









 本文详细介绍如何在IDEA中搭建Spark项目、打包成JAR并使用spark-submit命令在集群中部署运行,包括解决常见问题和注意事项。
本文详细介绍如何在IDEA中搭建Spark项目、打包成JAR并使用spark-submit命令在集群中部署运行,包括解决常见问题和注意事项。
转载:
蜗龙徒行-Spark学习笔记【四】Spark集群中使用spark-submit提交jar任务包实战经验 - cafuc46wingw的专栏 - 博客频道 - CSDN.NET
http://blog.csdn.net/cafuc46wingw/article/details/45043941
一、所遇问题
由于在IDEA下可以方便快捷地运行Scala程序,所以先前并没有在终端下使用Spark-submit提交打包好的jar任务包的习惯,但是其只能在local模式下执行,在网上搜了好多帖子设置VM参数都不能启动spark集群,由于实验任务紧急只能暂时作罢IDEA下任务提交,继而改由终端下使用spark-submit提交打包好的jar任务。
二、spark-shell功能介绍
进入$SPARK_HOME目录,输入bin/spark-submit --help可以得到该命令的使用帮助。
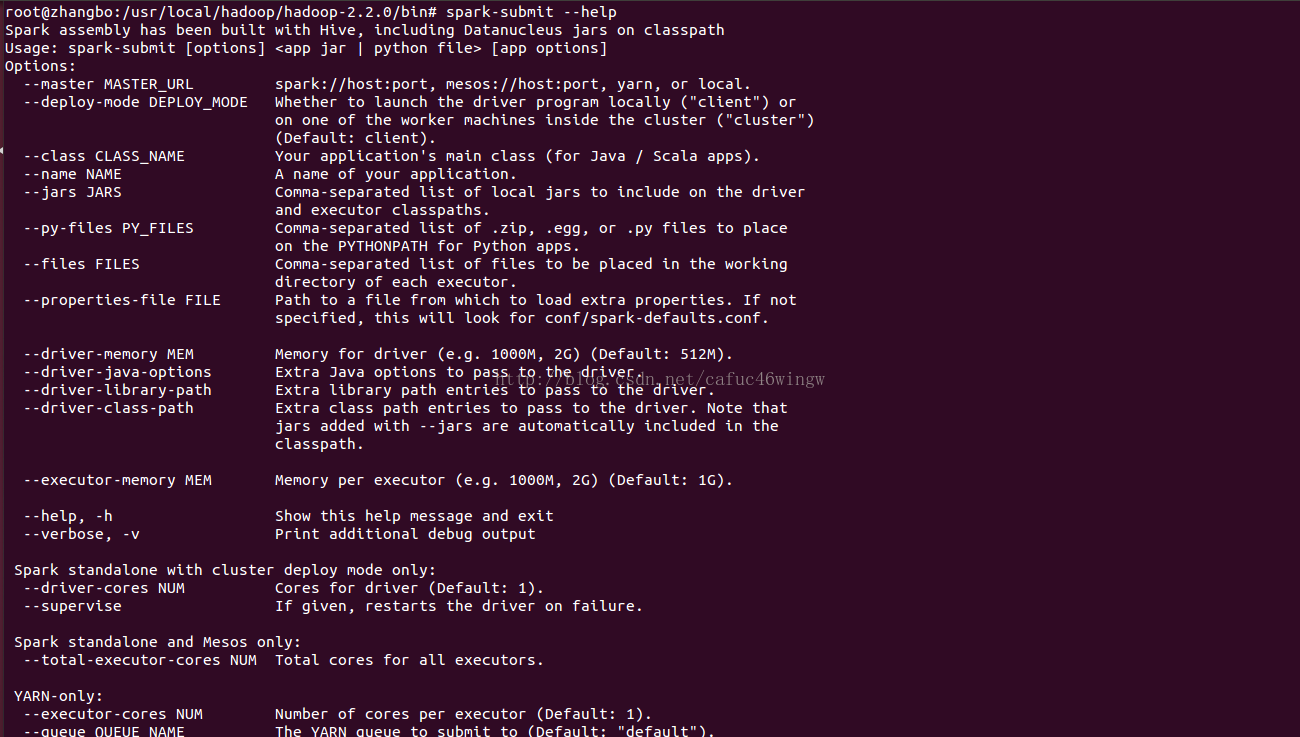

