









线性回归
线性回归,顾名思义,是使用属性之间的线性组合以预测输出,引入常量项
x
0
=
1
x_0=1
x0=1 后,其数学公式如下:
y
=
∑
i
=
0
N
w
i
x
i
y = \sum_{i=0}^N w_i x_i
y=i=0∑Nwixi
一般来说,我们使用均方误差作为其损失函数,其数学公式如下:
L
=
∑
k
=
1
(
w
⃗
x
k
−
y
k
)
2
L=\sum_{k=1} (\vec w x_k-y_k)^2
L=k=1∑(wxk−yk)2
为什么要采用均方误差作为其损失函数呢?我们从概率论的角度探讨这个问题。
假设线性回归可以完美匹配理想样本点的分布,而真实的样本数据是理想样本点与噪声叠加的结果,假设噪声满足正态分布
N
(
0
,
σ
2
)
N(0,\sigma^2)
N(0,σ2),那么我们可以根据正态分布的概率密度函数和最大似然可得
p
(
w
1
,
⋯
,
w
k
,
⋯
∣
w
)
=
∏
k
1
2
π
σ
e
x
p
[
−
1
2
σ
2
(
y
k
−
w
x
k
)
2
]
p(w_1,\cdots,w_k,\cdots|w)=\prod_k \frac{1}{\sqrt{2\pi} \sigma}exp[-\frac{1}{2\sigma^2}(y_k-wx_k)^2]
p(w1,⋯,wk,⋯∣w)=k∏2πσ1exp[−2σ21(yk−wxk)2]
可见,这与均方误差的结果不谋而合。因此,如果噪声满足正态分布,那么几何意义出发的最小二乘法与从概率意义出发的最大似然估计是等价的。
LASSO回归
LASSO 回归的全称是“最小绝对缩减和选择算子”(Least Absolute Shrinkage and Selection Operator),LASSO 回归选择了待求解参数的一范数项作为惩罚项,即 ∣ ∣ w ∣ ∣ 1 ||w||_1 ∣∣w∣∣1。LASSO 回归的特点在于稀疏性的引入,LASSO 回归是在 w i w_i wi 满足拉普拉斯先验分布的条件下,用最大后验概率进行估计得到的结果。下面我们来证明:
拉普拉斯先验分布的概率密度函数为:
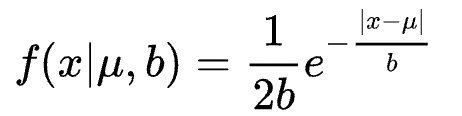
其中,
μ
\mu
μ是位置参数,
b
b
b是尺度参数。
假设,参数
w
∼
l
a
p
l
a
c
e
(
μ
,
b
)
w \sim laplace(\mu,b)
w∼laplace(μ,b),那么根据MAP我们有:

由此得证。
岭回归
岭回归方法又被称为“参数衰减”,岭回归实现正则化的方式是在原始均方误差项的基础上添加一个待求解参数的二范数项,即 ∣ ∣ w ∣ ∣ 2 ||w||_2 ∣∣w∣∣2。二范数惩罚项的作用在于优先选择范数较小的 w,这相当于在最小均方误差之外额外添加了一重关于最优解特性的约束条件,将最优解限制在高维空间内的一个球里。岭回归的作用相当于在原始最小二乘的结果上做了缩放,虽然最优解中每个参数的贡献被削弱了,但参数的数目并没有变少。
岭回归是在
w
i
w_i
wi 满足正态先验分布的条件下,用最大后验概率进行估计得到的结果。同样的,我们来证明这个结果:

由此得证。
逻辑回归
逻辑回归,其实是为了解决分类问题。其数学表达式为:
y
=
1
1
+
e
−
(
w
T
x
)
y=\frac{1}{1+e^{-(w^T x)}}
y=1+e−(wTx)1
线性回归与逻辑回归之间的关系:
o
d
d
=
y
1
−
y
odd=\frac{y}{1-y}
odd=1−yy叫做几率函数,且令:
l
n
y
1
−
y
=
w
T
x
+
b
ln\frac{y}{1-y}=w^Tx+b
ln1−yy=wTx+b
由此可见,当利用逻辑回归模型解决分类任务时,线性回归的结果正是以对数几率的形式出现的。
归根结底,逻辑回归模型由条件概率分布表示:

从数学角度看,线性回归和逻辑回归之间的渊源来源于非线性的对数似然函数;而从特征空间的角度看,两者的区别则在于数据判定边界的变化。以最简单的二维平面直角坐标系为例。受模型形式的限制,利用线性回归只能得到直线形式的判定边界;逻辑回归则在线性回归的基础上,通过对数似然函数的引入使判定边界的形状不再受限于直线,而是推广为更加复杂的曲线形式,更加精细的分类也就不在话下。
逻辑回归于朴素贝叶斯之间的关系:
即便原理不同,逻辑回归与朴素贝叶斯分类器在特定的条件下依然可以等效。 用朴素贝叶斯分类器处理二分类任务时,假设对每个
x
i
x_i
xi,属性条件概率
p
(
x
i
∣
Y
=
y
k
)
p(x_i∣Y=y_k)
p(xi∣Y=yk) 都满足正态分布,且正态分布的标准差与输出标记 Y 无关,那么根据贝叶斯定理,后验概率就可以写成:

根据朴素贝叶斯方法的假设,类条件概率可以表示为属性条件概率的乘积,因而令
p
(
Y
=
0
)
=
p
0
p(Y=0)=p_0
p(Y=0)=p0 ,并将满足正态分布的属性条件概率
p
(
x
i
∣
Y
=
y
k
)
p(x_i∣Y=y_k)
p(xi∣Y=yk) 代入以上表达式中,经过一番计算就可以得到:

不难看出,上式的形式和逻辑回归中条件概率
p
(
y
=
0
∣
x
)
p(y=0∣x)
p(y=0∣x) 的形式是完全一致的,这表明朴素贝叶斯方法和逻辑回归模型学习到的是同一个模型。实际上,在
p
(
x
∣
Y
)
p(x∣Y)
p(x∣Y) 的分布属于指数分布族这个更一般的假设下,类似的结论都是成立的。
说完了联系,再来看看区别。两者的区别在于当朴素贝叶斯分类的模型假设不成立时,逻辑回归和朴素贝叶斯方法通常会学习到不同的结果。 当训练样本数接近无穷大时,逻辑回归的渐近分类准确率要优于朴素贝叶斯方法。而且逻辑回归并不完全依赖于属性之间相互独立的假设,即使给定违反这一假设的数据,逻辑回归的条件似然最大化算法也会调整其参数以实现最大化的数据拟合。相比之下,逻辑回归的偏差更小,但方差更大。
除此之外,两者的区别还在于收敛速度的不同。 逻辑回归中参数估计的收敛速度要慢于朴素贝叶斯方法。当训练数据集的容量较大时,逻辑回归的性能优于朴素贝叶斯方法;但在训练数据稀缺时,两者的表现就会发生反转。















 7146
7146











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









