







参考
Negative-Sampling Word-Embedding Method
从Word Embedding到Bert模型—自然语言处理中的预训练技术发展史
(十五)通俗易懂理解——Glove算法原理
理解GloVe模型(Global vectors for word representation)
NNLM
word embedding 最初其实是从NNLM开始的,虽然该模型的本质不是为了训练语言模型,word embedding 只是他的副产品。其架构为:
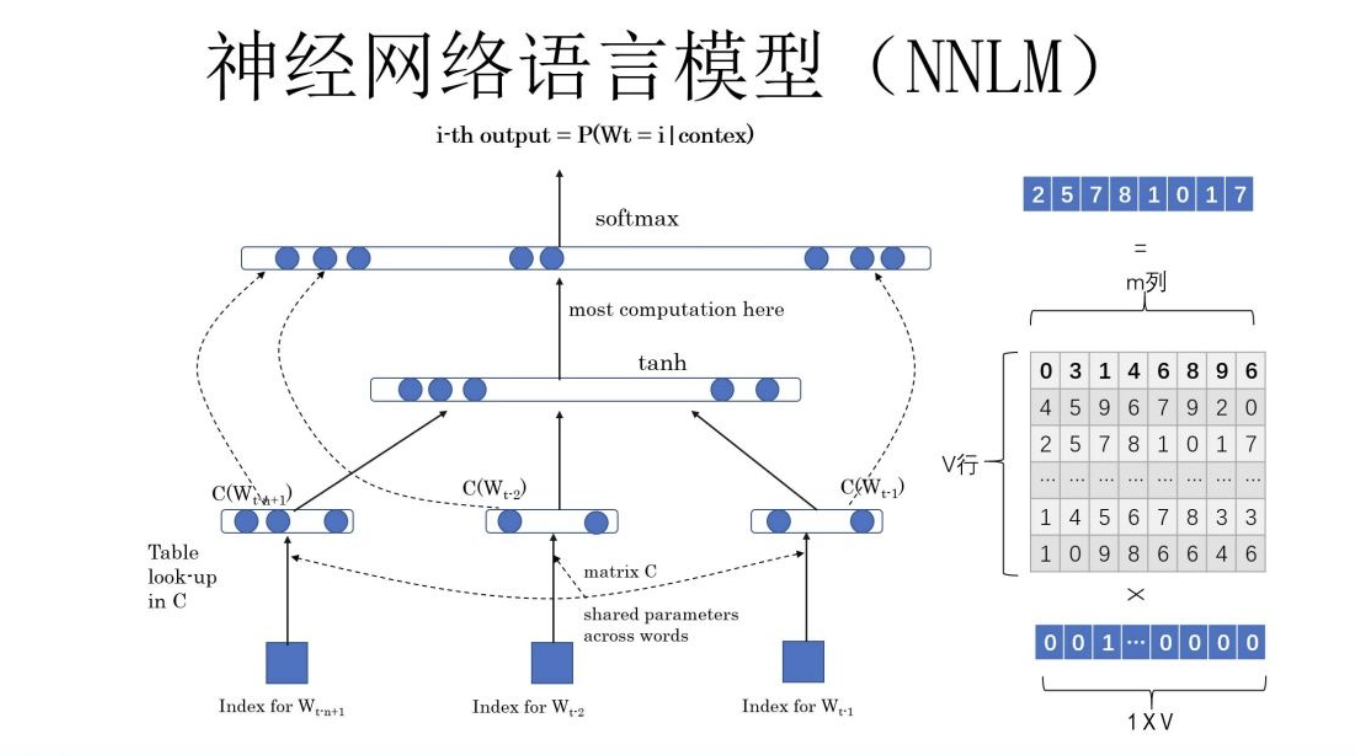
目标是用上文预测当前词,即:
p
(
c
u
r
r
e
n
t
∣
c
o
n
t
e
x
t
)
p(current|context)
p(current∣context)
word2vec
我在word2vec原理+代码完整的介绍了word2vec的原理。并介绍了word2vec的缺陷——多义词问题:
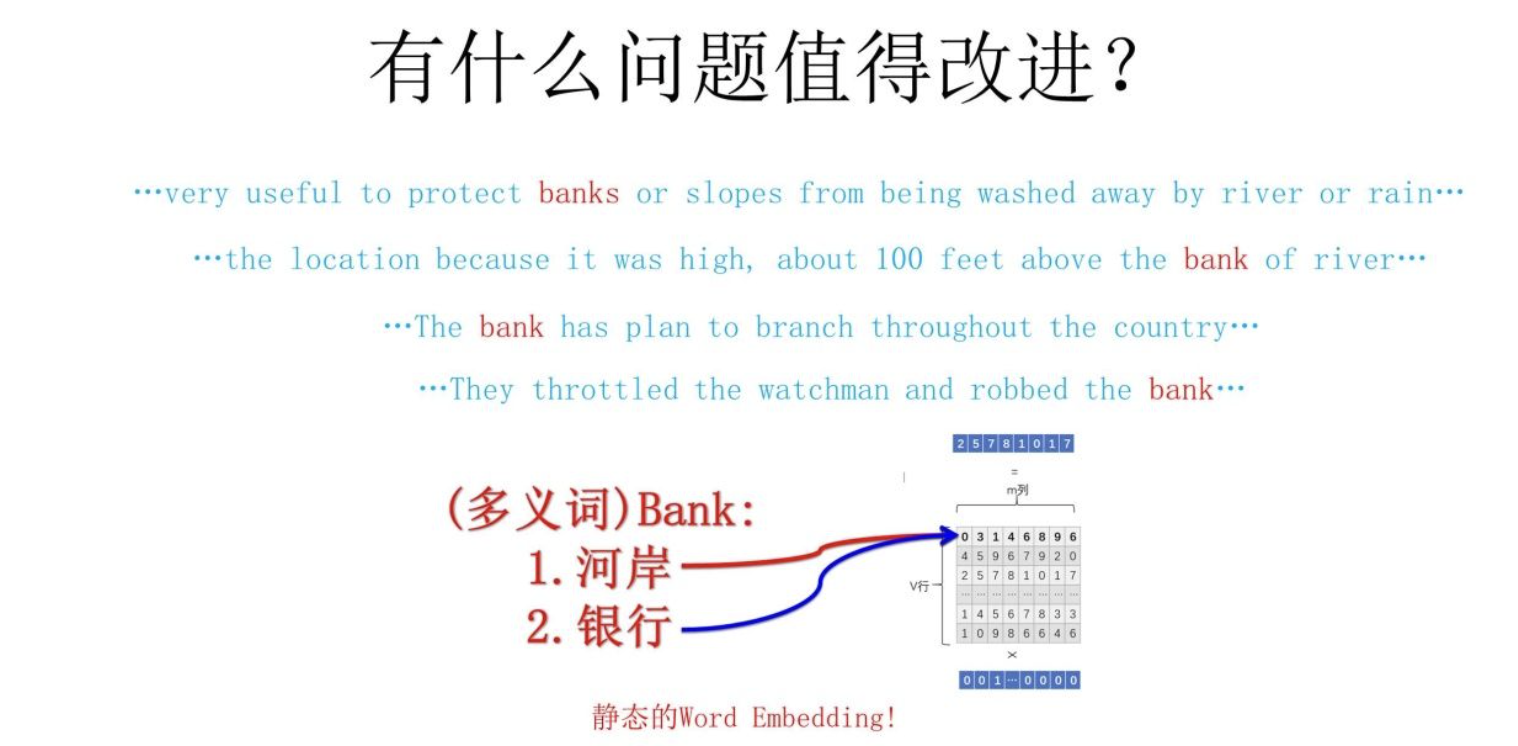
接下来介绍的Glove同样存在多义词问题。
Glove
Glove引入了Window based co-occurrence matrix(基于窗口的共现矩阵),令
X
i
j
X_{ij}
Xij表示word i 上下文中出现word j 的次数,
X
i
=
∑
j
X
i
j
X_i=\sum_j X_{ij}
Xi=∑jXij,定义:
P
i
,
k
=
X
i
,
k
X
i
P_{i,k}=\frac{X_{i,k}}{X_i}
Pi,k=XiXi,k
并令
r
a
d
i
o
i
,
j
,
k
=
P
i
,
k
P
j
,
k
radio_{i,j,k}=\frac{P_{i,k}}{P_{j,k}}
radioi,j,k=Pj,kPi,k,Glove的作者发现,radio的指标与单词相关度有关,具体关系如下:

那么,如果能有一个函数
g
g
g,使得
g
(
v
i
,
v
j
,
v
k
)
=
r
a
d
i
o
i
,
j
,
k
g(v_i,v_j,v_k)=radio_{i,j,k}
g(vi,vj,vk)=radioi,j,k,就可以通过embedding计算是否相关了。很自然的想法是使用代价函数
J
=
∑
i
,
j
,
k
(
P
i
,
k
P
j
,
k
−
g
(
v
i
,
v
j
,
v
k
)
)
2
J=\sum_{i,j,k} (\frac{P_{i,k}}{P_{j,k}}-g(v_i,v_j,v_k))^2
J=∑i,j,k(Pj,kPi,k−g(vi,vj,vk))2。但这样的计算方式,需要有三个单词,也就是说,时间复杂度是
O
(
N
3
)
O(N^3)
O(N3),因此,作者对其进行了改进:
- 考虑单词i与单词j的关系,所以 g ( v i , v j , v k ) g(v_i,v_j,v_k) g(vi,vj,vk)中要包含 v i − v j v_i-v_j vi−vj
- radio是标量,因此 g ( v i , v j , v k ) g(v_i,v_j,v_k) g(vi,vj,vk)中要包含 ( v i − v j ) T v k (v_i-v_j)^Tv_k (vi−vj)Tvk
- 使用指数函数,这样可以将减号变成除号,满足
P
i
,
k
P
j
,
k
\frac{P_{i,k}}{P_{j,k}}
Pj,kPi,k的形式,即
e
x
p
(
(
v
i
−
v
j
)
T
v
k
)
=
e
x
p
(
v
i
T
v
k
−
v
j
T
v
k
)
=
e
x
p
(
v
i
T
v
k
)
e
x
p
(
v
j
T
v
k
)
exp((v_i-v_j)^Tv_k)=exp(v_i^Tv_k-v_j^Tv_k)=\frac{exp(v_i^Tv_k)}{exp(v_j^Tv_k)}
