





Twenty Newsgroups Classification实例任务跑的是哪个算法?就是bayesian,也就是我们说的贝叶斯,首先不管你是否了解贝叶斯算法(说实话,我真的不知道这个算法的原理),如果你看了这篇博客,至少应该了解如何对数据 进行处理,然后就可以分类了,不管它是啥算法,好,来开始。
接上篇系列blog: Twenty Newsgroups Classification实例任务之TrainNaiveBayesJob(一),其实贝叶斯算法从上篇博客才开始算是开始,之前的都是文本处理的内容,不看也可以,作用不大(下篇博客就说针对一般的直接数值型输入文件如何应用贝叶斯算法)。
首先来分析下原始数据:原始数据有20个文件夹,每个文件夹里面有n个子文件,经过一系列的转换每个子文件被用一组单词和单词出现的次数(次数也是经过转换的,好像叫做tfdif之类的,具体没咋了解)来表示,所以可以看做如下的形式:
directory1:{
direcctory1_file1:[word_a:3.2,word_b:2.2...]
directory1_file2:[word_a:3.2,word_b:2.2...]
}
directory2:{
direcctory2_file1:[word_a:3.2,word_b:2.2...]
directory2_file2:[word_a:3.2,word_b:2.2...]
}
...TrainNaiveByaesJob的第一个任务其实就是把20个文件中各自所有文件整合到如下的形式(所谓的整合就是把对应单词的出现次数全部相加):
directory1:{
direcctory1_files:[word_a:6.4,word_b:4.4...]
}
directory2:{
direcctory2_files:[word_a:6.4,word_b:4.4...]
}
...然后来分析index的问题,上次大概说了下意思,这里详细分析下:
TrainNaiveBayesJob里面的createLabelIndex方法里面的
SequenceFileDirIterable<Text, IntWritable> iterable =
new SequenceFileDirIterable<Text, IntWritable>(getInputPath(), PathType.LIST, PathFilters.logsCRCFilter(), getConf());Collection<String> seen = new HashSet<String>();
int i = 0;
try {
for (Object label : labels) {
String theLabel = ((Pair<?,?>) label).getFirst().toString().split("/")[1];
if (!seen.contains(theLabel)) {
writer.append(new Text(theLabel), new IntWritable(i++));
seen.add(theLabel);
}
}
} finally {
Closeables.closeQuietly(writer);
}然后到第二个prepareJob。这个job主要看weightsMapper这个类文件,这里面定义了两个Vector,分别是:
private Vector weightsPerFeature;
private Vector weightsPerLabel;weightsPerFeature.assign(instance, Functions.PLUS);
weightsPerLabel.set(label, weightsPerLabel.get(label) + instance.zSum());directoryall:{
direcctoryall_files:[word_a:12.8,word_b:8.8...]
}
然后到了weightsPerLabel,首先要搞清楚instance.zSum()是干嘛的,这个是把所有instance的值全部加起来,好吧,那应该就可以猜到weightsPerLabel的值了,如下:directory_1:{[word_all:10.8]}
directory_2:{[word_all:10.8]}
...
所以weightsPerFeature应该是一个一维的,size是单词个数的向量;weightsPerLabel是一个一维的,size是标识个数的向量;
cleanup输出这两个向量:
ctx.write(new Text(TrainNaiveBayesJob.WEIGHTS_PER_FEATURE), new VectorWritable(weightsPerFeature));
ctx.write(new Text(TrainNaiveBayesJob.WEIGHTS_PER_LABEL), new VectorWritable(weightsPerLabel));
然后就到了第三个prepareJob了,什么?第三个?不是说有两个的么,的确是,看log信息的确是两个,但是源码里面有三个,这个是怎么回事?好吧,源码里面的job没有提交:
/* TODO(robinanil): Enable this when thetanormalization works.
succeeded = thetaSummer.waitForCompletion(true);
if (!succeeded) {
return -1;
}*/然后就得到模型了,然后就完了。额 ,完了?
好吧,还没。继续看下面:
NaiveBayesModel naiveBayesModel = BayesUtils.readModelFromDir(getTempPath(), getConf());
naiveBayesModel.validate();
naiveBayesModel.serialize(getOutputPath(), getConf());后面两个就不看了,主要看下模型是如何得到的:
public static NaiveBayesModel readModelFromDir(Path base, Configuration conf) {
float alphaI = conf.getFloat(ThetaMapper.ALPHA_I, 1.0f);
// read feature sums and label sums
Vector scoresPerLabel = null;
Vector scoresPerFeature = null;
for (Pair<Text,VectorWritable> record : new SequenceFileDirIterable<Text, VectorWritable>(
new Path(base, TrainNaiveBayesJob.WEIGHTS), PathType.LIST, PathFilters.partFilter(), conf)) {
String key = record.getFirst().toString();
VectorWritable value = record.getSecond();
if (key.equals(TrainNaiveBayesJob.WEIGHTS_PER_FEATURE)) {
scoresPerFeature = value.get();
} else if (key.equals(TrainNaiveBayesJob.WEIGHTS_PER_LABEL)) {
scoresPerLabel = value.get();
}
}
Preconditions.checkNotNull(scoresPerFeature);
Preconditions.checkNotNull(scoresPerLabel);
Matrix scoresPerLabelAndFeature = new SparseMatrix(scoresPerLabel.size(), scoresPerFeature.size());
for (Pair<IntWritable,VectorWritable> entry : new SequenceFileDirIterable<IntWritable,VectorWritable>(
new Path(base, TrainNaiveBayesJob.SUMMED_OBSERVATIONS), PathType.LIST, PathFilters.partFilter(), conf)) {
scoresPerLabelAndFeature.assignRow(entry.getFirst().get(), entry.getSecond().get());
}
Vector perlabelThetaNormalizer = scoresPerLabel.like();
/* for (Pair<Text,VectorWritable> entry : new SequenceFileDirIterable<Text,VectorWritable>(
new Path(base, TrainNaiveBayesJob.THETAS), PathType.LIST, PathFilters.partFilter(), conf)) {
if (entry.getFirst().toString().equals(TrainNaiveBayesJob.LABEL_THETA_NORMALIZER)) {
perlabelThetaNormalizer = entry.getSecond().get();
}
}
Preconditions.checkNotNull(perlabelThetaNormalizer);
*/
return new NaiveBayesModel(scoresPerLabelAndFeature, scoresPerFeature, scoresPerLabel, perlabelThetaNormalizer,
alphaI);
}即标识*单词个数这样维度的向量,使用scoresPerLabelAndFeature表示,然后就把这三个变量存入了model里面了(最后一行最后两个参数都是常量,可以不管)。
这样模型就建好了。这时就会产生疑问了?模型有了?如何用?
额,好吧,我直接说了:参考mahout bayesian 算法数据流,下载excel点击f2看里面的公式。这里简单的说明下:
(1)首先,原始数据是1到10行的一个向量集合,每个向量由a,b,c三个属性,最后面是它的标识,比如第10行(行号为10),属于第4类;所以标识有4个,属性(对应于前面的单词个数)有3个;
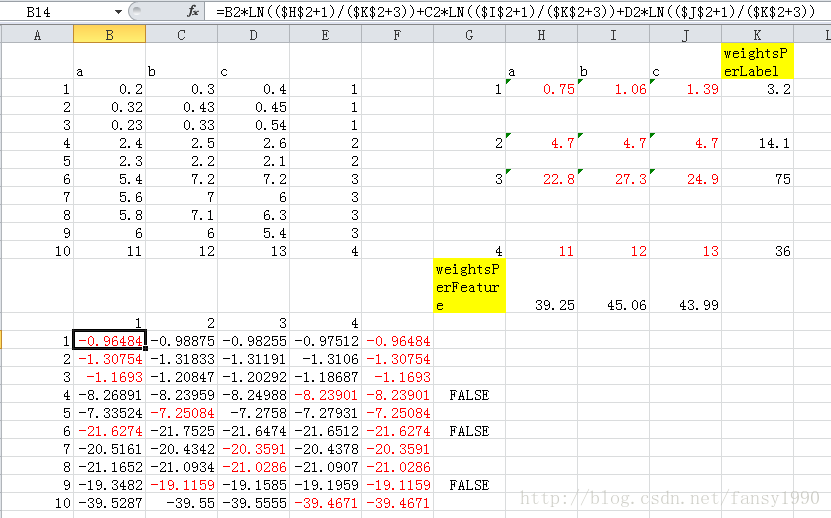
(2)计算weightsPerLabel(4*1向量),weightsPerFeature(1*3向量)分别由图中黄色格子标出,scoreFeatureAndLabel(4*3向量)由图中红色字体标出
(3)按照最上面的计算公式就可以计算出来第一行数据的label_1的参数值,然后计算label_2的参数值,一直到label_4的参数值,然后求出这些参数值的最大值所在的label就是这行数据应该被分入的标识了。
看到上面的10行数据有3行是被分错了。
这个,好吧,基本就是mahout中bayesian算法的实现了,不过说实话,贝叶斯算法就是这样的?
下篇,针对这样的数据应用贝叶斯算法:
0.2 0.3 0.4 1
0.32 0.43 0.45 1
0.23 0.33 0.54 1
2.4 2.5 2.6 2
2.3 2.2 2.1 2
5.4 7.2 7.2 3
5.6 7 6 3
5.8 7.1 6.3 3
6 6 5.4 3
11 12 13 4
分享,成长,快乐
转载请注明blog地址:http://blog.csdn.net/fansy1990















 1824
1824











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









