







第九章 过拟合
一切都应该尽可能地简单,但不能过于简单。 —艾伯特·爱因斯坦
机器学习的主要目的是从训练集上学习到数据的真实模型,从而能够在未见过的测试集上也能够表现良好,我们把这种能力叫做泛化能力。通常来说,训练集和测试集都采样自某个相同的数据分布𝑝(𝑥)。采样到的样本是相互独立的,但是又来自于相同的分布,我们把这种假设叫做独立同分布假设(Independent Identical Distribution assumption,简称i.i.d.)。
前面已经提到了模型的表达能力,也称之为模型的容量(Capacity)。当模型的表达能力偏弱时,比如单一线性层,它只能学习到线性模型,无法良好地逼近非线性模型;但模型的表达能力过强时,它就有可能把训练集的噪声模态也学到,导致在测试集上面表现不佳的现象(泛化能力偏弱)。因此针对不同的任务,设计合适容量的模型算法才能取得较好的泛化性能。
9.1 模型的容量
通俗地讲,模型的容量或表达能力,是指模型拟合复杂函数的能力。一种体现模型容量的指标为模型的假设空间(Hypothesis Space)大小,即模型可以表示的函数集的大小。假设空间越大越完备,从假设空间中搜索出逼近真实模型的函数也就越有可能;反之,如果假设空间非常受限,就很难从中找到逼近真实模型的函数。
考虑采样自真实分布
p
data
=
{
(
x
,
y
)
∣
y
=
sin
(
x
)
,
x
∈
[
−
5
,
5
]
}
p_{\text {data }}=\{(x, y) | y=\sin (x), x \in[-5,5]\}
pdata ={(x,y)∣y=sin(x),x∈[−5,5]}
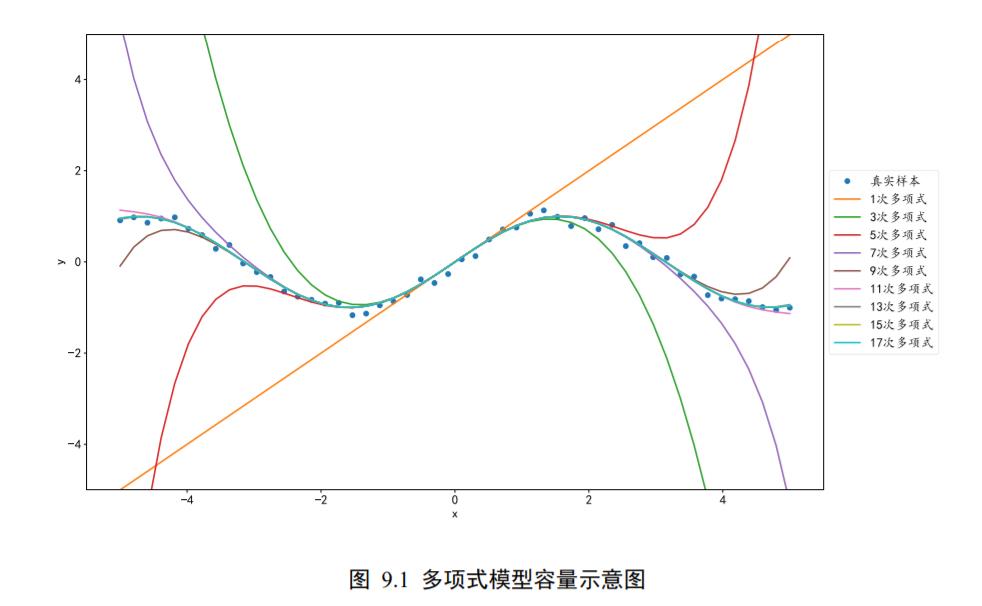
的数据集,从真实分布中采样少量样本点构成训练集,其中包含了观测误差ϵ,如图 9.1 中的小圆点。
如果只搜索所有 1 次多项式的模型空间,令偏置为 0,即𝑦 = 𝑎𝑥,如图 9.1 中 1次多项式的直线所示,则很难找到一条直线较好地逼近真实数据的分布。
稍微增大假设空间,令假设空间为所有的 3 次多项式函数,即 y = a x 3 + b x 2 + c x y=a x^{3}+b x^{2}+c x y=ax3+bx2+cx,很明显此假设空间明显大于 1 次多项式的假设空间,我们可以找到一条曲线,如图 9.1 3 次多项式曲线所示,它比 1 次多项式模型更好地反映了数据的关系,但是仍然不够好。
再次增大假设空间,使得可以搜索的函数为 5 次多项式,即 y = a x 5 + b x 4 + c x 3 + d x 2 + e x y=a x^{5}+b x^{4}+c x^{3}+d x^{2}+e x y=ax5+bx4+cx3+dx2+ex,在此假设空间中,可以搜索到一个较好的函数,如图 9.1 中 5 次多项式所示。
再次增加假设空间后,如图 9.1中 7、9、11、13、15、17 次多项式曲线所示,函数的假设空间越大,就越有可能找到一个函数更好地逼近真实分布的函数模型。
但是过大的假设空间无疑会增加搜索难度和计算代价。实际上,在有限的计算资源的约束下,较大的假设空间并不一定能搜索出更好的函数模型。同时由于观测误差的存在,较大的假设空间中可能包含了大量表达能力过强的函数,能够将训练样本的观测误差也学习进来,从而伤害了模型的泛化能力。挑选合适容量的学习模型是一个很大的难题.
9.2 过拟合与欠拟合
由于真实数据的分布往往是未知而且复杂的,无法推断出其分布函数的类型和相关参数,因此人们在选择学习模型的容量时,往往会根据经验值选择稍大的模型容量。但模型的容量过大时,有可能出现在训练集上表现较好,但是测试集上表现较差的现象,如图9.2 中红色竖线右边区域所示;当模型的容量过小时,有可能出现在训练集和测试集表现皆不佳的现象,如图 9.2 中红色竖线左边区域所示。

当模型的容量过大时,网络模型除了学习到训练集数据的模态之外,还把额外的观测误差也学习进来,导致学习的模型在训练集上面表现较好,但是在未见的样本上表现不佳,也就是模型泛化能力偏弱,我们把这种现象叫作过拟合(Overfitting)。
当模型的容量过小时,模型不能够很好地学习到训练集数据的模态,导致训练集上表现不佳,同时在未见的样本上表现也不佳,我们把这种现象叫作欠拟合(Underfitting)。
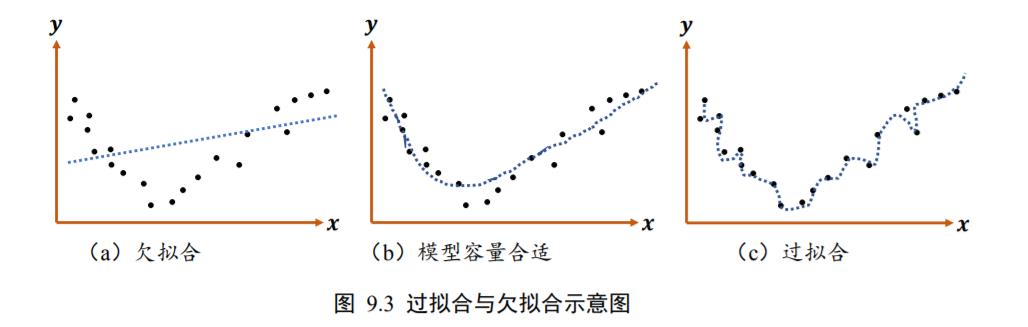
这里用一个简单的例子来解释模型的容量与数据的分布之间的关系。图 9.3 绘制了某种数据的分布图,可以大致推测数据可能属于某 2 次多项式分布。
如果我们用简单的线性函数去学习时,会发现很难学习到一个较好的函数,从而出现训练集和测试集表现都不理想的现象,如图 9.3(a)所示,这种现象叫做欠拟合。
但如果用较复杂的函数模型去学习时,有可能学习到的函数会过度地“拟合”训练集样本,从而导致在测试集上表现不佳,如图 9.3©所示,这种现象叫做过拟合。
只有学习的模型和真实模型容量大致匹配时,模型才能具有较好地泛化能力,如图 9.3(b)所示。
考虑数据点(𝑥, 𝑦)的分布
p
d
a
t
a
p_{data}
pdata,其中
y
=
sin
(
1.2
⋅
π
⋅
x
)
y=\sin (1.2 \cdot \pi \cdot x)
y=sin(1.2⋅π⋅x)
在采样时,添加随机高斯噪声𝒩(0,1),共获得 120 个点的数据集,如图 9.4 所示,图中曲线为真实模型函数的曲线,黑色圆形点为训练样本,绿色矩阵点为测试样本。

在已知真实模型的情况下,自然可以设计容量合适的函数假设空间,从而获得不错的学习模型,如图 9.5 所示,我们将模型假设为 2 次多项式模型,学习得到的函数曲线较好地逼近真实模型的函数曲线。但是在实际场景中,真实模型往往是无法得知的,因此设计的假设空间如果过小,导致无法搜索到合适的学习模型;设计的假设空间过大,导致模型泛化能力过差。

