









文章目录
首先来看看RL
深度强化学习—— 译 Deep Reinforcement Learning
任何可以被视为或转变为顺序决策问题的问题,RL都可能会有所帮助。
以优化classification time 和memory footprint为目标,找全局最优解而不是局部最优解(贪心,不需要手动调整参数)。
这篇论文到底做了什么?

1、 论述了为什么RL可以很好地进行决策树网包分类
2、 在将RL用在决策树网包分类的时候,解决两个问题
(1) 决策树是动态生长的,如何对决策树编码作为定长的输入
(2) 反馈耗时太长,导致weak reward attribution,简单来说就是训练结果variance太高
解决方案:
(1) 只编码当前节点,用所代表的五元组的区间左右端点表示
(2) 将训练过程由线性升级为树形
3、 与四种算法做性能比较,号称能将baseline提高18%。
网包分类问题:
网包分类类似于在高维集合空间定点问题:fields 是维度,包时空间中的一个点,规则是一个hypercube。
定点问题在时间和空间复杂度:(d维数据,n个non-overlapping hypercube,d>3)
O
(
log
n
)
O\left(\log n\right)
O(logn) time 为下界 and
O
(
n
d
)
O(n^d)
O(nd) space
lower bound of
O
(
log
d
−
1
n
)
O\left(\log ^{d-1} n\right)
O(logd−1n) time and
O
(
n
)
O(n)
O(n) space
而网包分类问题允许hypercube重叠,难度只增不减
两种常见方法
两种常见的方法来构建决策树进行网包分类
- Node cutting
The main idea is to split nodes in the decision tree by “cutting” them along one or more dimensions.

