







当我们需要执行分页查询时等情况,难免需要执行count操作(或叫count聚合函数),下面分析各种count操作的执行流程和效率。如本文标题,直接先给出结论,按照效率排序:count(字段)<count(主键 id)<count(1)≈count(*),所以尽量使用count(*)。
MyISAM存储引擎内部维护了一个 count(*)的计数器,需要的时候直接访问,所以效率非常的高,但是不支持事务。但是如果count(*)操作后面有where语句时,也需要挨个统计行数。现在基本都会直接使用InnoDB,不仅仅是因为支持事务,Mysql - 争取一篇讲清楚Mysql中的锁(全局锁、表级锁、行级锁)及加锁规则、死锁问题中分析过,当DBA需要执行数据备份时,如果使用全局锁 flush tables with read lock(FTWRL)时会阻塞整个Mysql实例的所有操作,对于高并发系统来说非常危险。但是如果所有表都使用InnoDB引擎的话,就是可以使用官方的mysql-dump配合–single-transaction,底层基于一致性视图非阻塞的完成数据备份。
Mysql中还可以使用 show table status命令查看条数,但是该结果是基于 alalyze table t命令得到的,Mysql - 优化器阶段的索引选择过程中我们知道该命令是按照一定的数据页采样率得到的,Mysql官方之处存在误差的达到 40~50%,所以返回速度非常快,但是不能使用。
InnoDB引擎中执行count操作,需要遍历全表,虽然结果精确但是性能极差。因为InnoDB需要支持事务,内部的MVCC对于每行数据都有多个版本,并且当执行count操作时会创建一个视图(Read View),此时需要根据视图判断行数据本身对该视图是否可见,详细过程可以参考:Mysql - InnoDB引擎对事务ACID的实现原理分析。
下面对InnoDB引擎的各种count操作分析其实现过程,整个过程都是基于Server层的执行器调用InnoDB引擎层的接口实现,如果查询的结果不为Null,就在Server层中计数器叠加1,否则不加。整体遵循三个原则:
- Server层想要什么就给什么;比如count(name字段)就给该字段。
- InnoDB只给必要的字段;
- 现在的优化器只对count(*)优化为“取行数”,其他优化都没有做。其他count类型没有做优化。
count(主键id)
InnoDB会遍历整张表,将每行的id字段都取出来返回给server的执行器。server层拿到id后判断不为空的就叠加1。
count(1)
InnoDB会遍历整张表,但是不会取值。server层对于返回的每一行都放入数字1,进行叠加。count(1)比count(id)快,因为从引擎返回id需要解析数据行,以及拷贝字段值的操作。
count(字段)
如果字段定义为 not null的话,一行一行的读取记录里面的字段,判断不为null就进行叠加1。 如果字段定义为 允许null,那么在执行的时候,判断到有可能是null的情况下,还要把字段再取出来判断一次,不是null才会叠加1。
count(*)
count(*)专门做了优化比较例外,并不会把所有的字段都取出来,而是不取值。
但是对于高并发的系统,如果经常需要对一个页面进行分页展示的话【比如:取前 30行数据,count整张表的条数】。之前有项目中处理分页的逻辑是,如果想要查询分页的30条数据,此时直接查该分页的 31条数据,那么说明还有下一个分页,则直接在前端分页出显示并且能触发下一页即可。前提是产品允许,或者用户允许,可以不查看总页数。 但是如果想要在一个高并发系统中返回正确的条数和分页数据,每次对整张表执行count(*)肯定是不行的。下面有两种逻辑:
1、基于Redis存储该表的总行数
当发生了数据库的增删操作时,调用redis对总行数进行叠加或者叠减,对于redis并发度完全足够了。 但是会导致总条数和分页数据的不一致,需要业务允许。 比如:当执行分页查询时, Redis已经进行了叠加1,而数据库还没有完成新增操作;或者 Redis还没有执行叠加1的操作,而此时数据已经完成了新增操作,并且在分页数据中已经查询到了该新数据。 如果是高并发系统,当执行分页查询的过程中,已经有N多条这样不一致的情况,那么 分页数据和总条数 差距显而易见的 。
2、基于Mysql专门的表存储中行数,再基于事务保证条数和分页数据的一致性
不能直接执行count(*)操作的本质是为了支持事务,底层使用MVCC实现了多版本。也正是因为事务的特点,将添加表数据和对另一张表存储的总条数进行叠加放到同一个事务中,那么基于InnoDB的默认事务隔离级别repeatable read的一致性视图,整个中间过程对外不可见,从而保证一致性,如下图:
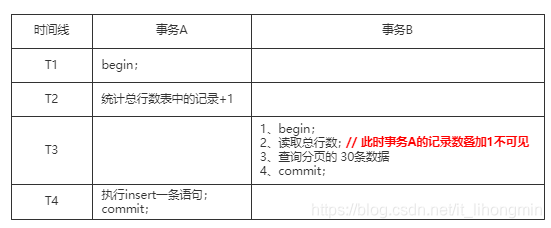
总结: 如果要执行count操作的话,性能排序为:count(字段)<count(主键 id)<count(1)≈count(*),所以尽量使用count(*)。 如果要在高并发的查询中,频繁执行 获取分页数据和或者总条数,可以将总行数专门存储在一张表中,使用事务的一致性视图的特点,将增加(删除)数据和总条数叠加(叠减)放到同一事务保证一致性。














 1934
1934











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









