









 本文探讨了过拟合在机器学习中的成因与解决策略,包括正则化、Dropout、EarlyStopping等方法,通过实例展示了如何在神经网络中应用这些技术。
本文探讨了过拟合在机器学习中的成因与解决策略,包括正则化、Dropout、EarlyStopping等方法,通过实例展示了如何在神经网络中应用这些技术。
过拟合(overfitting)现象:训练集准确率(高)与验证集准确(低)率差异过大
欠拟合(underfitting)现象:训练集和测试集准确率都偏低
欠拟合也叫作叫高偏差(bias),过拟合也叫高方差(variance)

原因:
-
训练集的数量级和模型的复杂度不匹配。训练集的数量级要小于模型的复杂度;
-
训练集和测试集特征分布不一致;
-
样本里的噪音数据干扰过大,大到模型过分记住了噪音特征,反而忽略了真实的输入输出间的关系;
-
权值学习迭代次数足够多(Overtraining),拟合了训练数据中的噪声和训练样例中没有代表性的特征。
解决方法:
-
simpler model structure:调小模型复杂度,使其适合自己训练集的数量级(缩小宽度和减小深度)
-
data augmentation:数据扩充,训练集越多,过拟合的概率越小。在计算机视觉领域中,增广的方式是对图像旋转,缩放,剪切,添加噪声等。
-
regularization:参数太多,会导致我们的模型复杂度上升,容易过拟合,也就是我们的训练误差会很小。 正则化是指通过引入额外新信息来解决机器学习中过拟合问题的一种方法。这种额外信息通常的形式是模型复杂性带来的惩罚度。 正则化可以保持模型简单,另外,规则项的使用还可以约束我们的模型的特性。
-
dropout:这个方法在神经网络里面很常用。dropout方法是ImageNet中提出的一种方法,通俗一点讲就是dropout方法在训练的时候让神经元以一定的概率不工作。
-
early stopping:对模型进行训练的过程即是对模型的参数进行学习更新的过程,这个参数学习的过程往往会用到一些迭代方法,如梯度下降(Gradient descent)学习算法。Early stopping便是一种迭代次数截断的方法来防止过拟合的方法,即在模型对训练数据集迭代收敛之前停止迭代来防止过拟合。
-
ensemble:集成学习算法也可以有效的减轻过拟合。Bagging通过平均多个模型的结果,来降低模型的方差。Boosting不仅能够减小偏差,还能减小方差。(boosting可以解决欠拟合)
import cv2
import os
import tensorflow as tf
import numpy as np
import matplotlib.pyplot as plt
path='flower_photos/'
读取数据集图片并添加标签,最后的形式是data 对应图片, label 是标签,roses 0,daisy 1,sunflowers 2,tulips 3,dandelion 4.
def read_img(path):
imgs=[]
labels=[]
cate=[path+x for x in os.listdir(path) if os.path.isdir(path+x)]
for idx,i in enumerate(cate):
for j in os.listdir(i):
im = cv2.imread(i+'/'+j)
img = cv2.resize(im, (100,100))/255.
