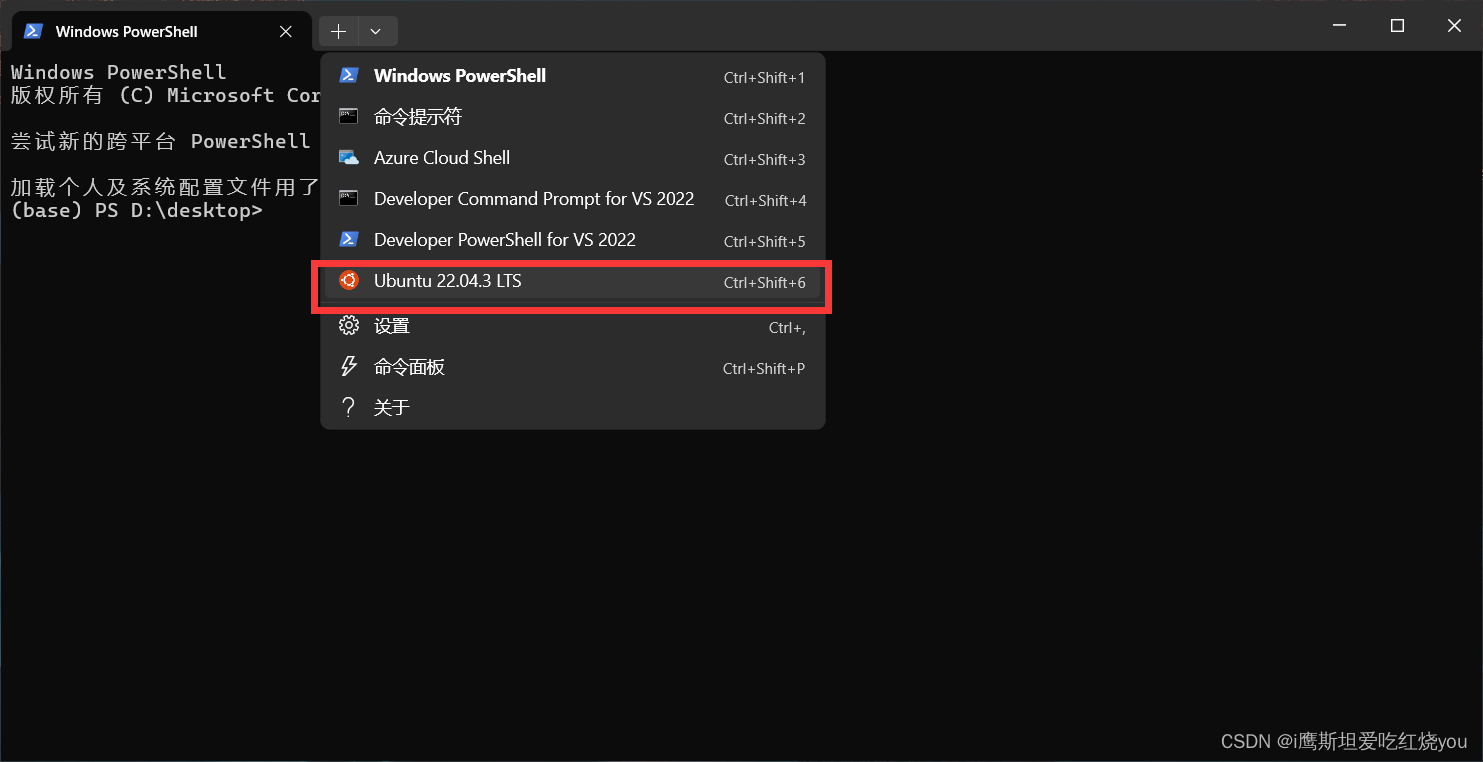
1.5.打开win terminal,选中Ubuntu 22.04
5.回到命令行窗口(输入命令quit()可退出python环境)
本地部署:
1.wsl2安装+cuda11.8+cudnn8.9.7,基础环境部署请看该文章:
wsl2安装深度学习环境2024最新版(cuda11.8+torch2.2)_wsl深度学习-CSDN博客
1.5.打开win terminal,选中Ubuntu 22.04
2.conda创建虚拟环境并安装torch
conda create -n tuling python==3.10
conda install pytorch==2.2.2 torchvision==0.17.2 torchaudio==2.2.2 pytorch-cuda=11.8 -c pytorch -c nvidia3.激活环境,下载源码并安装依赖
conda activate tuling
