









IndexError: invalid index of a 0-dim tensor. Use tensor.item() to convert a 0-dim tensor to a Python
一、IndexError: invalid index of a 0-dim tensor. Use tensor.item() to convert a 0-dim tensor to a Python number
是你的torch版本的不同造成的。
解决:将loss.data[0] 改成loss.item()
1、torch.max(input, dim) 函数
output = torch.max(input, dim)
输入
input是softmax函数输出的一个tensor
dim是max函数索引的维度0/1,0是每列的最大值,1是每行的最大值
输出
函数会返回两个tensor,第一个tensor是每行的最大值,softmax的输出中最大的是1,所以第一个tensor是全1的tensor;第二个tensor是每行最大值的索引。
torch.max()[0], 只返回最大值的每个数
troch.max()[1], 只返回最大值的每个索引
torch.max()[1].data 只返回variable中的数据部分(去掉Variable containing:)
torch.max()[1].data.numpy() 把数据转化成numpy ndarry
torch.max()[1].data.numpy().squeeze() 把数据条目中维度为1 的删除掉
torch.max(tensor1,tensor2) element-wise 比较tensor1 和tensor2 中的元素,返回较大的那个值
2、np.newaxis的作用就是在这一位置增加一个一维
In [124]: arr = np.arange(5*5).reshape(5,5)
In [125]: arr.shape
Out[125]: (5, 5)
# promoting 2D array to a 5D array
In [126]: arr_5D = arr[np.newaxis, ..., np.newaxis, np.newaxis]
In [127]: arr_5D.shape
Out[127]: (1, 5, 5, 1, 1)
3、Pytorch反向传播中的细节-计算梯度时的默认累加
4、ModuleNotFoundError: No module named ‘tqdm’
Tqdm 是 Python 进度条库,可以在 Python 长循环中添加一个进度提示信息。用户只需要封装任意的迭代器,是一个快速、扩展性强的进度条工具库。
!pip install -i https://mirrors.aliyun.com/pypi/simple tqdm
5、ModuleNotFoundError: No module named ‘torchtext’
torchtext:程序包包含数据处理实用程序和流行的自然语言数据集。
!pip install -i https://mirrors.aliyun.com/pypi/simple torchtext
6、AttributeError: ‘tqdm’ object has no attribute ‘disp’
7、PyTorch有个小的知识点:x.item()用法。
官方文档解释.item()用法是:一个元素张量可以用x.item()得到元素值,我理解的就是一个是张量,一个是元素。
8、X, y = iter(test_iter).next()
参考
dataloader本质上是一个可迭代对象,使用iter()访问,不能使用next()访问;
使用iter(dataloader)返回的是一个迭代器,然后可以使用next访问;
batch_size = 256
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size)
X, y = iter(test_iter).next()
X.size()
输出:
torch.Size([256, 1, 28, 28])
9、python中*和**
参考
Python中,(*)会把接收到的参数形成一个元组,而()则会把接收到的参数存入一个字典**
在Python中定义函数,可以用必选参数、默认参数、可变参数和关键字参数,这4种参数都可以一起使用,或者只用其中某些,但是请注意,参数定义的顺序必须是:必选参数、默认参数、可变参数和关键字参数。
比如定义一个函数,包含上述4种参数:
def func(a, b, c=0, *args, **kw):
print( 'a =', a, 'b =', b, 'c =', c, 'args =', args, 'kw =', kw)
在函数调用的时候,Python解释器自动按照参数位置和参数名把对应的参数传进去。
>>> func(1, 2)
a = 1 b = 2 c = 0 args = () kw = {}
>>> func(1, 2, c=3)
a = 1 b = 2 c = 3 args = () kw = {}
>>> func(1, 2, 3, 'a', 'b')
a = 1 b = 2 c = 3 args = ('a', 'b') kw = {}
>>> func(1, 2, 3, 'a', 'b', x=99)
a = 1 b = 2 c = 3 args = ('a', 'b') kw = {'x': 99}
10、python中with的用法
with 语句适用于对资源进行访问的场合,确保不管使用过程中是否发生异常都会执行必要的“清理”操作,释放资源,比如文件使用后自动关闭/线程中锁的自动获取和释放等。
11、卷积(convolution)与互相关(cross-correlation)的一点探讨
现在深度学习中所做的卷积操作,其实都是互相关运算。无论哪个框架,conv2的API都是这个操作。
对于我们来讲,卷积就是一种运算,和加减乘除一样。