exp((vi−vj)Tvk)=exp(viTvk−vjTvk)=exp(vjTvk)exp(viTvk),经过上述分析,我们最终有:
P i , k P j , k = e x p ( v i T v k ) e x p ( v j T v k ) \frac{P_{i,k}}{P_{j,k}}=\frac{exp(v_i^Tv_k)}{exp(v_j^Tv_k)} Pj,kPi,k=exp(vjTvk)exp(viTvk)
那么此时,只需要将 P i , k = e x p ( v i T v k ) P_{i,k}=exp(v_i^Tv_k) Pi,k=exp(viTvk)即可。
目标函数变为:
J
=
∑
i
,
j
[
l
o
g
(
P
i
,
j
)
−
v
i
T
v
j
]
2
J=\sum_{i,j} [log(P_{i,j})-v_i^Tv_j]^2
J=i,j∑[log(Pi,j)−viTvj]2
上面的式子已经很完美了,将时间复杂度从
O
(
N
3
)
O(N^3)
O(N3)转变为
O
(
N
2
)
O(N^2)
O(N2),但是他还是存在一些问题,
P
i
,
j
≠
P
j
,
i
P_{i,j}≠P_{j,i}
Pi,j=Pj,i,但是
v
i
T
v
j
=
v
j
T
v
i
v_i^Tv_j=v_j^Tv_i
viTvj=vjTvi,所以还需要做一些处理:
l
o
g
(
P
i
,
j
)
=
l
o
g
(
X
i
,
j
)
−
l
o
g
(
X
i
)
=
v
i
T
v
j
l
o
g
(
X
i
,
j
)
=
v
i
T
v
j
+
b
i
+
b
j
log(P_{i,j})=log(X_{i,j})-log(X_i)=v_i^Tv_j \\ log(X_{i,j})=v_i^Tv_j + b_i+b_j
log(Pi,j)=log(Xi,j)−log(Xi)=viTvjlog(Xi,j)=viTvj+bi+bj