那么如何去选择模型的容量?统计学习理论给我们提供了一些思路,其中 VC 维度(Vapnik-Chervonenkis 维度)是一个应用比较广泛的度量函数容量的方法。尽管这些方法给机器学习提供了一定程度的理论保证,但是这些方法却很少应用到深度学习中去,一部分原因是神经网络过于复杂,很难去确定网络结构背后的数学模型的 VC 维度。
尽管统计学习理论很难给出神经网络所需要的最小容量,但是却可以根据奥卡姆剃刀原理(Occam’s razor)来指导神经网络的设计和训练。奥卡姆剃刀原理是由 14 世纪逻辑学家、圣方济各会修士奥卡姆的威廉(William of Occam)提出的一个解决问题的法则,他在《箴言书注》2 卷 15 题说:切勿浪费较多东西,去做用较少的东西,同样可以做好的事情。也就是说,如果两层的神经网络结构能够很好的表达真实模型,那么三层的神经网络也能够很好的表达,但是我们应该优先选择使用更简单的两层神经网络,因为它的参数量更少,更容易训练,也更容易通过较少的训练样本获得不错的泛化误差。
9.2.1 欠拟合
我们来考虑欠拟合的现象。如图 9.6 中所示,黑色圆点和绿色矩形点均独立采样自某抛物线函数的分布,在已知数据的真实模型的条件下,如果用模型容量小于真实模型的线性函数去回归这些数据,会发现很难找到一条线性函数较好地逼近训练集数据的模态,具体表现为学习到的线性模型在训练集上的误差(如均方误差)较大,同时在测试集上面的误差也较大。

当我们发现当前的模型在训练集上误差一直维持较高的状态,很难优化减少,同时在测试集上也表现不佳时,我们可以考虑是否出现了欠拟合的现象。这个时候可以通过增加神经网络的层数、增大中间维度的大小等手段,比较好的解决欠拟合的问题。但是由于现代深度神经网络模型可以很轻易达到较深的层数,用来学习的模型的容量一般来说是足够的,在实际使用过程中,更多的是出现过拟合现象。
9.2.2 过拟合
继续来考虑同样的问题,训练集黑色圆点和测试机绿色矩形点均独立采样自同分布的某抛物线模型,当我们设置模型的假设空间为 25 次多项式时,它远大于真实模型的函数容量,这时发现学到的模型很有可能过分去拟合训练样本,导致学习模型在训练样本上的误差非常小,甚至比真实模型在训练集上的误差还要小。但是对于测试样本,模型性能急剧下降,泛化能力非常差,如图 9.7 所示。

现代深度神经网络中过拟合现象非常容易出现,主要是因为神经网络的表达能力非常强,训练集样本数不够,很容易就出现了神经网络的容量偏大的现象。那么如何有效检测并减少过拟合现象呢?接下来我们将介绍一系列的方法,来帮助检测并抑制过拟合现象。
9.3 数据集划分
前面我们介绍了数据集需要划分为训练集(Train set)和测试集(Test set),但是为了挑选模型超参数和检测过拟合现象,一般需要将原来的训练集再次切分为新的训练集和验证集(Validation set),即数据集需要切分为训练集、验证集和测试集 3 个子集。
9.3.1 验证集与超参数
前面已经介绍了训练集和测试集的区别,训练集 D t r a i n D^{train} Dtrain用于训练模型参数,测试集 D t e s t D^{test} Dtest用于测试模型的泛化能力,测试集中的样本不能参与模型的训练,防止模型“记忆”住数据的特征,损害模型的泛化能力。
训练集和测试集都是采样自相同的数据分布,比如MNIST 手写数字图片集共有 7 万张样本图片,其中 6 万张图片用做训练集,余下的 1 万张图片用于测试集。训练集与测试集的分配比例可以由用户自行定义,比如 80%的数据用于训练,剩下的 20%用于测试。
当数据集规模偏小时,为了测试集能够比较准确地测试出模型的泛化能力,可以适当增加测试集的比例。下图 9.8 演示了 MNIST 手写数字图片集的划分:80%用于训练,剩下的 20%用于测试。

但是将数据集仅划分为训练集与测试集是不够的,由于测试集的性能不能作为模型训练的反馈,而我们需要在模型训练时能够挑选出较合适的模型超参数,判断模型是否过拟合等,因此需要将训练集再次切分为训练集
D
t
r
a
i
n
D^{train}
Dtrain和验证集
D
v
a
l
D^{val}
Dval,如图 9.9 所示。划分过的训练集与原来的训练集的功能一致,用于训练模型的参数,而验证集则用于选择模型的超参数(模型选择,Model selection),它的功能包括:
❑ 根据验证集的性能表现来调整学习率、权值衰减系数、训练次数等。
❑ 根据验证集的性能表现来重新调整网络拓扑结构。
❑ 根据验证集的性能表现判断是否过拟合和欠拟合。
和训练集-测试集的划分类似,训练集、验证集和测试集可以按着自定义的比例来划分,比如常见的 60%-20%-20%的划分,图 9.9 演示了 MNIST 手写数据集的划分示意图。

验证集与测试集的区别在于,算法设计人员可以根据验证集的表现来调整模型的各种超参数的设置,提升模型的泛化能力,但是测试集的表现却不能用来反馈模型的调整,否则测试集将和验证集的功能重合,因此在测试集上的性能表现将无法代表模型的泛化能力。
实际上,部分开发人员会错误地使用测试集来挑选最好的模型,然后将其作为模型泛化性能汇报(甚至部分论文也会出现这种做法),此时的测试集其实是验证集的功能,因此汇报的“泛化性能”本质上是验证集上的性能,而不是真正的泛化性能。为了防止出现这种作弊行为,可以选择生成多个测试集,这样即使开发人员使用了其中一个测试集来挑选模型,我们还可以使用其它测试集来评价模型,这也是 Kaggle 竞赛常用的做法。
9.3.2 提前停止
一般把对训练集中的一个 Batch 运算更新一次叫做一个 Step,对训练集的所有样本循环迭代一次叫做一个 Epoch。验证集可以在数次 Step 或数次 Epoch 后使用,计算模型的验证性能。验证的步骤过于频繁,能够精准地观测模型的训练状况,但是也会引入额外的计算代价,一般建议几个 Epoch 后进行一次验证运算。
以分类任务为例,在训练时,一般关注的指标有训练误差、训练准确率等,相应地,验证时也有验证误差和验证准确率等,测试时也有测试误差和测试准确率等。
通过观测训练准确率和验证准确率可以大致推断模型是否出现过拟合和欠拟合。如果模型的训练误差较低,训练准确率较高,但是验证误差较高,验证准确率较低,那么可能出现了过拟合现象。如果训练集和验证集上面的误差都较高,准确率较低,那么可能出现了欠拟合现象。
当观测到过拟合现象时,可以从新设计网络模型的容量,如降低网络的层数、降低网络的参数量、添加正则化手段、添加假设空间的约束等,使得模型的实际容量降低,从而减轻或解决过拟合现象;当观测到欠拟合现象时,可以尝试增大网络的容量,如加深网络的层数、增加网络的参数量,尝试更复杂的网络结构。
实际上,由于网络的实际容量可以随着训练的进行发生改变,因此在相同的网络设定下,随着训练的进行,可能观测到不同的过拟合、欠拟合状况。如图 9.10 所示为分类问题的典型训练曲线,红色曲线为训练准确率,蓝色曲线为测试准确率。从图中可以看到,在训练的前期,随着训练的进行,模型的训练准确率和测试准确率都呈现增大的趋势,此时并没有出现过拟合现象;在训练后期,即使是相同网络结构下,由于模型的实际容量发生改变,我们观察到了过拟合的现象,具体表现为训练准确度继续改善,但是泛化能力变弱(测试准确率减低)。

这意味着,对于神经网络,即使网络结构超参数保持不变(即网络最大容量固定),模型依然可能会出现过拟合的现象,这是因为神经网络的有效容量和网络参数的状态息息相关,神经网络的有效容量可以很大,也可以通过稀疏化参数、添加正则化等手段降低有效容量。
在训练的前中期,神经网络的过拟合现象没有出现,当随着训练 Epoch 数的增加,过拟合程度越来越严重。图 9.10 中竖直虚线所处的网络状态最佳,没有出现明显的过拟合现象,网络的泛化能力最佳。