--master MASTER_URL spark://host:port, mesos://host:port, yarn, or local.
--deploy-mode DEPLOY_MODE driver运行之处,client运行在本机,cluster运行在集群
--class CLASS_NAME 应用程序包的要运行的class
--name NAME 应用程序名称
--jars JARS 用逗号隔开的driver本地jar包列表以及executor类路径
--py-files PY_FILES 用逗号隔开的放置在Python应用程序PYTHONPATH上的.zip, .egg, .py文件列表
--files FILES 用逗号隔开的要放置在每个executor工作目录的文件列表
--properties-file FILE 设置应用程序属性的文件放置位置,默认是conf/spark-defaults.conf
--driver-memory MEM driver内存大小,默认512M
--driver-java-options driver的java选项
--driver-library-path driver的库路径Extra library path entries to pass to the driver
--driver-class-path driver的类路径,用--jars 添加的jar包会自动包含在类路径里
--executor-memory MEM executor内存大小,默认1G
Spark standalone with cluster deploy mode only:
--driver-cores NUM driver使用内核数,默认为1
--supervise 如果设置了该参数,driver失败是会重启
Spark standalone and Mesos only:
--total-executor-cores NUM executor使用的总核数
YARN-only:
--executor-cores NUM 每个executor使用的内核数,默认为1
--queue QUEUE_NAME 提交应用程序给哪个YARN的队列,默认是default队列
--num-executors NUM 启动的executor数量,默认是2个
--archives ARCHIVES 被每个executor提取到工作目录的档案列表,用逗号隔开
- 关于--master --deploy-mode,正常情况下,可以不需要配置--deploy-mode,使用下面的值配置--master就可以了,使用类似 --master spark://host:port --deploy-mode cluster会将driver提交给cluster,然后就将worker给kill的现象。
| Master URL | 含义 |
| local | 使用1个worker线程在本地运行Spark应用程序 |
| local[K] | 使用K个worker线程在本地运行Spark应用程序 |
| local[*] | 使用所有剩余worker线程在本地运行Spark应用程序 |
| spark://HOST:PORT | 连接到Spark Standalone集群,以便在该集群上运行Spark应用程序 |
| mesos://HOST:PORT | 连接到Mesos集群,以便在该集群上运行Spark应用程序 |
| yarn-client | 以client方式连接到YARN集群,集群的定位由环境变量HADOOP_CONF_DIR定义,该方式driver在client运行。 |
| yarn-cluster | 以cluster方式连接到YARN集群,集群的定位由环境变量HADOOP_CONF_DIR定义,该方式driver也在集群中运行。 |
- 如果要使用--properties-file的话,在--properties-file中定义的属性就不必要在spark-sumbit中再定义了,比如在conf/spark-defaults.conf 定义了spark.master,就可以不使用--master了。关于Spark属性的优先权为:SparkConf方式 > 命令行参数方式 >文件配置方式,具体参见Spark1.0.0属性配置。
- 和之前的版本不同,Spark1.0.0会将自身的jar包和--jars选项中的jar包自动传给集群。
- Spark使用下面几种URI来处理文件的传播:
- file:// 使用file://和绝对路径,是由driver的HTTP server来提供文件服务,各个executor从driver上拉回文件。
- hdfs:, http:, https:, ftp: executor直接从URL拉回文件
- local: executor本地本身存在的文件,不需要拉回;也可以是通过NFS网络共享的文件。
- 如果需要查看配置选项是从哪里来的,可以用打开--verbose选项来生成更详细的运行信息以做参考。
三、如何将scala程序在IDEA中打包为JAR可执行包
A:建立新项目(new project)
- 创建名为KMeansTest的project:启动IDEA -> Welcome to IntelliJ IDEA -> Create New Project -> Scala -> Non-SBT -> 创建一个名为KMeansTest的project(注意这里选择自己安装的JDK和scala编译器) -> Finish。
- 设置KMeansTest的project structure
- 增加源码目录:File -> Project Structure -> Medules -> KMeansTest,给KMeansTest创建源代码目录和资源目录,注意用上面的按钮标注新增加的目录的用途。
- 增加源码目录:File -> Project Structure -> Medules -> KMeansTest,给KMeansTest创建源代码目录和资源目录,注意用上面的按钮标注新增加的目录的用途。

- 增加开发包:File -> Project Structure -> Libraries -> + -> java -> 选择
- /usr/local/spark/spark-1.0.2-bin-hadoop2/lib/spark-assembly-1.0.2-hadoop2.2.0.jar
- /root/.sbt/boot/scala-2.10.4/lib/scala-library.jar可能会提示错误,可以根据fix提示进行处
B:编写代码
在源代码scala目录下创建1个名为KMeansTest的package,并增加3个object(SparkPi、WordCoun、SparkKMeans):
C:生成jar程序包
生成jar程序包之前要先建立一个artifacts,File -> Project Structure -> Artifacts -> + -> Jars -> From moudles with dependencies,然后随便选一个class作为主class。
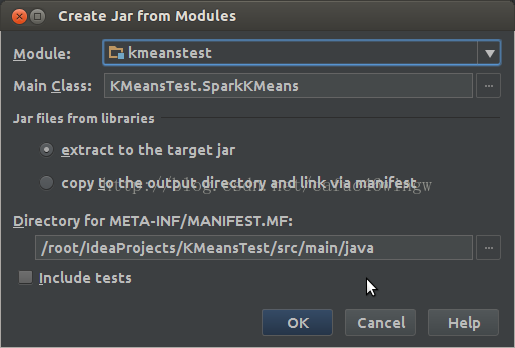
按OK后, Build -> Build Artifacts -> KMeansTest -> rebuild进行打包,经过编译后,程序包放置在out/artifacts/KMeansTest目录下,文件名为KMeansTest.jar。
D:Spark应用程序部署
将生成的程序包KMeansTest.jar复制到spark安装目录下,切换到用户Hadoop/bin目录下进行程序的部署。
四、spark-shell下进行jar程序包提交运行实验



- 集群外的客户机向Spark Standalone部署Spark应用程序时,要注意事先实现该客户机和Spark Standalone之间的SSH无密码登录。
- 向YARN部署spark应用程序的时候,注意executor-memory的大小,其内存加上container要使用的内存(默认值是1G)不要超过NM可用内存,不然分配不到container来运行executor。

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









