









开源软件包 SENNA 和 word2vec 中都用到了词向量(distributed word representation),当时我就在想,对于我们的中文,是不是也类似地有字向量(distributed character representation)的概念呢?
最近恰好读到复旦大学郑骁庆博士等人的文章 [1]《Deep Learning for Chinese Word Segmentation and POS tagging》。这篇文章利用文 [3] 作者提出的神经网络框架,针对中文分词和词性标注任务,给出了一种基于字向量的 perceptron-style 算法,该算法的亮点是受文 [4] 启发在训练部分用了一种新的思路,而不是采用传统的 maximum log-likelihood 方法,极大地降低了算法复杂度,且非常容易实现。数值实验表明,该算法的 performance 也还不错。
本博客是读完文 [1] 后的一则笔记,内容以翻译为主,同时也穿插了一些注记,供感兴趣的读者参考。



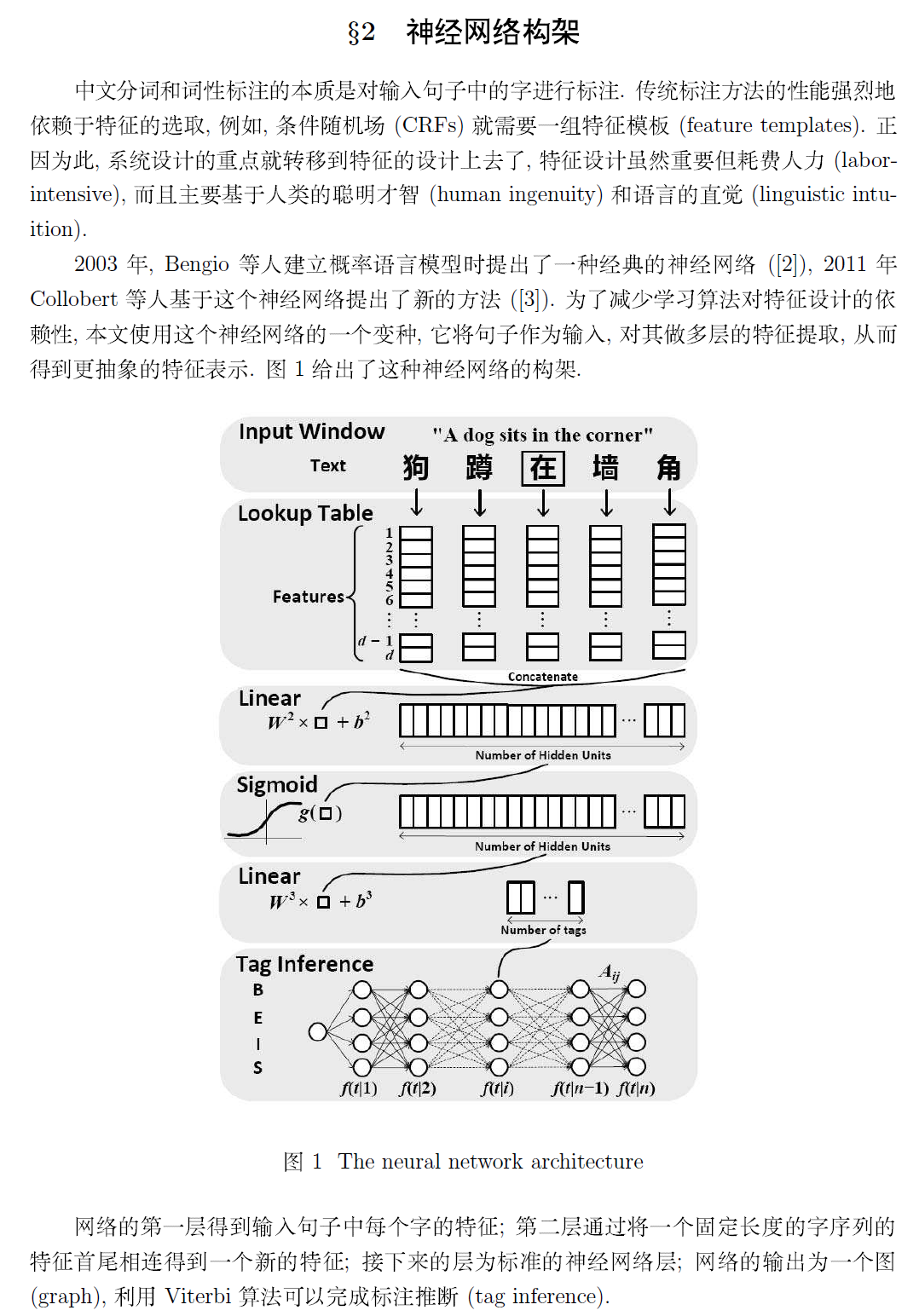









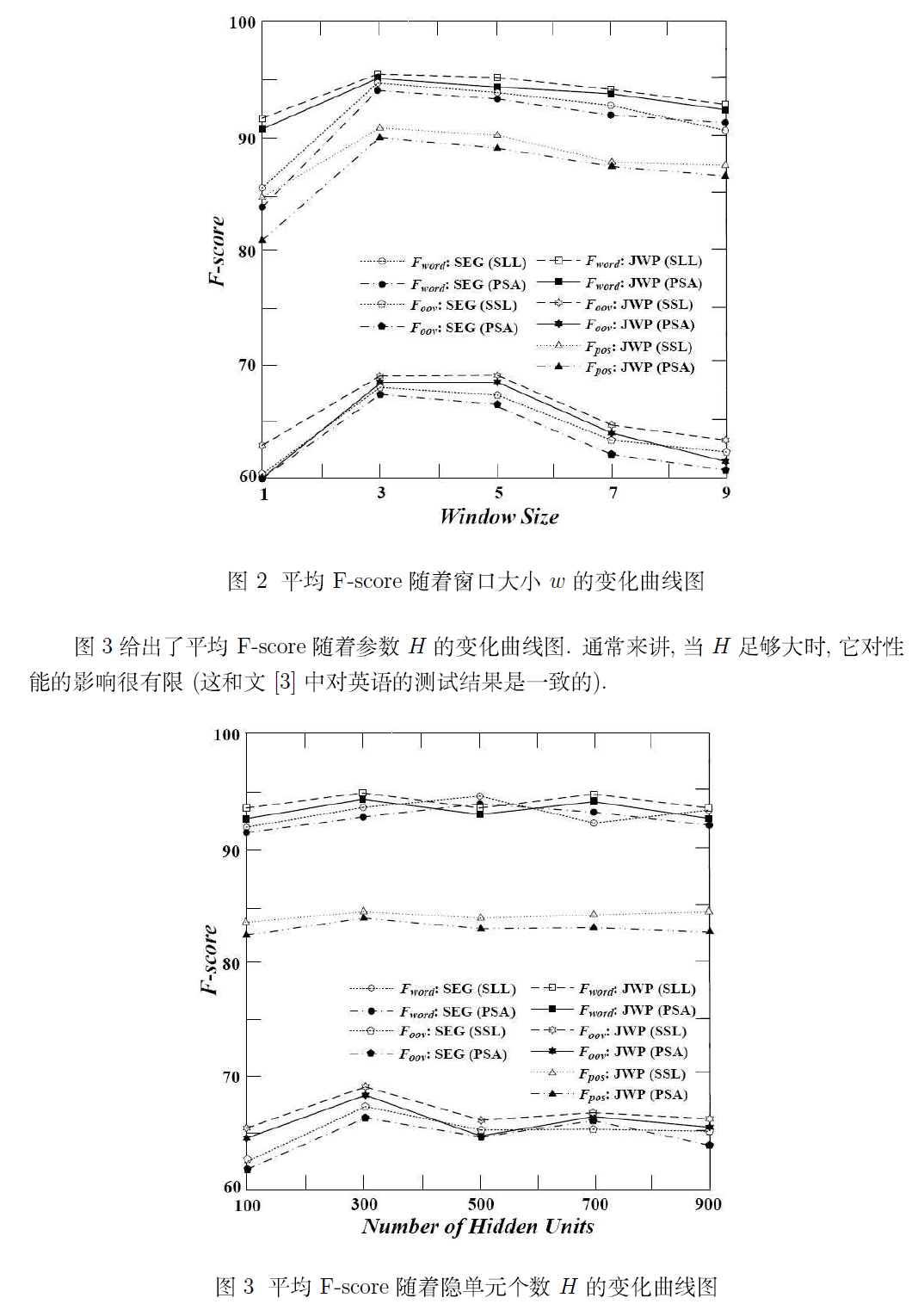

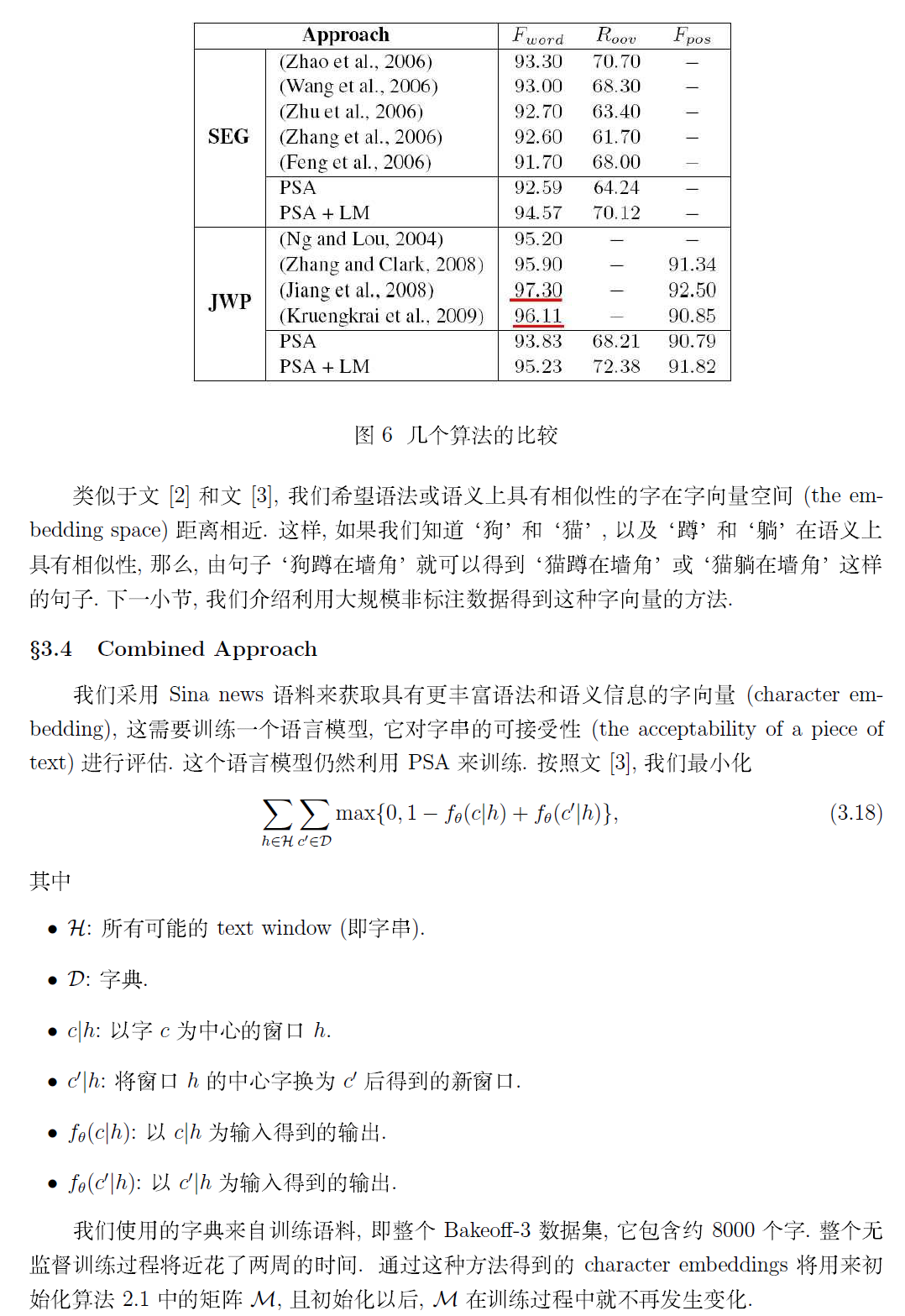
