









1:这个文章是youtube发表的paper,主要是将dnn应用到推荐的召回与排序中。这里主要从几张图说起,不做直接翻译,是带着讲解方式,把重点更清晰的理解出来。首先看下面这个图:

这个图展示了,推荐的整体架构,从上百万级别的视频库里,通过召回,到排序,这个像漏斗一样,逐步把视频的数量级进行减少,直到展现在用户面试只有很少的几个。
召回---->排序----->展现 对应的数量级 百万---->几百---->几个----->展现.
说明:这个架构类似多路召回,看下面还有个其他资源候选,最后都融入到排序系统进行统一排序。(其实这个在实践中也有弊端,实践中比如多路召回,有的是基于长期兴趣,有的短期,如果都纳入一起排序,长期很难排过短期,所以这个还是根据大家各自系统需求来设计。)
2:召回

过程解析:
1:把用户观看过的视频,比如视频ID,用户历史搜索词,用户的属性信息,以及视频发布了多久,这些信息先经过事先embedding,这里可以用word2vector或者自己训练得到的embedding。不过电商里面,这里ID embedding就是商品ID的embedding,不过我们这个embedding可以不止是ID,还可以融入品牌、品类等信息的embedding加进去。
2:因为用户观看的视频不固定,有看多有看少,包括搜索词也一样,那这里为了解决这个动态问题,在上层针对这两块做了average(平均)处理。
3:然后把这些所有的embedding信息直接拼接在一起,然后传到上层隐藏层ReLU层。
4:数据经过几个隐藏层到了最上层后,会经过训练阶段,然后是预测阶段。
5:训练阶段,采用的是多分类方案,他这里的多分类,可是上百万的类别,就像用户喜欢看A视频,分类就要分类到A视频,有多少视频就多少分类,这个是一个极端分类。非常消耗性能的。面对极端分类,目前主要采用两个方法:
一:负采样方式
二:分层softmax
这里采用的是负采样的方式。
6:如何计算分类的概率,公式如下:
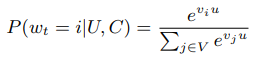
这个公式就是用户U,在上下文C的情况看在时间t时刻,看视频i的概率。就是用用户u的embedding向量与视频库V的向量做点积,然后用指数函数换算下,计算出每个点积的概率是多少。
7:产生候选集,如何产生?这里直接用用户embedding向量与视频的embedding向量做点积,不需要经过softmax,直接取topN最大的N个就行了,做为候选集。这个涉及向量计算,你可以基于faiss这个工具去做这个工程上的事情。想自己写也行。文中说,实际AB测试的实话,数据对ANN算法不敏感。
备注:上层做点击的视频向量,我们可以直接用下面的embedded video watches里面的向量。 选取多少历史视频,我觉得这里我们选取最多50个,用户不够50个,那就有多少就用多少,求平均的时候最好用真实数多少个。
看文章并不一定要实现这个算法,其实里面细节与亮点也很重要:
1:很多连续的特征都被归一化了,归一化到[0,1]之间。
2:增加视频的example age特征,这个特征就是视频从发布到现在的时间,如果没有时间,会把用户表示的更偏旧内容,增加这个特征,可以让用户表示的更偏新的内容,不过在预测阶段这个特征设置为0,让新老视频都是公平对待。这个可以选择最近几周的观看视频,视频越靠后,这个age就越接近于0.这里可以这样看,越新的视频,age趋近于0,如果这个样本预测还是与老视频一样,那新视频本身的权重就高。你也可以这么理解,增加了age这个特征,越成熟上传越久的视频,这个age权重就会越高,但是在预测的时候一下把这个age特征值变成0了,是不是就把本来训练出来的这个权重抑制了。其他的特征权重作用就大了。(简单的处理就是把训练库里视频发布时间与训练时间做个时间差,最大时间差做分母,其他的时间差直接除以这个分母就行)
3:选择训练样本,不能仅仅从推荐场景里获取,要从整个网站考虑用户的点击与观看行为,这样可以避免我们推什么用户看什么,这样学习范围就很窄了。要从整个网站层面上去收集用户的点击行为与观看行为。
4:固定用户的样本数,就是训练时候,为每个用户选取固定一样数量的样本数。这样可以在损失函数的时候控制住每个用户的权重都是一样的。避免活跃用户对损失函数贡献太大,导致权重偏向活跃用户。(这里就是通过样本来控制学习权重一样,想偏向哪些就多选哪些该类的样本)
5:搜索行为要做无序化处理,如果有序的话,会产生过拟合,比如用户最后搜索词,搜索了手机,那推荐结果与搜索结果是一样的,这样会比较差,我们可以基于搜索词分词后,形成词袋,无序输入。这样就不会过拟合,也更加稳定。
6:训练label选取,用户观看视频是有顺序的,不是对称的,比如我们传统的协同过滤其实就没有考虑这样的顺序,是把用户全量历史行为哪来,随机去丢弃其中一个,然后去预测出来,这样其实是把未来信息泄露了。所以我们这里是选取label前面的序列做特征。如下图所示:
7:剩下的提升就是增加网络的宽度与深度,这个根据自己的性能与能力加吧。
8:就是历史观看的视频,搜索词,文中采取的丢弃序列信息,而是直接把视频的ID embedding与搜索词embedding直接加权平均了,没有去考虑序列信息。文中没有按照时间衰减去加权。
3:排序
如下图是排序的整体框架,下面会详细说下这个处理过程

