







Spark是大数据体系的明星产品,是一款高性能的分布式内存迭代计算框架,可以处理海量规模的数据。下面就带大家来学习今天的内容!
往期内容:
- Spark基础入门-第一章:Spark 框架概述
- Spark基础入门-第二章:Spark环境搭建-Local
- Spark基础入门-第三章:Spark环境搭建-StandAlone
- Spark基础入门-第四章:Spark环境搭建-StandAlone-HA
- Spark基础入门-第五章:环境搭建-Spark on YARN
- Spark基础入门-第六章:PySpark库
一、本机PySpark环境配置
Hadoop DDL(Windows系统) mac系统可以 忽略
1. 将课程资料中提供的: hadoop-3.3.0 文件件, 复制到一个地方, 比如E:\softs\hadoop-3.0.0
2. 将文件夹内bin内的hadoop.dll复制到: C:\Windows\System32里面去
3. 配置HADOOP_HOME环境变量指向 hadoop-3.3.0文件夹的路径, 如下图
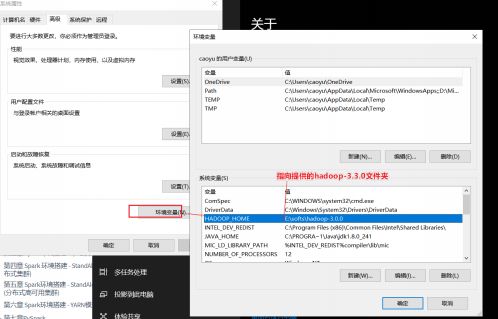
配置这些的原因是:
hadoop设计用于linux运行, 我们写spark的时候 在windows上开发 不可避免的会用到部分hadoop功能,为了避免在windows上报错, 我们给windows打补丁。
Anaconda和PySpark安装
前面我们在部署Spark的时候, 在Linux系统上配置了Anaconda的Python环境, 供Spark集群使用. 现在, 如果我们要在个人电脑上开发Python Spark程序, 也需要配置Python(Anaconda)和PySpark库 在Windows上安装Anaconda 参见:<<spark环境部署.doc>>
安装PySpark库:
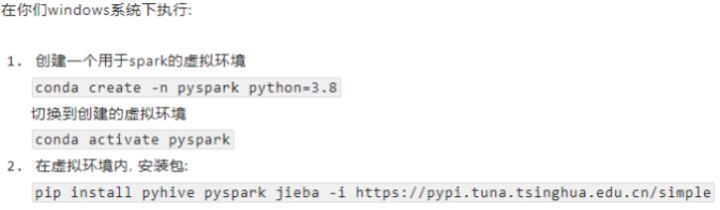
pip install pyhive pyspark jieba -i https://pypi.tuna.tsinghua.edu.cn/simple
二、PyCharm配置Python解释器
配置本地解释器
- 创建PythonProject工程需要设置Python解析器 ,然后点击创建即可
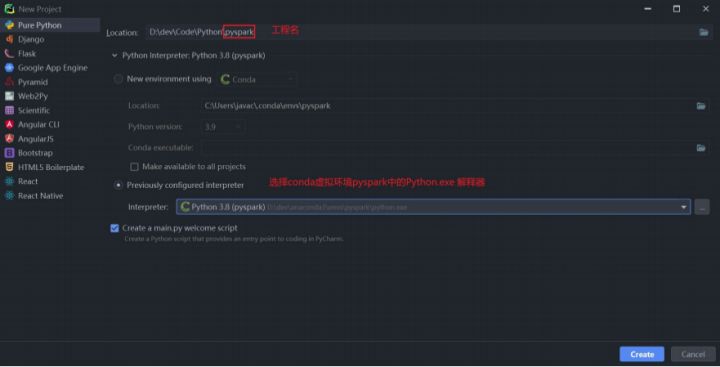
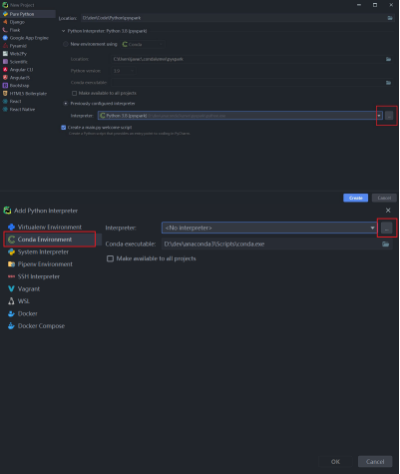
- 如果没有找到conda虚拟环境的解释器,可以:

配置远程SSH Linux解释器
刚刚,配置了本地的Python(基于conda虚拟环境)的解释器, 现在我们来配置Linux远程的解释器
PySpark支持在Windows上执行,但是会有性能问题以及一些小bug, 在Linux上执行是完美和高效的.
所以, 我们也可以配置好Linux上的远程解释器, 来运行Python Spark代码.
配置远程SSH Linux解释器
1) 设置远程SSH python pySpark 环境
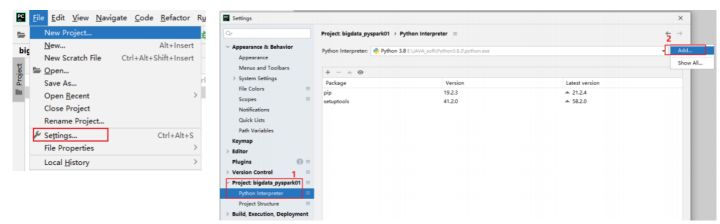
2) 添加新的远程连接
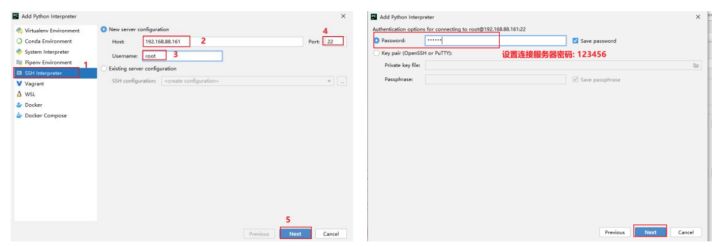
3) 设置虚拟机Python环境路径

三、应用入口: SparkContext
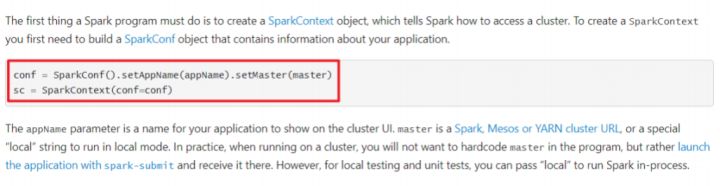
Spark Application程序入口为: SparkContext,任何一个应用首先需要构建SparkContext对象,如下两步构建: 第一步、创建SparkConf对象
设置Spark Application基本信息,比如应用的名称AppName和应用运行Master
第二步、基于SparkConf对象, 创建SparkContext对象
文档: http://spark.apache.org/docs/3.1.2/rdd-programming-guide.html
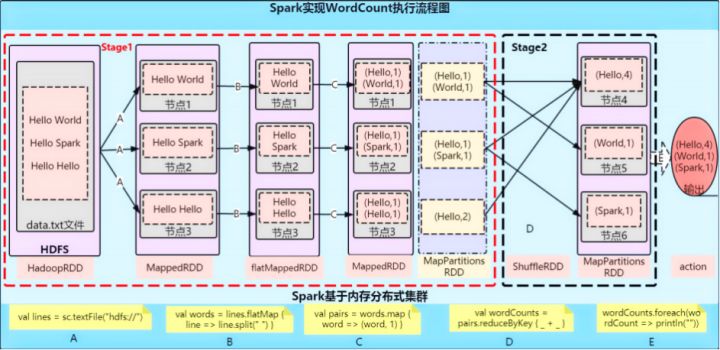
四、WordCount代码实战
- 本地准备文件word.txt
hello you Spark Flink
hello me hello she Spark
- PySpark代码
这里大家主要学习如何构建SparkContext对象 WordCount API在RDD阶段会详解