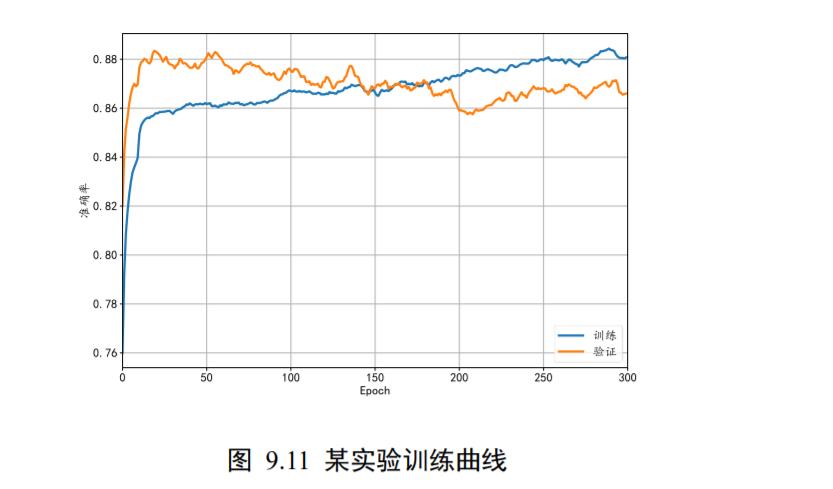
那么如何选择合适的 Epoch 就提前停止训练(Early Stopping),避免出现过拟合现象呢?我们可以通过观察验证指标的变化,来预测最适合的 Epoch 可能的位置。具体地,对于分类问题,我们可以记录模型的验证准确率,并监控验证准确率的变化,当发现验证准确率连续𝑛个 Epoch 没有下降时,可以预测可能已经达到了最适合的 Epoch 附近,从而提前终止训练。图 9.11 中绘制了某次具体的训练过程中,训练和验证准确率随训练 Epoch 的变化曲线,可以观察到,在 Epoch 为 30 左右时,模型达到最佳状态,提前终止训练。
算法 1 是采用提前停止的模型训练算法伪代码。