One challenge with “blindly” cutting a node is that we might end up with a rule being replicated to a large number of nodes - Rule partition
In particular, if a rule has a large size along one dimension, cutting along that dimension will result in that rule being added to many nodes.
Rule replication can lead to decision trees with larger depths and sizes, which translate to higher classification time and memory footprint
partition rules based on their “shapes”. rules with large sizes in a particular dimension are put in the same set. Then, we can build a separate decision tree for each of these partitions.
To classify a packet, we classify it against every decision tree, and then choose the highest priority rule among all rules the packet matches in all decision trees.
In contrast, decision trees for packet classi.cation provide perfect accuracy by construction, and the goal is to minimize classification time and memory footprint
决策树保证了分类的正确性 嗯
为什么使用RL?
- 当我们切割一个节点的时候,我们不能立刻知道这个决定是好是坏直到我们把整棵树给建完了。RL天生就又这样的特性,不是立即知道结果
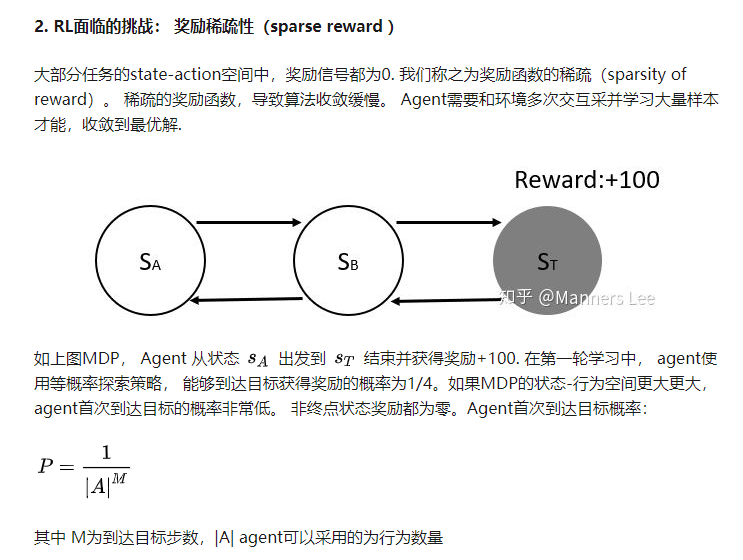
RL两个特性:
- 奖励稀疏性,不是每一步都有奖励,移动不知道会导致赢还是输的棋子的时候不设置奖励
- 延迟奖励,只有当比赛结束的时候才知道奖励(动态规划)
First, when we take an action, we do not know for sure whether it will lead to a good decision tree or not; we only know this once the tree is built. As a result, the rewards in our problem are both sparse and delayed. This is naturally captured by the RL formulation.
- 之前的启发式算法都是loosely related to 性能指标,RL算法是直接以优化性能指标为目的。Second, the explicit goal of RL is to maximize Thus, unlike existing heuristics, our RL solution aims to explicitly optimize the performance objective, rather than using local statistics whose correlation to the performance objective can be tenuous.
- 不像RL领域的其他问题(robotics)难以evaluate。By being able to evaluate each model quickly (and, as we will see, in parallel) we
Third, one potential concern with Deep RL algorithms is sample complexity. In general, these algorithms require a huge number of samples (i.e., input examples) to learn a good policy. Fortunately, in the case of packet classication we can generate such samples cheaply. A sample, or rollout, is a sequence of actions that builds a decision tree with the associated reward(s) by using a given policy. The reason we can generate these rollouts cheaply is because we can build all these trees in software, and do so in parallel. Contrast this with other RL-domains, such as robotics, where generating each rollout can take a long time and requires expensive equipment (i.e., robots).
采样复杂性
将RL用到决策树网包分类上需要解决的三个问题:
- RL算法需要定长的输入,但是在算法执行的过程中树一直在生长。只对当前节点进行编码(当前节点如何分割只需要考虑当前节点,不依赖于树的其他部分,因此不需要对整棵树进行编码)
- reducing the sparsity of rewards to accelerate the learning process ???利用问题的分支结构来向tree size和depth提供denser feedback 。exploit the branching structure of the problem to provide denser feedback for tree size and depth
- 训练大量的rules耗时很长。使用RLlib,分布式RL库
为什么要学习?
7. 启发式手动调参,当给了一个全新的rule set,得全部重做
8. 没有全局找最优解 poorly correlated with the desired objective.
学什么?
learn building decision trees for a given set of rules.
如何学?
a), an RL system
consists of an agent that repeatedly interacts with an environment. The agent observes the state of the environment, and then takes an action that might change the environment’s state. The goal of the agent is to compute a policy that maps the environment’s state to an action in order to optimize a reward.
DNN+RL Deep RL
用在网络和系统问题:路由、拥塞控制、视频流、job scheduling
Building a decision tree can be easily cast as an RL problem: the environment’s state is the current decision tree, an action is either cutting a node or partitioning a set of rules, and the reward is either the classification time, memory footprint, or a combination of the two
Neurocuts Design
action:
- cut
- partition
NeuroCuts Training Algorithm
the goal of an RL algorithm is to compute a policy to maximize rewards from the environment evaluates it using multiple rollouts, and then updates it based on the results (rewards) of these rollouts. Then, it repeats this process until satisfied with the reward.