#print('reading the images:%s'%(i+'/'+j))
imgs.append(img)
labels.append(idx)
return np.asarray(imgs,np.float32),np.asarray(labels,np.int32)
data,label=read_img(path)
将数据集打乱顺序
num_example=data.shape[0] # data.shape是(3029, 100, 100, 3)
arr=np.arange(num_example)# 创建等差数组 0,1,...,3028
np.random.shuffle(arr)# 打乱顺序
data=data[arr]
label=label[arr]
print(label)
[4 3 4 ... 1 0 1]
标签one-hot处理
def to_one_hot(label):
return tf.one_hot(label,5)
label_oh = to_one_hot(label)
将所有数据集分为训练集80%、测试集20%
ratio=0.8
s=np.int(num_example*ratio)
x_train=data[:s]
y_train=label_oh.numpy()[:s]
x_val=data[s:]
y_val=label_oh.numpy()[s:]
搭建网络
class large_model(tf.keras.Model):
def __init__(self):
super().__init__()
# 卷积层
self.conv1 = tf.keras.layers.Conv2D(
filters=32, # 卷积层神经元(卷积核)数目
kernel_size=[3, 3], # 感受野大小
padding='same', # padding策略(vaild 或 same)
activation=tf.nn.relu # 激活函数
)
# 池化层
self.pool1 = tf.keras.layers.MaxPool2D(pool_size=[2, 2], strides=2)
self.flatten = tf.keras.layers.Flatten()
self.dense1 = tf.keras.layers.Dense(units=128, activation=tf.nn.relu)
self.dense2 = tf.keras.layers.Dense(units=5)
def call(self, inputs):
x = self.conv1(inputs)
x = self.pool1(x)
x = self.flatten(x)
x = self.dense1(x)
x = self.dense2(x)
output = tf.nn.softmax(x)
return output
large_model = large_model()
large_model.compile(optimizer=tf.keras.optimizers.Adam(learning_rate=0.001),
loss = tf.keras.losses.categorical_crossentropy,
metrics=[tf.keras.metrics.categorical_accuracy])
history = large_model.fit(x_train, y_train, batch_size=64, epochs=10, validation_split=0.2)
Train on 2348 samples, validate on 588 samples
Epoch 1/10
2348/2348 [==============================] - 9s 4ms/sample - loss: 2.1651 - categorical_accuracy: 0.3790 - val_loss: 1.2875 - val_categorical_accuracy: 0.4609
Epoch 2/10
2348/2348 [==============================] - 8s 3ms/sample - loss: 1.0091 - categorical_accuracy: 0.6129 - val_loss: 1.1533 - val_categorical_accuracy: 0.5476
Epoch 3/10
2348/2348 [==============================] - 8s 3ms/sample - loss: 0.7414 - categorical_accuracy: 0.7453 - val_loss: 1.1719 - val_categorical_accuracy: 0.55273s - loss: 0.7
Epoch 4/10
2348/2348 [==============================] - 8s 4ms/sample - loss: 0.5352 - categorical_accuracy: 0.8322 - val_loss: 1.2183 - val_categorical_accuracy: 0.5510
Epoch 5/10
2348/2348 [==============================] - 8s 4ms/sample - loss: 0.3590 - categorical_accuracy: 0.9089 - val_loss: 1.2133 - val_categorical_accuracy: 0.5476
Epoch 6/10
2348/2348 [==============================] - 8s 3ms/sample - loss: 0.2420 - categorical_accuracy: 0.9446 - val_loss: 1.2393 - val_categorical_accuracy: 0.5816
Epoch 7/10
2348/2348 [==============================] - 8s 3ms/sample - loss: 0.1437 - categorical_accuracy: 0.9779 - val_loss: 1.2860 - val_categorical_accuracy: 0.5782
Epoch 8/10
2348/2348 [==============================] - 8s 4ms/sample - loss: 0.0900 - categorical_accuracy: 0.9902 - val_loss: 1.3834 - val_categorical_accuracy: 0.5663
Epoch 9/10
2348/2348 [==============================] - 8s 3ms/sample - loss: 0.0585 - categorical_accuracy: 0.9953 - val_loss: 1.4701 - val_categorical_accuracy: 0.5595
Epoch 10/10
2348/2348 [==============================] - 8s 3ms/sample - loss: 0.0477 - categorical_accuracy: 0.9974 - val_loss: 1.5167 - val_categorical_accuracy: 0.5629
