





分布式高可用键值对数据库Riak - 背景篇(1)
Riak简介
典型的现代关系数据库在某些类型的应用程序中表现平平,难以满足如今的互联网应用程序的性能和可扩展性要求。因此,需要采用不同的方法。在过去几年中,一种新的数据存储类型变得非常流行,通常称为 NoSQL,因为它可以直接解决关系数据库的一些缺陷。Riak 就是这类数据存储类型中的一种。
Riak 并不是惟一的一种 NoSQL 数据存储。另外两种较流行的数据存储是 MongoDB 和 Cassandra。尽管在许多方面十分相似,但是它们之间也存在明显的不同。例如,Riak 是一种分布式系统,而 MongoDB 是一种单独的系统数据库,也就是说,Riak 没有主节点的概念,因此在处理故障方面有更好的弹性。尽管 Cassandra 同样是基于 Amazon 的 Dynamo 描述,但是它在组织数据方面摒弃了向量时钟和相容散列等特性。Riak 的数据模型更加灵活。在 Riak 中,在第一次访问 bucket 时会动态创建这些 bucket;Cassandra 的数据模型是在 XML 文件中定义的,因此在修改它们过后需要重启整个集群。
Riak 是用 Erlang 编写的。而 MongoDB 和 Cassandra 是用通用语言(分别为 C++和 Java)编写,因此 Erlang 从一开始就支持分布式、容错应用程序,所以更加适用于开发 NoSQL 数据存储等应用程序,这些应用程序与使用 Erlang 编写的应用程序有一些共同的特征。
Riak支持Map/Reduce 作业,但是Map/Reduce 作业只能使用 Erlang 或 JavaScript 编写。
分布式存储?一个头疼的问题
目前,基于互联网的业务都处于量级高速变化的状态(要么增长特别快,要么萎缩特别快)。一个比较头疼的问题就是如何存储并保持高速访问业务数据。很多公司采用了分布式存储的解决方案,这带来了一些更令人头疼的问题:
- 很难扩容:如果现在业务发展迅速,3台主机撑不住了,需要加到5台主机,那要如何处理呢?首先要更改分类方法,把用户分成5类,然后重新迁移已经存在的数据。你要在网站上贴个条子,“系统维护中”,然后开始伟大的迁移工程,等到终于迁移完成,发现其实3台也不用了,用户都走光了-_-。
- 数据高可用性无法保证:有一天,发现有一台数据库服务器的硬盘坏了,这下麻烦就来了,本来网站就不赚钱,没用什么高档机器,只有一个定期的增量备份而已。经过一天复杂的恢复工作,你还要对部分用户说,麻烦你们把做过的事情再做一遍啊。然后用户对你说go fuck yourself,你发现你再也不用维护或者恢复用户数据了,因为他们又走光了。
- 单点问题:负责把用户分类,然后决定使用哪个数据服务器的那台主机是网站的命根子啊,它如果宕机,所有的数据都不能访问了,它如果满负荷了,增加数据服务器也不会对整体性能有帮助。我好像看到一台贴满着驱邪保平安符咒的pc server。
- 写入还要重试:倘若你后台某个用户对应的存储介质因为某不可知原因挂掉了,用户发现无论发送什么请求后台都没反应,也不知道自己的请求到底成功没有。这时考验用户忠诚度和心理素质的时候到了,想想如果是像支付宝买一件奢侈品的时候,你敢重试好几次么。
接下来我们将针对每个问题将Dynamo的解决方案展示给大家。
Dynamo扩容与一致性哈希
我们运用快递员与运单的场景,假设我们的数据库存储每个快递员的所有运单记录。现在有A,B,C,D,E这五台机器,有200个快递员,有2000条运单记录。我们很容易想到通过哈希取模来平均分配这200个快递员与2000个运单对应关系。通过快递员对5取模,即A(1,6,11,16…), B(2,7,12,17…), C(3,8,13,18…), D(4,9,14,19…), E(5,10,15,20…),保存对应的快递员与运单关系(其实就是快递员为key运单为value)。
如果这时,我们想扩容到六台,那么变成A(1,7,13,19…), B(2,8,14,20…), C(3,9,15…), D(4,10,16…), E(5,11,17…), F(6,12,18…). 迁移量非常大。如何减少迁移量呢?
