






15.指针和引用的区别
1)定义
指针:是一种直接指向存储器中某个地址的值的变量。
引用:是变量的一个别名,与被引用的变量可以算作是同一个变量。在编译时,编译器会自动执行解引用操作,即帮忙检查该引用是否初始化。引用并非基于const指针实现,虽然二者在使用上有一定的相似程度。
2)初始化
指针:每次赋值时,指针都可以被赋值为不同的值(对于普通指针,未被const修饰的)
引用:只能初始化一次,绑定了一个变量之后不能再绑定到其他变量上。后续的赋值实际上是对被绑定变量的值的修改。
3)特殊值
指针:可以是NULL或者nullptr(C++11及以上)
引用:没有空引用,只能在初始化的时候同步绑定到一个变量上。
4)内存占用
指针:指针本身会根据系统位数占用一定大小,在32位系统下占4字节,64位下占8字节;
引用:引用本身所占内存取决于被引用变量的大小,因为二者指向的是同一块内存空间,即编译器不会为引用额外开辟一块空间,否则用sizeof检查引用的大小就不是被引用对象的大小,这与实际不符。但是在实际底层实现上,引用可能被当做指针进行处理,而这个处理过程对于用户来说是不透明的,即我们不能操作引用的地址。
5)多级引用与指针
指针:可以使用多级指针,例如多维数组的操作
引用:没有多级引用
6)安全性
大多数情况下使用引用比指针更安全,因为引用在编译器底层会进行更多的类型检查或者限制,但是指针则不会,不然也没那么多野指针空指针的问题了lol。
7)实际使用
指针:一般用在直接操作内存的地方,或者需要手动管理内存的地方,例如数组的操作或者类对象的管理上,希望对象的构造/析构由用户决定。
引用:通常用于函数的传参或者返回,避免不必要的临时拷贝,这样做会提高效率,同时有着更高的安全性。
16.内存对齐定义、作用及规则
定义:指计算机在内存中按照一定规则排列数据,确保数据的起始地址是某个特定值的整数倍,这个特定值通常与数据类型有关。
作用:提高数据访问效率,减少内存碎片,确保数据正确读取。
规则:
1)基本数据类型:
char:对齐值为1
short:对齐值为2
int,float:对齐值为4(32位系统)
double:对齐值为8(64位系统)
2)结构体或类:
①:结构体内任何K字节的基本数据类型对象相对于结构体首地址的偏移必须是K的整数倍;
②:满足①后,还需满足结构体首地址是结构体内最大基本对象长度的整数倍,即可保证字节对齐。
在C++中,可使用#pragma pack(n)... #pragma来强制要求以n字节为对齐值。
举例:
struct test
{
int i; // offset: 0
char c; // offset: 4
int j; // offset: 5
};可以看到j相对于结构体首地址的偏移量为5,肯定不能被4整除,所以在以4字节对齐为前提下,c与j中间还需要隐式地插入3个字节,最终如下:
struct test
{
int i; // offset: 0
char c; // offset: 4
char gap_c[3] // offset: 5
int j; // offset: 8
};考虑下面这种情况:
struct test
{
int i; // offset: 0
int j; // offset: 4
char c; // offset: 8
};显然上述情况 可以满足规则①,但是如果我们定义一个test数组:test t[2],那么如果test的最后一个char字节后面没有填充的话,那么t[1]这个结构体实例的起始地址将会是&t[0] + 9,显然没办法被4除尽,这样就违背了规则②。也就是说,规则②还有一个隐藏条件:结构体的长度要能被其中最大对象的长度整除。
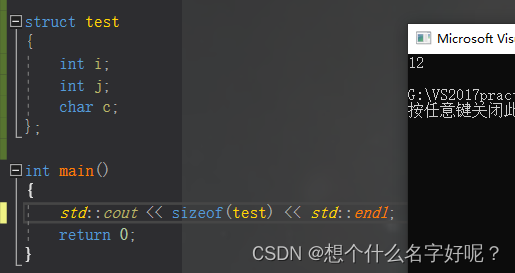
故需要在c后面补齐3个字节。
struct test
{
int i; // offset: 0
int j; // offset: 4
char c; // offset: 8
char gap_c[3]; // offset: 9
};