history.history.keys()
dict_keys(['loss', 'categorical_accuracy', 'val_loss', 'val_categorical_accuracy'])
过拟合展示
plt.plot(history.epoch,history.history["categorical_accuracy"],'r--',label = 'categorical_accuracy')
plt.plot(history.epoch,history.history["val_categorical_accuracy"],label = 'val_categorical_accuracy')
plt.legend()
plt.show()
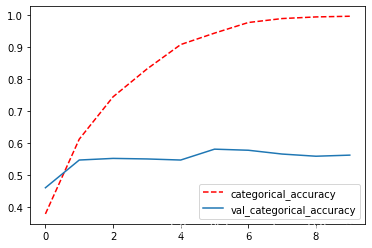
一、正则化
限制参数过多或者过大,避免模型更加复杂。
keras提供了三种正则化方法:
-
L1:绝对值权重之和
-
L2:平方权重之和
-
L1L2:两者累加之和
-
L1正则:在原来的损失函数基础上加上权重参数的绝对值,权重参数稀疏化,权重矩阵中很多值为0。可以用于特征选择,一定程度上,L1可以防止过拟合。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-37x1430S-1584352277785)(attachment:image.png)]](https://i-blog.csdnimg.cn/blog_migrate/9132ea07050dce91a4cb78a483693b41.png#pic_center)
- L2正则:在原来的损失函数基础上加上权重参数的平方和,使得最终的权重值非常小,但不会等于0。一般来说选择L2正则化,因为L1范数在取得最小值处是不可导的,这会给后续求梯度带来麻烦。L2正则化可以防止模型过拟合。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-8FvJMeGW-1584352277786)(attachment:image.png)]](https://i-blog.csdnimg.cn/blog_migrate/0933eac4e39b862e8ea7fff208590d89.png#pic_center)

以二维情况讨论,上图左边是 L2 正则化,右边是 L1 正则化。从另一个方面来看,满足正则化条件,实际上是求解蓝色区域与黄色区域的交点,即同时满足限定条件和 Ein 最小化。对于 L2 来说,限定区域是圆,这样,得到的解 w1 或 w2 为 0 的概率很小,很大概率是非零的。
对于 L1 来说,限定区域是正方形,方形与蓝色区域相交的交点是顶点的概率很大,这从视觉和常识上来看是很容易理解的。也就是说,方形的凸点会更接近 Ein 最优解对应的 wlin 位置,而凸点处必有 w1 或 w2 为 0。这样,得到的解 w1 或 w2 为零的概率就很大了。所以,L1 正则化的解具有稀疏性。
扩展到高维,同样的道理,L2 的限定区域是平滑的,与中心点等距;而 L1 的限定区域是包含凸点的,尖锐的。这些凸点更接近 Ein 的最优解位置,而在这些凸点上,很多 wj 为 0。
正则化项的参数选择
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-5ONFcJRc-1584352277787)(attachment:image.png)]
以 L2 为例,若 λ 很小,对应上文中的 C 值就很大。这时候,圆形区域很大,能够让 w 更接近 Ein 最优解的位置。若 λ 近似为 0,相当于圆形区域覆盖了最优解位置,这时候,正则化失效,容易造成过拟合。相反,若 λ 很大,对应上文中的 C 值就很小。这时候,圆形区域很小,w 离 Ein 最优解的位置较远。w 被限制在一个很小的区域内变化,w 普遍较小且接近 0,起到了正则化的效果。但是,λ 过大容易造成欠拟合。
L2正则λ选择:
发生过拟合, 参数θ一般是比较大的值, 加入惩罚项后, 只要控制λ的大小,当λ很大时,θ1到θn就会很小
- λ很小:能够让 w 更接近 C0最优解
- λ近似为 0:覆盖了最优解位置,这时候,正则化失效,容易造成过拟合。
- λ很大:w 离 C0最优解的位置较远。w 被限制在一个很小的区域内变化,w 普遍较小且接近 0,起到了正则化的效果。但是,λ 过大容易造成欠拟合。
当 λ 的值开始上升时,它减小了系数的值,从而降低了方差。直到上升到某个值之前,λ 的增大很有利,因为它只是减少方差(避免过拟合),而不会丢失数据的任何重要特性。但是在某个特定值之后,模型就会失去重要的性质,导致偏差上升产生欠拟合。因此,要仔细选择 λ 的值。
正则化添加方法:权重正则化可以应用到任意一层
全连接层
# 权重正则化,bias正则化(应用较少)
tf.keras.layers.Dense(32,
activation='relu',
kernel_regularizer=tf.keras.regularizers.l2(0.001),
bias_regularizer=tf.keras.regularizers.l2(l=0.001))
卷积层
tf.keras.layers.Conv2D(filters=32,
kernel_size=[3, 3],
activation=tf.nn.relu,
kernel_regularizer=tf.keras.regularizers.l2(l=0.001))
RNN层
tf.keras.layers.LSTM(32,
activation=tf.nn.tanh,
recurrent_regularizer=tf.keras.regularizers.l2(l=0.001),
kernel_regularizer=tf.keras.regularizers.l2(l=0.001),
bias_regularizer=tf.keras.regularizers.l2(l=0.001)
权重正则化使用经验:
正则项系数初始值应该设置为多少,好像也没有一个比较好的准则。从0开始,逐渐增大λ。在训练集上学习到参数,然后在测试集上验证误差。反复进行这个过程,直到测试集上的误差最小。一般的说,随着λ从0开始增大,测试集的误分类率应该是先减小后增大,交叉验证的目的,就是为了找到误分类率最小的那个位置。建议一开始将正则项系数λ设置为0,先确定一个比较好的learning rate。然后固定该learning rate,给λ一个值(比如1.0),然后根据validation accuracy,将λ增大或者减小10倍,增减10倍是粗调节,当你确定了λ的合适的数量级后,比如λ=0.01,再进一步地细调节,比如调节为0.02,0.03,0.009之类。
- 最常见的权重正则化是L2正则化,数值通常是0-0.1之间,如:0.1,0.001,0.0001。
- 找到最优的系数并不容易,需要尝试不同的权重系数,找到模型表现最平稳优秀的系数
- L2正则化在CNN网络中,建议系数设置小一些,如:0.0005
- 少量的权重正则对模型很重要,可以减少模型训练误差
- LSTM网络中L2权重系数通常更小,如:10^-6
网格搜索正则化超参数(伪代码):
# 待测权重正则化值
values = [1e-1, 1e-2, 1e-3, 1e-4, 1e-5, 1e-6]
all_train, all_test = list(), list()
for param in values:
...