并且,频率高的词,权重不应该过分加大,需要增加一个权重系数
f
(
x
)
f(x)
f(x):
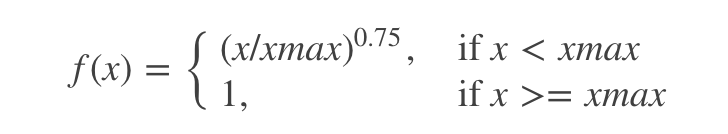
于是代价函数变为:
J
=
∑
i
,
j
f
(
X
i
,
j
)
[
v
i
T
v
j
+
b
i
+
b
j
−
l
o
g
(
X
i
,
j
)
]
2
J=\sum_{i,j} f(X_{i,j})[v_i^Tv_j+b_i+b_j-log(X_{i,j})]^2
J=i,j∑f(Xi,j)[viTvj+bi+bj−log(Xi,j)]2
但是Glove同样存在多义词问题,ELMO提供了一个优雅的解决方案。
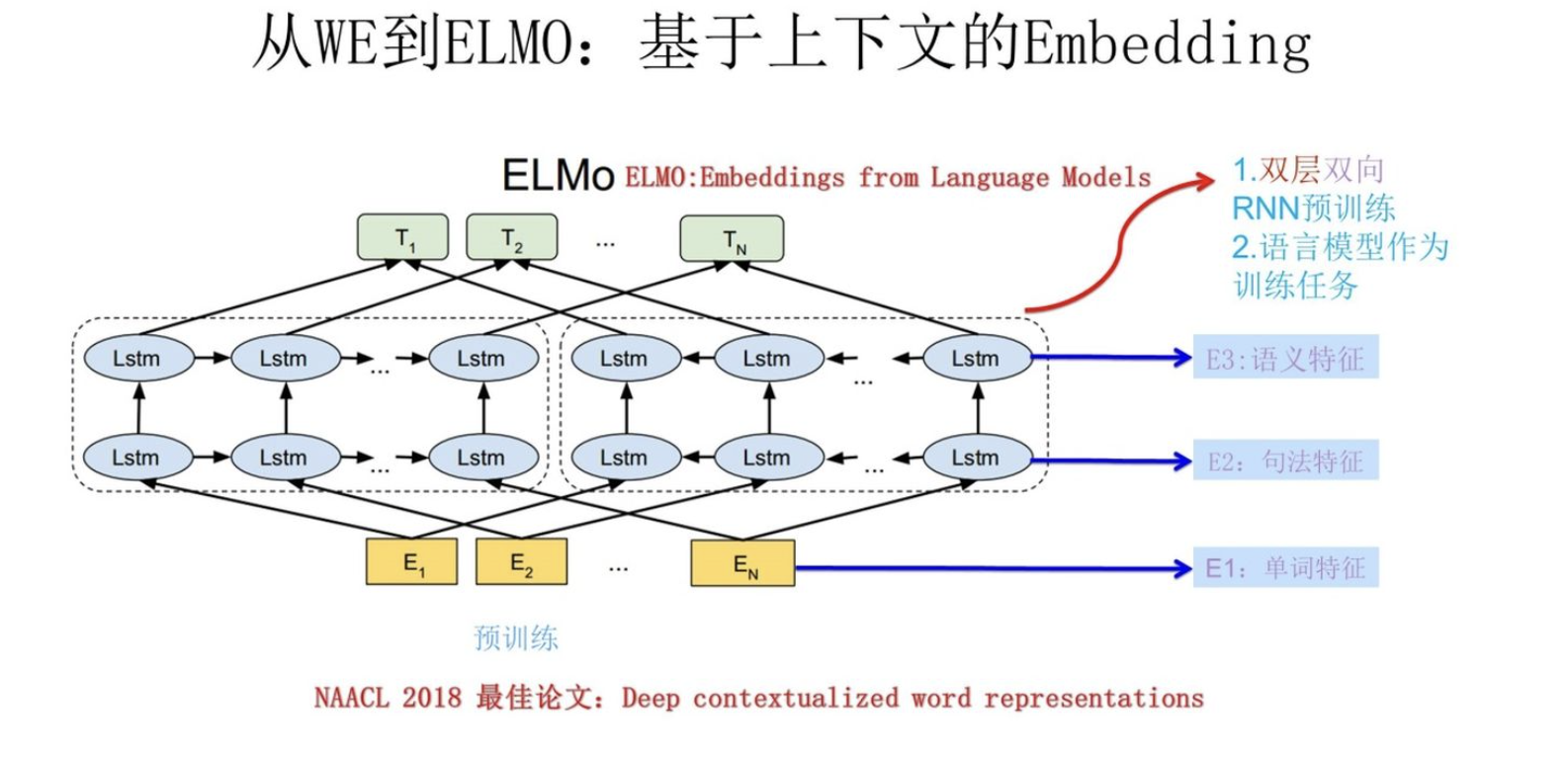
ELMO
论文:
Deep contextualized word representation
ELMO是“Embedding from Language Models”的简称。他的想法是利用上下文的信息调整单词的word embedding。主要做法是:
- 利用语言模型进行预训练,举个例子:【我 喜欢 吃 西瓜。】输入【我】预测【喜欢】,输入【喜欢】预测【吃】。
- 在下游任务中调整网络各层输出的embedding的权重,比如,下游任务可以是:QA任务,情感分类任务等等。
利用语言模型进行预训练
使用BILSTM,最大化下一个单词的概率,即:
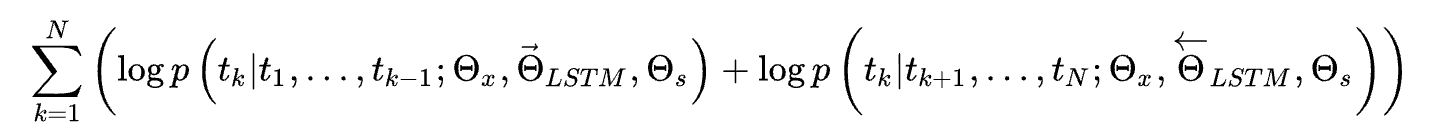
其中的
Θ
x
\Theta_x
Θx表示输入的word embedding,
Θ
s
\Theta_s
Θs表示softmax层的参数(预测词自然要加softmax层),他们是共享的。ELMO包含多个BiLSTM层,假设包含L个,那么会得到2L+1个表示:
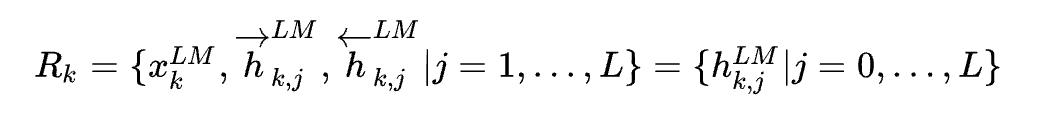
其中
x
k
L
M
x_k^{LM}