9.4 模型设计
通过验证集可以判断网络模型是否过拟合或者欠拟合,从而为调整网络模型的容量提供判断依据。对于神经网络来说,网络的层数和参数量是网络容量很重要的参考指标,通过减少网络的层数,并减少每层中网络参数量的规模,可以有效降低网络的容量。反之,如果发现模型欠拟合,需要增大网络的容量,可以通过增加层数,增大每层的参数量等方式实现。
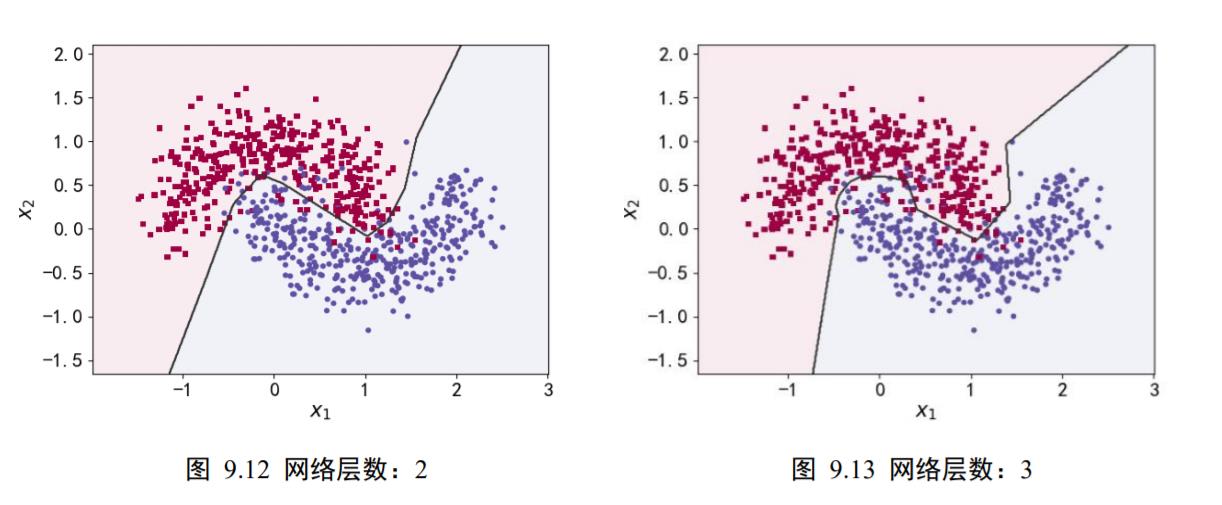
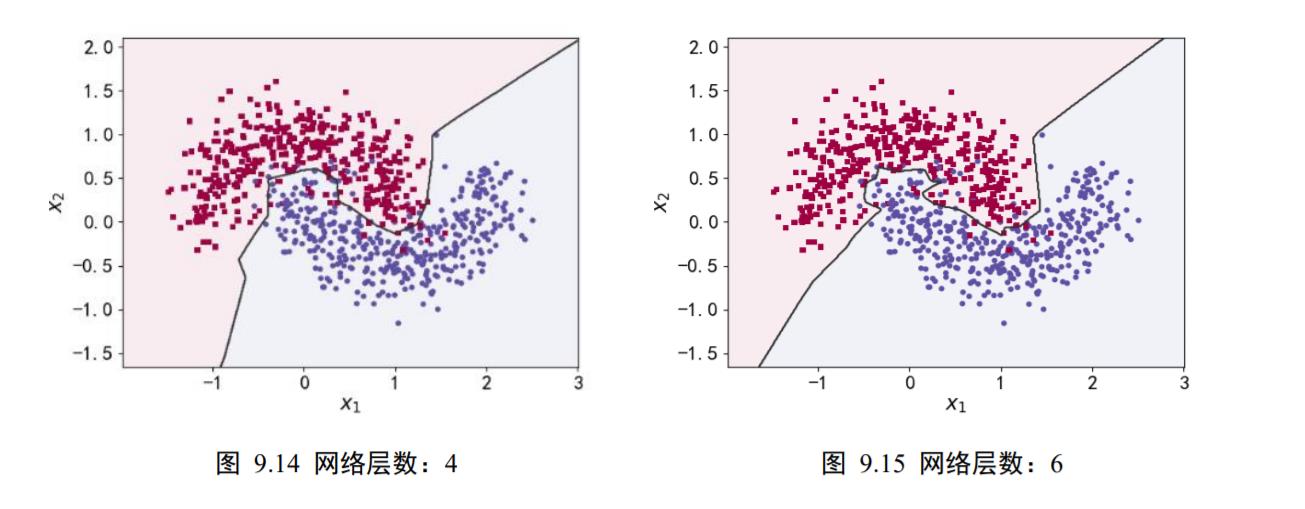
为了演示网络层数对网络容量的影响,我们可视化了一个分类任务的决策边界(Decision boundary)。图 9.12、图 9.13、图 9.14、图 9.15 分别演示在不同的网络层数下训练 2 分类任务的决策边界图,其中红色矩形块和蓝色圆形块分别代表了训练集上的 2 类样本,保持其它超参数一致,仅调整网络的层数,训练获得样本上的分类效果,如图中所示,可以看到,随着网络层数的加深,学习到的模型决策边界越来越逼近训练样本,出现了过拟合现象。对于此任务,2 层的神经网络即可获得不错的泛化能力,更深层数的网络并没有提升性能,反而出现过拟合现象,泛化能力变差,同时计算代价也更高。
9.5 正则化
通过设计不同层数、大小的网络模型可以为优化算法提供初始的函数假设空间,但是模型的实际容量可以随着网络参数的优化更新而产生变化。以多项式函数模型为例:
y
=
β
0
+
β
1
x
+
β
2
x
2
+
β
3
x
3
+
⋯
+
β
n
x
n
+
ε
y=\beta_{0}+\beta_{1} x+\beta_{2} x^{2}+\beta_{3} x^{3}+\cdots+\beta_{n} x^{n}+\varepsilon
y=β0+β1x+β2x2+β3x3+⋯+βnxn+ε
上述模型的容量可以通过𝑛简单衡量。在训练的过程中,如果网络参数
β
k
+
1
\beta_{k+1}
βk+1, ⋯ ,
β
n
\beta_{n}
βn均为 0,那么网络的实际容量退化到𝑘次多项式的函数容量。因此,通过限制网络参数的稀疏性,可以来约束网络的实际容量。
这种约束一般通过在损失函数上添加额外的参数稀疏性惩罚项实现,在未加约束之前的优化目标是
min
L
(
f
θ
(
x
)
,
y
)
,
(
x
,
y
)
∈
D
train
\min \mathcal{L}\left(f_{\theta}(\boldsymbol{x}), y\right),(\boldsymbol{x}, y) \in \mathbb{D}^{\text {train }}
minL(fθ(x),y),(x,y)∈Dtrain
对模型的参数添加额外的约束后,优化的目标变为
min
L
(
f
θ
(
x
)
,
y
)
+
λ
⋅
Ω
(
θ
)
,
(
x
,
y
)
∈
D
train
\min \mathcal{L}\left(f_{\theta}(\boldsymbol{x}), y\right)+\lambda \cdot \Omega(\theta),(\boldsymbol{x}, y) \in \mathbb{D}^{\text {train }}
minL(fθ(x),y)+λ⋅Ω(θ),(x,y)∈Dtrain
其中𝛺(𝜃)表示对网络参数𝜃的稀疏性约束函数。一般地,参数𝜃的稀疏性约束通过约束参数
𝜃的𝐿范数实现,即
Ω
(
θ
)
=
∑
θ
i
∥
θ
i
∥
l
\Omega(\theta)=\sum_{\theta_{i}}\left\|\theta_{i}\right\|_{l}
Ω(θ)=θi∑∥θi∥l
其中
∥
θ
i
∥
l
\left\|\theta_{i}\right\|_{l}
∥θi∥l表示参数
θ
i
\theta_{i}
θi的𝑙范数。
新的优化目标除了要最小化原来的损失函数 L ( x , y ) \mathcal{L}(x, y) L(x,y)之外,还需要约束网络参数的稀疏性𝛺(𝜃),优化算法会在降低 L ( x , y ) \mathcal{L}(x, y) L(x,y)的同时,尽可能地迫使网络参数𝜃𝑖变得稀疏,它们之间的权重关系通过超参数𝜆来平衡。较大的𝜆意味着网络的稀疏性更重要;较小的𝜆则意味着网络的训练误差更重要。通过选择合适的𝜆超参数,可以获得较好的训练性能,同时保证网络的稀疏性,从而获得不错的泛化能力。
常用的正则化方式有 L0、L1、L2 正则化.
9.5.1 L0 正则化
L0 正则化是指采用 L0 范数作为稀疏性惩罚项𝛺(𝜃)的正则化计算方式,即
Ω
(
θ
)
=
∑
θ
i
∥
θ
i
∥
0
\Omega(\theta)=\sum_{\theta_{i}}\left\|\theta_{i}\right\|_{0}
Ω(θ)=θi∑∥θi∥0
其中 L0 范数
∥
θ
i
∥
0
\left\|\theta_{i}\right\|_{0}
∥θi∥0定义为𝜃𝑖中非零元素的个数。
通过约束 ∑ θ i ∥ θ i ∥ 0 \sum_{\theta_{i}}\left\|\theta_{i}\right\|_{0} ∑θi∥θi∥0的大小可以迫使网络中的连接权值大部分为 0,从而降低网络的实际参数量和网络容量。但是由于 L0 范数 ∥ θ i ∥ 0 \left\|\theta_{i}\right\|_{0} ∥θi∥0并不可导,不能利用梯度下降算法进行优化,在神经网络中使用的并不多。
9.5.2 L1 正则化
采用 L1 范数作为稀疏性惩罚项𝛺(𝜃)的正则化计算方式叫作 L1 正则化,即