model.add(Dense(500, input_dim=2, activation='relu', kernel_regularizer=l2(param)))
...
all_train.append(train_acc)
all_test.append(test_acc)
# 画图展示不同值得效果
pyplot.semilogx(values, all_train, label='train', marker='o')
pyplot.semilogx(values, all_test, label='test', marker='o')
举个栗子:
class re_model(tf.keras.Model):
def __init__(self):
super().__init__()
self.conv1 = tf.keras.layers.Conv2D(
filters=32, # 卷积层神经元(卷积核)数目
kernel_size=[3, 3], # 感受野大小
padding='same', # padding策略(vaild 或 same)
activation=tf.nn.relu, # 激活函数
kernel_regularizer=tf.keras.regularizers.l2(0.1),
)
self.pool1 = tf.keras.layers.MaxPool2D(pool_size=[2, 2], strides=2)
self.flatten = tf.keras.layers.Flatten()
self.dense1 = tf.keras.layers.Dense(units=128,
kernel_regularizer=tf.keras.regularizers.l2(0.1),
activation=tf.nn.relu)
self.dense2 = tf.keras.layers.Dense(units=5)
def call(self, inputs):
x = self.conv1(inputs)
x = self.pool1(x)
x = self.flatten(x)
x = self.dense1(x)
x = self.dense2(x)
output = tf.nn.softmax(x)
return output
re_model = re_model()
re_model.compile(optimizer=tf.keras.optimizers.Adam(learning_rate=0.001),
loss = tf.keras.losses.categorical_crossentropy,
metrics=[tf.keras.metrics.categorical_accuracy])
history2 = re_model.fit(x_train, y_train, batch_size=64, epochs=10, validation_split=0.2)
Train on 2348 samples, validate on 588 samples
Epoch 1/10
2348/2348 [==============================] - 10s 4ms/sample - loss: 9.7473 - categorical_accuracy: 0.2994 - val_loss: 3.4922 - val_categorical_accuracy: 0.3878
Epoch 2/10
2348/2348 [==============================] - 10s 4ms/sample - loss: 2.4671 - categorical_accuracy: 0.4629 - val_loss: 1.9573 - val_categorical_accuracy: 0.4728
Epoch 3/10
2348/2348 [==============================] - 9s 4ms/sample - loss: 1.8752 - categorical_accuracy: 0.4651 - val_loss: 1.8812 - val_categorical_accuracy: 0.4371
Epoch 4/10
2348/2348 [==============================] - 9s 4ms/sample - loss: 1.7870 - categorical_accuracy: 0.4872 - val_loss: 1.8487 - val_categorical_accuracy: 0.4133
Epoch 5/10
2348/2348 [==============================] - 9s 4ms/sample - loss: 1.7803 - categorical_accuracy: 0.4710 - val_loss: 1.7839 - val_categorical_accuracy: 0.4779
Epoch 6/10
2348/2348 [==============================] - 9s 4ms/sample - loss: 1.7384 - categorical_accuracy: 0.4698 - val_loss: 1.7689 - val_categorical_accuracy: 0.4694
Epoch 7/10
2348/2348 [==============================] - 9s 4ms/sample - loss: 1.7257 - categorical_accuracy: 0.4983 - val_loss: 1.8818 - val_categorical_accuracy: 0.4354
Epoch 8/10
2348/2348 [==============================] - 10s 4ms/sample - loss: 1.6976 - categorical_accuracy: 0.4936 - val_loss: 1.7046 - val_categorical_accuracy: 0.4252
Epoch 9/10
2348/2348 [==============================] - 9s 4ms/sample - loss: 1.6480 - categorical_accuracy: 0.5064 - val_loss: 1.6559 - val_categorical_accuracy: 0.5068
Epoch 10/10