xkLM是对token直接编码的结果,后面的分量分别表示每一层向前或者向后的LSTM输出的结果。
下游任务如何使用:
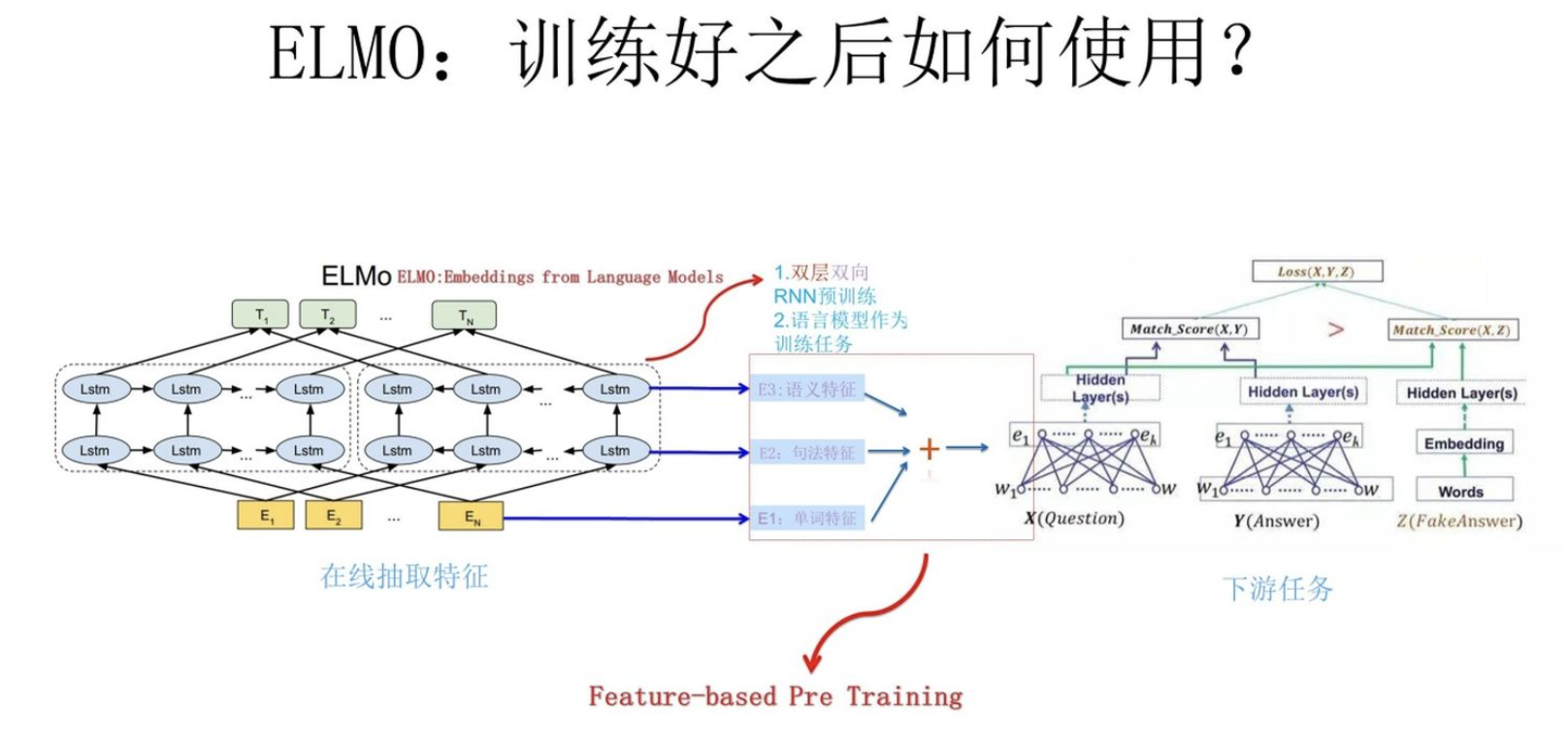
将2L+1个表示加权求和:
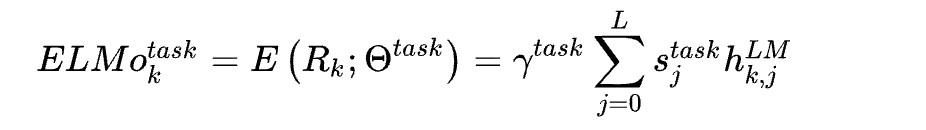
ELMO优缺点:
优点:
解决了多义词的问题

缺点:
- LSTM作为特征提取器的效果没有transformer好。
- ELMO 采取双向拼接这种融合特征的能力可能比 Bert 一体化的融合特征方式弱。
GPT
给出一个参考的链接:
GPT2是自回归语言模型,就是有一大堆句子,对句子中的每个单词,使用前文预测后文。举个例子:【我 喜欢 吃 西瓜。】输入【我】预测【喜欢】,输入【喜欢】预测【吃】。GPT2使用的是transformer作为其特征提取器,为了方便说明,这里把transformer的模型结构贴过来:
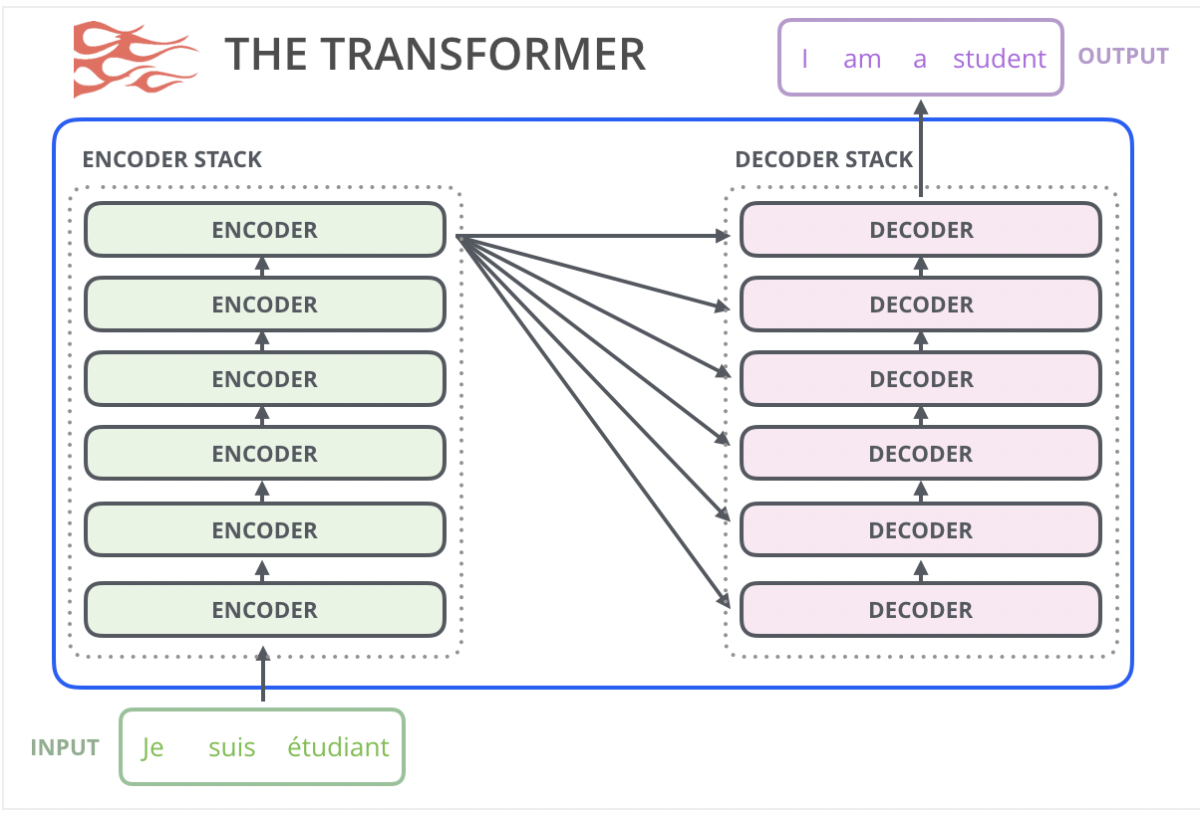
原始的Transformer模型是由 Encoder部分和Decoder部分组成的,它们都是由多层transformer堆叠而成的。原始Transformer的seq2seq结构很适合机器翻译,因为机器翻译正是将一个文本序列翻译为另一种语言的文本序列。
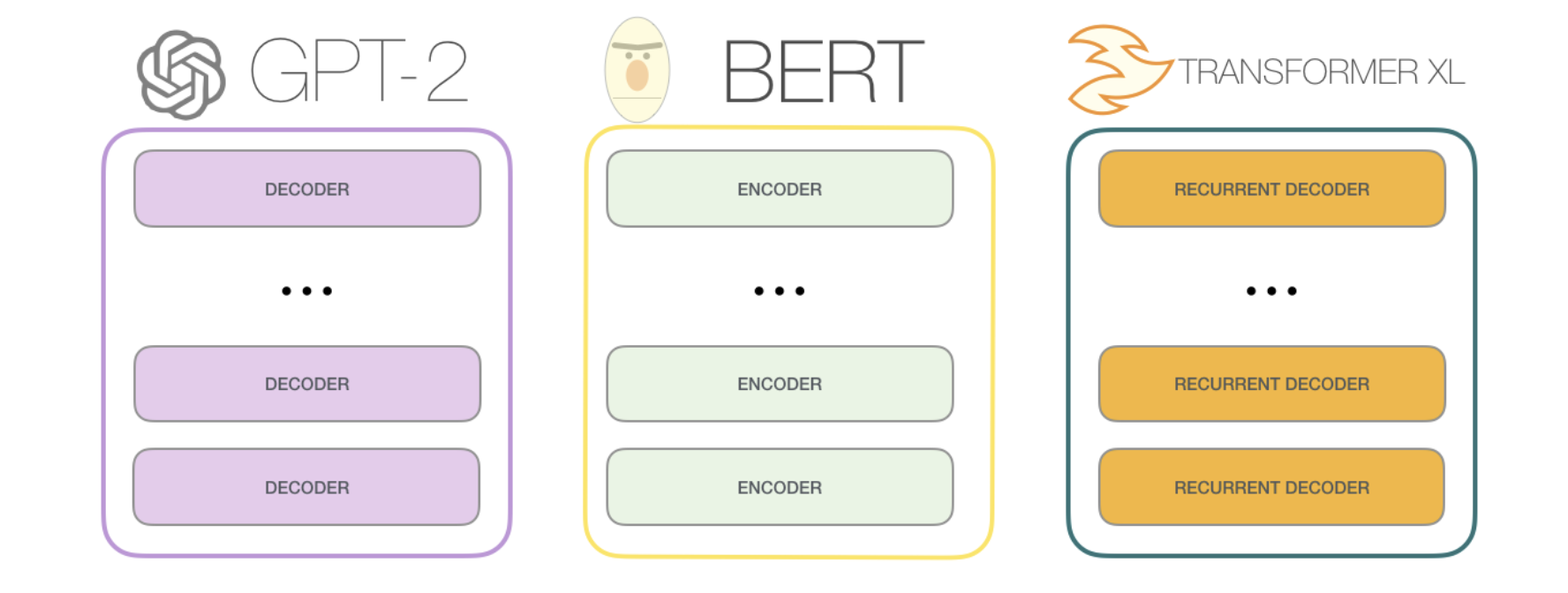
但如果要使用Transformer来解决语言模型任务,并不需要完整的Encoder部分和Decoder部分,于是在原始Transformer之后的许多研究工作中,人们尝试只使用Transformer Encoder或者Decoder,并且将它们堆得层数尽可能高,然后使用大量的训练语料和大量的计算资源(数十万美元用于训练这些模型)进行预训练。比如BERT只使用了Encoder部分进行masked language model(自编码)训练,GPT-2便是只使用了Decoder部分进行自回归(auto regressive)语言模型训练。
