







《An overview of gradient descent optimization algorithms 》论文2017年发表,是一篇综述类论文,介绍了很多基于梯度下降方法的改进方法以及分布式执行的方法。其中先是介绍了三种典型的梯度下降算法:批量梯度下降、随机梯度下降和微批量梯度下降,区别在于他们的更新参数的时间点不同,计算梯度的方法相同。这是基础知识。重点在于后面。
文中提出四个至今仍是挑战的问题:学习率的大小如何设定,太大导致预测值在局部最优值附近震荡,太小导致收敛太慢;动态变化的学习率设定需要提前设定变化策略和阀值;用相同的学习率来更新所有的参数没有考虑到数据和特征的特点;对于非凸函数应用梯度下降算法不够充分因为即使导数为0也有可能是鞍点。之后第四部分提出了多种优化方法来对梯度下降优化,而这些改变基本上都是在数学公式上做文章:
1,对于求解的损失函数,可能其在某一维度上变化的剧烈而在其他维度上变化缓慢,这就导致梯度下降时在该维度上变动大而在其他维度上变化很小导致收敛慢:
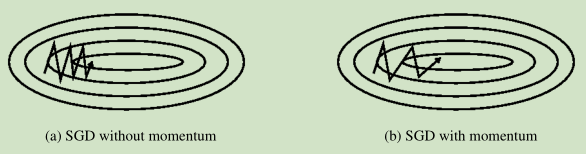
文中采用的方法是V(t) = γ*V(t−1)+η∇J(θ),θ=θ−V(t),第二个式子是更新参数的,第一个式子是在计算更新量,而本次的更新量取决于上一次的更新量和此次的梯度值即改变量,这样可以抑制某一变化剧烈的维度的更新侵蚀了整体的改变即进展。
2,Nesterov accelerated gradient(NAG):NAG考虑的内容和前一种方法不同,他考虑的是上一次的更新量和下一近似点的梯度值。V(t)=γ*V(t-1)+η*∇J(θ−γ*V(t−1)),θ=θ−v(t)。
3,Adagrad:在Adagrad的每一个参数的每一次更新中都使用不同的learning rate,即动态变化的,Adagrad动态变化learning rate只是这其中的一种公式:
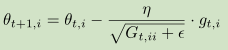
Gt是一个d*d维对角矩阵,对角线上的元素(i,i)表示在第t步更新时,历史上θi梯度平方和的积累。ϵ只是一个值很小的防止分母为0的平滑项。这可以实现随着步数的增加learning rate变化,但是只能实现learning rate越来越小,而且后期太小导致参数更新很慢。
4,Adadelta:他与Adagrad的区别在于不再是单纯的累加之前梯度的平方值,而是设定一个固定大小的窗口w,每一刻保留的是
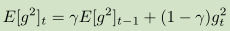
而在计算梯度值的时候公式变为
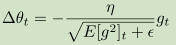
5,RMSprop类似于Adadelta。
6,Adaptive Moment Estimation(Adam)适应性矩估计:他维护了一阶和二阶矩估计值
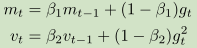
之后计算矩估计的偏差:
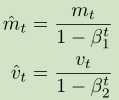
在更新参数值的时候,公式为
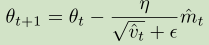
7,AdaMAX:该方法把Adam中的vt从计算二阶范数改为无穷阶范数,因为范数越高越会导致数值不稳定性,而无穷阶范数数值很稳定。其他更新操作相同。
8,Nadam:结合前面几种优化方法。
之后论文针对于异步并行计算梯度下降,给出了几个方案和相应论文:
Hogwild---A Lock-Free Approach to Parallelizing Stochastic gradient Descent : https://arxiv.org/abs/1106.5730
Large Scale Distributed Deep Networks : http://www.cs.toronto.edu/~ranzato/publications/DistBeliefNIPS2012_withAppendix.pdf