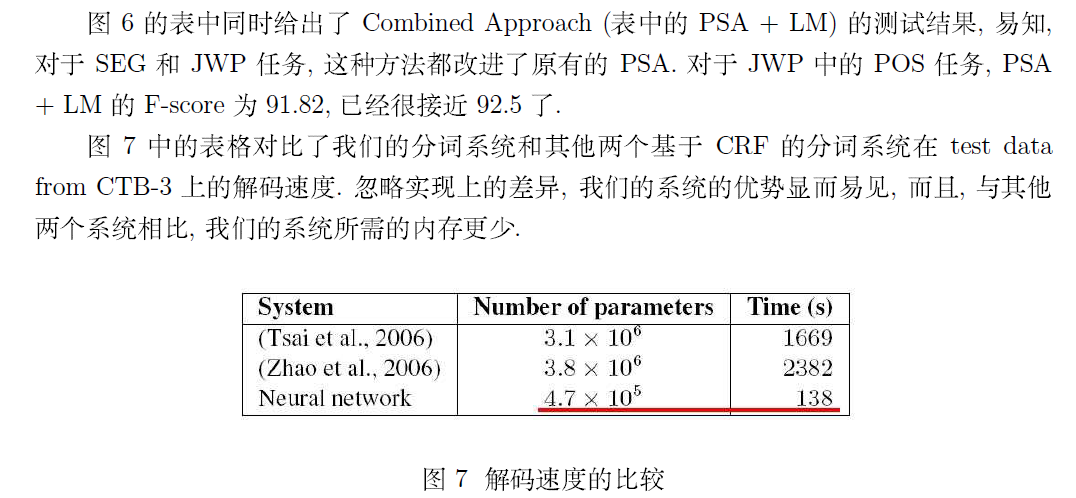


若需要本文完整的 PDF 文档,请点击《Deep Learning 在中文分词和词性标注任务中的应用》进行下载!
作者: peghoty
出处: http://blog.csdn.net/itplus/article/details/13616045
欢迎转载/分享, 但请务必声明文章出处.















 6659
6659

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