Ω
(
θ
)
=
∑
θ
i
∥
θ
i
∥
1
\Omega(\theta)=\sum_{\theta_{i}}\left\|\theta_{i}\right\|_{1}
Ω(θ)=θi∑∥θi∥1
其中 L1 范数
∥
θ
i
∥
1
\left\|\theta_{i}\right\|_{1}
∥θi∥1定义为张量𝜃𝑖中所有元素的绝对值之和。L1 正则化也叫 Lasso Regularization,它是连续可导的,在神经网络中使用广泛。
L1 正则化可以实现如下:
import tensorflow as tf
# 创建网络参数 w1,w2
w1 = tf.random.normal([4,3])
w2 = tf.random.normal([4,2])
# 计算 L1 正则化项
loss_reg = tf.reduce_sum(tf.math.abs(w1)) + tf.reduce_sum(tf.math.abs(w2))
loss_reg
9.5.3 L2 正则化
采用 L2 范数作为稀疏性惩罚项𝛺(𝜃)的正则化计算方式叫做 L2 正则化,即
Ω
(
θ
)
=
∑
θ
i
∥
θ
i
∥
2
\Omega(\theta)=\sum_{\theta_{i}}\left\|\theta_{i}\right\|_{2}
Ω(θ)=θi∑∥θi∥2
其中 L2 范数
∥
θ
i
∥
2
\left\|\theta_{i}\right\|_{2}
∥θi∥2定义为张量𝜃𝑖中所有元素的平方和。L2 正则化也叫 Ridge Regularization,它和 L1 正则化一样,也是连续可导的,在神经网络中使用广泛。
L2 正则化项实现如下:
# 创建网络参数 w1,w2
w1 = tf.random.normal([4,3])
w2 = tf.random.normal([4,2])
# 计算 L2 正则化项
loss_reg = tf.reduce_sum(tf.square(w1)) + tf.reduce_sum(tf.square(w2))
loss_reg
9.5.4 正则化效果
继续以月牙形的 2 分类数据为例。在维持网络结构等其它超参数不变的条件下,在损失函数上添加 L2 正则化项,并通过改变不同的正则化超参数𝜆来获得不同程度的正则化效果。
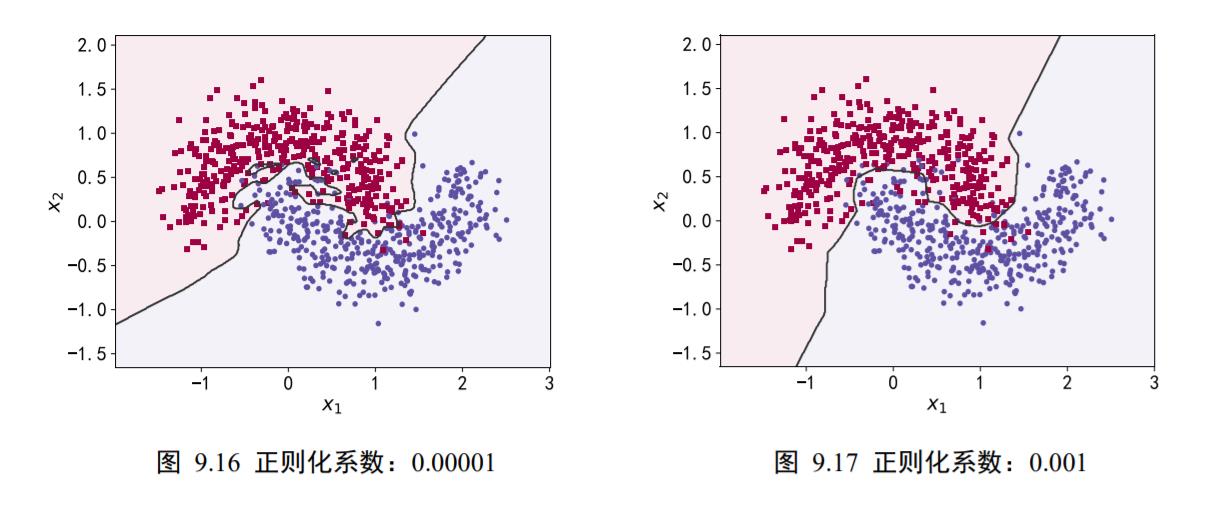
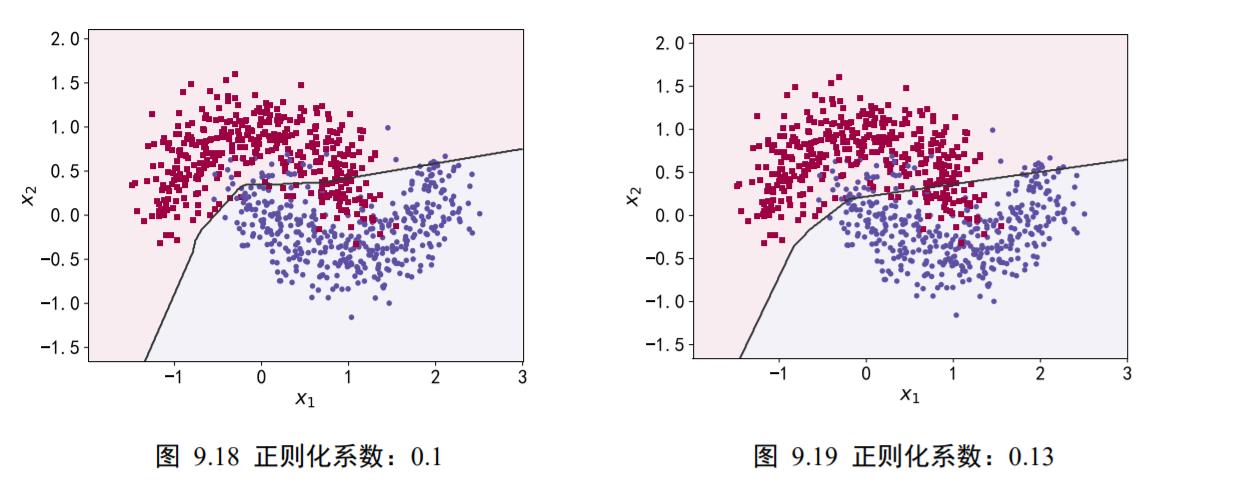
在训练了 500 个 Epoch 后,我们获得学习模型的分类决策边界,如图 9.16、图9.17、图 9.18、图 9.19 分布代表了正则化系数𝜆 = 0.00001、0.001、0.1、0.13时的分类效果。可以看到,随着正则化系数𝜆的增加,网络对参数稀疏性的惩罚变大,从而迫使优化算法搜索让网络容量更小的模型。在𝜆 = 0.00001时,正则化的作用比较微弱,网络出现了过拟合现象;但是𝜆 = 0.1时,网络已经能够优化到合适的容量,并没有出现明显过拟合或者欠拟合现象。
实际训练时,一般优先尝试较小的正则化系数𝜆,观测网络是否出现过拟合现象。然后尝试逐渐增大𝜆参数来增加网络参数稀疏性,提高泛化能力。
但是,过大的𝜆参数有可能导致网络不收敛,需要根据实际任务调节。
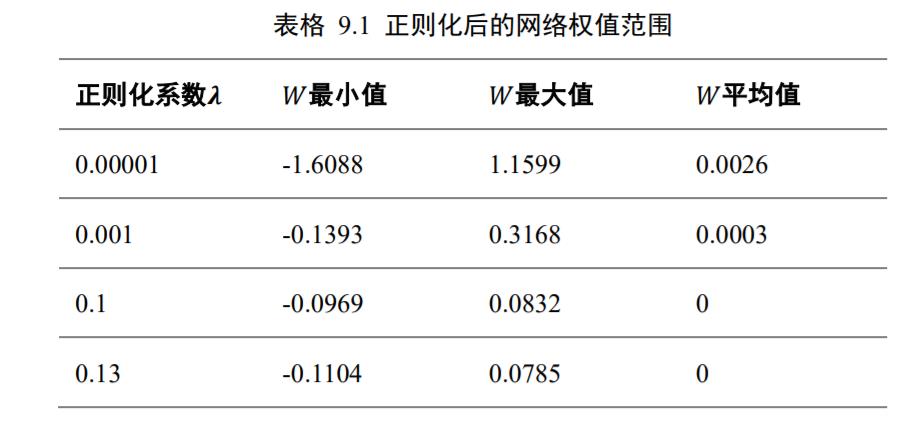
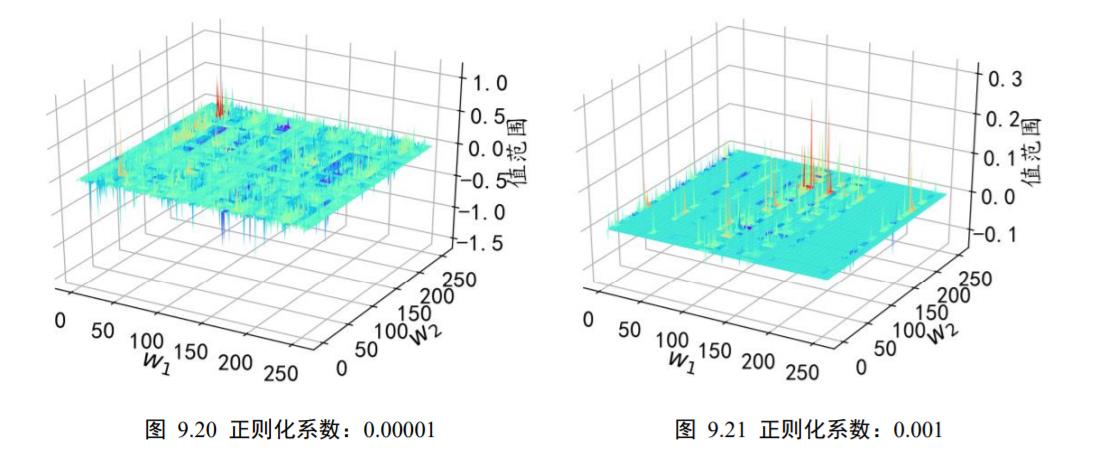
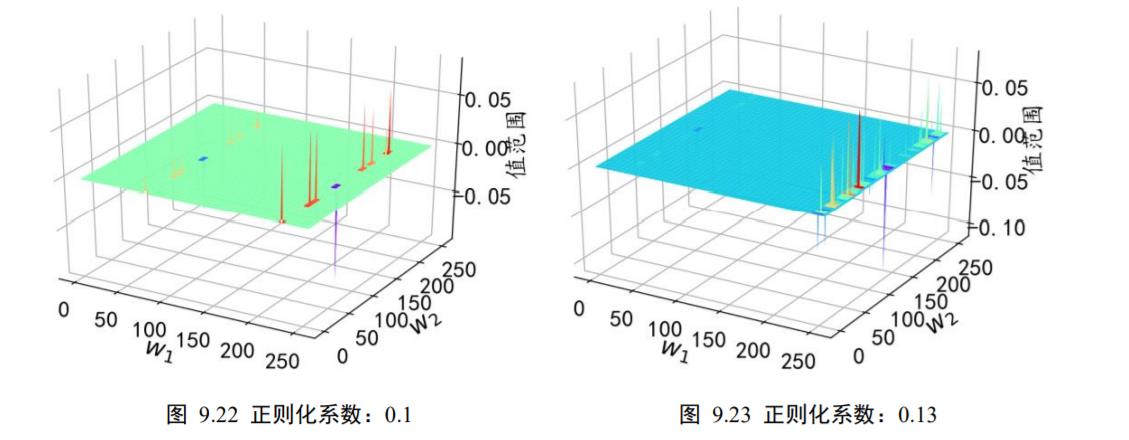
在不同的正则化系数𝜆下,我们统计了网络中每个连接权值的数值范围。考虑网络的第2 层的权值矩阵𝑾,其 shape 为[256,256],即将输入长度为 256 的向量转换为 256 的输出向量。从全连接层权值连接的角度来看,𝑾一共包含了256 ∙ 256根连接线的权值,我们将它对应到图 9.20、图 9.21、图 9.22、图 9.23 中的 X-Y 网格中,其中 X 轴的范围为[0,255],Y 轴的范围为[0,255],X-Y 网格的所有整数点分别代表了 shape 为[256,256]的权值张量𝑾的每个位置,每个网格点绘制出当前连接上的权值。
从图中可以看到,添加了不同程度的正则化约束对网络权值的影响。在𝜆 = 0.00001时,正则化的作用比较微弱,网络中权值数值相对较大,分布在[−1.6088,1.1599]区间;在添加较强稀疏性约束𝜆 = 0.13后,网络权值数值约束在[−0.1104,0.0785]较小范围中,具体的权值范围如表格 9.1 所示,同时也可以观察到正则化后权值的稀疏性变化。
9.6 Dropout
2012 年,Hinton 等人在其论文《Improving neural networks by preventing co-adaptationof feature detectors》中使用了 Dropout 方法来提高模型性能。Dropout 通过随机断开神经网络的连接,减少每次训练时实际参与计算的模型的参数量;但是在测试时,Dropout 会恢复所有的连接,保证模型测试时获得最好的性能。
图 9.24 是全连接层网络在某次前向计算时连接状况的示意图。图(a)是标准的全连接神经网络,当前节点与前一层的所有输入节点相连。
在添加了 Dropout 功能的网络层中,如图 9.24(b)所示,每条连接是否断开符合某种预设的概率分布,如断开概率为𝑝的伯努利分布。图 9.24(b)中的显示了某次具体的采样结果,虚线代表了采样结果为断开的连接线,实线代表了采样结果不断开的连接线。

