






1:简介
这个算法是一个通用的打标签算法,无论是图片还是文本,视频,只要能提取特征,然后再提供一个固定的标签集合,就可以使用该算法进行打标签。
比如我们有数据(x,y)我们的x的特征向量是Vx 标签(label)的向量是Wi,那么我们计算x与标签的相似度函数如下:
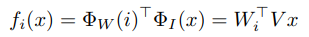
其中: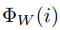 函数就是把i标签变成向量Wi。
函数就是把i标签变成向量Wi。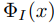 是把x变量向量的函数。这样我们可以根据 fi(x)函数对标签进行排序,相似度越高的就排在前面。
是把x变量向量的函数。这样我们可以根据 fi(x)函数对标签进行排序,相似度越高的就排在前面。
还要增加正则化,这里采用L2正则化:
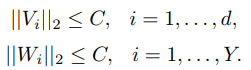
这个就是一个约束,比如Vi就是一个X的向量,约束这个向量的L2是小于一个常数C,Wi是标签的向量,也做了约束。
2:算法步骤
1:我们知道 fi(x)是用来计算x向量与标签的相似度,这里我们直接理解为是标签i的排序值吧。因为越相关,值越大,排序越靠前,所以我们这里直接认为是排序。
2:下面公式就是我们的排序损失函数:
这个就是排序的损失函数,f(x) 是预测的分数,y是真实值。我们看损失函数里面用的是 ranky(f(x),那这个具体的定义如下: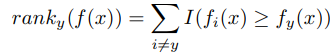
,这个函数是什么意思呢?这个函数就是利用f(x)给真实y排出来的顺序。比如,我们理性状态y应该在第一位,如果现在排在了第10位,那么这个函数的值就是10了。
也可以这么理解,就是x向量与其他标签相似度排在与y前面的标签有多少,如果这个值可以计算得到了,那么我们就可以计算损失函数了,比如这里就用10来计算,那么 L(ranky(f(x))) = L(k) = L(10) = 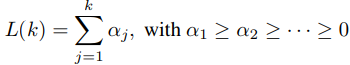
,这个函数中的 αj可以取不同的值,取不同的值代表不同的优化器。如果我们令αj = 1/(Y-1),这样就是一个常数了,这样就比较平均了。所以论文中选择了 αj = 1/j这样的方式。
3:推导损失函数。一:原损失函数
L(ranky(f(x)))
它等价于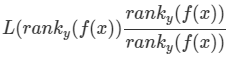 为后面增加的,相除等于1
为后面增加的,相除等于1
我们按照公式展开后就是: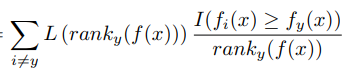
这里我们把ranky(f(x)函数展开了。他展开的公式是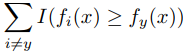 ,我们把求和公式迁移。我们这里规定,如果y标签已经排在最前面,那么ranky(f(x)=0了,这样后面就会出现0/0情况,我们约定下,0/0=0。这样损失就是0,就是最小了。但是我们看上面的公式,居然是一个指示性的函数,不好优化,所以我们需要把上面函数进一步近似,近似成一个连续值的函数方式,这里我们用折页损失函数hinge 0/1去近似。近似后的公式如下:
,我们把求和公式迁移。我们这里规定,如果y标签已经排在最前面,那么ranky(f(x)=0了,这样后面就会出现0/0情况,我们约定下,0/0=0。这样损失就是0,就是最小了。但是我们看上面的公式,居然是一个指示性的函数,不好优化,所以我们需要把上面函数进一步近似,近似成一个连续值的函数方式,这里我们用折页损失函数hinge 0/1去近似。近似后的公式如下: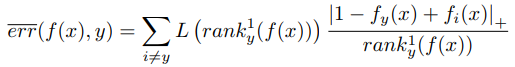 这里的
这里的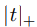 函数是t的正的部分。这样近似我们可以这样理解,分类要么是0,要么是1,如果每个X只有一个标签,那么当y是真实标签的时候, fy(x)=1了,如果存在三个匹配的标签也是1,比如 fi(x) =1,那按照我们之前说定义的, ranky(f(x) =3,这里 |1−fy(x)+fi(x)|+= |1−1+1|+=1 ,因为有三个标签,所以算上连加,就是3,是不是跟原来的比较近似了。那么分母呢?