Delay-Tolerant Algorithms for Asynchronous Distributed Online Learning: http://papers.nips.cc/paper/5242-delay-tolerant-algorithms-for-asynchronous-distributed-online-learning.pdf
TensorFlow: Large-Scale Machine Learning on Heterogeneous Distributed Systems
Deep learning with Elastic Averaging SGD : https://arxiv.org/abs/1412.6651
以上各种优化方法对于不同的神经网络其优势是不同的,具体选用哪个优化方法还是需要依据具体的模型运行结果。
python代码实现:
__author__ = 'ing'
""" 测试并画出各种梯度下降算法 """
import numpy as np
import matplotlib.pyplot as plt
import time
# 原始拟合函数
def f(x):
return x[0]*x[0]+30*x[1]*x[1]
# 根据f(x)直接写出的求解梯度的函数
def g(x):
return np.array([2*x[0],100*x[1]])
xi = np.linspace(-200,200,1000)
yi = np.linspace(-100,100,1000)
X,Y = np.meshgrid(xi,yi)
Z = X*X+30*Y*Y
# 绘图方法
def contour(X,Y,Z,arr=None):
plt.figure(figsize=(15,7))
xx = X.flatten()
yy = Y.flatten()
zz = Z.flatten()
plt.contour(X,Y,Z,colors='black')
plt.plot(0,0,marker='*')
if arr is not None:
arr = np.array(arr)
for i in range(len(arr)-1):
plt.plot(arr[i:i+2,0],arr[i:i+2,1])
plt.show()
# 标准的梯度下降
def gd(x_start,step,g):
start = time.clock()
x = np.array(x_start,dtype='float64')
passing_dot = [x.copy()]
for i in range(150):
grad = g(x)
x -= grad*step
passing_dot.append(x.copy())
print('[Epoch {0}] grad={1},position={2}'.format(i,grad,x))
if abs(sum(grad)) < 1e-6:
break
end = time.clock()
print(end-start)
return x,passing_dot
def show_st_gd():
_,path = gd([100,80],0.020,g)
contour(X,Y,Z,path)
# 使用动量实现梯度下降
def momentum(x_start,step,g,discount=0.9):
start = time.clock()
x = np.array(x_start,dtype='float64')
pre_grad = np.zeros_like(x)
passing_dot = [x.copy()]
for i in range(100):
grad = g(x)
pre_grad = pre_grad*discount+step*grad