在 TensorFlow 中,可以通过 tf.nn.dropout(x, rate)函数实现某条连接的 Dropout 功能,其中 rate 参数设置断开的概率值𝑝。例如:
# 添加 dropout 操作,断开概率为 0.5
x = tf.nn.dropout(x, rate=0.5)
也可以将 Dropout 作为一个网络层使用,在网络中间插入一个 Dropout 层。例如:
# 添加 Dropout 层,断开概率为 0.5
model.add(layers.Dropout(rate=0.5))
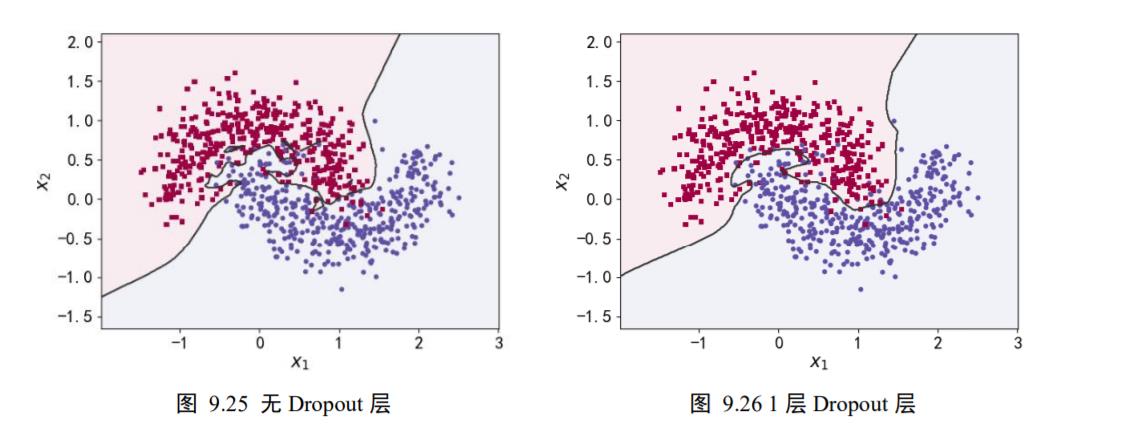
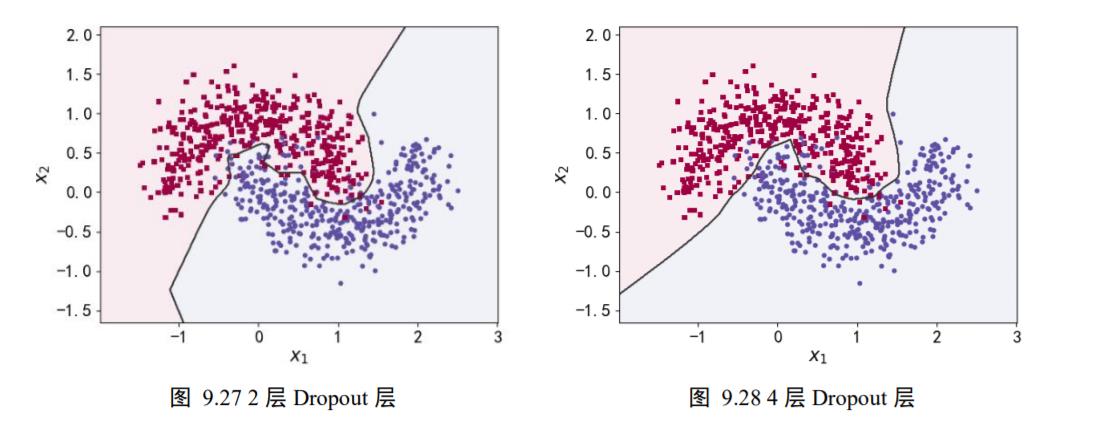
为了验证 Dropout 层对网络训练的影响,我们在维持网络层数等超参数不变的条件下,通过在 5 层的全连接层中间隔插入不同数量的 Dropout 层来观测 Dropout 对网络训练的影响。
如图 9.25、图 9.26、图 9.27、图 9.28 所示,分布绘制了不添加 Dropout 层,添加 1、2、4 层 Dropout 层网络模型的决策边界效果。可以看到,在不添加 Dropout 层时,网络模型与之前观测的结果一样,出现了明显的过拟合现象;随着 Dropout 层的增加,网络模型训练时的实际容量减少,泛化能力变强。
9.7 数据增强
除了上述介绍的方式可以有效检测和抑制过拟合现象之外,增加数据集规模是解决过拟合最重要的途径。但是收集样本数据和标签往往是代价昂贵的,在有限的数据集上,通过数据增强技术可以增加训练的样本数量,获得一定程度上的性能提升。
数据增强(DataAugmentation)是指在维持样本标签不变的条件下,根据先验知识改变样本的特征,使得新产生的样本也符合或者近似符合数据的真实分布。
以图片数据为例,我们来介绍怎么做数据增强。数据集中的图片大小往往是不一致的,为了方便神经网络处理,需要将图片缩放到某个固定的大小,如图 9.29 所示,是缩放后的固定224 × 224大小的图片。对于图中的人物图片,根据先验知识,我们知道旋转、缩放、平移、裁剪、改变视角、遮挡某局部区域都不会改变图片的主体类别标签,因此针对图片数据,可以有多种数据增强方式。