2348/2348 [==============================] - 9s 4ms/sample - loss: 1.6152 - categorical_accuracy: 0.4979 - val_loss: 1.6551 - val_categorical_accuracy: 0.5000
import matplotlib.pyplot as plt
plt.plot(history2.epoch,history2.history["categorical_accuracy"],'r--',label = 'categorical_accuracy')
plt.plot(history2.epoch,history2.history["val_categorical_accuracy"],label = 'val_categorical_accuracy')
plt.legend()
plt.show()
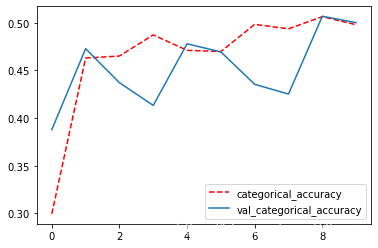
二、dropout
tf.keras.layers.Dropout§
- p:神经元不起作用的比例,p是概率值,在0-1之间,一般设置在0.2-0.5
Dropout在正向传播过程中会随机以一定概率将部分节点的值置零,这样能减轻过拟合的情况。记住分类层不能加dropout!
需要注意的是,训练时候dropout起作用,测试时候不起作用,因此两者dropout运行机制不一样。如果使用fit方法训练,模型会自动判断为训练模式,dropout起作用,如果是测试和预测,模型会自当判断为测试模式,dropout不起作用。如果是自定义循环训练模型,需要改变dropout中的traing来控制训练或者测试。同样BN层也分训练和测试,两者道理相同。
class dropout_model(tf.keras.Model):
def __init__(self):
super().__init__()
self.conv1 = tf.keras.layers.Conv2D(
filters=32, # 卷积层神经元(卷积核)数目
kernel_size=[3, 3], # 感受野大小
padding='same', # padding策略(vaild 或 same)
activation=tf.nn.relu # 激活函数
)
self.pool1 = tf.keras.layers.MaxPool2D(pool_size=[2, 2], strides=2)
self.flatten = tf.keras.layers.Flatten()
self.drop1 = tf.keras.layers.Dropout(0.5)
self.dense1 = tf.keras.layers.Dense(units=128, activation=tf.nn.relu)
self.drop2 = tf.keras.layers.Dropout(0.5)
self.dense2 = tf.keras.layers.Dense(units=5)
def call(self, inputs):
x = self.conv1(inputs)
x = self.pool1(x)
x = self.flatten(x)
x = self.drop1(x)
x = self.dense1(x)
x = self.drop2(x)
x = self.dense2(x)
output = tf.nn.softmax(x)
return output
dropout_model = dropout_model()
dropout_model.compile(optimizer=tf.keras.optimizers.Adam(learning_rate=0.001),
loss = tf.keras.losses.categorical_crossentropy,
metrics=[tf.keras.metrics.categorical_accuracy])
history3 = dropout_model.fit(x_train, y_train, batch_size=64, epochs=10, validation_split=0.2)
Train on 2348 samples, validate on 588 samples
Epoch 1/10
2348/2348 [==============================] - 9s 4ms/sample - loss: 1.9331 - categorical_accuracy: 0.3011 - val_loss: 1.4651 - val_categorical_accuracy: 0.4133
Epoch 2/10
2348/2348 [==============================] - 9s 4ms/sample - loss: 1.4558 - categorical_accuracy: 0.3629 - val_loss: 1.3962 - val_categorical_accuracy: 0.4065
Epoch 3/10
2348/2348 [==============================] - 9s 4ms/sample - loss: 1.4057 - categorical_accuracy: 0.3910 - val_loss: 1.2633 - val_categorical_accuracy: 0.4507
Epoch 4/10
2348/2348 [==============================] - 9s 4ms/sample - loss: 1.2685 - categorical_accuracy: 0.4570 - val_loss: 1.1876 - val_categorical_accuracy: 0.5272
Epoch 5/10
2348/2348 [==============================] - 9s 4ms/sample - loss: 1.1849 - categorical_accuracy: 0.4949 - val_loss: 1.1502 - val_categorical_accuracy: 0.5136
Epoch 6/10
2348/2348 [==============================] - 9s 4ms/sample - loss: 1.0587 - categorical_accuracy: 0.5711 - val_loss: 1.1047 - val_categorical_accuracy: 0.5714