互相关(cross-correlation)
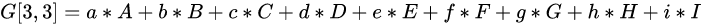
卷积(convolution)
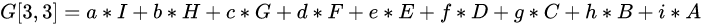
那么这就相当于将‘filter翻转’了
12、PyTorch中view的用法
相当于numpy中resize()的功能,但是用法可能不太一样。
把原先tensor中的数据按照行优先的顺序排成一个一维的数据(这里应该是因为要求地址是连续存储的),然后按照参数组合成其他维度的tensor。比如说是不管你原先的数据是[[[1,2,3],[4,5,6]]]还是[1,2,3,4,5,6],因为它们排成一维向量都是6个元素,所以只要view后面的参数一致,得到的结果都是一样的。比如,
a=torch.Tensor([[[1,2,3],[4,5,6]]])
b=torch.Tensor([1,2,3,4,5,6])
print(a.view(1,6))
print(b.view(1,6))
得到的结果都是tensor([[1., 2., 3., 4., 5., 6.]])
13、卷积神经网络中的填充(padding)和步幅(stride)
请参考:https://blog.csdn.net/qq_42255269/article/details/109284214
X = torch.rand(8, 8)
conv2d = nn.Conv2d(1, 1, kernel_size=3, padding=1, stride=2)
comp_conv2d(conv2d, X).shape
此处的padding=1表示在高和宽的两侧分别填充1,即
p
h
=
2
p_h=2
ph=2,
p
w
=
2
p_w=2
pw=2。
stride=2表示
s
h
=
2
s_h=2
sh=2 。
n
h
=
8
n_h=8
nh=8,
n
w
=
8
n_w=8
nw=8,
k
h
=
3
k_h=3
kh=3,
k
w
=
3
k_w=3
kw=3
根据公式:
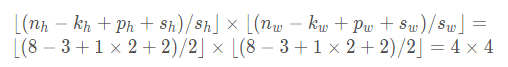
14、torch.nn.MaxPool2d
参考:https://www.jianshu.com/p/9d93a3391159
PyTorch学习之池化层(POOLING LAYERS
class torch.nn.MaxPool2d(kernel_size, stride=None, padding=0, dilation=1, return_indices=False, ceil_mode=False)
如果padding不是0,会在输入的每一边添加相应数目0 比如padding=1,则在每一边分别补0.
参数:
kernel_size(int or tuple) - max pooling的窗口大小,
stride(int or tuple, optional) - max pooling的窗口移动的步长。默认值是kernel_size
padding(int or tuple, optional) - 输入的每一条边补充0的层数
dilation(int or tuple, optional) – 一个控制窗口中元素步幅的参数
return_indices - 如果等于True,会返回输出最大值的序号,对于上采样操作会有帮助
ceil_mode - 如果等于True,计算输出信号大小的时候,会使用向上取整,代替默认的向下取整的操作
15、Input type (torch.FloatTensor) and weight type (torch.cuda.FloatTensor) should be the same
参考:https://blog.csdn.net/qq_27261889/article/details/86575033
在运行torch中出现这个错误。
错误内容大概就是指输入类型是CPU(torch.FloatTensor),而参数类型是GPU(torch.cuda.FloatTensor)。
关于数据类型的链接:官方链接
首先,请先检查是否正确使用了CUDA。
16、ubuntu—【nvidia-smi】命令参数含义

















 346
346











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