TensorFlow 中提供了常用图片的处理函数,位于 tf.image 子模块中。通过tf.image.resize 函数可以实现图片的缩放功能,我们将数据增强一般实现在预处理函数preprocess中,将图片从文件系统读取进来后,即可进行图片数据增强操作。例如:
import matplotlib.pyplot as plt
import tensorflow as tf
from imageio import imread, imwrite
import os
img = imread('/content/lena512color.tiff')
print(img.shape)
plt.imshow(img)
plt.axis('off')
# 转换格式成png,否则无法进行tensorflow图像处理
if not os.path.isfile("lena512color.png"):
imwrite(im=img, format='png', uri='lena512color.png')
(512, 512, 3)
def preprocess(x):
# 预处理函数
# x: 图片的路径
x = tf.io.read_file(x)
x = tf.image.decode_jpeg(x, channels=3) # RGBA
# 图片缩放到 244x244 大小,这个大小根据网络设定自行调整
x = tf.image.resize(x, [244, 244])
pic_lena = preprocess('/content/lena512color.png')
print(pic_lena.shape)
plt.imshow(pic_lena / 255.)
plt.axis('off')
(244, 244, 3)
9.7.1 旋转
旋转图片是非常常见的图片数据增强方式,通过将原图进行一定角度的旋转运算,可以获得不同角度的新图片,这些图片的标签信息维持不变,如图 9.30 所示。

通过 tf.image.rot90(x, k=1)可以实现图片按逆时针方式旋转 k 个 90 度,例如:
# 图片逆时针旋转 180 度
rot_x = tf.image.rot90(pic_lena, 2)
plt.imshow(rot_x / 255.)
plt.axis('off')
plt.show()
9.7.2 翻转
图片的翻转分为沿水平轴翻转和竖直轴翻转,分别如图 9.31、图 9.32 所示。在TensorFlow 中,可以通过 tf.image.random_flip_left_right 和 tf.image.random_flip_up_down 实现图片在水平方向和竖直方向的随机翻转操作,例如:
# 随机水平翻转
rot_x=tf.image.random_flip_left_right(pic_lena)
plt.imshow(rot_x/255.)
plt.show()
# 随机竖直翻转
rot_x=tf.image.random_flip_up_down(pic_lena)
plt.imshow(rot_x/255.)
plt.show()

9.7.3 裁剪
通过在原图的左右或者上下方向去掉部分边缘像素,可以保持图片主体不变,同时获得新的图片样本。在实际裁剪时,一般先将图片缩放到略大于网络输入尺寸的大小,再裁剪到合适大小。例如网络的输入大小为224 × 224,那么可以先通过 resize 函数将图片缩放到244 × 244大小,再随机裁剪到224 × 224大小。代码实现如下:
# 图片先缩放到稍大尺寸
x = tf.image.resize(pic_lena, [244, 244])
# 再随机裁剪到合适尺寸
x = tf.image.random_crop(pic_lena, [224,224,3])
图 9.33 是缩放到244 × 244大小的图片,图 9.34 某次随机裁剪到224 × 224大小的例子,图 9.35 也是某次随机裁剪的例子。

9.7.4 生成数据
通过生成模型在原有数据上进行训练,学习到真实数据的分布,从而利用生成模型获得新的样本,这种方式也可以在一定程度上提升网络性能。如通过条件生成对抗网络(Conditional GAN,简称 CGAN)可以生成带标签的样本数据,如图 9.36 所示。

9.7.5 其它方式
除了上述介绍的典型图片数据增强方式以外,可以根据先验知识,在不改变图片标签信息的条件下,任意变换图片数据,获得新的图片。图 9.37 演示了在原图上叠加高斯噪声后的图片数据,图 9.38 演示了通过改变图片的观察视角后获得的新图片,图 9.39 演示了在原图上随机遮挡部分区域获得的新图片。

9.8 过拟合问题实战
前面我们大量使用了月牙形状的 2 分类数据集来演示网络模型在各种防止过拟合措施下的性能表现。本节实战我们将基于月牙形状的 2 分类数据集的过拟合与欠拟合模型,进行完整的实战。
9.8.1 构建数据集
我们使用的数据集样本特性向量长度为 2,标签为 0 或 1,分别代表了两种类别。借助于 scikit-learn 库中提供的 make_moons 工具,我们可以生成任意多数据的训练集。首先打开 cmd 命令终端,安装 scikit-learn 库,命令如下:
# pip 安装 scikit-learn 库
pip install -U scikit-learn
为了演示过拟合现象,我们只采样了 1000 个样本数据,同时添加标准差为 0.25 的高斯噪声数据。代码如下:
# 导入数据集生成工具
from sklearn.datasets import make_moons
from sklearn.model_selection import train_test_split
#从moon分布中随机采样1000个点,并切分为训练集和测试集
N_SAMPLES = 1000
TEST_SIZE = None
X,y=make_moons(n_samples=N_SAMPLES,noise=0.25,random_state=100)
X_train,X_test,y_train,y_test=train_test_split(X,y,test_size=TEST_SIZE,random_state=42)
make_plot 函数可以方便地根据样本的坐标 X 和样本的标签 y 绘制出数据的分布图:
import matplotlib.pyplot as plt
from matplotlib import cm
import numpy as np
def mscatter(x, y, ax=None, m=None, **kw):
import matplotlib.markers as mmarkers
if not ax: ax = plt.gca()
sc = ax.scatter(x, y, **kw)
if (m is not None) and (len(m) == len(x)):
paths = []
for marker in m:
if isinstance(marker, mmarkers.MarkerStyle):
marker_obj = marker
else:
marker_obj = mmarkers.MarkerStyle(marker)
path = marker_obj.get_path().transformed(
marker_obj.get_transform())
paths.append(path)
sc.set_paths(paths)
return sc
def make_plot(X, y, plot_name, file_name, XX, YY, preds, dark=False):
# 绘制数据集的分布, X 为 2D 坐标, y 为数据点的标签
if dark:
plt.style.use('dark_background')
else:
sns.set_style("whitegrid")
axes = plt.gca()
axes.set_xlim([-2, 3])
axes.set_ylim([-1.5, 2])
axes.set(xlabel="$x_1$", ylabel="$x_2$")
plt.title(plot_name, fontsize=20, fontproperties='SimHei')
plt.subplots_adjust(left=0.20)
plt.subplots_adjust(right=0.80)
if XX is not None and YY is not None and preds is not None:
plt.contourf(XX, YY, preds.reshape(XX.shape), 25, alpha=0.08, cmap=plt.cm.Spectral)
plt.contour(XX, YY, preds.reshape(XX.shape), levels=[.5], cmap="Greys", vmin=0, vmax=.6)
# 绘制散点图,根据标签区分颜色m=markers
markers = ['o' if i == 1 else 's' for i in y.ravel()]
mscatter(X[:, 0], X[:, 1], c=y.ravel(), s=20, cmap=plt.cm.Spectral, edgecolors='none', m=markers, ax=axes)
# 保存矢量图
plt.savefig(file_name)
plt.show()
绘制出采样的 1000 个样本分布,如图 9.40 所示,红色方块点为一个类别,蓝色圆点为另一个类别。
# 绘制数据集分布
make_plot(X_train,y_train,None,'dataset.svg',None,None,None)