git clone https://github.com/2noise/ChatTTS.git
cd ChatTTS
pip install -r requirements.txt如果想本地简单体验一下,可选择另一版本ChatTTS-ui安装,选择原版是为了后续的开发。
conda activate tuling
git clone https://github.com/jianchang512/ChatTTS-ui.git
cd ChatTTS-ui
pip install -r requirements.txt
python app.py
4.下载模型文件
pip install modelscope输入python进入python环境
依次输入两行代码:
from modelscope import snapshot_download
model_dir = snapshot_download('pzc163/chatTTS',local_dir="./")从modelscope社区下载模型文件:

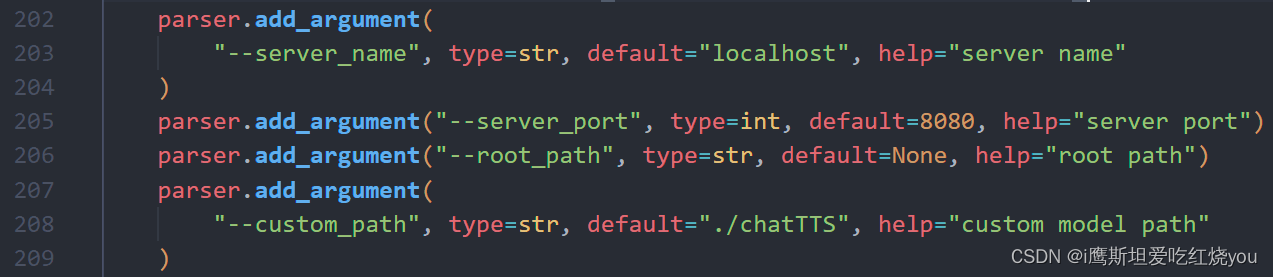
点开ChatTTS\examples\web\webui.py代码,修改203行传参为"localhost",208行的传参为"./chatTTS",对应上一步中拷贝的模型文件。
在第一行的下面添加以下代码,全局禁用gradio的遥测功能,否则会报一堆网络连接的错误
os.environ["GRADIO_ANALYTICS_ENABLED"] = "False"5.回到命令行窗口(输入命令quit()可退出python环境)
6.ChatTTS!启动!
python examples/web/webui.py点击红框的网站进行跳转,或复制到浏览器打开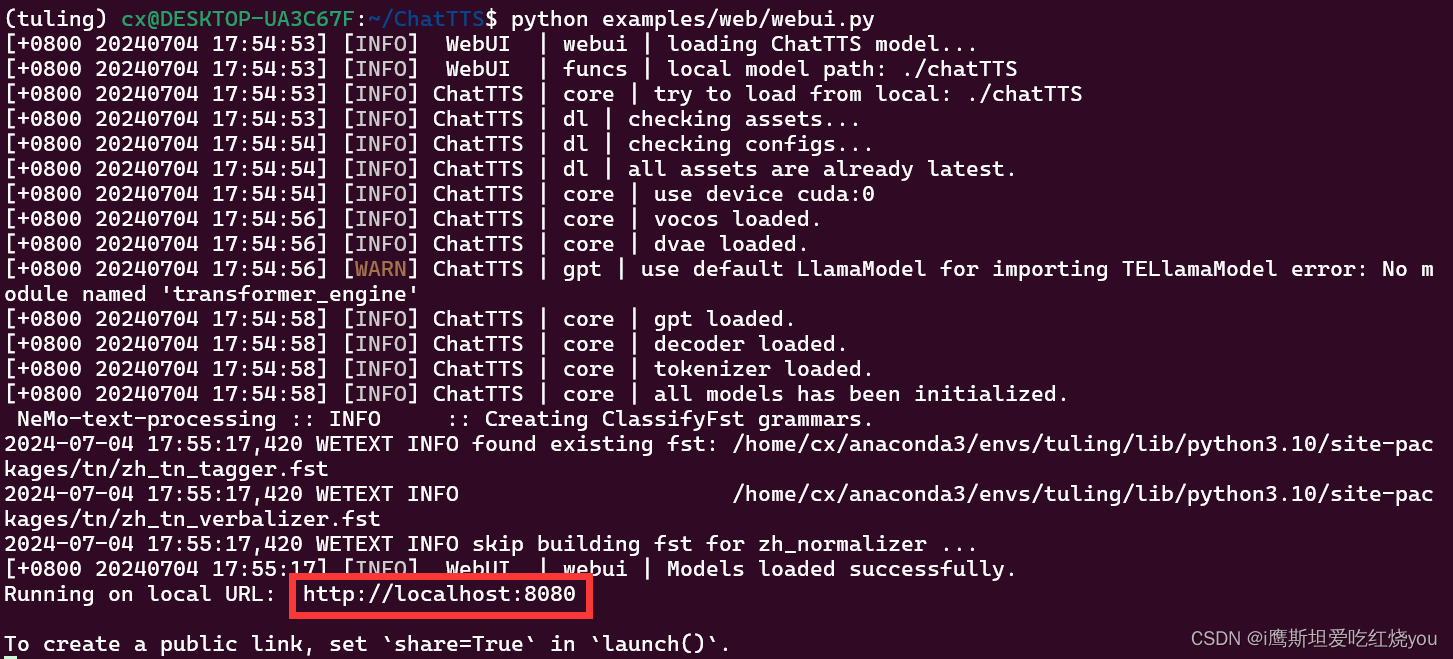
网页版打开如下:
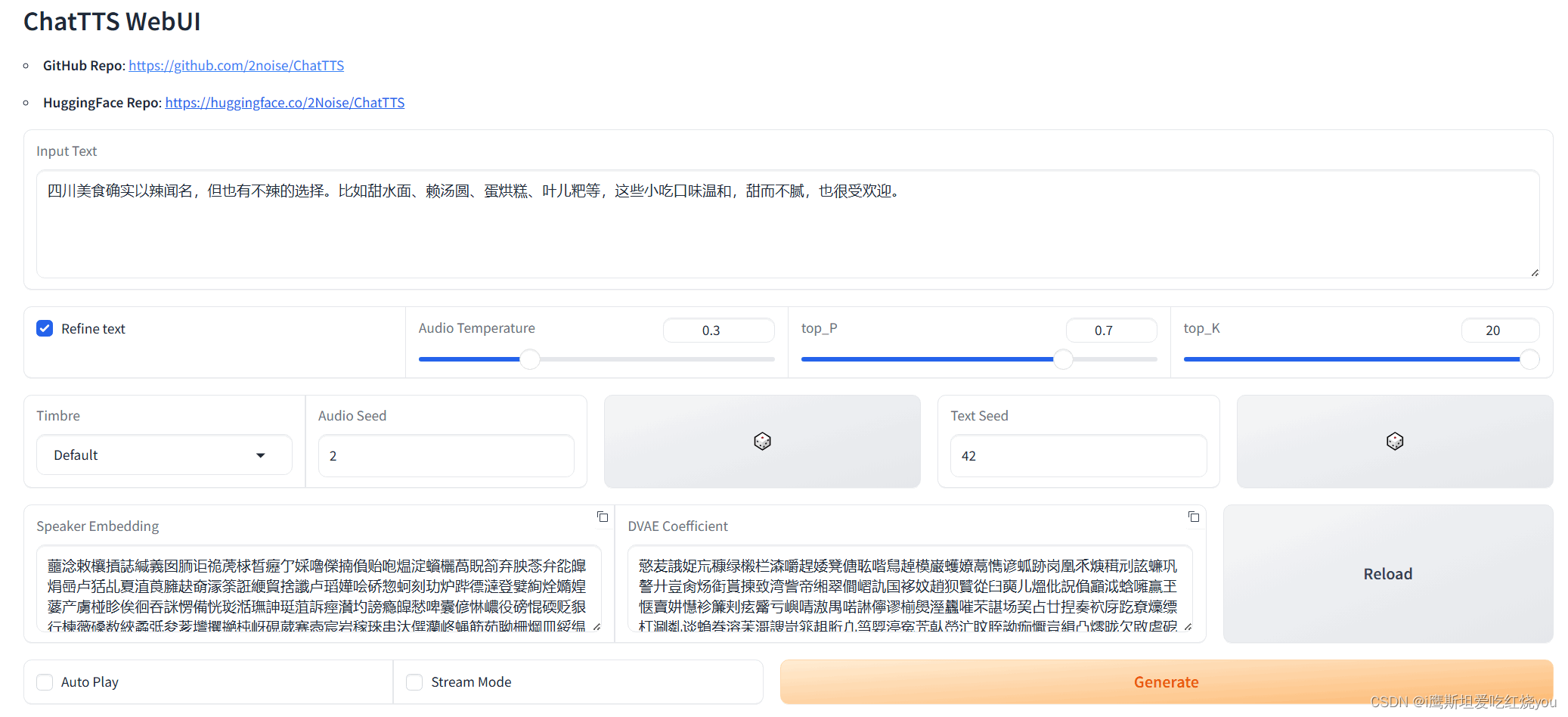
主要选择第一个Timebre(选择语音)选择不同的音色。