17.C语言如何实现多态
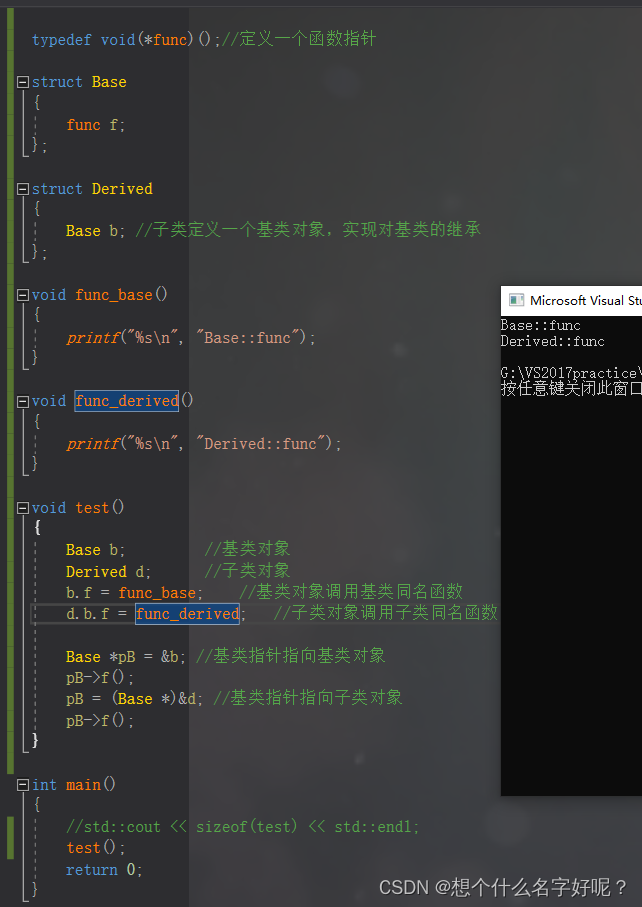
由于结构体和类比较相似,只不过结构体默认的访问权限是public,而类是private,所以结构体可以借助函数指针实现多态。
typedef void(*func)();//定义一个函数指针
struct Base
{
func f;
};
struct Derived
{
Base b; //子类定义一个基类对象,实现对基类的继承
};
void func_base()
{
printf("%s\n", "Base::func");
}
void func_derived()
{
printf("%s\n", "Derived::func");
}
void test()
{
Base b; //基类对象
Derived d; //子类对象
b.f = func_base; //基类对象调用基类同名函数
d.b.f = func_derived; //子类对象调用子类同名函数
Base *pB = &b; //基类指针指向基类对象
pB->f();
pB = (Base *)&d; //基类指针指向子类对象
pB->f();
}运行结果:
18.构造函数、析构函数、重载运算符可以是虚函数吗?
析构函数和重载运算符可以是虚函数,并且在有继承的情况下比较推荐析构函数写成虚函数的形式,防止部分资源释放不到位。但是构造函数不能为虚函数,第一是因为C++编译器不支持这样操作,第二是构造函数没有动态多态的必要(但是有静态多态也就是重载的需要,例如默认构造函数、拷贝构造函数等),因为多态是为了解决编译期无法确定类型的问题,但是构造函数显然可以在编译期确定其类型。
19.构造和析构的调用顺序
创建对象时,首先调用基类构造函数(如果有继承,且如果有多重继承,则按照顺序依次调用),然后调用类中非静态成员的构造函数(也是按照声明顺序进行调用,如果是指针成员对象则可以手动规定析构顺序。类的静态成员只与类本身进行关联,跟类的实例没有关系,所以实例在构造的时候静态成员不参与),最后调用自己的构造函数。
销毁对象时,与创建对象时的顺序相反,首先调用自己的析构函数,然后按照声明反序依次调用类成员对象的析构函数,然后按照声明反序调用基类的析构函数。
class Base1 {
public:
~Base1() { std::cout << "~Base1 destructor\n"; }
};
class Base2 {
public:
~Base2() { std::cout << "~Base2 destructor\n"; }
};
class Member1 {
public:
~Member1() { std::cout << "~Member1 destructor\n"; }
};
class Member2 {
public:
~Member2() { std::cout << "~Member2 destructor\n"; }
};
class Derived : public Base1, public Base2 {
Member1 m1;
Member2 m2;
public:
~Derived() { std::cout << "~Derived destructor\n"; }
};
int main() {
Derived d;
return 0; // 离开作用域时,对象d被销毁
}运行结果如下:
~Derived destructor
~Member2 destructor
~Member1 destructor
~Base2 destructor
~Base1 destructor
20.union、struct和class的区别
struct和class都能用来定义类,虽然struct常被用来定义数据块。struct也通常被视为class的一种简化形式,通过函数指针的形式,struct也可以实现class的多态(见第17条)。此外struct的默认访问权限为public,class的默认访问权限为private。