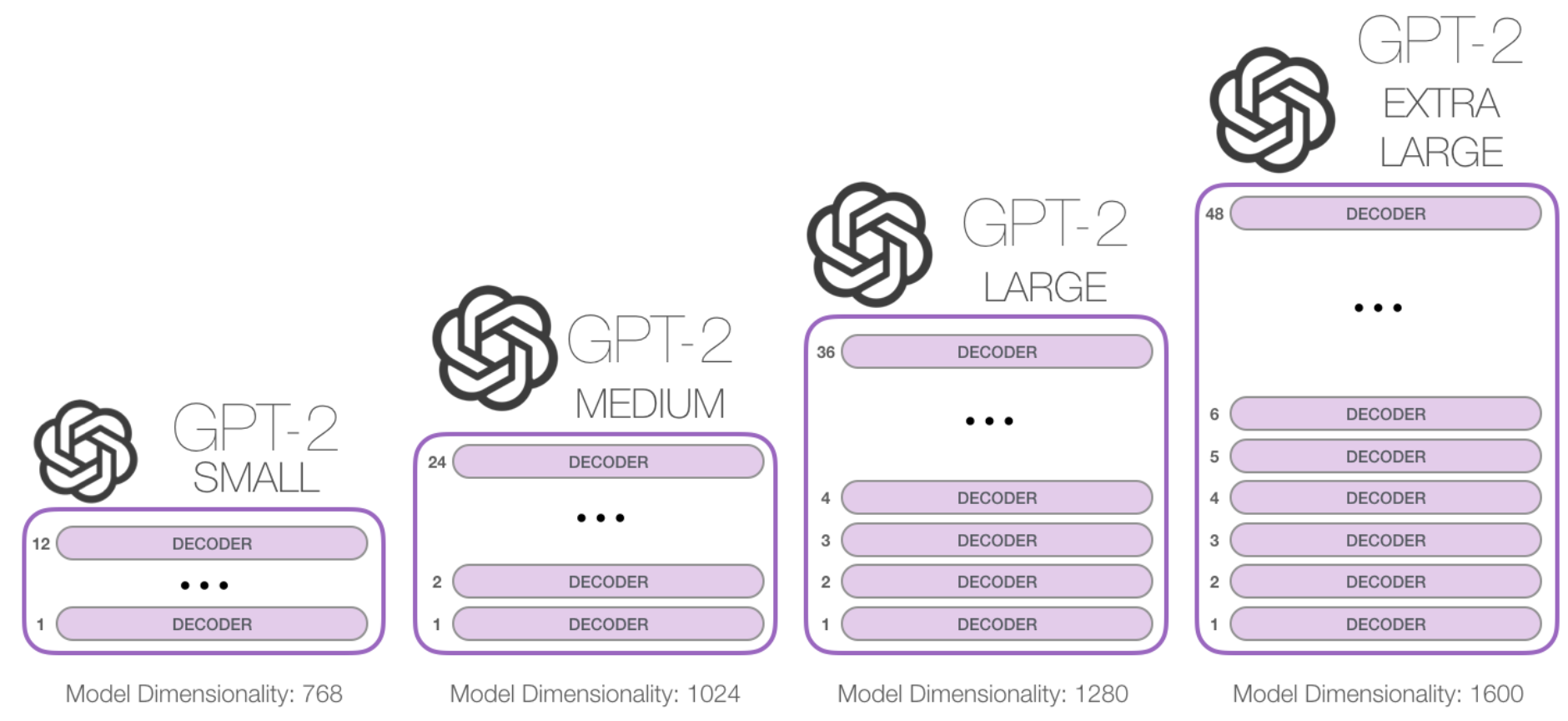
随着堆叠层数的增加,其参数量非常巨大:

既然GPT2使用的是transformer的decoder部分,那么就来复习一下transformer的decoder block:
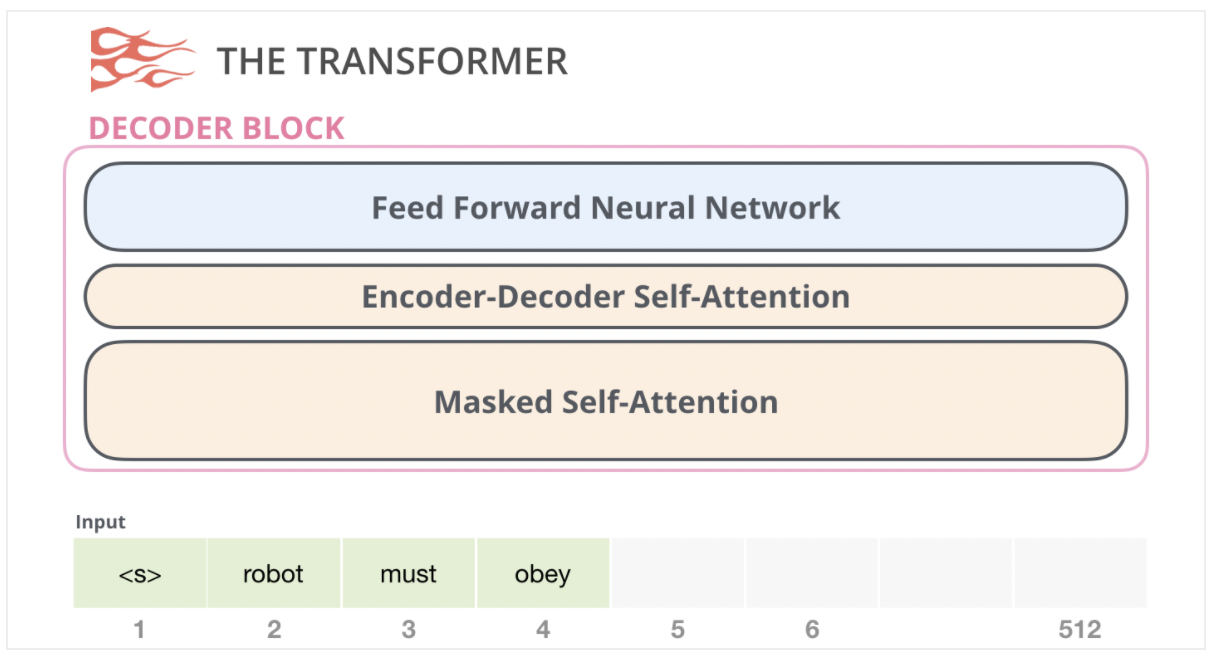
transformer的decoder与encoder不同,采用的是masked self-attention,这里的mask并非bert的[mask],而是在做self-attention运算时,会屏蔽掉未来单词的信息。
GPT2 概述
GPT2 能够处理1024个token,每个token沿着自己的路径经过所有的decoder层,GPT2的一个常用的用法是可以用来生成文本:
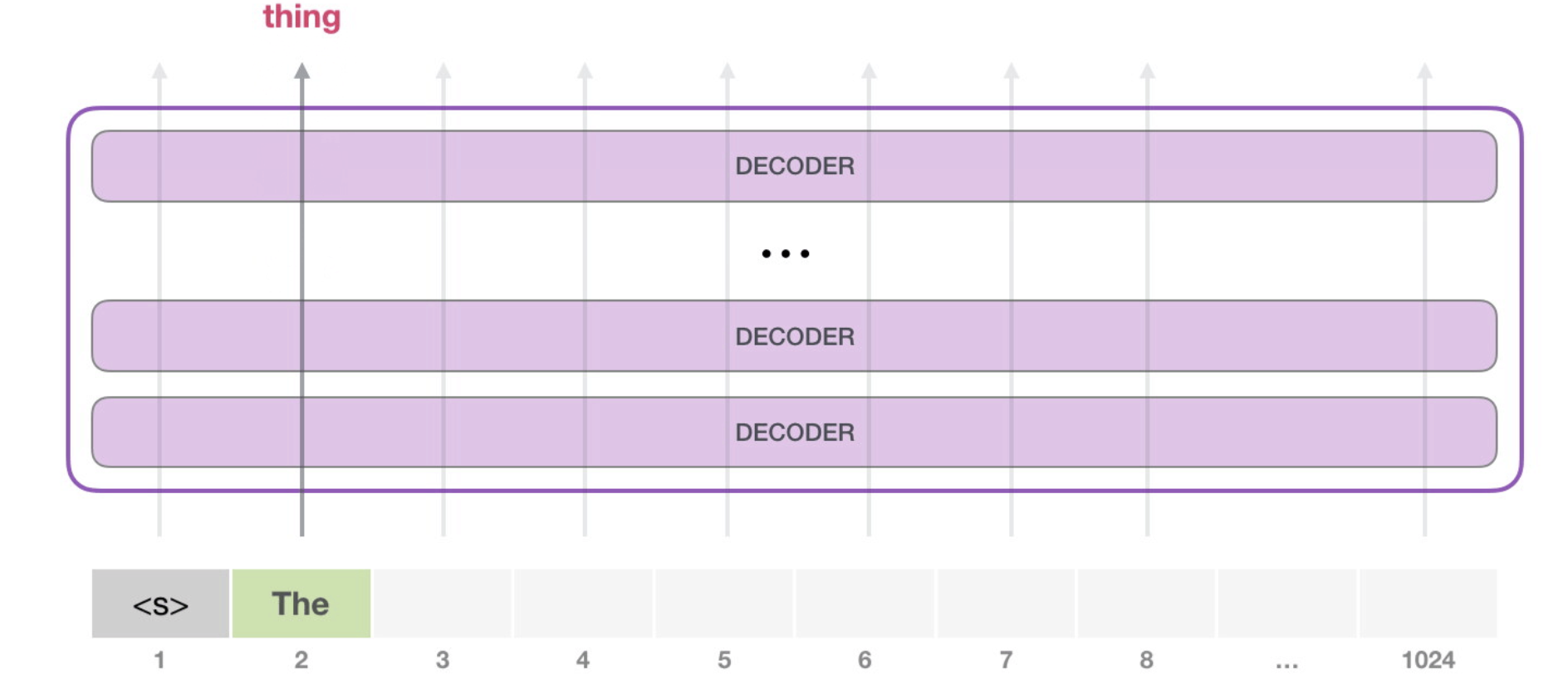
比如输入<s>和The,输出thing。这里需要注意的是,每次计算时都会保留之前计算过得token的编码的信息,这样就不会在接下来的计算中重复的计算。
GPT2详解
输入编码
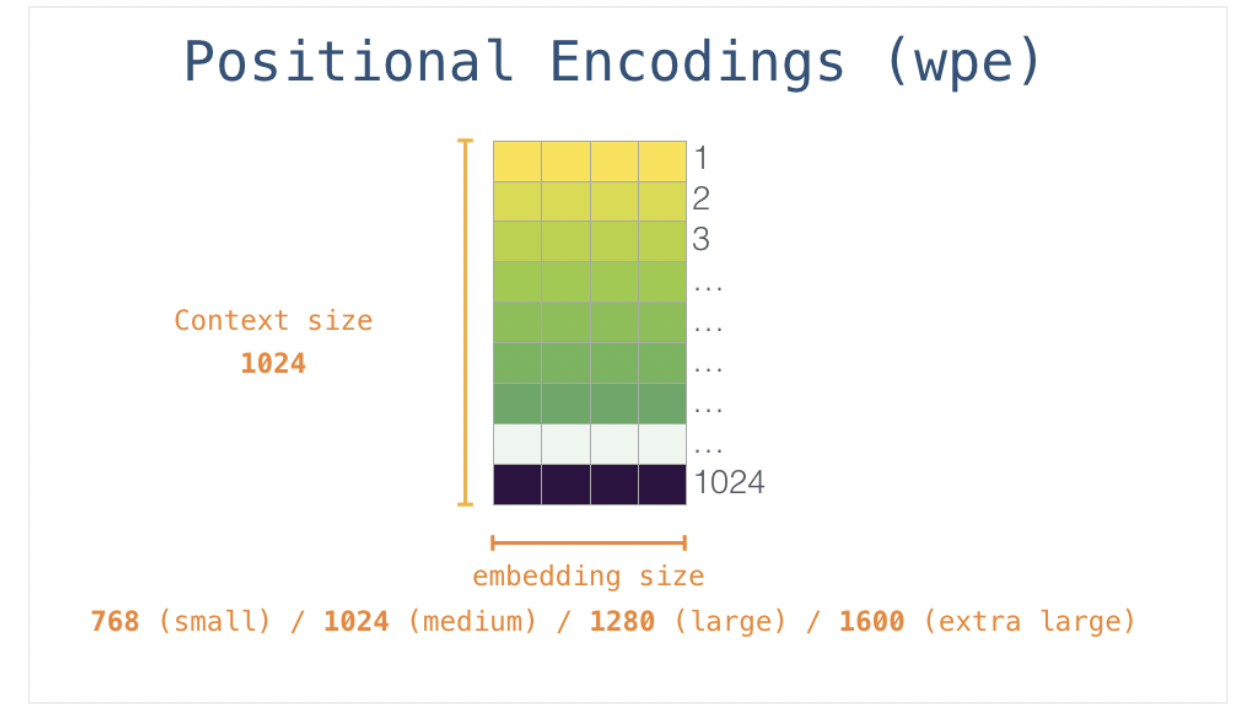
token embedding:

positional embedding:
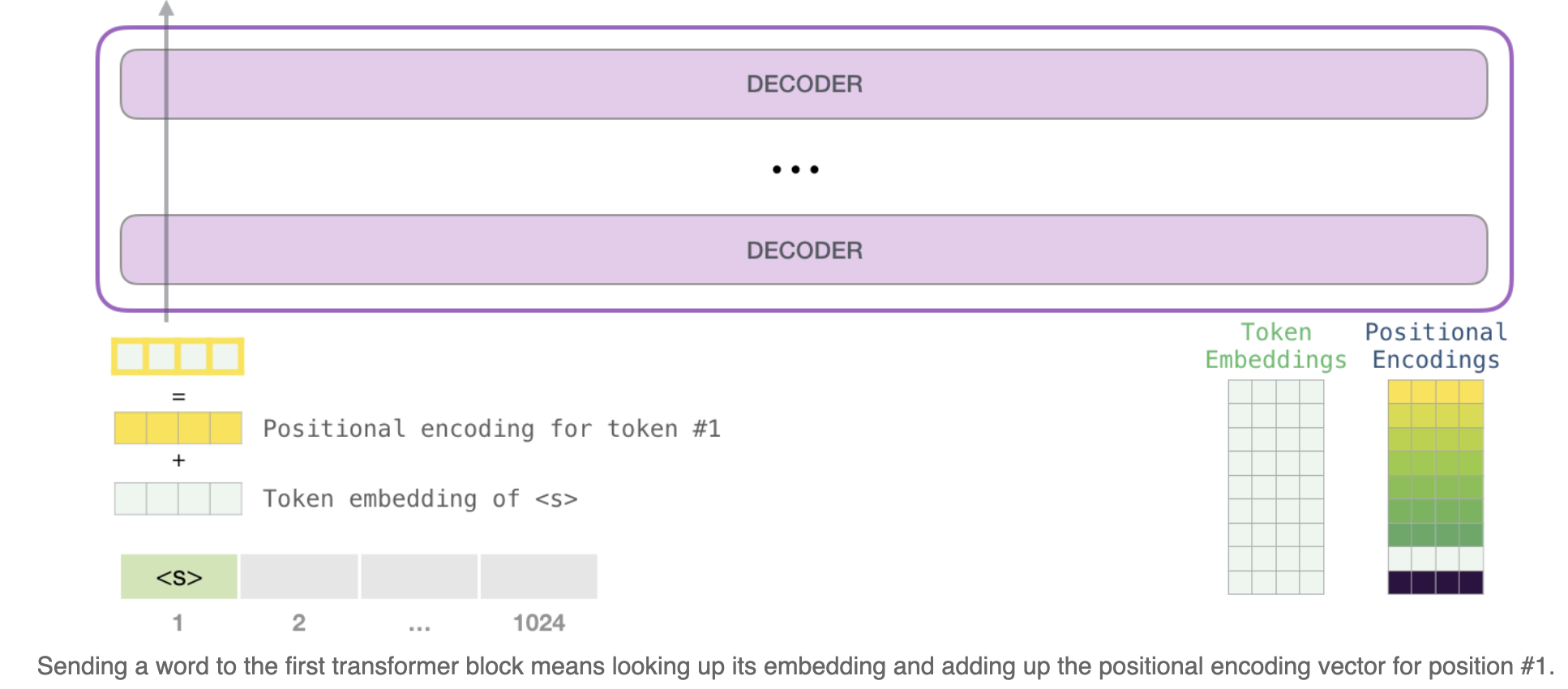
token+position:
多层Decoder:
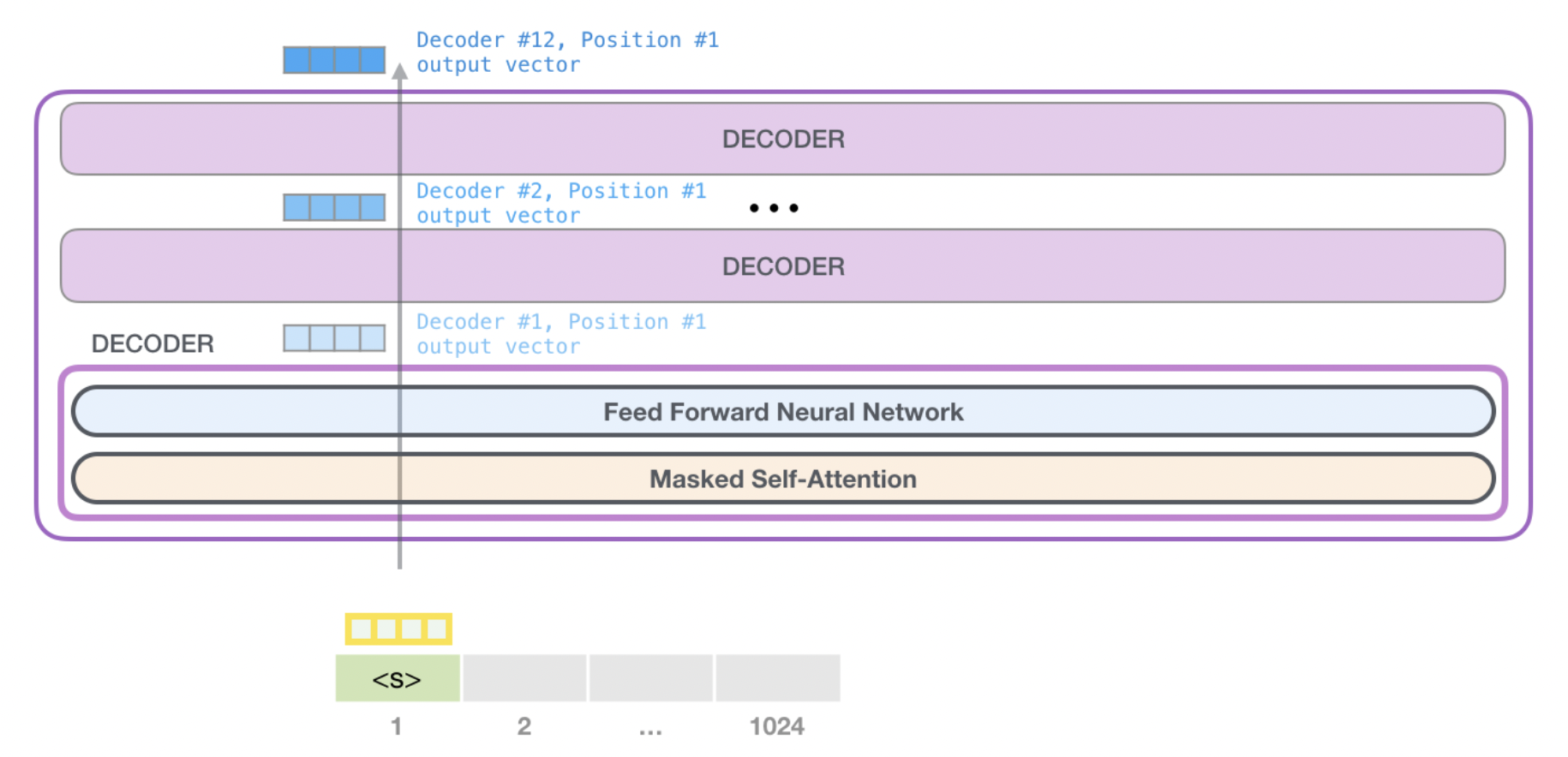
Decoder中的self-attention
A robot must obey the orders given it by human beings except where such orders would conflict with the First Law.