Epoch 7/10
2348/2348 [==============================] - 9s 4ms/sample - loss: 0.9577 - categorical_accuracy: 0.6188 - val_loss: 1.0937 - val_categorical_accuracy: 0.5782
Epoch 8/10
2348/2348 [==============================] - 9s 4ms/sample - loss: 0.8702 - categorical_accuracy: 0.6606 - val_loss: 1.0931 - val_categorical_accuracy: 0.5629
Epoch 9/10
2348/2348 [==============================] - 9s 4ms/sample - loss: 0.7901 - categorical_accuracy: 0.6899 - val_loss: 1.0723 - val_categorical_accuracy: 0.5867
Epoch 10/10
2348/2348 [==============================] - 9s 4ms/sample - loss: 0.7036 - categorical_accuracy: 0.7330 - val_loss: 1.0653 - val_categorical_accuracy: 0.6003
plt.plot(history3.epoch,history3.history["categorical_accuracy"],'r--',label = 'categorical_accuracy')
plt.plot(history3.epoch,history3.history["val_categorical_accuracy"],label = 'val_categorical_accuracy')
plt.legend()
plt.show()
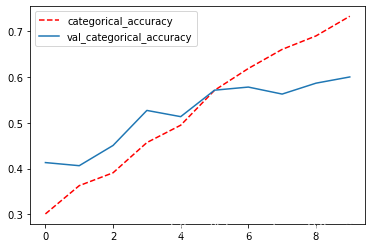
三、正则化+dropout
class re_dropout_model(tf.keras.Model):
def __init__(self):
super().__init__()
self.conv1 = tf.keras.layers.Conv2D(
filters=32, # 卷积层神经元(卷积核)数目
kernel_size=[3, 3], # 感受野大小
padding='same', # padding策略(vaild 或 same)
activation=tf.nn.relu, # 激活函数
kernel_regularizer=tf.keras.regularizers.l2(0.001)
)
self.pool1 = tf.keras.layers.MaxPool2D(pool_size=[2, 2], strides=2)
self.flatten = tf.keras.layers.Flatten()
self.drop1 = tf.keras.layers.Dropout(0.5)
self.dense1 = tf.keras.layers.Dense(units=128,
activation=tf.nn.relu,
kernel_regularizer=tf.keras.regularizers.l2(0.001))
self.drop2 = tf.keras.layers.Dropout(0.5)
self.dense2 = tf.keras.layers.Dense(units=5)
def call(self, inputs):
x = self.conv1(inputs)
x = self.pool1(x)
x = self.flatten(x)
x = self.drop1(x)
x = self.dense1(x)
x = self.drop2(x)
x = self.dense2(x)
output = tf.nn.softmax(x)
return output
re_dropout_model = re_dropout_model()
re_dropout_model.compile(optimizer=tf.keras.optimizers.Adam(learning_rate=0.001),
loss = tf.keras.losses.categorical_crossentropy,
metrics=[tf.keras.metrics.categorical_accuracy])
tf.keras.backend.set_learning_phase(1)
history4 = re_dropout_model.fit(x_train, y_train, batch_size=64, epochs=10, validation_split=0.2)
Train on 2348 samples, validate on 588 samples
Epoch 1/10
2348/2348 [==============================] - 10s 4ms/sample - loss: 3.1728 - categorical_accuracy: 0.2521 - val_loss: 1.7598 - val_categorical_accuracy: 0.3112
Epoch 2/10
2348/2348 [==============================] - 9s 4ms/sample - loss: 1.7319 - categorical_accuracy: 0.2819 - val_loss: 1.6261 - val_categorical_accuracy: 0.3707
Epoch 3/10
2348/2348 [==============================] - 10s 4ms/sample - loss: 1.6177 - categorical_accuracy: 0.3369 - val_loss: 1.5679 - val_categorical_accuracy: 0.3503
Epoch 4/10
2348/2348 [==============================] - 10s 4ms/sample - loss: 1.5333 - categorical_accuracy: 0.3722 - val_loss: 1.4599 - val_categorical_accuracy: 0.3503