union是联合体,其用于在同一块内存中存储不同类型的数据。这种数据结构允许定义一个变量,该变量可以在不同的时间保存不同的数据类型和不同长度的变量,即同一时刻union在内存中只能存储其某一个成员变量的值,所有的这些变量都共享同一段内存空间。
21.extern “C”作用
C++ 提供的一个关键字,用于指示编译器将某个函数或变量的名称按照 C 语言的方式进行处理,以便与C语言进行交互。其原理上就是关闭编译器的name mangling(名称覆盖/命名倾轧,老是喜欢起一些佶屈聱牙的名词增加学习和理解难度,三分之一个哪吒)。
22.RTTI是什么
1)定义
run time type identification,运行时类型识别,即在运行时确定对象的实际类型。
2)作用
①类型检查:RTTI可以在运行时检查对象的实际类型,这对于处理多态性、基类指针指向派生类对象等场景非常有用。通过使用RTTI,程序员可以在不依赖虚函数或模板的情况下,根据对象的实际类型执行特定的操作。
②类型转换:通过提供dynamic_cast操作符,用于将基类指针或引用安全地转换为派生类指针或引用。这种转换是类型安全的,因为如果转换不合法(例如,基类指针并不指向派生类对象),dynamic_cast将返回空指针或抛出异常。
③获取类型信息:RTTI中的typeid操作符可以返回指针或引用所指对象的实际类型信息。这个信息可以用于调试、日志记录或执行基于类型的特定操作。
3)实现方式
RTTI的实现方式通常是在对象的内存布局中添加额外的元数据,这些元数据包含了关于对象类型的信息。这些元数据可以被RTTI操作符(如typeid和dynamic_cast)在运行时访问和使用。
4)示例
#include <iostream>
#include <typeinfo>
class Base {
public:
virtual ~Base() {} // 虚析构函数,确保多态性
};
class Derived : public Base {};
int main() {
Base* ptr = new Derived(); // 基类指针指向派生类对象
// 使用RTTI检查对象的实际类型
if (typeid(*ptr) == typeid(Derived)) {
std::cout << "ptr指向Derived类型的对象\n";
}
// 使用dynamic_cast进行类型转换
Derived* derivedPtr = dynamic_cast<Derived*>(ptr);
if (derivedPtr != nullptr) {
std::cout << "成功将ptr转换为Derived*类型\n";
}
delete ptr; // 释放内存
return 0;
}23.RAII是什么
1)定义
resource acquisition is initialization,资源获取即为初始化。RAII可以算是C++与C最重要的区别之一了。是C++非常重要的设计理念(编程范式)。一般会经过三个步骤:创建对象-适用对象-销毁对象。
2)作用
①自动管理资源:通过将资源的生命周期与对象的生命周期绑定,资源的分配和释放被自动化。这避免了程序员手动管理资源的繁琐过程,降低了出错的可能性。
②异常安全:在发生异常时,局部对象会被自动销毁,其析构函数被调用,从而保证资源(如动态分配的内存)被释放,防止内存泄漏。
③简化代码:使用RAII可以减少手动管理资源的代码量,使代码更加简洁和可靠。程序员只需关注对象的构造和析构,而无需担心资源的显式获取和释放。
④提高可读性:通过将资源管理逻辑封装在对象中,可以提高代码的可读性和可维护性。其他程序员可以更容易地理解和管理代码中的资源。
3)实现方式
构造函数:在对象的构造函数中,可以执行资源的获取和初始化操作。例如,打开一个文件、分配内存或建立网络连接等。
析构函数:在对象的析构函数中,可以执行资源的释放操作。当对象离开其作用域或被删除时,析构函数会自动被调用,从而确保资源得到正确释放。
这就是定义中说到的步骤1和步骤3.