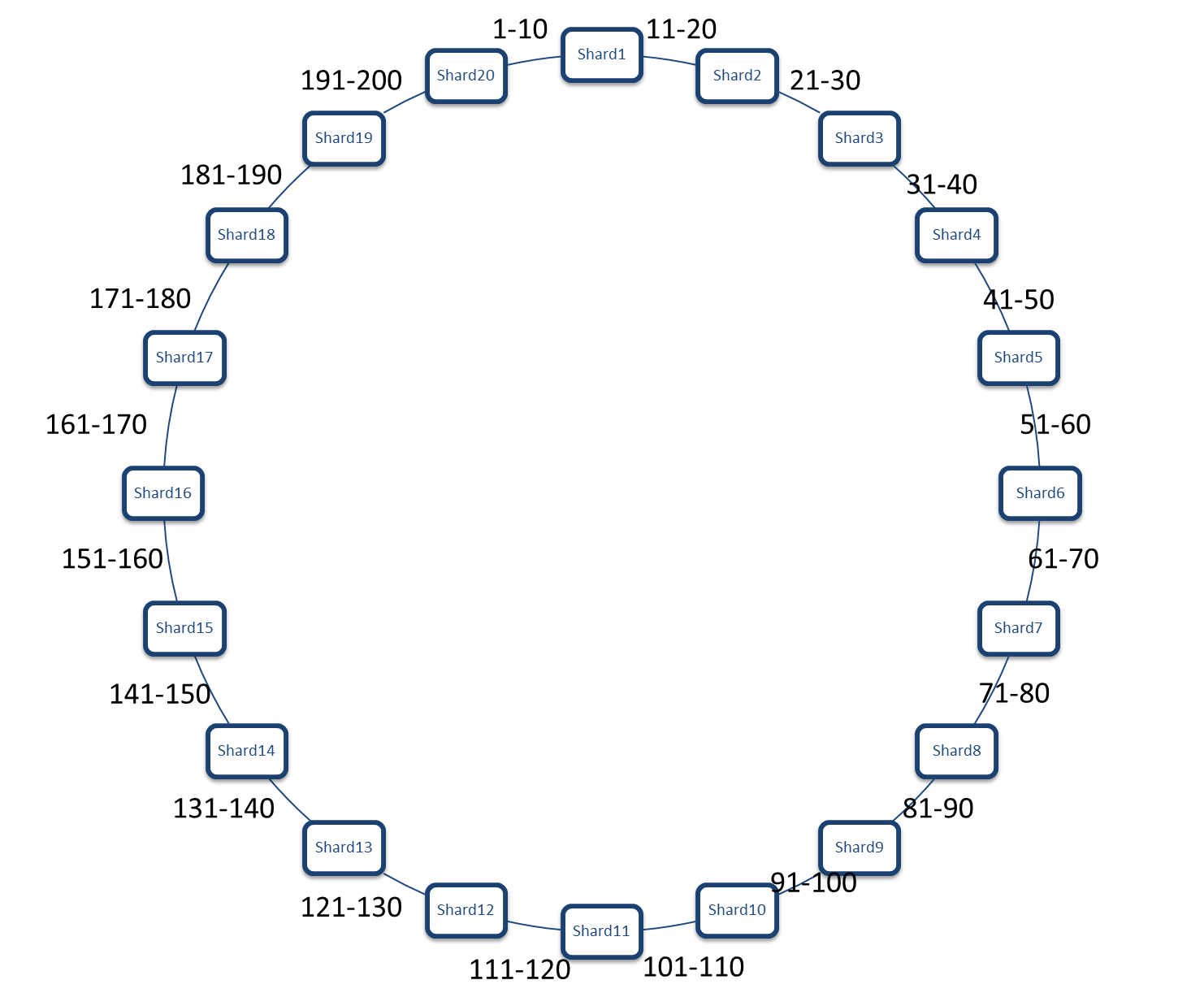
Dynamo采用一致性哈希的方法,首先,我们假设有S=20个逻辑分片。然后200个快递员的哈希值处理之后落到的区域正好如下图所示:
每个快递员的键值对都会落到这个环上,假设我们这里一致哈希算法是按快递员号码进行的。Shard1负责1-10,Shard2负责11-20,以此类推。因为快递员的能力是差不多的,所以当资源节点的数量足够多的时候,可以认为每个节点的负载基本是均衡的。这是原始的consistent hashing。