Epoch 5/10
2348/2348 [==============================] - 10s 4ms/sample - loss: 1.5109 - categorical_accuracy: 0.3684 - val_loss: 1.4812 - val_categorical_accuracy: 0.4541
Epoch 6/10
2348/2348 [==============================] - 9s 4ms/sample - loss: 1.4721 - categorical_accuracy: 0.4012 - val_loss: 1.4110 - val_categorical_accuracy: 0.4609
Epoch 7/10
2348/2348 [==============================] - 10s 4ms/sample - loss: 1.4221 - categorical_accuracy: 0.4327 - val_loss: 1.3502 - val_categorical_accuracy: 0.5000
Epoch 8/10
2348/2348 [==============================] - 10s 4ms/sample - loss: 1.3830 - categorical_accuracy: 0.4387 - val_loss: 1.3300 - val_categorical_accuracy: 0.5391
Epoch 9/10
2348/2348 [==============================] - 10s 4ms/sample - loss: 1.3579 - categorical_accuracy: 0.4612 - val_loss: 1.3290 - val_categorical_accuracy: 0.5051
Epoch 10/10
2348/2348 [==============================] - 10s 4ms/sample - loss: 1.3190 - categorical_accuracy: 0.4966 - val_loss: 1.3299 - val_categorical_accuracy: 0.4847
plt.plot(history4.epoch,history4.history["categorical_accuracy"],'r--',label = 'categorical_accuracy')
plt.plot(history4.epoch,history4.history["val_categorical_accuracy"],label = 'val_categorical_accuracy')
plt.legend()
plt.show()
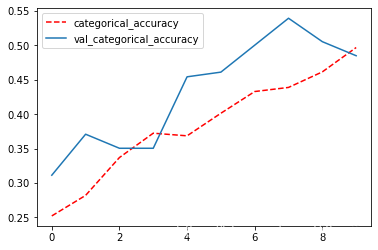
四、EarlyStopping
使用Keras中回调(Callbacks)函数:
- tf.keras.callbacks.EarlyStopping:当验证集上的性能不再提高时,终止训练。
EarlyStopping
一般是在model.fit函数中调用callbacks,fit函数中有一个参数为callbacks。
参数:
- monitor:要监测的数量。
- min_delta:小于该值的会被当成模型没有进步。
- patience:没有进步的训练轮数,在这之后训练就会被停止。
- verbose:0,1详细信息模式。
- mode:{“auto”, “min”, “max”}其中之一。在min模式中,当监测的数量停止减少时,训练将停止;在max模式下,当监测的数量停止增加时,它将停止;在auto模式下,从监测数量的名称自动推断方向。
- baseline:受监测的数量的基线值。如果模型没有显示基线的改善,训练将停止。
- restore_best_weights:是否从具有监测数量的最佳值的时期恢复模型权重。如果为False,则使用在训练的最后一步获得的模型权重。
使用技巧
monitor: 监控的数据接口,有"loss",“accuracy”,“val_loss”,"val_accuracy"等等。正常情况下如果有验证集,就用’val_acc’或者’val_loss’。
# 连续3个epoch 验证集accuracy没有提高将停止训练
callback = tf.keras.callbacks.EarlyStopping(monitor='val_accuracy', patience=3)
model.fit(train_x, train_y, epochs=100, callbacks=[callback],validation_data=(val_data, val_labels))
class earlyStopp_model(tf.keras.Model):
def __init__(self):
super().__init__()
self.conv1 = tf.keras.layers.Conv2D(
filters=32, # 卷积层神经元(卷积核)数目
kernel_size=[3, 3], # 感受野大小
padding='same', # padding策略(vaild 或 same)
activation=tf.nn.relu, # 激活函数
kernel_regularizer=tf.keras.regularizers.l2(0.001)
)
self.pool1 = tf.keras.layers.MaxPool2D(pool_size=[2, 2], strides=2)
self.flatten = tf.keras.layers.Flatten()
self.drop1 = tf.keras.layers.Dropout(0.4)
self.dense1 = tf.keras.layers.Dense(units=128,
activation=tf.nn.relu,
kernel_regularizer=tf.keras.regularizers.l2(0.001))
self.drop2 = tf.keras.layers.Dropout(0.4)
self.dense2 = tf.keras.layers.Dense(units=5)
def call(self, inputs):
x = self.conv1(inputs)
x = self.pool1(x)
x = self.flatten(x)
