






java实现OCR图文识别Tess4j,高准确率高效率,用最新的词库2秒就可以识别,没有最新词库的找我
傻瓜式调用中文词库,及其方便。
虽然不能达到99%的准确率,但是也能达到90%左右的准确率,而且效率也非常高。总体来说相对于各大厂商的API接口来说,高昂的费用省下来不香吗。
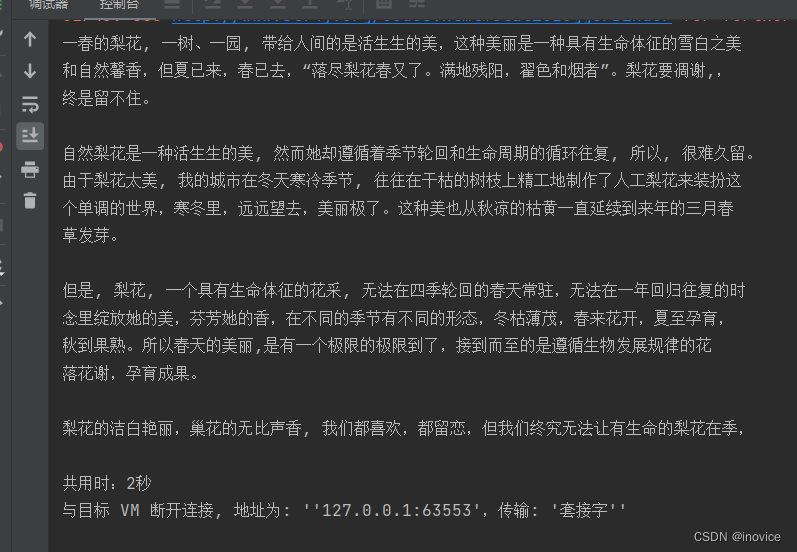
本文以一张简单的图片为例:图片放置在E:/App/TestTess4/src/main/resources/bbb.png,因此使用代码测试前需要修改代码中指定的两个路径!!!
这篇文章是我从网络上随便找的,文字还是很优美哦
/**
* 图片文字识别
*/
public void ocrDemo(){
File imageFile = new File("E:/App/TestTess4/src/main/resources/bbb.png");
Tesseract instance = new Tesseract();
instance.setDatapath(DATA_PATH);
instance.setVariable("user_defined_dpi", "300");
instance.setLanguage(DEFAULT_LANG);
try {
long startTime = System.currentTimeMillis();
String result = instance.doOCR(imageFile);
System.out.println(result);
long endTime = System.currentTimeMillis();
long seconds = (endTime - startTime) / 1000;
System.out.println("共用时:"+ seconds + "秒");
} catch(TesseractException e){
e.printStackTrace();
}
}一个简单的验证码识别就算完成了,怎么样是不是很简单。
:















 8759
8759











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