输入想要生成的文本,点击Generate,web端帮你的文本自动加上一些停顿和语气词生成新的文本,然后根据这个生成一段语音,如下:(第一段语音加载非常慢,估计得等2分钟,之后就非常流畅了)
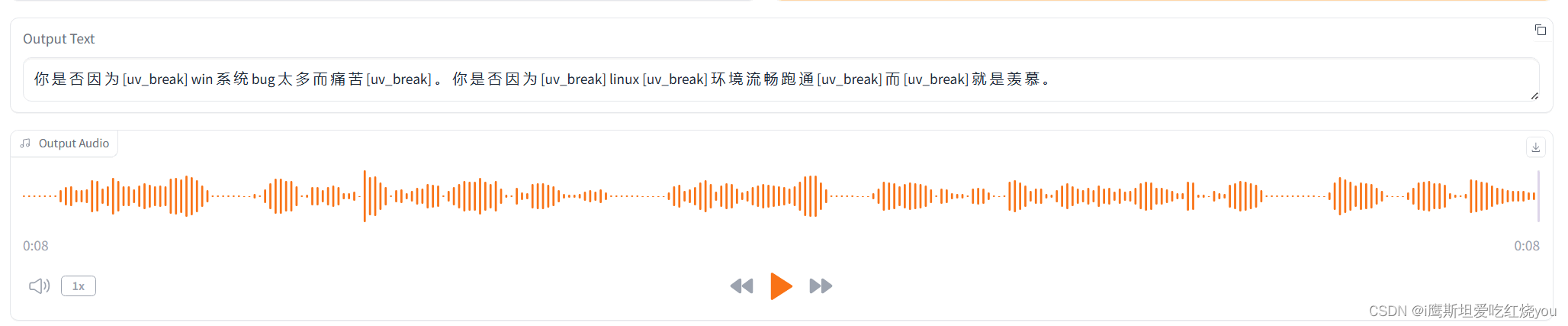
大家可以自由尝试不同的音色,不同的文本,来试着用aigc为世界增添一份不一样的声音!
祝各位的ai之旅一路顺风!
参考:
运行run_demo.py成功,但是报错httpx.ConnectTimeout: timed out · Issue #191 · THUDM/CodeGeeX2 (github.com)
GitHub - 2noise/ChatTTS: A generative speech model for daily dialogue.
















 821
821

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