原理分析:
切换到远程SSH 解释器执行(在Linux系统上执行)
要注意, 远程解释器,本质上是在服务器上执行, 那么读取的文件,也应该是服务器上的文件路径.
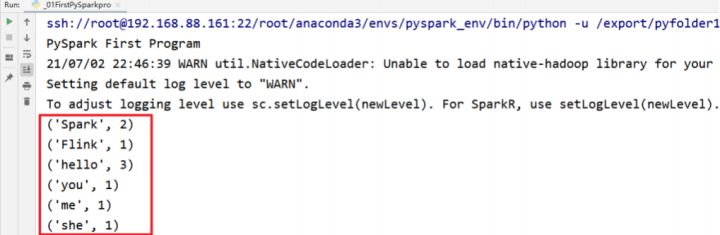
五、代码结果解析
- 执行结果如下:
六、从HDFS读取数据
- 上传数据到HDFS中:
hdfs dfs -put word.txt /input/words.txt
hdfs dfs -ls /input
- 需要调整的代码:
# 第一步、读取本地数据 封装到RDD集合,认为列表List
wordsRDD = sc.textFile("hdfs://node1:8020/pydata/")
# 输出到本地文件中
resultRDD.saveAsTextFile("hdfs://node1:8020/pydata/output1/")
print('停止 PySpark SparkSession 对象')
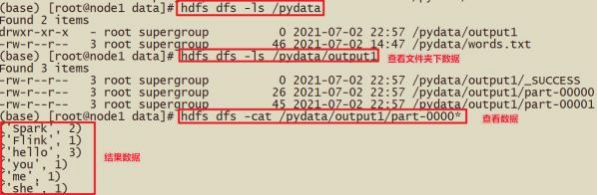
- hdfs dfs -cat /output/output1/*

七、提交代码到集群执行
现在将代码提交到YARN集群进行测试.
提交集群对代码:setMaster部分进行删除
因为提交到集群可以通过客户端工具的参数指定master, 比如spark-submit工具.
所以,我们不在代码中固定master的设置, 不然客户端工具参数无效, 代码的优先级是最高的.
- PySpark程序将Python代码以及数据部分上传到centos集群node1机器上, 执行spark-submit就可以执行该任务。
- bin/spark-submit --master local[2] --name wordcount01 /export/pyfolder1/pyspark-
chapter01_3.8/main/_03FirstPySparkSubmit.py file:///export/pyfolder1/pyspark-
chapter01_3.8/data/word.txt

结果如下:
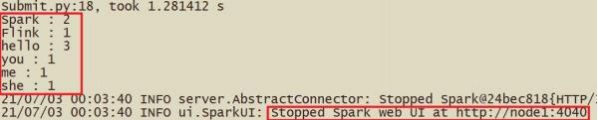
截图如下:
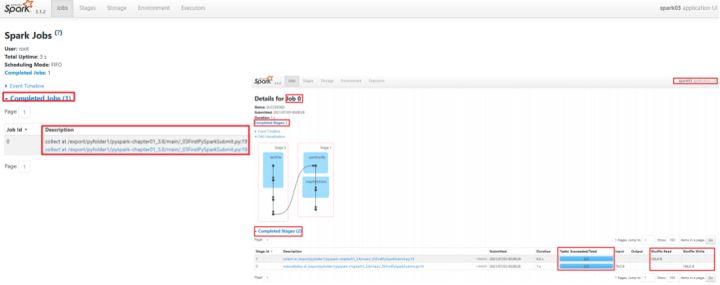
上述的4040随着SparkContext停止就不能访问,但是由于spark配置的时候使用了历史日志服务器,因此可以通过 http://192.168.88.161:18080/访问spark的historyserver观看任务执行情况:















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