x -= pre_grad
passing_dot.append(x.copy())
print('[Epoch {0}] grad={1},position={2}'.format(i,grad,x))
if abs(sum(grad)) < 1e-6:
break
end = time.clock()
print(end-start)
return x,passing_dot
def show_momentum_gd():
_,path = momentum([100,80],0.01,g)
contour(X,Y,Z,path)
# NAG Nesterov accelerated gradient实现梯度下降
def NAG(x_start,step,g,discount=0.9):
start = time.clock()
x = np.array(x_start,dtype='float64')
passing_dot = [x.copy()]
pre_grad = np.zeros_like(x)
for i in range(150):
x_future = x - discount*pre_grad
grad = g(x_future)
pre_grad = discount*pre_grad+step*grad
x -= pre_grad
passing_dot.append(x.copy())
print('[Epoch {0}] grad = {1},position={2}'.format(i,grad,x))
if abs(sum(grad)) < 1e-6:
break
end = time.clock()
print(end-start)
return x,passing_dot
def show_NAG_GD():
_,path = NAG([100,80],0.002,g)
contour(X,Y,Z,path)
# Adagrad实现梯度下降
def Adagrad(x_start,step,g,smooth=1e-8):
start = time.clock()
x = np.array(x_start,dtype='float64')
passing_dot = [x.copy()]
G = np.zeros_like([1,len(x)],dtype='float64')
for i in range(350):
grad = g(x)
G += grad**2
x -= step*grad/np.sqrt(smooth+G)
passing_dot.append(x)
print('Epoch {0},grad = {1}, position = {2}'.format(i,grad,x))
if abs(sum(grad)) < 1e-6:
break
end = time.clock()
print(end-start)
return x,passing_dot
def show_Adagrad_GD():
_,path = Adagrad([100,80],10,g)
contour(X,Y,Z,path)
show_Adagrad_GD()
# Adadelta 实现梯度下降
def Adadelta(x_start,step,w,g,gamma=0.95,smooth=1e-8):
start = time.clock()
x = np.array(x_start,dtype='float64')
passing_dot = [x.copy()]
E = np.zeros([len(x),w],dtype='float64') # 矩阵最近的w个值,每一行代表一个参数,每一列代表某次的梯度的平方值
for i in range(350):
grad = g(x)
if i < w:
for j in range(len(x)):
E[j][i] = grad[j]**2
else:
E = np.column_stack((E,grad**2))
E = np.delete(E,[0],axis=1)
temp_sum = np.sum(E,axis=1,dtype='float64')
temp_mean = (temp_sum/w).T
sita = gamma*temp_mean+(1-gamma)*(grad**2)
sita = np.array(sita)
x -= step*grad/np.sqrt(smooth+sita)
passing_dot.append(x)
print('Epoch {0},grad = {1},position={2}'.format(i,grad,x))
if abs(sum(grad)) < 1e-6:
break
end = time.clock()
print(end-start)
return x,passing_dot
def show_Adadelta_GD():
_,path = Adadelta([100,80],10,4,g)
contour(X,Y,Z,path)
# Adam实现梯度下降
def Adam(x_start,g,learning_rate,beta1=0.9,beta2=0.999,smooth=1e-8):
start = time.clock()
x = np.array(x_start,dtype='float64')
passing_dot = [x.copy()]
m = np.zeros_like(x)
v = np.zeros_like(x)
for i in range(350):
grad = g(x)
m = beta1*m+(1-beta1)*grad
v = beta2*v+(1-beta2)*(grad**2)
temp_m = m/(1-beta1)
temp_v = v/(1-beta2)
delta = learning_rate*temp_m/(np.sqrt(temp_v)+smooth)