Design challenges
- how to encode the variable-length decision tree state st as an
input to the neural network policy.
一个问题是编码问题
when the agent is deciding how to split a node, it only observes a xed-length representation of the node. All needed state is encoded in the representation; no other information about the rest of the tree is observed
目标是全局优化性能指标,但是不需要编码整棵树。因为不需要考虑父节点或者兄弟节点。给定一个树节点,动作只要达到那个子树上的最优。
虽然只编码了当前的节点,但是选取的action A 并不是仅仅是noden,而是从整个子树来看的最优选择。
对于cut:
T n = t n + max i ∈ c h i l d r e n ( n ) T i T_{n}=t_{n}+\max _{i \in c h i l d r e n(n)} T_{i} Tn=tn+maxi∈children(n)Ti
S n = s n + sum i ∈ c h i l d r e n ( n ) S i S_{n}=s_{n}+\operatorname{sum}_{i \in c h i l d r e n(n)} S_{i} Sn=sn+sumi∈children(n)Si
对于partition:
T n = t n + sum i ∈ c h i l d r e n ( n ) T i T_{n}=t_{n}+\operatorname{sum}_{i \in c h i l d r e n(n)} T_{i} Tn=tn+sumi∈children(n)Ti
S n = s n + sum i ∈ c h i l d r e n ( n ) S i S_{n}=s_{n}+\operatorname{sum}_{i \in c h i l d r e n(n)} S_{i} Sn=sn+sumi∈children(n)Si
V n = argmax a ∈ A − ( c ⋅ T n + ( 1 − c ) ⋅ S n ) V_{n}=\operatorname{argmax}_{a \in A}-\left(c \cdot T_{n}+(1-c) \cdot S_{n}\right) Vn=argmaxa∈A−(c⋅Tn+(1−c)⋅Sn)
c=0
V
n
=
argmax
a
∈
A
−
T
n
V_{n}=\operatorname{argmax}_{a \in A}-T_{n}
Vn=argmaxa∈A−Tn
c=1
V
n
=
argmax
a
∈
A
−
S
n
V_{n}=\operatorname{argmax}_{a \in A}-S_{n}
Vn=argmaxa∈A−Sn
总结:只需要编码当前节点作为agent的输入,因为建树是node-by-node,只需要考虑自己的状态,用它们涵盖的区间来对数进行编码
Given d dimensions, we use 2d numbers to encode a tree node, which indicate the left and right boundaries of each dimension for this node.
NeuroCuts通过从环境中获得的奖励来隐式地解释包分类规则。
NeuroCuts learns to account for packet classifier rules implicitly through the rewards it gets from the environment.
- how to deal with the sparse and delayed
奖励的稀疏性咋整
Q π ( s , a ) Q^{\pi}(s, a) Qπ(s,a):策略 π \pi π在状态s下采取行为a后的累计回报数学期望
Q
(
s
,
a
)
←
Q
(
s
,
a
)
+
α
(
r
+
max
a
′
Q
(
s
′
,
a
′
)
−
Q
(
s
,
a
)
)
Q(s, a) \leftarrow Q(s, a)+\alpha\left(r+\max _{a^{\prime}} Q\left(s^{\prime}, a^{\prime}\right)-Q(s, a)\right)
Q(s,a)←Q(s,a)+α(r+maxa′Q(s′,a′)−Q(s,a))
强化学习奖励函数塑形简介(The reward shaping of RL)
会导致variance过大->训练失败
划分树的过程不视作线性的,而是树形的。即:分支决策过程。
一个行为的rewards由其产生的多个子状态聚合而成。比如说切割节点,reward 计算包含了sum或是每个孩子未来rewards的min。如果我们要优化树大小,那么选择sum,如果优化树的深度,选择min。
how to deal with the sparse and delayed rewards incurred by the node-by-node process of building the decision tree. While we could in principle return a single reward to the agent when the tree is complete, it would be very dicult to train an agent in such an environment. Due to the long length of tree rollouts (i.e., many thousands of steps), learning is only practical if we can compute meaningful dense rewards.1 Such a dense reward for an action would be based on the statistics of the subtree it leads to (i.e., its depth or size).将奖励密集化
- 如何将solution扩展到大的网包分类
关于只编码最开始的
Our goal to optimize a global performance objective over the entire tree suggests that we would need to make decisions based on the global state. However, this does not mean that the state representation needs to encode the entire decision tree. Given a tree node, the action on that node only needs to make the best decision to optimize the sub-tree rooted at that node. It does not need to consider other tree nodes in the decision tree.
这两个不是local的
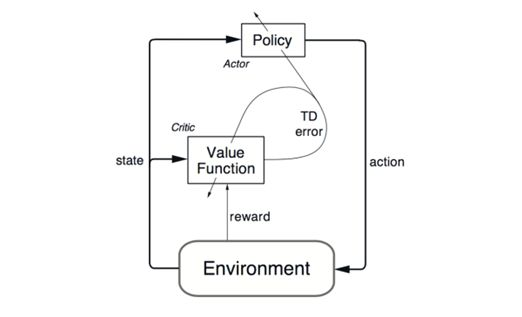
Training Algorithm
an actor-critic algorithm
∑
t
γ
t
r
t
\sum_{t} \gamma^{t} r_{t}
∑tγtrt where
γ
\gamma
γ is a discounting factor
γ
\gamma
γ是大于0小于1的数,越靠近现在越大
end goal是学习最优的随机策略函数
π
(
a
∣
s
;
θ
)
\pi(a | s ; \theta)
π(a∣s;θ),
跑N轮去训练policy和value function,每轮都处理一个root node
通过反复选择和应用action增量建树
迭代地切割子节点知道成为叶节点。
在决策树建好后,梯度重置,算法遍历所有的树节点去累计梯度。最后用梯度来更新网络的actor和critic参数,到下一个rollout














 708
708











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









