







spark-submit远程提交的常用命令如下:
spark-submit \
--master spark://bigdata.node2:7077 \
--class test.nospark.NoSpark \
--num-executors 1 \
--driver-memory 499m \
--driver-cores 1 \
--executor-memory 499m \
--executor-cores 1 \
/opt/spark-jar/wyt01bigdata-1.0-SNAPSHOT.jar该命令运行时是将一些参数传递给spark-submit脚本,所以我们接着看一下spark-submit的脚本信息:
if [ -z "${SPARK_HOME}" ]; then
source "$(dirname "$0")"/find-spark-home
fi
# disable randomized hash for string in Python 3.3+
export PYTHONHASHSEED=0
exec "${SPARK_HOME}"/bin/spark-class org.apache.spark.deploy.SparkSubmit "$@"可以看到spark-submit脚本中会再我们参数的基础上再增加一个SparkSubmit类全路径的参数(该类很重要,是提交任务的核心类),然后将所有参数传给spark-class脚本处理,所以我们还要再看下spark-class脚本里面的内容,因为该脚本内容比较多,对于前面一些环境准备的脚本就不再细看,直接追踪和我们问题相关的主流程脚本。spark-class核心脚本如下:
build_command() {
"$RUNNER" -Xmx128m $SPARK_LAUNCHER_OPTS -cp "$LAUNCH_CLASSPATH" org.apache.spark.launcher.Main "$@"
printf "%d\0" $?
}其中RUNNER是前面环境准备过程中定位到的java命令路径,上述方法的整理含义就是发起一个java进程,运行的主类是org.apache.spark.launcher.Main,并将spark-submit中传递的参数
整体传入Main类中。
下面我们运行代码,远程debug看一下(spark的远程debug流程可以参考参考这篇文章:IDEA远程调试spark-submit提交的jar_Interest1_wyt的博客-CSDN博客)。spark-submit提交命令如下:
spark-submit \
--master spark://bigdata.node2:7077 \
--class test.wordcount.WordCount \
--num-executors 1 \
--driver-memory 499m \
--driver-cores 1 \
--executor-memory 499m \
--executor-cores 1 \
--driver-java-options -agentlib:jdwp=transport=dt_socket,server=y,suspend=y,address=8888 \
/opt/spark-jar/wyt01bigdata-1.0-SNAPSHOT.jar
我们再Main和SparkSubmit对应的类方法中加上断点,如下:


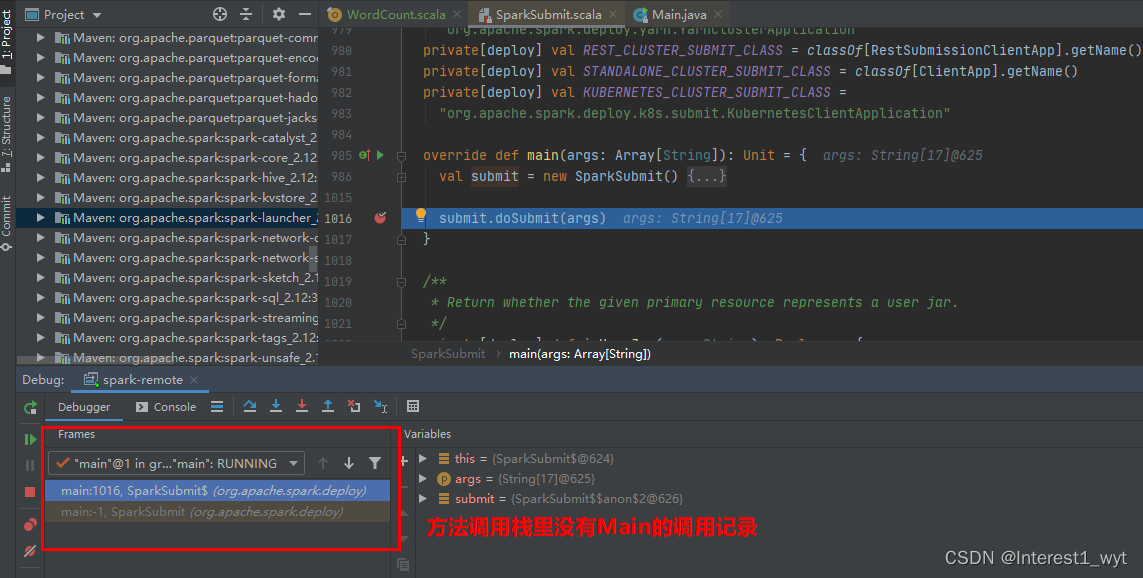
然后分别运行spark-submit命令和idea项目,可以看到直接进入到了SparkSubmit类的断点中,而且我们观察程序运行的记录可以发现,根本没有Main类的信息(这里我推测是因为Main是一个启动进程,它的作用是发起一个spark项目的提交,而它本身并不属于spark项目,也就是说执行main类方法时,整个spark项目还没有运行,即Main还不是真正的执行入口。所以对应的远程代码也不会映射到本地的断点中。如果有知道具体原因的大佬,希望可以留言告知,谢谢哈)。
虽然我们不能直接debug查看Main中方法的运行,但是Main类中提供了一个属性配置,通过该配置可以打印Main要执行的命令。