1:输入待评分的impression ID,这个ID经过embedding后,在上层直接与其他特征连接一起,不与历史观看的视频做平均。
2:输入历史观看过的视频ID,这里会有很多ID,不过这里是经过embedding后进行平均了的。
3:其他的特征,比如用户语言,视频语言、从上次观看到现在时间等一起来的数据,都归一化后输入到网络里。
4:一堆特征在网络输入层进行了拼接,拼接后直接给了全连接的Relu层,经过几层后,要准备输出了。
5:如果是训练阶段,不是一个分类问题,这里是回归问题,是采用的是weight-logistic。(为什么要加权,主要是针对用户观看视频进行加权,是基于用户观看时长进行加权的,负样本统一值都是1,正样本按照观看时间加权,加权的方式有多种(1:要么在训练样本的时间加权,就是把正样本加多些,让训练结果往正样本方向偏。2:在计算损失的时候,如果是正样本,正样本的损失值再乘以一个权重值进行加权,让模型训练偏向正样本))
6:在预测阶段,这里没有采用简单的点击率,因为点击率会有误点,还有作弊情况。所以这里直接用了观看时长。看上图,输出层直接用在指数函数上作为激活函数了。。ex了。
备注:他这里有个简单的推导,这里没有必要再写了,直接用就是了,直接用指数函数: 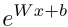
备注:
1:根据用户观看频率选取TON ID
2:ID类的embedding在底层是用来共享的,上层想怎么用就怎么用,单独使用,组合使用。这样效率高。减少内存,比如多值类的embedding,加起来做平均。其实还可以引入分类特征的embedding,比如视频属于哪类,这样同类视频就可以共享这个类别的embedding了。
3:利用预测的值是观看时长
4:神经网络对输入数据的规模与分布比较敏感,很多实验表明对于连续的值,把这些值归一化到【0,1】之间,效果会比较好,收敛也快。不过文章里用的是采用的是一种累积积分分布函数去生成的,不过这个自己看,根据自己喜好与实验,自己选择,不一定非要与论文一样。
5:最后有个评估的 Weighted, peruser loss,就是用用户预测错误的(把正的预测成错误的,把错误的预测成对的)除以总的观看。
6:可以增加一些特征,比如用户在哪个频道浏览,点击次数,以及上次浏览这个频道到现在的时间长度。这个用在电商,就是在浏览某个类目的次数,点击次数,加购次数等。。。。
李春生:负责搜索推荐,工程与算法,对搜索推荐有兴趣的,大家一起交流,相互学习!















 362
362











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









