






执行wordCount代码之前需要先导入几个包,找到haoop安装目录下的share和mapreduce目录底下包,如图:

wordCount中的计算框架mapreduce的具体流程:
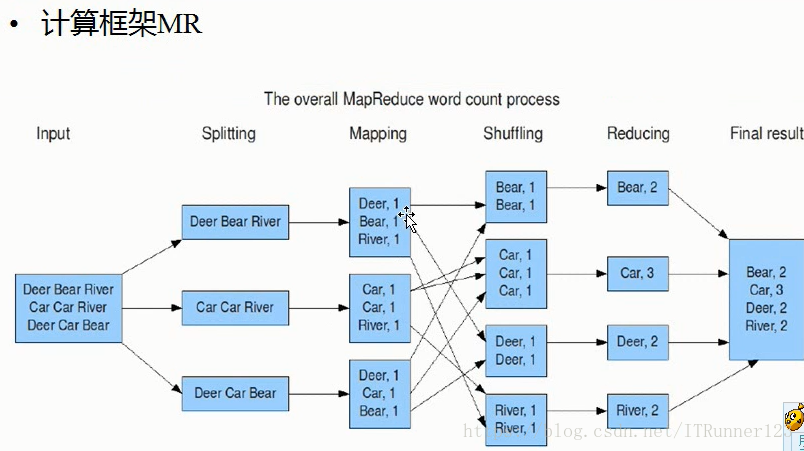
shuffling都是系统内部的处理过程,我们具体要做的是在map中如何分割出键和值,对键和值处理之后再传给reducer,在reduce方法里具体做对数据的总结处理!
wordcount:
运行wordcount前需要将本地的文本文件拷贝到hdfs中。
注意是在hdfs中新建目录:
hdfs dfs -mkdir -p /usr/input
然后在本地新建个txt文件(里面是一堆字符串),将文件拷贝到hdfs中:
hdfs dfs -put wc.txt /usr/input
再新建一个目录:
hdfs dfs -mkdir -p /usr/output
最后面运行命令:
hadoop jar /wordcount.jar com.lianxi.w.RunJob
解释:
/wordcount.jar:这个是从eclipse中将程序打包出来的jar
com.lianxi.w(包名) RunJob(程序的入口程序,包含main的程序)
查看结果:
hadoop fs -cat /usr/output/wc/part-r-00000
wordcount函数解释:
//从文件的split中读取,每行调用一次,把该行的值key,该行的值为value
mapper
import java.io.IOException;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.util.StringUtils;
public class WordCountMapper extends Mapper<LongWritable, Text, Text, IntWritable>{
//该方法循环调用,从文件的split中读取每行调用一次,把该行所在的下标为key,该行的内容为value
protected void map(LongWritable key, Text value,
Context context)
throws IOException, InterruptedException {
String[] words = StringUtils.split(value.toString(), ' ');
for(String w :words){
context.write(new Text(w), new IntWritable(1));//对应图中的shuffling洗牌。
}
}
}
上面的context.write(new Text(w), new IntWritable(1));等价于
private Text t = new Text();
t.set(w); //set()是给t赋值的方法
context.write(t, new IntWritable(1));上面的new IntWritable(1)其实就相当于给一个变量赋值了,赋为1,只是少了个中间变量。
分割字符串比较经典的方法:
StringTokenizer itr = new StringTokenizer(value.toString());
while (itr.hasMoreTokens()) {
context.write(new Text(itr.nextToken()), one);// 输出<key,value>为<word,one>
}reducer
import java.io.IOException;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
public class WordCountReducer extends Reducer<Text, IntWritable, Text, IntWritable>{
//每组调用一次,这一组数据特点:key相同,value可能有多个,比如<"hello",{1,1,1,1}>中的1有多个。
protected void reduce(Text arg0, Iterable<IntWritable> arg1,
Context arg2)
throws IOException, InterruptedException {
int sum =0;
for(IntWritable i: arg1){
sum=sum+i.get();
}