而且我们知道该类的功能其实就是构建命令并发起命令运行。所以这块不能debug追踪影响不大,接下来我们打开命令打印,打开方式是在linux环境下运行如下命令:
export SPARK_PRINT_LAUNCH_COMMAND=true
随后重新运行spark-submit命令并启动idea本地项目,可以看到打印的执行命令如下:

从打印的命令中我们也可以看到,远程debug相关的主类其实只有两个,最开始的是SparkSubmit,后一个则是我们的程序主类WordCount,这也可以从一方面解释为什么我们远程debug不能进入到Main类中。
了解了Main类要执行的命令,下面我们直接到spark任务真正的执行入口SparkSubmit类中观察其如何将任务提交给spark服务器处理。



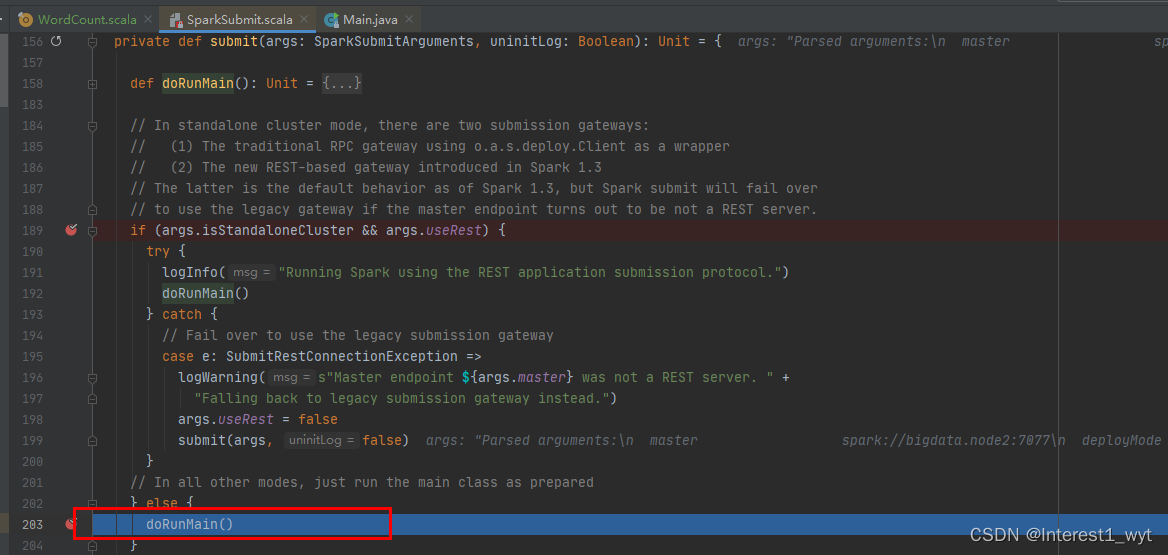
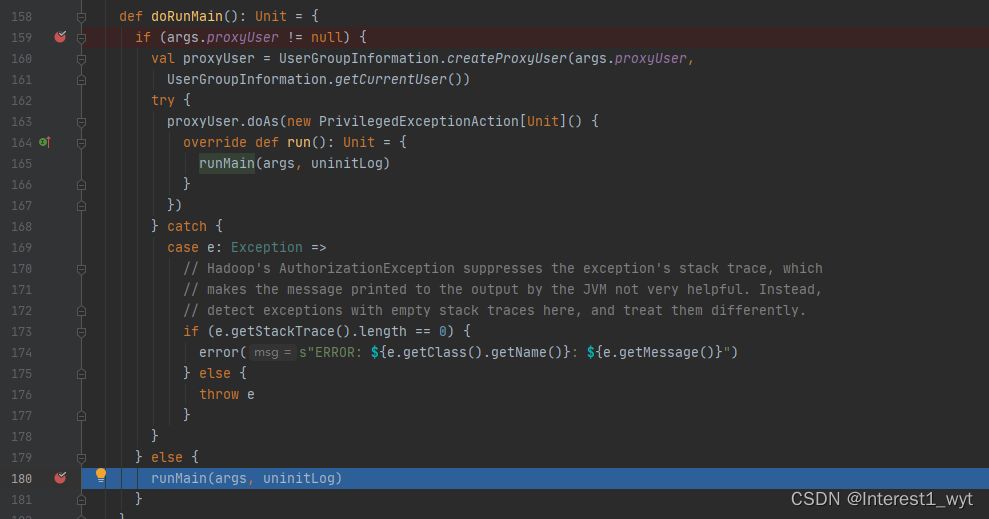
至此,随着一步步的深入,我们到了比较关键的一个方法中,在runMain方法中会准备任务运行的环境,并调用我们再spark-submit命令中指定的类的main方法。
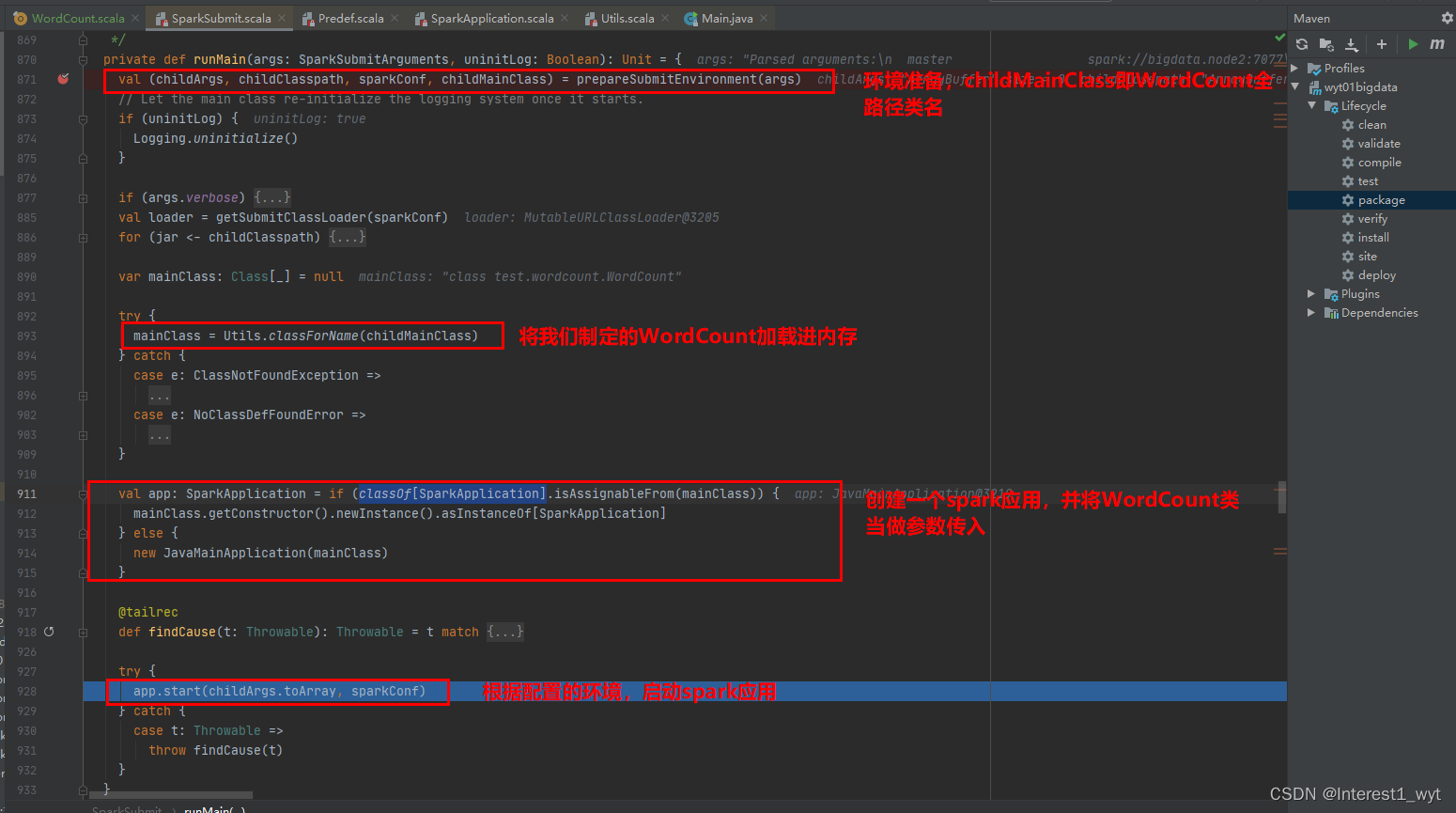
可以看到spark首先会根据spark-submit中的参数和一些默认参数准备环境,获取我们主类名称,这里我们在standalone环境client模式下获取的是WordCount类的信息,并以此构建spark application最后启动该application,我们接下来看下application的启动。

因为我们的WordCount不是SparkApplication子类,所以在上一步创建SparkApplicaiton时,实际创建的的是JavaMainApplication,所以我们这里看start方法是到JavaMainApplication里面查看。可以看到启动方法很简单,就是根据我们的环境情况获取我们到主类(这里我们获取到的主类是WordCount)的信息,并通过反射的方式调用。
至此,我们此次查看源码的目的已经达成。但是有几个关键点可以留意下:
第一,获取主类的过程其实有很多的逻辑判断,但是因为我们是以client模式提交的任务,所以最终获取的类名肯定是我们自己程序的名称。这是因为client模式是本地启动driver。
第二、SparkApplication的实现类只有三个,分别是JavaMainApplication、ClientApp、RestSubmissionClientApp,但是前者不需要spark master调度和启动driver,它是直接启动在本地。后两者则会提交driver的构建请求给master,由master调度分配资源和发起driver的构建。
至于后续的driver、application构建,executor资源分配和启动会在后续的文章中进行介绍。














 6142
6142











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