9.8.2 网络层数的影响
为了探讨不同的网络深度下的过拟合程度,我们共进行了 5 次训练实验。在𝑛 ∈ [0,4]时,构建网络层数为𝑛 + 2层的全连接层网络,并通过 Adam 优化器训练 500 个 Epoch,获得网络在训练集上的分隔曲线,如图 9.12、图 9.13、图 9.14、图 9.15 中所示。
from tensorflow.keras import Sequential,layers
import seaborn as sns
def network_layers_influence(X_train, y_train):
# 构建 5 种不同层数的网络
for n in range(5):
# 创建容器
model = Sequential()
# 创建第一层
model.add(layers.Dense(8, input_dim=2, activation='relu'))
# 添加 n 层,共 n+2 层
for _ in range(n):
model.add(layers.Dense(32, activation='relu'))
# 创建最末层
model.add(layers.Dense(1, activation='sigmoid'))
# 模型装配与训练
model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy'])
model.fit(X_train, y_train, epochs=500, verbose=1)
# 绘制不同层数的网络决策边界曲线
xx = np.arange(-2, 3, 0.01)# 可视化的 x 坐标范围为[-2, 3]
yy = np.arange(-1.5, 2, 0.01) # 可视化的 y 坐标范围为[-1.5, 2]
# 利用训练好的模型,用(XX,YY)生成的数据特征来预测标签的结果
XX, YY = np.meshgrid(xx, yy)
preds = model.predict_classes(np.c_[XX.ravel(), YY.ravel()])
title = "网络层数:{0}".format(2 + n)
file = "网络容量_%i.png" % (2 + n)
make_plot(X_train, y_train, title, file, XX, YY, preds)
network_layers_influence(X_train,y_train)
9.8.3 Dropout 的影响
为了探讨 Dropout 层对网络训练的影响,我们共进行了 5 次实验,每次实验使用 7 层的全连接层网络进行训练,但是在全连接层中间隔插入 0~4 个 Dropout 层,并通过 Adam优化器训练 500 个 Epoch,网络训练效果如图 9.25、图 9.26、图 9.27、图 9.28 所示。
def dropout_influence(x_train,y_train):
# 构建5种不同数量的Dropout层的网络
for n in range(5):
# 创建容器
model=Sequential()
# 创建第一层
model.add(layers.Dense(8,input_dim=2,activation='relu'))
counter=0
# 网络层数固定为5
for _ in range(5):
model.add(layers.Dense(64,activation='relu'))
# 添加n个Dropout
if counter<n:
counter+=1
model.add(layers.Dropout(rate=0.5))
# 输出层
model.add(layers.Dense(1,activation='sigmoid'))
# 模型装配
model.compile(loss='binary_crossentropy',optimizer='adam',metrics=['accuracy'])
# 训练
model.fit(X_train,y_train,epochs=500,verbose=1)
# 绘制不同 Dropout 层数的决策边界曲线
# 可视化的 x 坐标范围为[-2, 3]
xx = np.arange(-2, 3, 0.01)
# 可视化的 y 坐标范围为[-1.5, 2]
yy = np.arange(-1.5, 2, 0.01)
# 生成 x-y 平面采样网格点,方便可视化
XX, YY = np.meshgrid(xx, yy)
preds = model.predict_classes(np.c_[XX.ravel(), YY.ravel()])
title = "无Dropout层" if n == 0 else "{0}层 Dropout层".format(n)
file = "Dropout_{}.png" .format(n)
make_plot(X_train, y_train, title, file, XX, YY, preds)
dropout_influence(X_train,y_train)
9.8.4 正则化的影响
为了探讨正则化系数𝜆对网络模型训练的影响,我们采用 L2 正则化方式,构建了 5 层的神经网络,其中第 2、3、4 层神经网络层的权值张量 W 均添加 L2 正则化约束项,代码如下:
def build_model_with_regularization(_lambda):
# 创建带正则化项的神经网络
model = Sequential()
model.add(layers.Dense(8, input_dim=2, activation='relu')) # 不带正则化项
# 2-4层均是带 L2 正则化项
model.add(layers.Dense(256, activation='relu', kernel_regularizer=regularizers.l2(_lambda)))
model.add(layers.Dense(256, activation='relu', kernel_regularizer=regularizers.l2(_lambda)))
model.add(layers.Dense(256, activation='relu', kernel_regularizer=regularizers.l2(_lambda)))
# 输出层
model.add(layers.Dense(1, activation='sigmoid'))
model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy']) # 模型装配
return model
在保持网络结构不变的条件下,我们通过调节正则化系数𝜆 =0.00001、0.001、0.1、0.12、0.13来测试网络的训练效果,并绘制出学习模型在训练集上的决策边界曲线,如图 9.16、图 9.17、图 9.18、图 9.19 所示。
from tensorflow.keras import regularizers
def build_model_with_regularization(_lambda):
# 创建带正则化项的神经网络
model = Sequential()
model.add(layers.Dense(8, input_dim=2, activation='relu')) # 不带正则化项
# 2-4层均是带 L2 正则化项
model.add(layers.Dense(256, activation='relu', kernel_regularizer=regularizers.l2(_lambda)))
model.add(layers.Dense(256, activation='relu', kernel_regularizer=regularizers.l2(_lambda)))
model.add(layers.Dense(256, activation='relu', kernel_regularizer=regularizers.l2(_lambda)))
# 输出层
model.add(layers.Dense(1, activation='sigmoid'))
model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy']) # 模型装配
return model
def plot_weights_matrix(model, layer_index, plot_name, file_name):
# 绘制权值范围函数
# 提取指定层的权值矩阵
weights = model.layers[layer_index].get_weights()[0]
shape = weights.shape
# 生成和权值矩阵等大小的网格坐标
X = np.array(range(shape[1]))
Y = np.array(range(shape[0]))
X, Y = np.meshgrid(X, Y)
# 绘制3D图
fig = plt.figure()
ax = fig.gca(projection='3d')
ax.xaxis.set_pane_color((1.0, 1.0, 1.0, 0.0))
ax.yaxis.set_pane_color((1.0, 1.0, 1.0, 0.0))
ax.zaxis.set_pane_color((1.0, 1.0, 1.0, 0.0))
plt.title(plot_name, fontsize=20, fontproperties='SimHei')
# 绘制权值矩阵范围
ax.plot_surface(X, Y, weights, cmap=plt.get_cmap('rainbow'), linewidth=0)
# 设置坐标轴名
ax.set_xlabel('网格x坐标', fontsize=16, rotation=0, fontproperties='SimHei')
ax.set_ylabel('网格y坐标', fontsize=16, rotation=0, fontproperties='SimHei')
ax.set_zlabel('权值', fontsize=16, rotation=90, fontproperties='SimHei')
# 保存矩阵范围图
plt.savefig(file_name + ".svg")
plt.close(fig)
def regularizers_influence(X_train, y_train):
for _lambda in [1e-5, 1e-3, 1e-1, 0.12, 0.13]: # 设置不同的正则化系数
# 创建带正则化项的模型
model = build_model_with_regularization(_lambda)
# 模型训练
model.fit(X_train, y_train, epochs=500, verbose=1)
# 绘制权值范围
layer_index = 2
plot_title = "正则化系数:{}".format(_lambda)
file_name = "正则化网络权值_" + str(_lambda)
# 绘制网络权值范围图
plot_weights_matrix(model, layer_index, plot_title, file_name)
# 绘制不同正则化系数的决策边界线
# 可视化的 x 坐标范围为[-2, 3]
xx = np.arange(-2, 3, 0.01)
# 可视化的 y 坐标范围为[-1.5, 2]
yy = np.arange(-1.5, 2, 0.01)
# 生成 x-y 平面采样网格点,方便可视化
XX, YY = np.meshgrid(xx, yy)
preds = model.predict_classes(np.c_[XX.ravel(), YY.ravel()])
title = "正则化系数:{}".format(_lambda)
file = "正则化_%g.svg" % _lambda
make_plot(X_train, y_train, title, file, XX, YY, preds)
regularizers_influence(X_train, y_train)
综上所述,附上所有代码。
#!/usr/bin/env python
# encoding: utf-8
import matplotlib.pyplot as plt
# 导入数据集生成工具
import numpy as np
import seaborn as sns
from sklearn.datasets import make_moons
from sklearn.model_selection import train_test_split
from tensorflow.keras import layers, Sequential, regularizers
from mpl_toolkits.mplot3d import Axes3D
plt.rcParams['font.size'] = 16
plt.rcParams['font.family'] = ['STKaiti']
plt.rcParams['axes.unicode_minus'] = False
OUTPUT_DIR = 'output_dir'
N_EPOCHS = 500
def load_dataset():
# 采样点数
N_SAMPLES = 1000
# 测试数量比率
TEST_SIZE = None
# 从 moon 分布中随机采样 1000 个点,并切分为训练集-测试集
X, y = make_moons(n_samples=N_SAMPLES, noise=0.25, random_state=100)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=TEST_SIZE, random_state=42)
return X, y, X_train, X_test, y_train, y_test
def make_plot(X, y, plot_name, file_name, XX=None, YY=None, preds=None, dark=False, output_dir=OUTPUT_DIR):
# 绘制数据集的分布, X 为 2D 坐标, y 为数据点的标签
if dark:
plt.style.use('dark_background')
else:
sns.set_style("whitegrid")
axes = plt.gca()
axes.set_xlim([-2, 3])
axes.set_ylim([-1.5, 2])
axes.set(xlabel="$x_1$", ylabel="$x_2$")
plt.title(plot_name, fontsize=20, fontproperties='SimHei')
plt.subplots_adjust(left=0.20)
plt.subplots_adjust(right=0.80)
if XX is not None and YY is not None and preds is not None:
plt.contourf(XX, YY, preds.reshape(XX.shape), 25, alpha=0.08, cmap=plt.cm.Spectral)
plt.contour(XX, YY, preds.reshape(XX.shape), levels=[.5], cmap="Greys", vmin=0, vmax=.6)
# 绘制散点图,根据标签区分颜色m=markers
markers = ['o' if i == 1 else 's' for i in y.ravel()]
mscatter(X[:, 0], X[:, 1], c=y.ravel(), s=20, cmap=plt.cm.Spectral, edgecolors='none', m=markers, ax=axes)
# 保存矢量图
plt.savefig(output_dir + '/' + file_name)
plt.close()
def mscatter(x, y, ax=None, m=None, **kw):
import matplotlib.markers as mmarkers
if not ax: ax = plt.gca()
sc = ax.scatter(x, y, **kw)
if (m is not None) and (len(m) == len(x)):
paths = []
for marker in m:
if isinstance(marker, mmarkers.MarkerStyle):
marker_obj = marker
else:
marker_obj = mmarkers.MarkerStyle(marker)
path = marker_obj.get_path().transformed(
marker_obj.get_transform())
paths.append(path)
sc.set_paths(paths)
return sc
def network_layers_influence(X_train, y_train):
# 构建 5 种不同层数的网络
for n in range(5):
# 创建容器
model = Sequential()
# 创建第一层
model.add(layers.Dense(8, input_dim=2, activation='relu'))
# 添加 n 层,共 n+2 层
for _ in range(n):
model.add(layers.Dense(32, activation='relu'))
# 创建最末层
model.add(layers.Dense(1, activation='sigmoid'))
# 模型装配与训练
model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy'])
model.fit(X_train, y_train, epochs=N_EPOCHS, verbose=1)
# 绘制不同层数的网络决策边界曲线
# 可视化的 x 坐标范围为[-2, 3]
xx = np.arange(-2, 3, 0.01)
# 可视化的 y 坐标范围为[-1.5, 2]
yy = np.arange(-1.5, 2, 0.01)
# 生成 x-y 平面采样网格点,方便可视化
XX, YY = np.meshgrid(xx, yy)
preds = model.predict_classes(np.c_[XX.ravel(), YY.ravel()])
title = "网络层数:{0}".format(2 + n)
file = "网络容量_%i.png" % (2 + n)
make_plot(X_train, y_train, title, file, XX, YY, preds, output_dir=OUTPUT_DIR + '/network_layers')
def dropout_influence(X_train, y_train):
# 构建 5 种不同数量 Dropout 层的网络
for n in range(5):
# 创建容器
model = Sequential()
# 创建第一层
model.add(layers.Dense(8, input_dim=2, activation='relu'))
counter = 0
# 网络层数固定为 5
for _ in range(5):
model.add(layers.Dense(64, activation='relu'))
# 添加 n 个 Dropout 层
if counter < n:
counter += 1
model.add(layers.Dropout(rate=0.5))
# 输出层
model.add(layers.Dense(1, activation='sigmoid'))
# 模型装配
model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy'])
# 训练
model.fit(X_train, y_train, epochs=N_EPOCHS, verbose=1)
# 绘制不同 Dropout 层数的决策边界曲线
# 可视化的 x 坐标范围为[-2, 3]
xx = np.arange(-2, 3, 0.01)
# 可视化的 y 坐标范围为[-1.5, 2]
yy = np.arange(-1.5, 2, 0.01)
# 生成 x-y 平面采样网格点,方便可视化
XX, YY = np.meshgrid(xx, yy)
preds = model.predict_classes(np.c_[XX.ravel(), YY.ravel()])
title = "无Dropout层" if n == 0 else "{0}层 Dropout层".format(n)
file = "Dropout_%i.png" % n
make_plot(X_train, y_train, title, file, XX, YY, preds, output_dir=OUTPUT_DIR + '/dropout')
def build_model_with_regularization(_lambda):
# 创建带正则化项的神经网络
model = Sequential()
model.add(layers.Dense(8, input_dim=2, activation='relu')) # 不带正则化项
# 2-4层均是带 L2 正则化项
model.add(layers.Dense(256, activation='relu', kernel_regularizer=regularizers.l2(_lambda)))
model.add(layers.Dense(256, activation='relu', kernel_regularizer=regularizers.l2(_lambda)))
model.add(layers.Dense(256, activation='relu', kernel_regularizer=regularizers.l2(_lambda)))
# 输出层
model.add(layers.Dense(1, activation='sigmoid'))
model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy']) # 模型装配
return model
def plot_weights_matrix(model, layer_index, plot_name, file_name, output_dir=OUTPUT_DIR):
# 绘制权值范围函数
# 提取指定层的权值矩阵
weights = model.layers[layer_index].get_weights()[0]
shape = weights.shape
# 生成和权值矩阵等大小的网格坐标
X = np.array(range(shape[1]))
Y = np.array(range(shape[0]))
X, Y = np.meshgrid(X, Y)
# 绘制3D图
fig = plt.figure()
ax = fig.gca(projection='3d')
ax.xaxis.set_pane_color((1.0, 1.0, 1.0, 0.0))
ax.yaxis.set_pane_color((1.0, 1.0, 1.0, 0.0))
ax.zaxis.set_pane_color((1.0, 1.0, 1.0, 0.0))
plt.title(plot_name, fontsize=20, fontproperties='SimHei')
# 绘制权值矩阵范围
ax.plot_surface(X, Y, weights, cmap=plt.get_cmap('rainbow'), linewidth=0)
# 设置坐标轴名
ax.set_xlabel('网格x坐标', fontsize=16, rotation=0, fontproperties='SimHei')
ax.set_ylabel('网格y坐标', fontsize=16, rotation=0, fontproperties='SimHei')
ax.set_zlabel('权值', fontsize=16, rotation=90, fontproperties='SimHei')
# 保存矩阵范围图
plt.savefig(output_dir + "/" + file_name + ".svg")
plt.close(fig)
def regularizers_influence(X_train, y_train):
for _lambda in [1e-5, 1e-3, 1e-1, 0.12, 0.13]: # 设置不同的正则化系数
# 创建带正则化项的模型
model = build_model_with_regularization(_lambda)
# 模型训练
model.fit(X_train, y_train, epochs=N_EPOCHS, verbose=1)
# 绘制权值范围
layer_index = 2
plot_title = "正则化系数:{}".format(_lambda)
file_name = "正则化网络权值_" + str(_lambda)
# 绘制网络权值范围图
plot_weights_matrix(model, layer_index, plot_title, file_name, output_dir=OUTPUT_DIR + '/regularizers')
# 绘制不同正则化系数的决策边界线
# 可视化的 x 坐标范围为[-2, 3]
xx = np.arange(-2, 3, 0.01)
# 可视化的 y 坐标范围为[-1.5, 2]
yy = np.arange(-1.5, 2, 0.01)
# 生成 x-y 平面采样网格点,方便可视化
XX, YY = np.meshgrid(xx, yy)
preds = model.predict_classes(np.c_[XX.ravel(), YY.ravel()])
title = "正则化系数:{}".format(_lambda)
file = "正则化_%g.svg" % _lambda
make_plot(X_train, y_train, title, file, XX, YY, preds, output_dir=OUTPUT_DIR + '/regularizers')
def main():
X, y, X_train, X_test, y_train, y_test = load_dataset()
# 绘制数据集分布
make_plot(X, y, None, "月牙形状二分类数据集分布.svg")
# 网络层数的影响
network_layers_influence(X_train, y_train)
# Dropout的影响
dropout_influence(X_train, y_train)
# 正则化的影响
regularizers_influence(X_train, y_train)
if __name__ == '__main__':
main()















 827
827











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