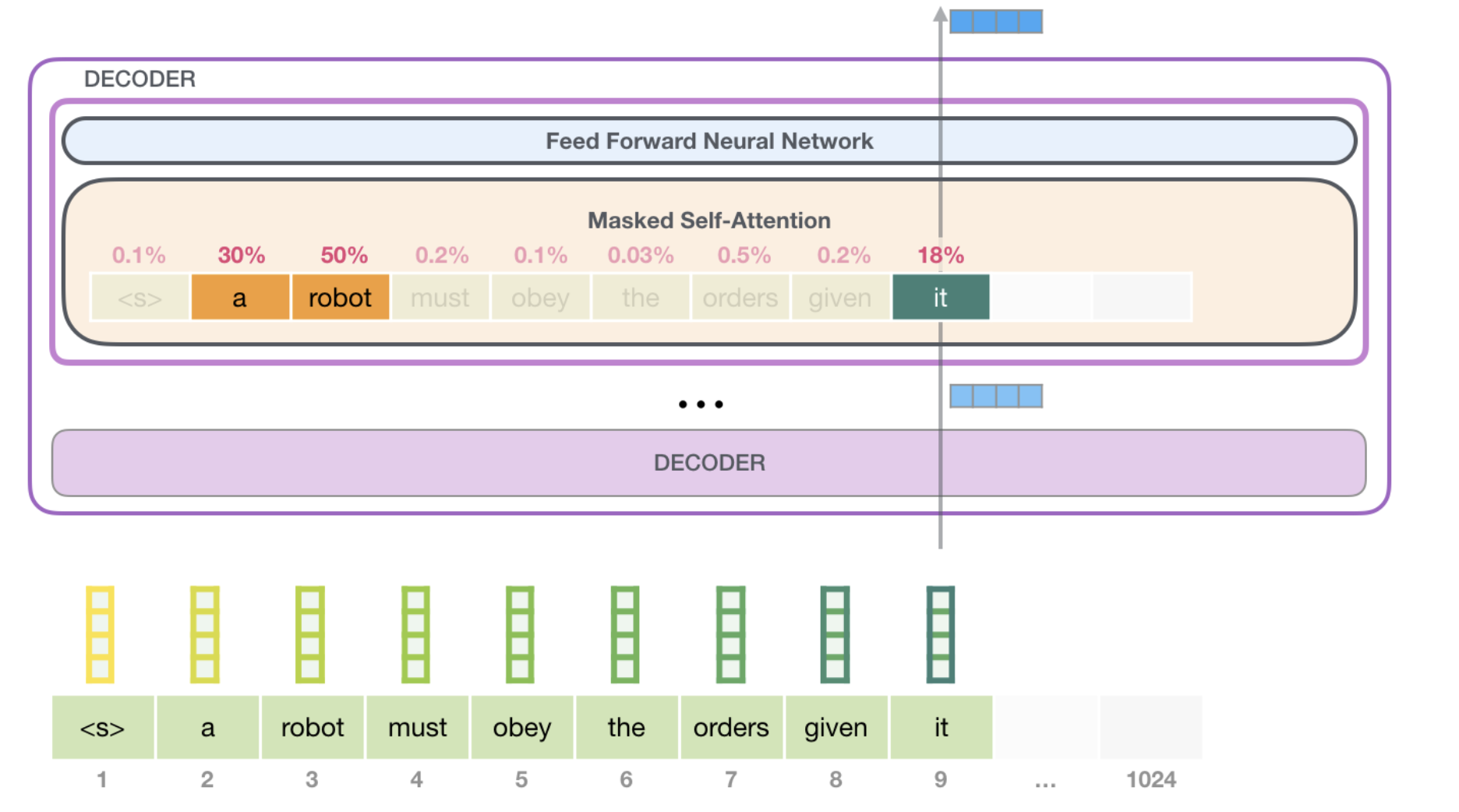
可以看出it和a,robot 之间的相关度比较高,说明it指代的是a robot。
self-attention的过程将在tansformer代码+原理中讲述。
model output
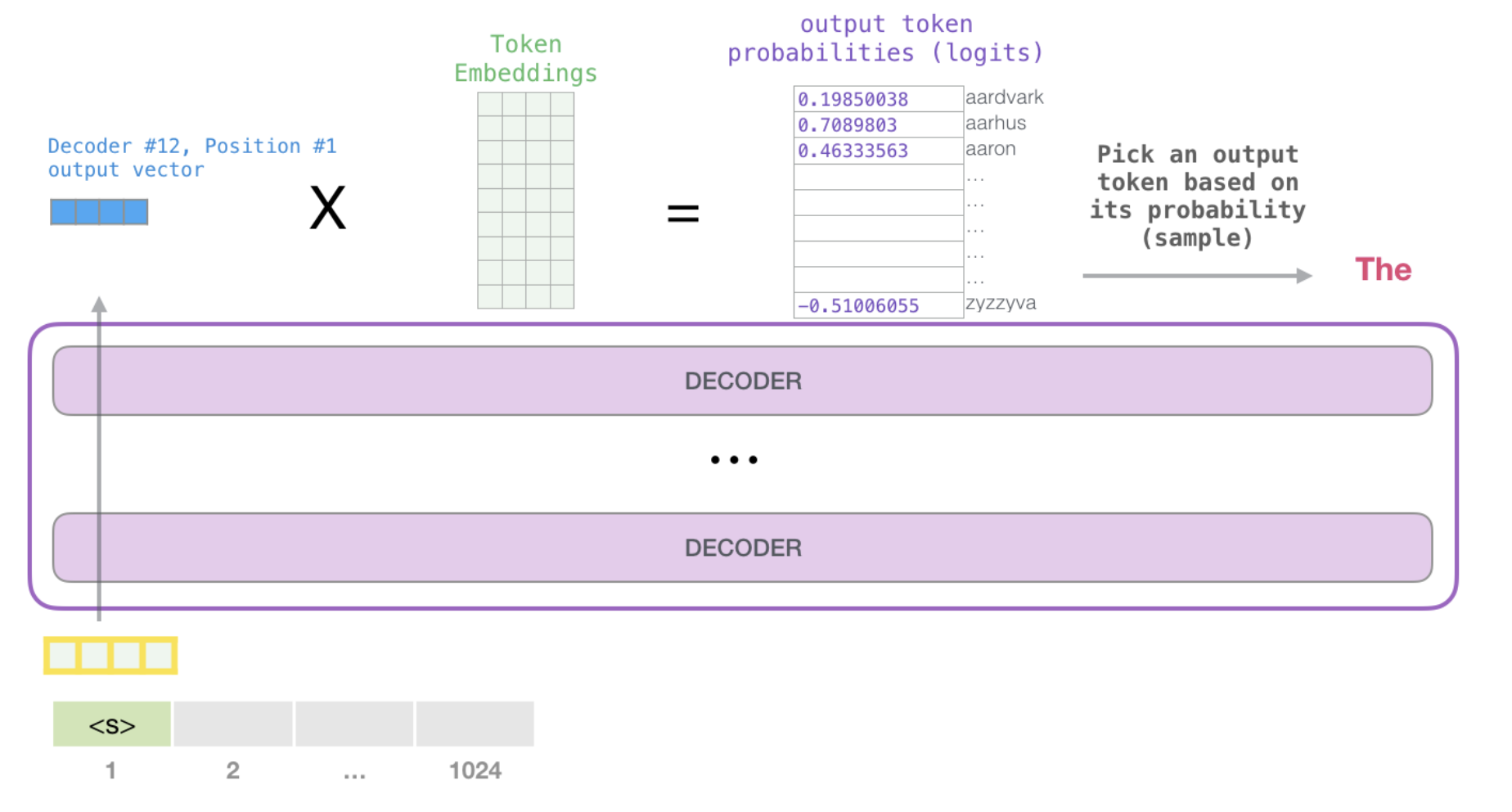
当模型顶部的Decoder层产生输出向量时(这个向量是经过 Self Attention 层和神经网络层得到的),模型会将这个向量乘以一个巨大的嵌入矩阵(vocab size x embedding size)来计算该向量和所有单词embedding向量的相关得分。这个相乘的结果,被解释为模型词汇表中每个词的分数,经过softmax之后被转换成概率。我们可以选择最高分数的 token(top_k=1),也可以同时考虑其他词(top k)。假设每个位置输出k个token,假设总共输出n个token,那么基于n个单词的联合概率选择的输出序列会更好。这样,模型就完成了一次迭代,输出一个单词。模型会继续迭代,直到所有的单词都已经生成,或者直到输出了表示句子末尾的 token。
GPT2 训练好怎么使用
把下游任务的网络结构改造成和GPT的网络结构一样。然后,在做下游任务的时候,利用第一步预训练好的参数初始化GPT的网络结构,这样通过预训练学到的语言学知识就被引入到你手头的任务里来。再次,你可以用手头的任务去训练这个网络,对网络参数进行Fine-tuning,使得这个网络更适合解决手头的问题。
面对花式的NLP问题,如何改造才能接近GPT的网络架构?