x = self.drop1(x)
x = self.dense1(x)
x = self.drop2(x)
x = self.dense2(x)
output = tf.nn.softmax(x)
return output
earlyStopp_model = earlyStopp_model()
early_stopping = tf.keras.callbacks.EarlyStopping(monitor='val_accuracy', patience=3,mode="max" )
earlyStopp_model.compile(optimizer=tf.keras.optimizers.Adam(learning_rate=0.001),
loss = tf.keras.losses.categorical_crossentropy,
metrics=["accuracy"])
history5 = earlyStopp_model.fit(x_train, y_train, batch_size=64, epochs=20, callbacks=[early_stopping],validation_split=0.2)
Train on 2348 samples, validate on 588 samples
Epoch 1/20
2348/2348 [==============================] - 10s 4ms/sample - loss: 2.7485 - accuracy: 0.2325 - val_loss: 1.8105 - val_accuracy: 0.2857
Epoch 2/20
2348/2348 [==============================] - 10s 4ms/sample - loss: 1.7322 - accuracy: 0.2866 - val_loss: 1.6145 - val_accuracy: 0.4184
Epoch 3/20
2348/2348 [==============================] - 10s 4ms/sample - loss: 1.5677 - accuracy: 0.3573 - val_loss: 1.4629 - val_accuracy: 0.4456
Epoch 4/20
2348/2348 [==============================] - 11s 5ms/sample - loss: 1.4626 - accuracy: 0.4008 - val_loss: 1.3661 - val_accuracy: 0.4949
Epoch 5/20
2348/2348 [==============================] - 13s 5ms/sample - loss: 1.4198 - accuracy: 0.3986 - val_loss: 1.3441 - val_accuracy: 0.4983
Epoch 6/20
2348/2348 [==============================] - 12s 5ms/sample - loss: 1.3611 - accuracy: 0.4323 - val_loss: 1.3552 - val_accuracy: 0.5034
Epoch 7/20
2348/2348 [==============================] - 11s 5ms/sample - loss: 1.3293 - accuracy: 0.4506 - val_loss: 1.3023 - val_accuracy: 0.4762
Epoch 8/20
2348/2348 [==============================] - 11s 5ms/sample - loss: 1.2989 - accuracy: 0.4672 - val_loss: 1.3255 - val_accuracy: 0.4745
Epoch 9/20
2348/2348 [==============================] - 10s 4ms/sample - loss: 1.2873 - accuracy: 0.4689 - val_loss: 1.2745 - val_accuracy: 0.5561
Epoch 10/20
2348/2348 [==============================] - 11s 5ms/sample - loss: 1.2429 - accuracy: 0.5068 - val_loss: 1.2547 - val_accuracy: 0.5510
Epoch 11/20
2348/2348 [==============================] - 10s 4ms/sample - loss: 1.2194 - accuracy: 0.5196 - val_loss: 1.2498 - val_accuracy: 0.5612
Epoch 12/20
2348/2348 [==============================] - 10s 4ms/sample - loss: 1.2188 - accuracy: 0.5166 - val_loss: 1.3002 - val_accuracy: 0.5663
Epoch 13/20
2348/2348 [==============================] - 10s 4ms/sample - loss: 1.1817 - accuracy: 0.5464 - val_loss: 1.2972 - val_accuracy: 0.5595
Epoch 14/20
2348/2348 [==============================] - 10s 4ms/sample - loss: 1.1604 - accuracy: 0.5439 - val_loss: 1.2852 - val_accuracy: 0.5510
Epoch 15/20
2348/2348 [==============================] - 10s 4ms/sample - loss: 1.1509 - accuracy: 0.5562 - val_loss: 1.3178 - val_accuracy: 0.5459

















 1604
1604

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