函数是t的正的部分。这样近似我们可以这样理解,分类要么是0,要么是1,如果每个X只有一个标签,那么当y是真实标签的时候, fy(x)=1了,如果存在三个匹配的标签也是1,比如 fi(x) =1,那按照我们之前说定义的, ranky(f(x) =3,这里 |1−fy(x)+fi(x)|+= |1−1+1|+=1 ,因为有三个标签,所以算上连加,就是3,是不是跟原来的比较近似了。那么分母呢?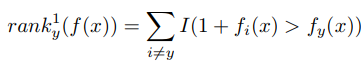 被改写成这样。与原来的
被改写成这样。与原来的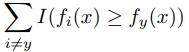 也是一种近似,改写后的是在前面加1了,这样就不需要等于号。二:期望误差
也是一种近似,改写后的是在前面加1了,这样就不需要等于号。二:期望误差
基于数据集(x,y)的分布P(x,y),采用上面的损失函数,我们得到期望误差是: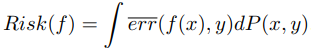 。期望损失。这个类似求的平均值一样,值不过这里有概率密度,所以我们用期望的方式。我们采用解决方案采取抽样的方式,抽样的方法如下:
。期望损失。这个类似求的平均值一样,值不过这里有概率密度,所以我们用期望的方式。我们采用解决方案采取抽样的方式,抽样的方法如下:
一:基于概率分布函数P(x,y)随机获取一个(x,y)
二:对于我们已经抽取到的样本(x,y)我们取它相反的label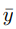 ,这个标签满足
,这个标签满足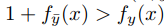 那么我们选择这三元组 (x, y, y¯)他们对整体的期望贡献多大呢?看公式:
那么我们选择这三元组 (x, y, y¯)他们对整体的期望贡献多大呢?看公式: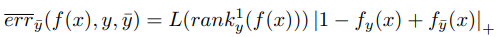 这个就是这个样本对整体期望的贡献。抽样的是一个样本,同时我们还单独抽取了一个负样本标签。那么这个公式是如何近似得到的呢?比如我们函数是f(x), 随机变量概率密度低P,抽样N次,这样的期望是 (f(x)*p)/n ,在这里我们看公式
这个就是这个样本对整体期望的贡献。抽样的是一个样本,同时我们还单独抽取了一个负样本标签。那么这个公式是如何近似得到的呢?比如我们函数是f(x), 随机变量概率密度低P,抽样N次,这样的期望是 (f(x)*p)/n ,在这里我们看公式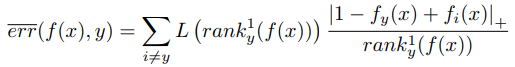 下面的分母就是所有排在正确标签前面错误标签数。这是一个总的期望。那其中每个错误标签对总期望的贡献是多少呢?就是我们不除以 (rank1 y (f(x)))的值,就是这次贡献的。如:
下面的分母就是所有排在正确标签前面错误标签数。这是一个总的期望。那其中每个错误标签对总期望的贡献是多少呢?就是我们不除以 (rank1 y (f(x)))的值,就是这次贡献的。如: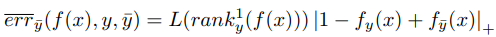 这样算法优化会带来以下问题:
这样算法优化会带来以下问题:
1:我要需要把x向量与所有标签向量做比较,才能知道哪些是正标签,哪些是负标签。这个计算量会很大。
2:就是计算rank1 y (f(x))的时候,我们需要知道,排在正标签前面所有负标签的数量。这个也要去计算,代价比较大。
三:核心思想,也只文章最重要地方
采样,先了解下基础概率中的采样:比如我们有N个苹果,其中有K个是坏的,那么每次有放回的抽样抽到坏的概率P = k/N ,如果我们一直抽样,直到抽到坏苹果,需要抽多次J,J = N/k 次。
那好吧,这里就用到了这个抽样思想,我不是要算排在正标签的负样本数吗?比如我们之前说满足: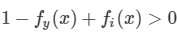 的有k个。那么N个标签里,抽到这样标签概率是 P = K/N-1
的有k个。那么N个标签里,抽到这样标签概率是 P = K/N-1
那么我们想抽到这样的标签,需要抽样的次数 E = N-1/k 那么E就是我们抽样次数了,我们通过抽样次数,就能近似出来有多少个k是满足上述公式了 k = N-1/E
下面算法中,用N作为抽样次数,如下: 这个算法的W V在初始化的实话,选择的是随机初始化,选的均值为0,标准差为
这个算法的W V在初始化的实话,选择的是随机初始化,选的均值为0,标准差为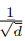 d是维度。
d是维度。
李春生:负责搜索推荐,工程与算法,对搜索推荐有兴趣的,大家一起交流,相互学习!















 2058
2058











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