4)使用场景
文件操作:可以使用RAII来管理文件句柄(某种意义上来讲指针也是句柄,地址的句柄怎么就不是句柄了)的生命周期,确保文件在不再需要时被正确关闭。
内存管理:通过封装动态内存分配和释放操作,可以避免内存泄漏和野指针等问题。
网络编程:在网络编程中,可以使用RAII来管理网络连接的创建和关闭。
24.可以在运行时访问private成员吗
可以,访问权限关键字只在编译期有效,运行期是没有访问权限关键字这些概念的,可以在运行时访问对象内的任何成员。例如Java可以使用反射的机制访问private成员,C++也提供了友元的概念访问private成员。
友元示例:
#include <iostream>
class MyClass {
private:
int privateMember;
public:
MyClass(int value) : privateMember(value) {}
// 声明一个友元函数
friend void printPrivateMember(const MyClass& obj);
};
// 定义友元函数,它可以访问 MyClass 的私有成员
void printPrivateMember(const MyClass& obj) {
std::cout << "Private member value: " << obj.privateMember << std::endl;
}
int main() {
MyClass myObj(42);
printPrivateMember(myObj); // 输出私有成员的值
return 0;
}25.一个空类的实例的内存大小是多少?为什么?
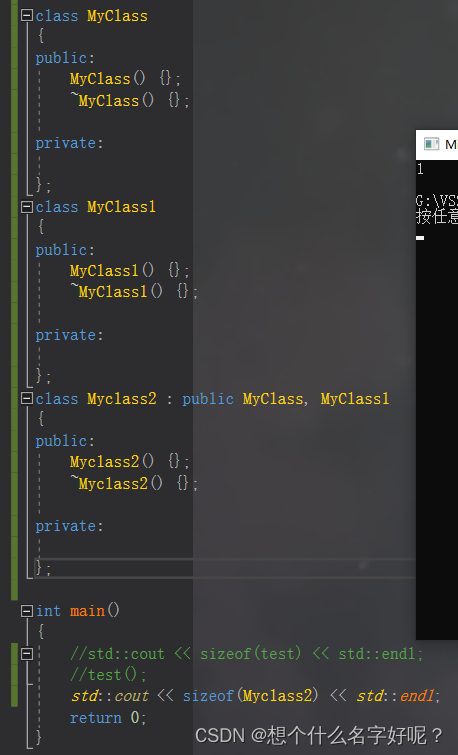
C++标准规定每个对象实例在内存中都必须有独一无二的地址,所以即使是空类,其实例化的对象也应有各自独特的内存地址,如果空类的大小为0,那么声明一个空类的对象数组时,数组中的所有元素都会具有相同的内存地址,这将违反C++的这一规定。
1)Windows平台下:
在Windows平台下,使用大多数编译器(如MSVC)编译时,空类的大小通常为1字节。这是为了确保每个空类的实例在内存中都有一个独一无二的地址。
多重继承/单继承均为1:
虚继承时,会因为虚基表指针的存在,会增加虚基表指针的大小(32位为4字节,64位为8字节),每多一个虚继承就多一个虚基表指针的大小。
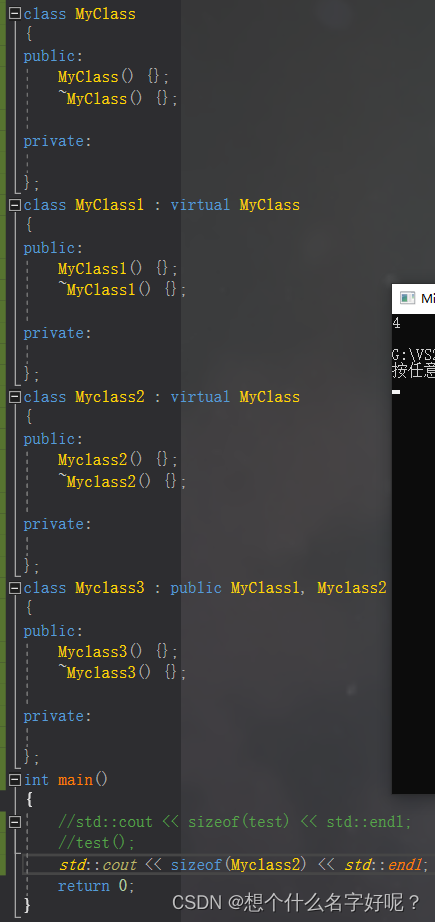
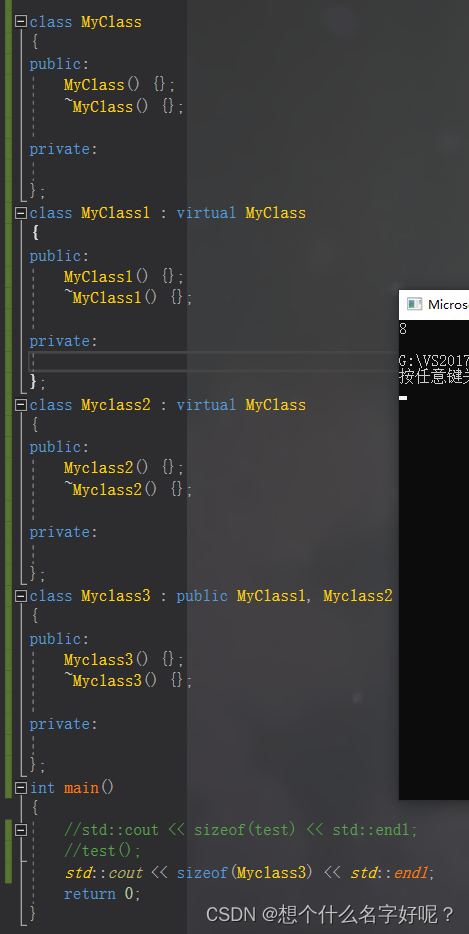
先继承空类再继承虚基类和先继承虚基类再继承空类所占大小是不一样的:
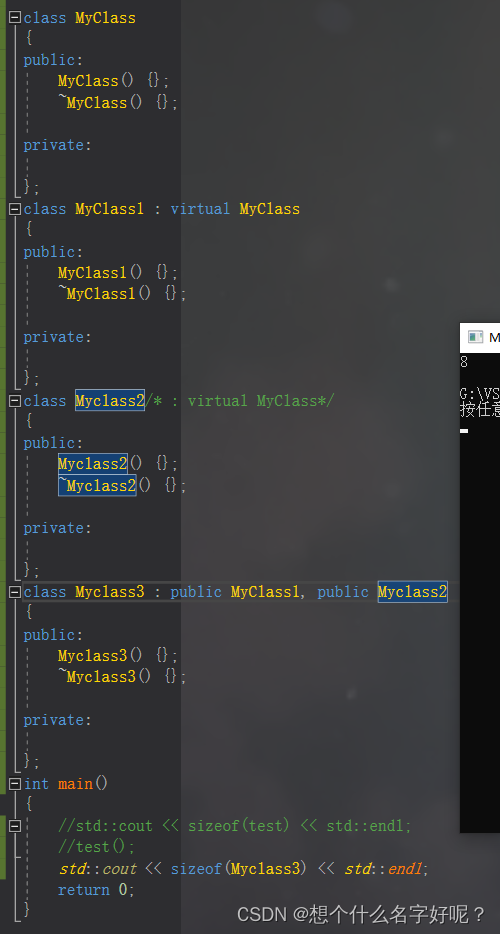
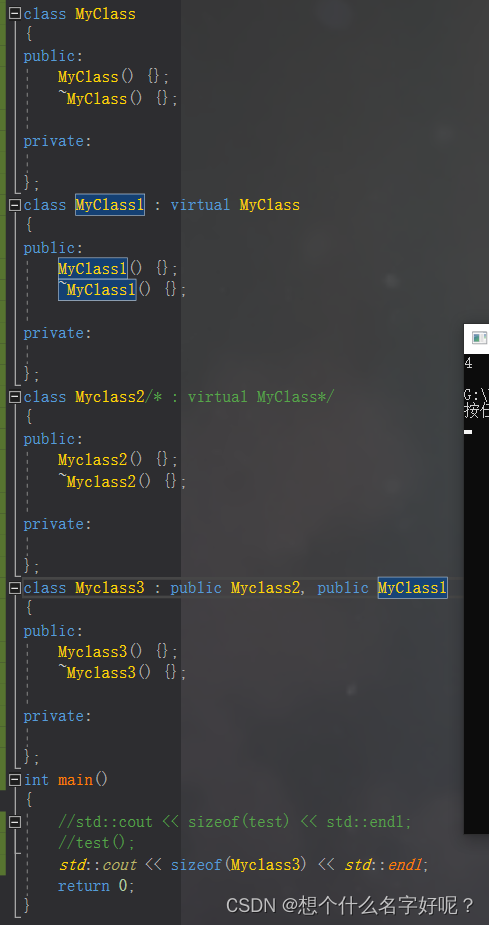
2)GNU-GCC平台下
在使用GCC编译器编译的平台上,空类的大小也通常为1字节,无论是单继承还是多继承的情况。















 678
678

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