GPT论文给了一个改造施工图如上,其实也很简单:
- 对于分类问题,不用怎么动,加上一个起始和终结符号即可;
- 对于句子关系判断问题,比如Entailment,两个句子中间再加个分隔符即可;对文本相似性判断问题,把两个句子顺序颠倒下做出两个输入即可,这是为了告诉模型句子顺序不重要;
- 对于多项选择问题,则多路输入,每一路把文章和答案选项拼接作为输入即可。
从上图可看出,这种改造还是很方便的,不同任务只需要在输入部分施工即可。
BERT
BERT论文为:
Bert:Bidirectional Encoder Representations from Transformers
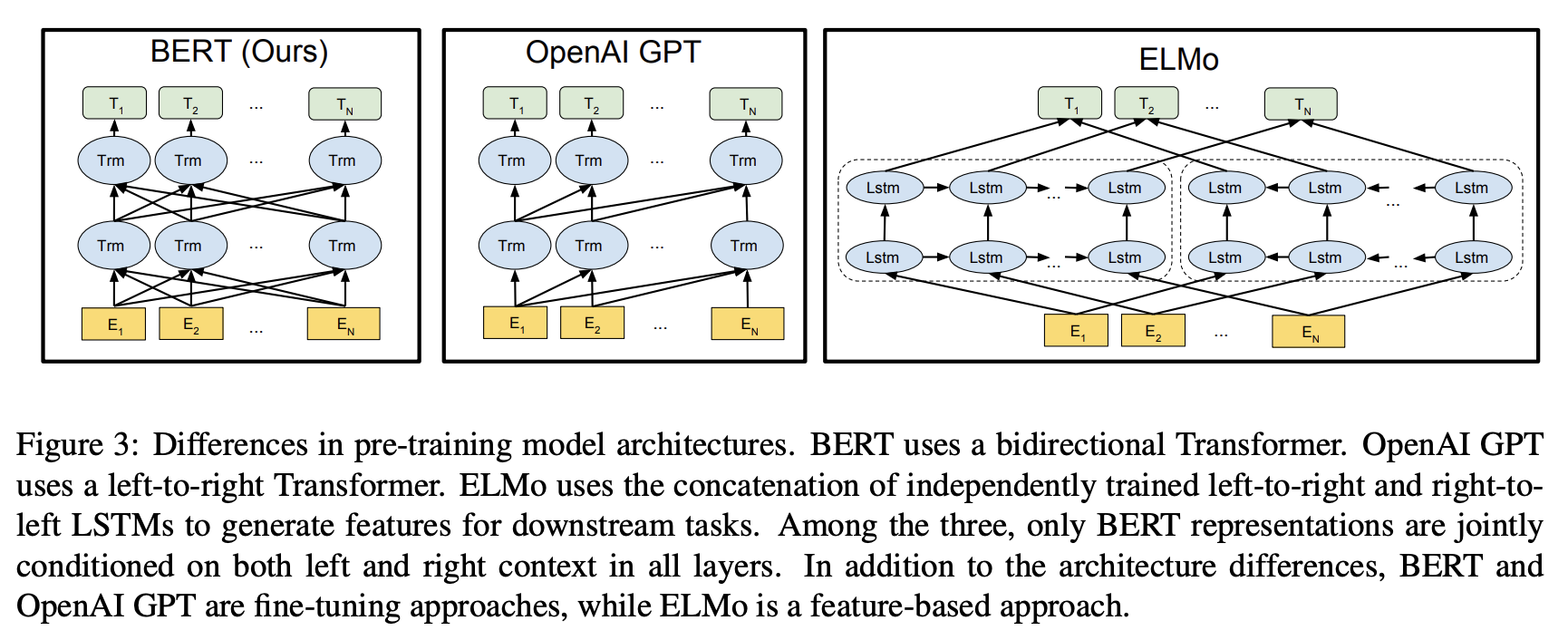
与GPT不同,bert采用的是transformer的encoder部分,且用到了句子上下文的信息(GPT只用了一个方向的信息)。
BERT如何做下游任务的改造
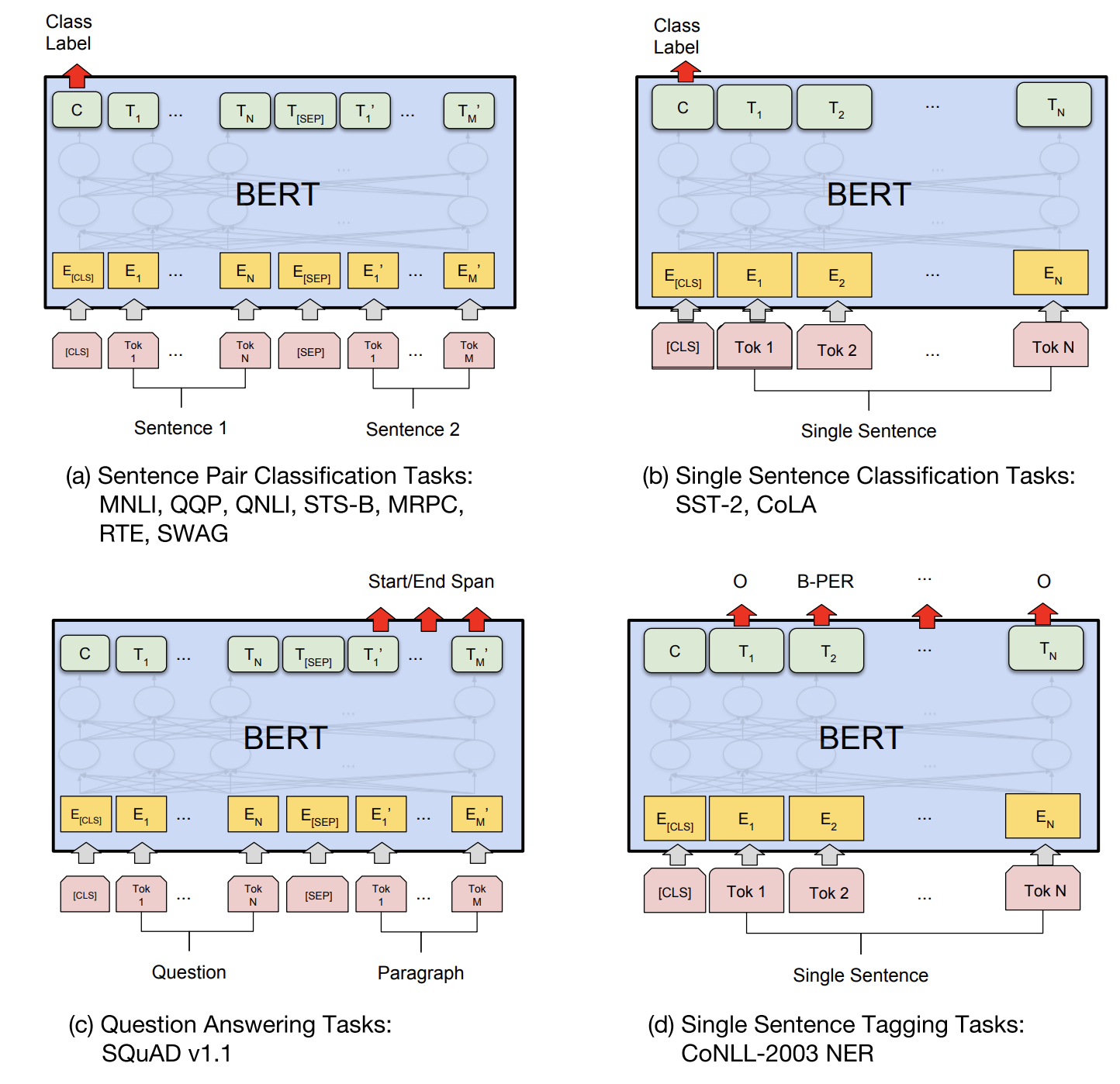
- a) 句子关系类任务:和GPT类似,加上一个起始和终结符号,句子之间加个分隔符即可。对于输出来说,把第一个起始符号对应的Transformer最后一层位置上面串接一个softmax分类层即可。
- b) 分类任务: 只需要增加起始和终结符号,输出部分在[CLS]上加一个softmax。
- c) QA任务: 输入为[cls]question[sep]document,输出是每个位置有两个softmax,分为输出start和end的概率。
- d) 序列标注任务: 与分类任务不同的只是在每个单词位置加对应的分类层。
BERT 如何训练
BERT主要是训练两个任务:
- mask prediction:输入[CLS]我 [mask] 中 [mask] 天 安 门[SEP],预测句子的[mask],多分类问题
随机选择语料中15%的单词,把它抠掉,也就是用[Mask]掩码代替原始单词,然后要求模型去正确预测被抠掉的单词。但是这里有个问题:训练过程大量看到[mask]标记,但是真正后面用的时候是不会有这个标记的,这会引导模型认为输出是针对[mask]这个标记的,但是实际使用又见不到这个标记,这自然会有问题。为了避免这个问题,Bert改造了一下,15%的被上天选中要执行[mask]替身这项光荣任务的单词中,只有80%真正被替换成[mask]标记,10%被狸猫换太子随机替换成另外一个单词,10%情况这个单词还待在原地不做改动。这就是Masked双向语音模型的具体做法。
- next sentence prediction:输入[CLS]a[SEP]b[SEP],预测b是否为a的下一句,即二分类问题;
指的是做语言模型预训练的时候,分两种情况选择两个句子,一种是选择语料中真正顺序相连的两个句子;另外一种是第二个句子从语料库中抛色子,随机选择一个拼到第一个句子后面。我们要求模型除了做上述的Masked语言模型任务外,附带再做个句子关系预测,判断第二个句子是不是真的是第一个句子的后续句子。之所以这么做,是考虑到很多NLP任务是句子关系判断任务,单词预测粒度的训练到不了句子关系这个层级,增加这个任务有助于下游句子关系判断任务。所以可以看到,它的预训练是个多任务过程。这也是Bert的一个创新。
因为bert及其变体有很多,在后面的博客中会更加详细的介绍bert系列。
















 679
679











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