x -= delta
passing_dot.append(x)
print("Epoch {0},grad = {1},position={2}".format(i,grad,x))
if abs(sum(grad)) < 1e-6:
break
end = time.clock()
print(end-start)
return x,passing_dot
def show_Adam_GD():
_,path = Adam([100,80],g,1)
contour(X,Y,Z,path)标准梯度下降,learning rate=0.019,迭代150步:
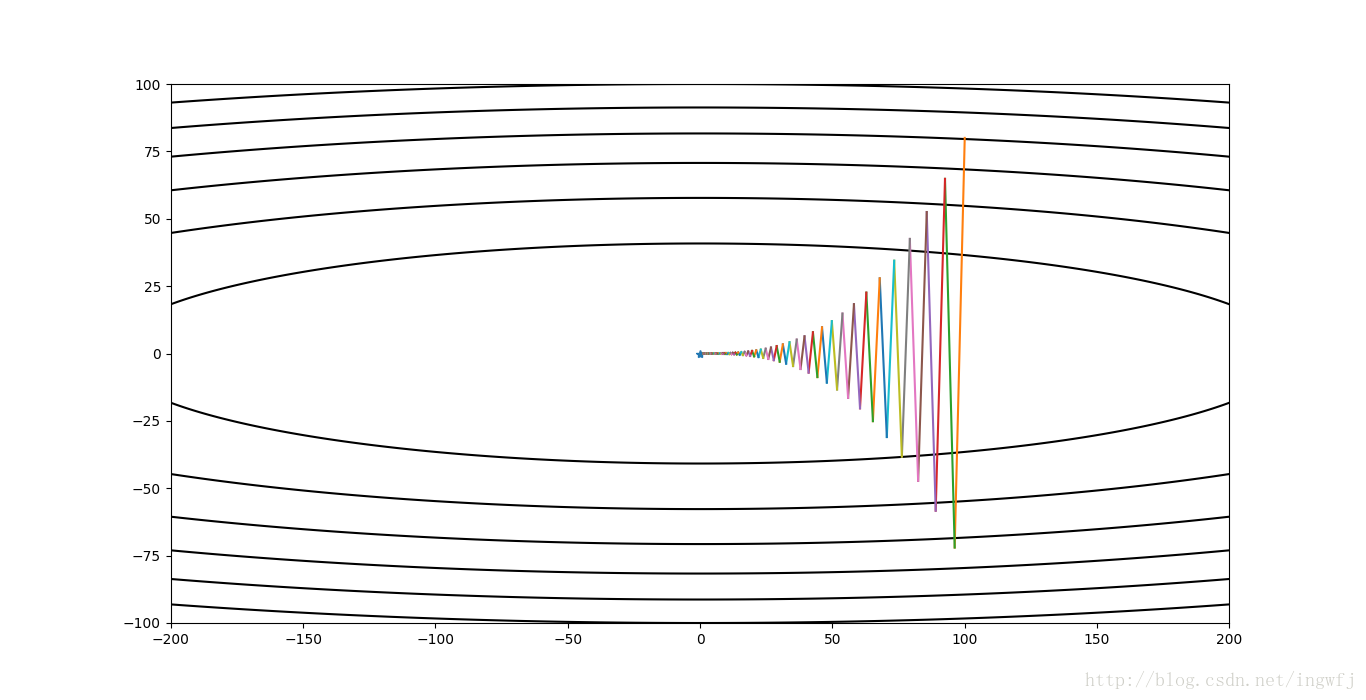
标准梯度下降,learning rate=0.020,迭代150步:
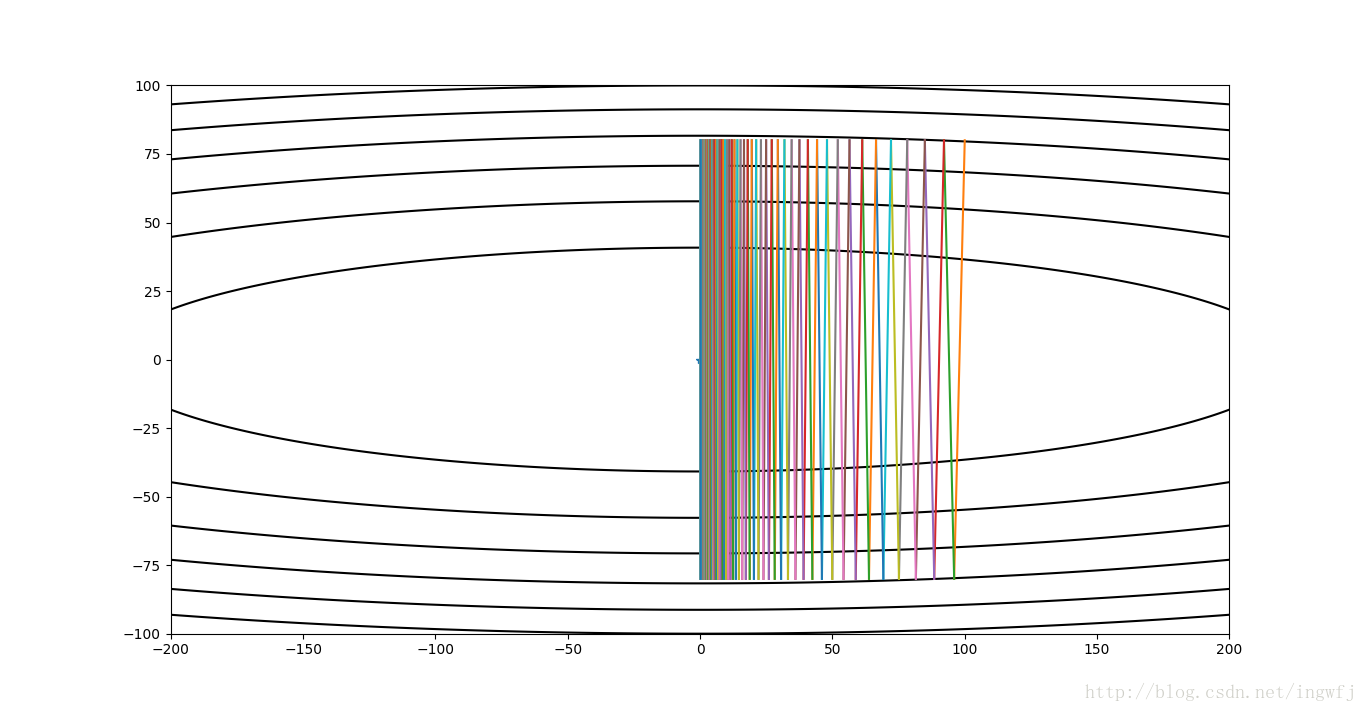
momentum法,learning rate=0.016,迭代150步,调参有问题,曲线冲过了最小点:
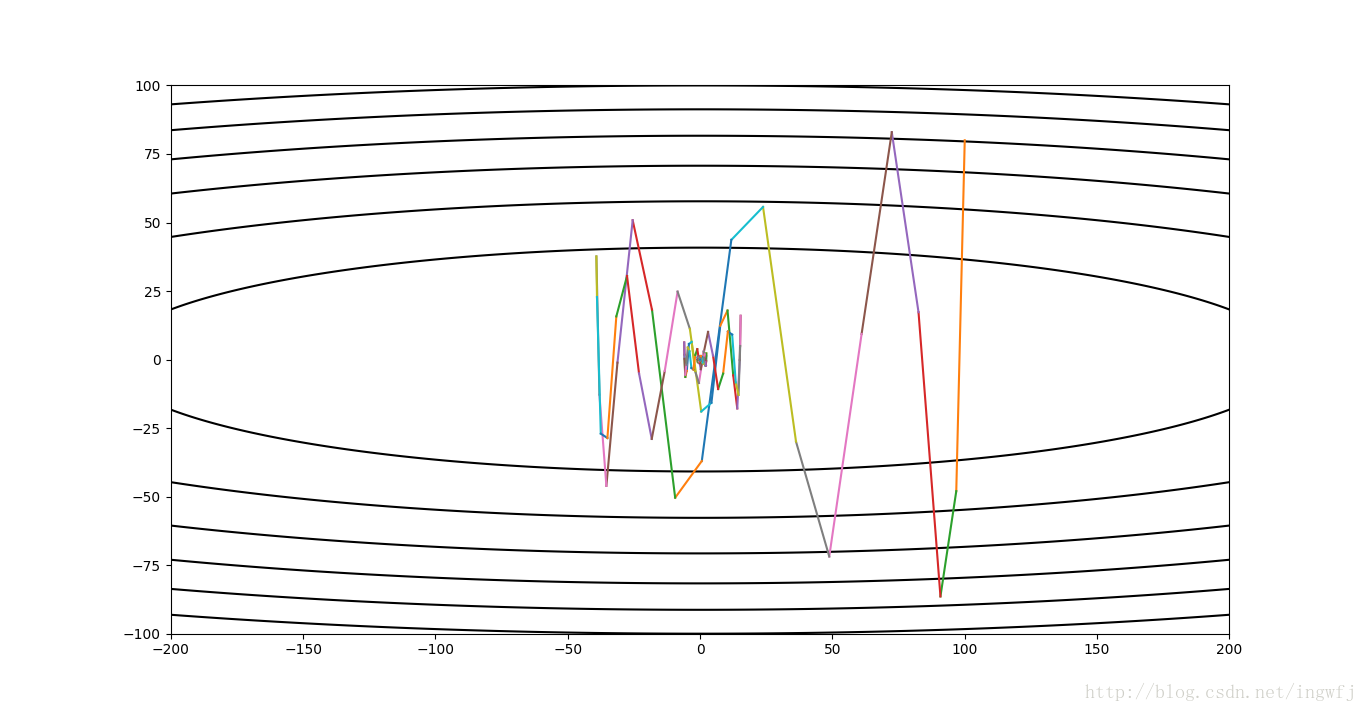
NAG,learning rate=0.003,迭代150步:
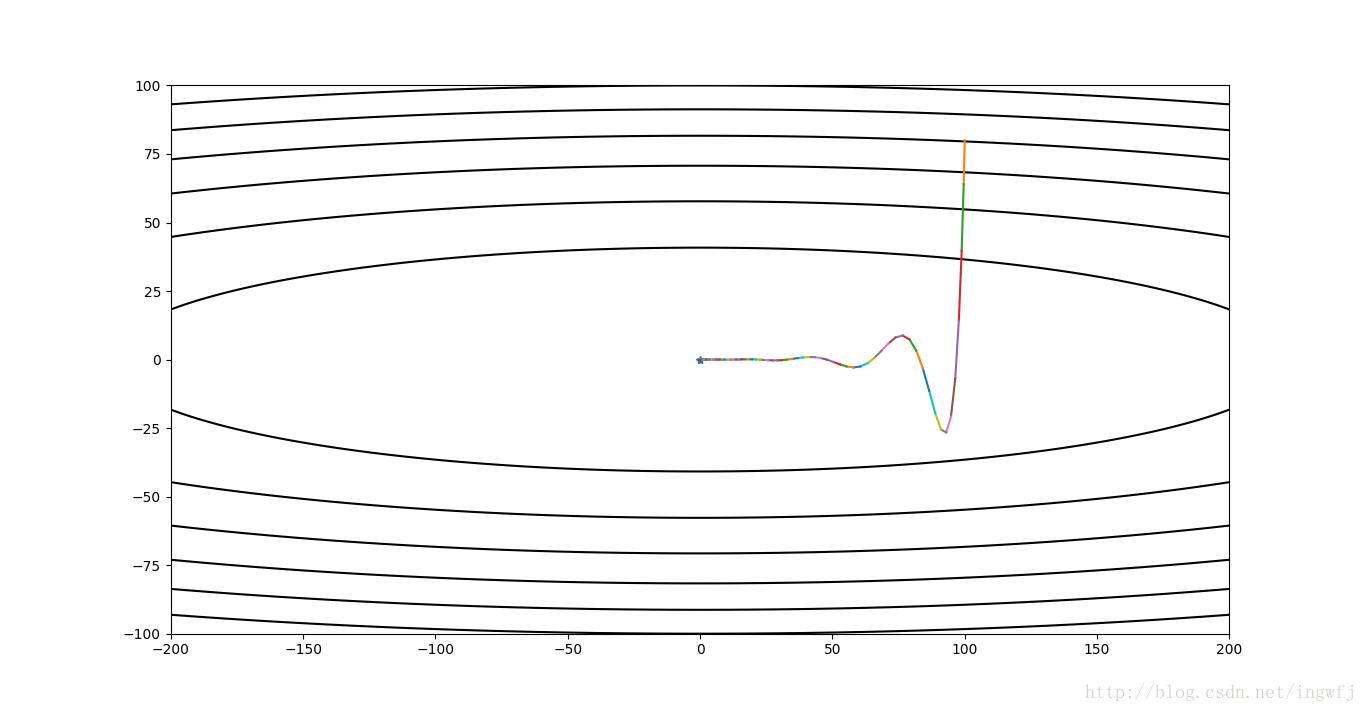
Adadelta,步长10,窗口w=4:
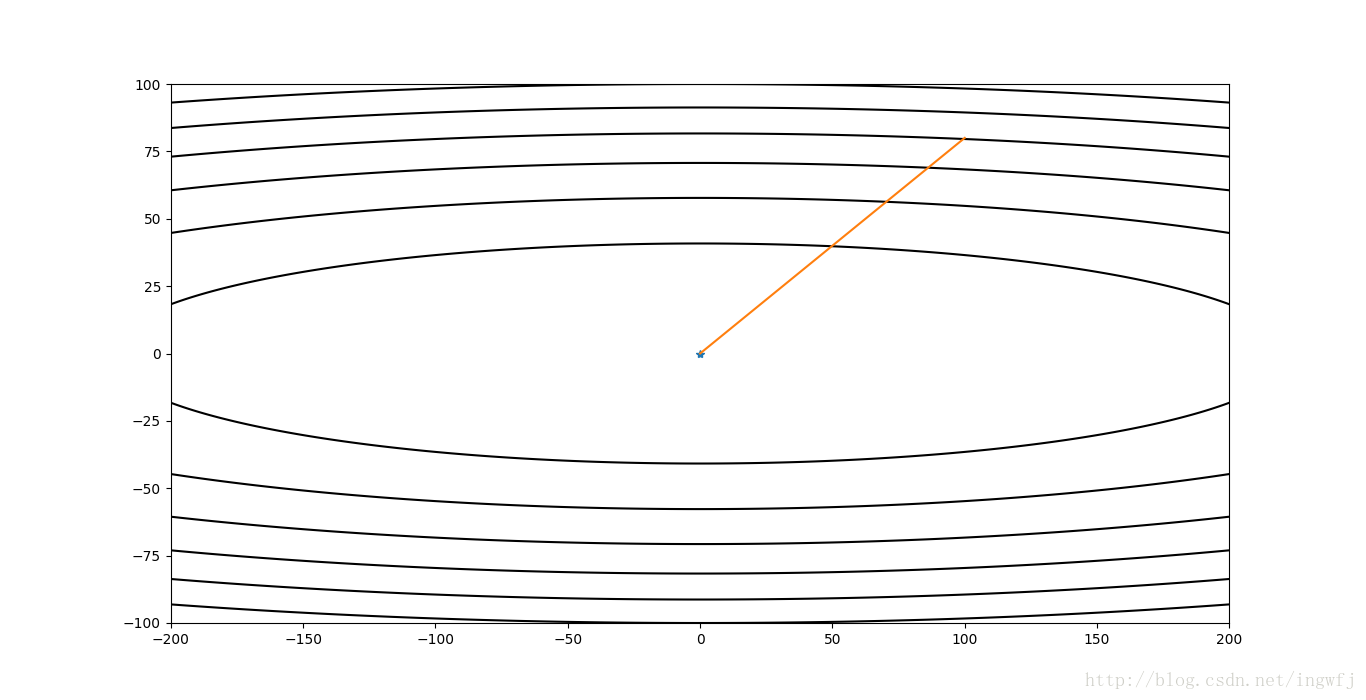
Adagrad,步长10:
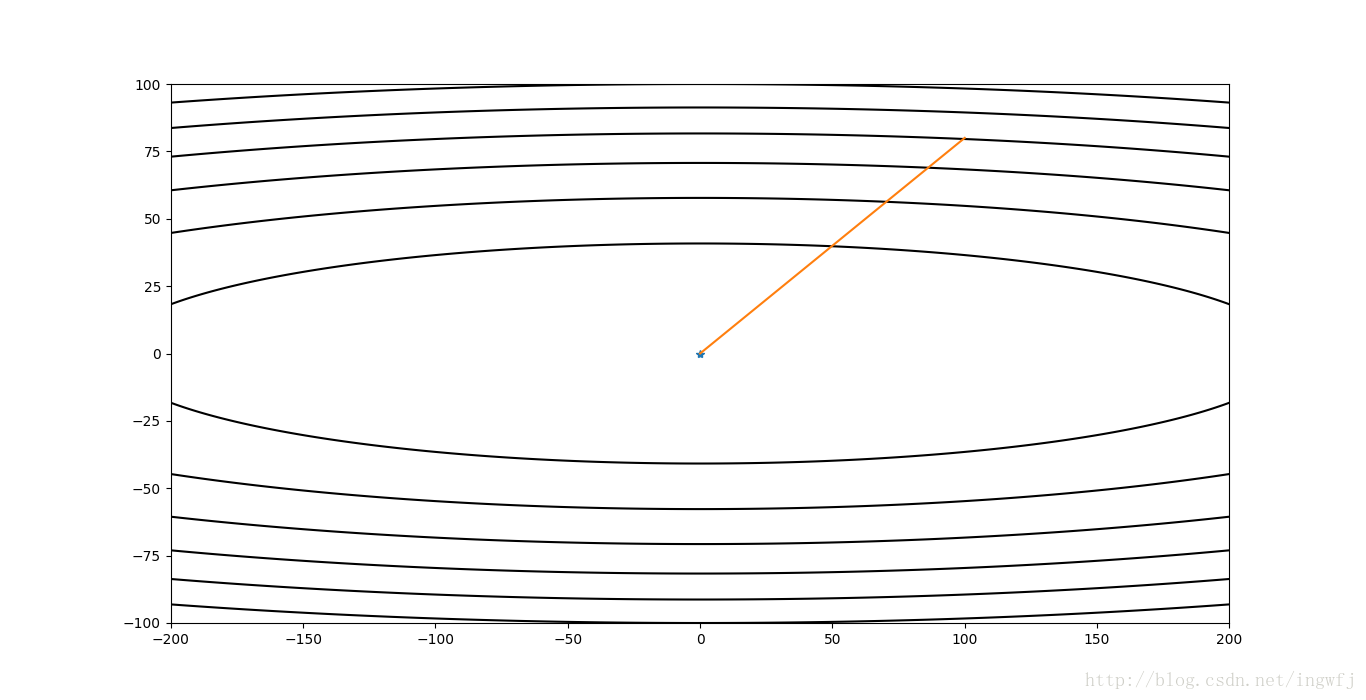
Adam,步长=1:
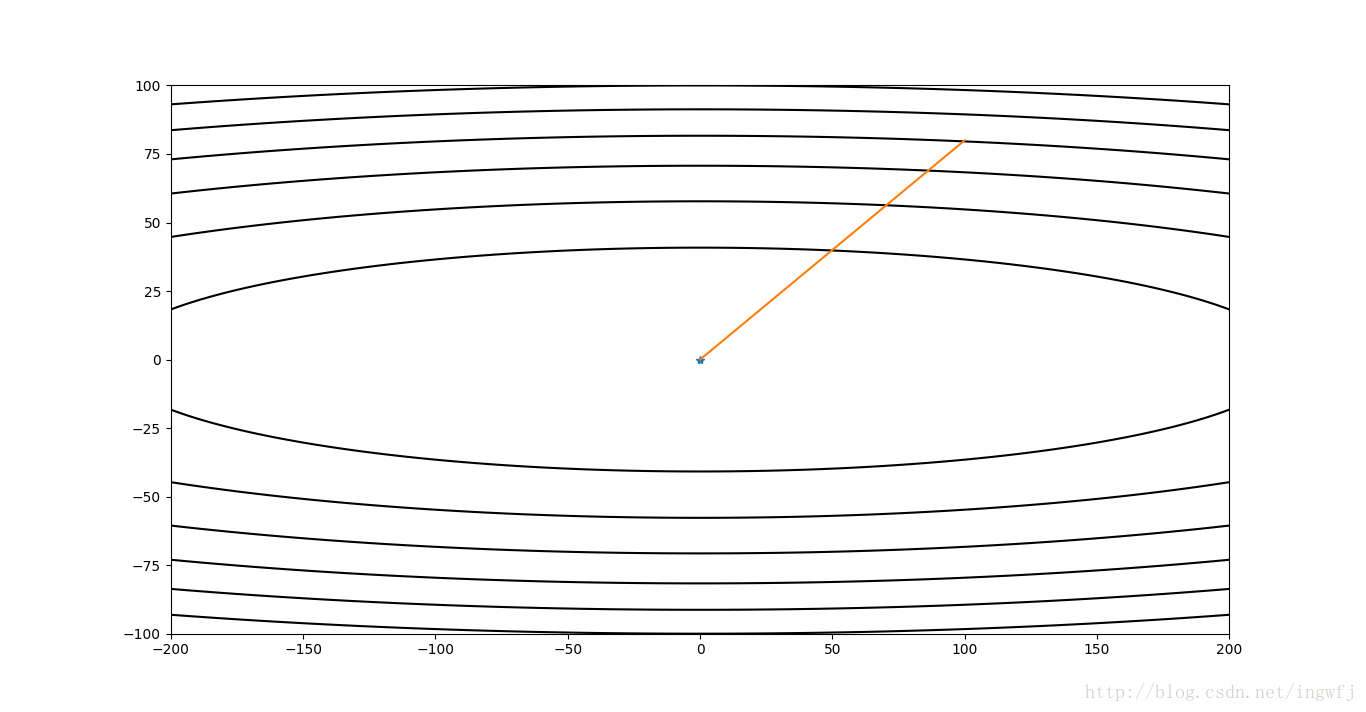

















 1213
1213

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