Dynamo并没有采用这个模型。这个理想的理论模型跟现实之间有一个问题,在这个理论模型上,每个资源节点的能力是一样的。我的意思是,他们有相同的cpu,内存,硬盘等,也就是有相同的处理能力。可现实世界,我们使用的资源却各有不同,新买的n核机器和老的奔腾主机一起为了节约成本而合作。如果只是这么简单的把机器直接分布上去,性能高的机器得不到充分利用,性能低的机器处理不过来。
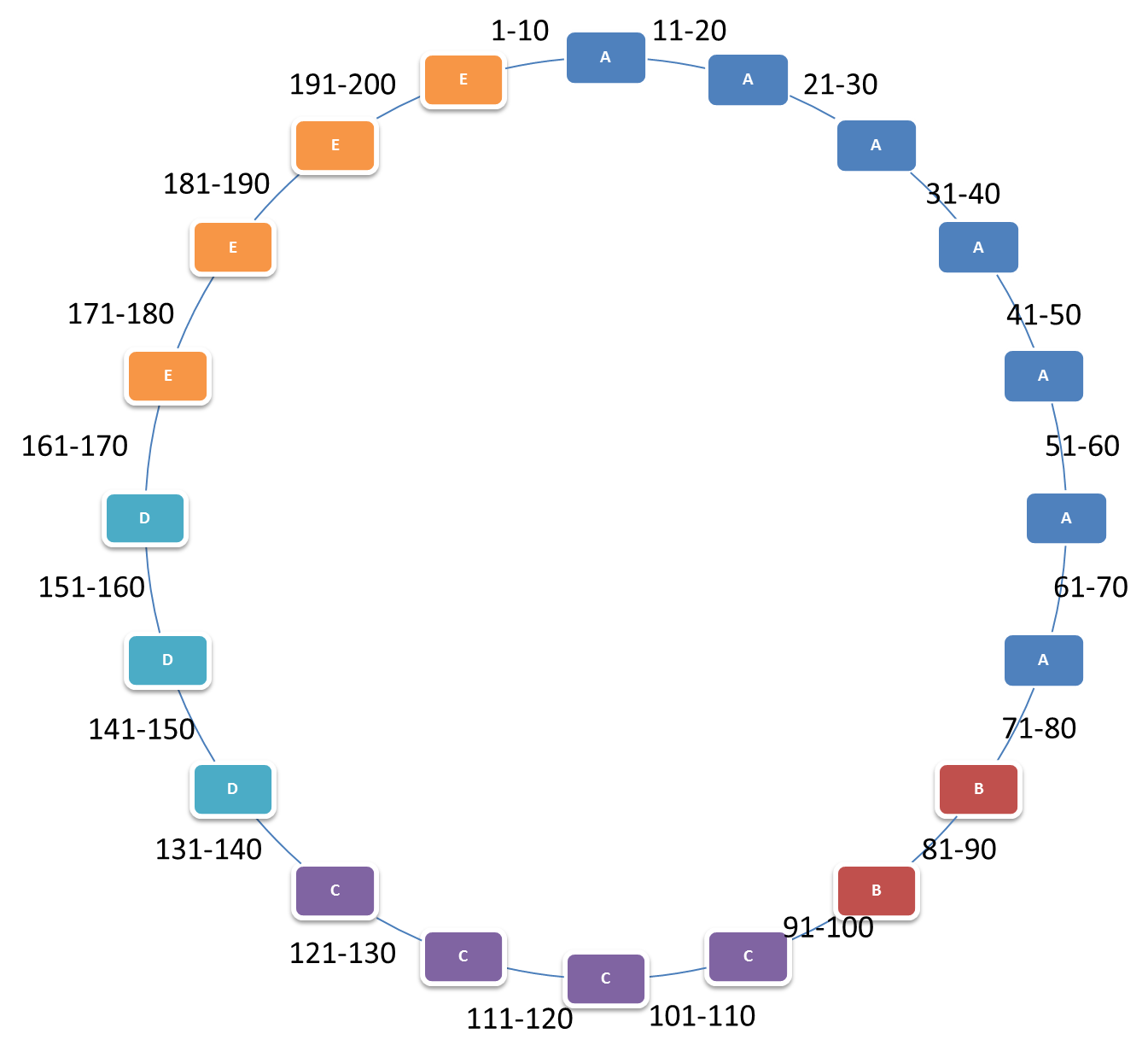
所以,Dynamo使每个物理机器按照能力包含不同个分片节点。假设还是刚才那5台机器, 一种分配方案就是:
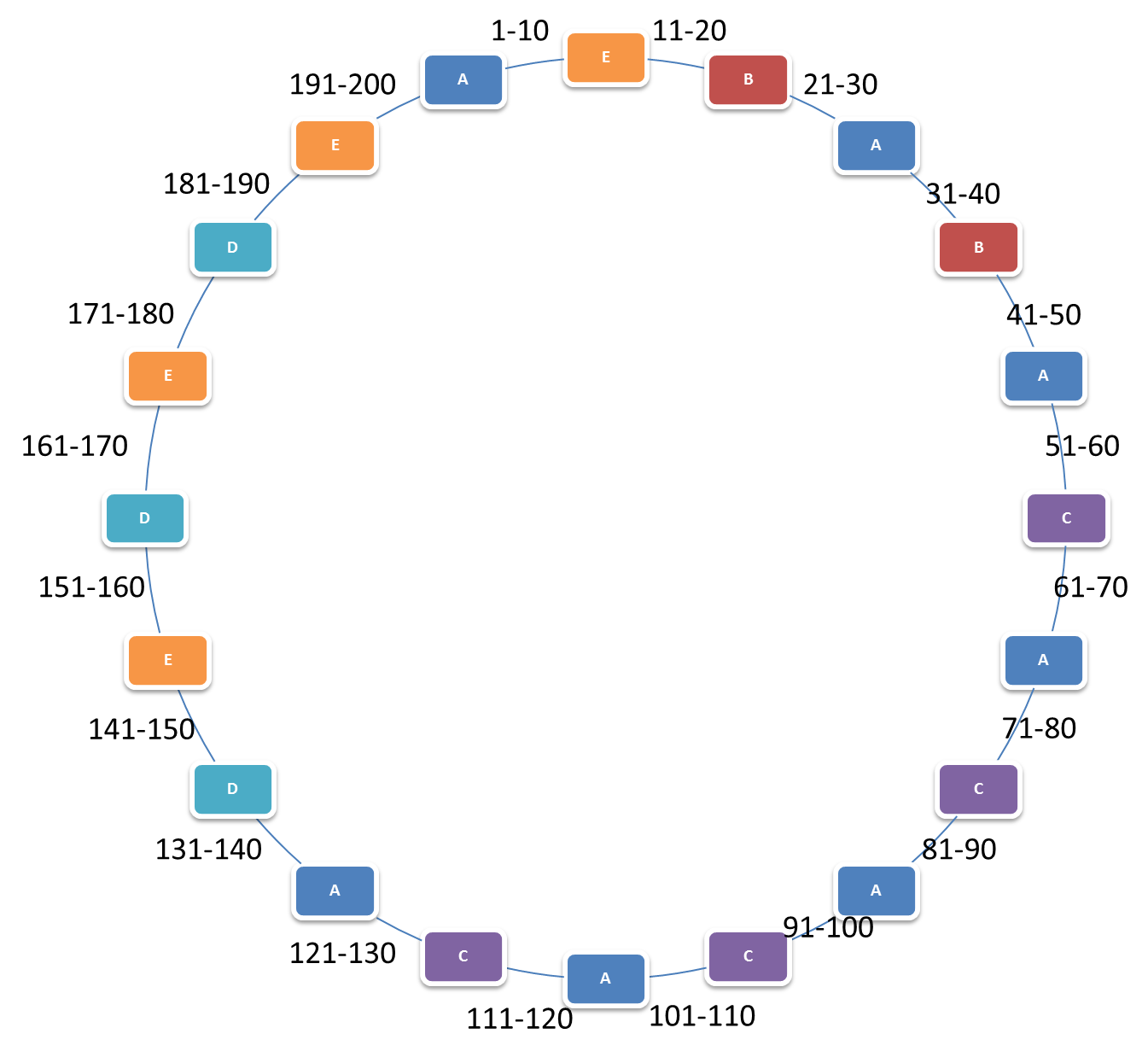
这样,即是一台机器挂了,所做的迁移量也只是那台机器上的数据。新加入的机器所要迁移的数据也只是他所要保存的数据。但是,这种方案还是有问题,假设A机器挂了,那么他的所有数据全都跑到了B上,而从上图可以看出,B的性能不是很好。所以,最好还是采用下种方案避免这种现象:
采用这种方法的前提是逻辑分片个数S要大于物理机个数P(如果P>S,不是不可以,就是多余出来机器没有分片需要它去承载)。这里就是20>5. 假设考虑到高可用一份数据要复制n份,那么我们就要保证S>n*P.















 234
234

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