arg2.write(arg0, new IntWritable(sum));
//在Hadoop中new IntWritable相当于java中Integer整型变量,为这个变量赋值为sum.
}
}
//结果对应上图的reducing的部分RunJob
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class RunJob {
public static void main(String[] args) {
//初始化的时候装载配置文件,会将classpath底下的路径和src下的hadoop的东西加载装载进来
Configuration config =new Configuration();
try {
FileSystem fs =FileSystem.get(config);
//Job时mapreduce的执行任务
Job job =Job.getInstance(config);
//设置Job的入口类
job.setJarByClass(RunJob.class);
//Job执行的时候给它一个名称,也可以不给(会有默认值)
job.setJobName("wc");
//Job执行的时候map的任务类是哪个类
job.setMapperClass(WordCountMapper.class);
job.setReducerClass(WordCountReducer.class);
//maptask输出键的类型(以单词为键所以用Text.class)
job.setMapOutputKeyClass(Text.class);
//maptask输出value的类型(以数值为值所以用IntWritable.class)
job.setMapOutputValueClass(IntWritable.class);
/*定义输入的数据的目录(在hdfs中的某一个文件),是运行程序的输出结果,提前建好usr和output就行,不用建wc,到时候会自动生成*/
FileInputFormat.addInputPath(job, new Path("/usr/input/"));
/*定义输出的数据的目录(在hdfs中的某一个文件),目录是在hdfs中txt文件所在的目录,在input文件夹下可以同时有好几个txt,下面路径只要写到input就行,会自动检测到底下的所有txt文件。*/
Path outpath =new Path("/usr/output/wc");
if(fs.exists(outpath)){
fs.delete(outpath, true);
}
FileOutputFormat.setOutputPath(job, outpath);
//等待任务执行(返回是否成功)
boolean f= job.waitForCompletion(true);
if(f){
System.out.println("job任务执行成功");
}
} catch (Exception e) {
e.printStackTrace();
}
}
}对于上面的LongWritable、IntWritable:除char类型以外,所有的原生类型都有对应的Writable类,并且通过get和set方法(或者new的方式)可以获取和设置它们。
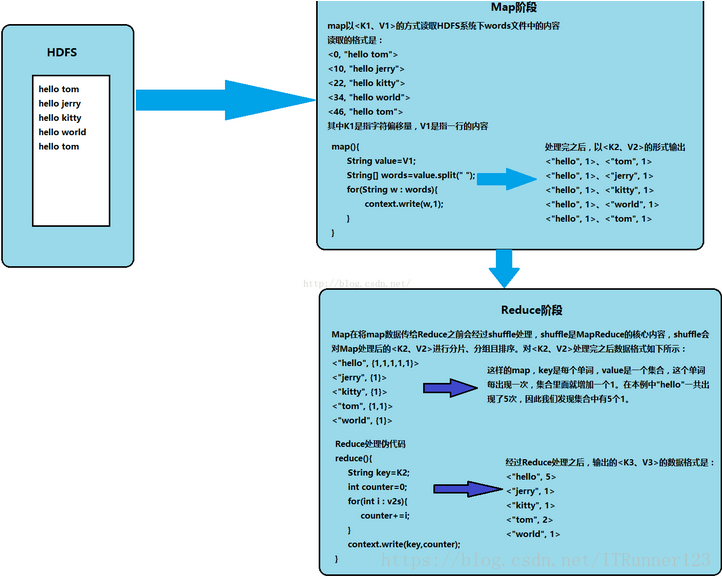
参考网址:https://blog.csdn.net/u012453843/article/details/52561533

总结:
1. mapreduce代码中的context指的是上下文,通过它可以传送数据。(在mapper中发送输出键值的内容,在reducer中接受键值的内容)
2.在定义类的时候,对于mapreducer类,需要定义四个泛型参数,分别是keyin,valuein,keyout,valueout,然后重写map方法,map方法只有三个参数,分别是键和对文本文件扫描的每行的值,还有上下文contex(上下文就是起到传递键值这两个参数的作用),在map方法中自己定义规则,定义好键和值的规则按照后两个参数(keyout,valueout)的类型通过context传递到reducer中。然后对于reducer类,也是定义四个泛型类参数,keyin,valuein,keyout,valueout,然后重写reduce方法,reduce里面有三个参数,第一个是键的值,其实就是从map传过来的键的值。然后就是Iterable”<”hadoop参数类型”>” arg1,这里的”hadoop类型”是根据reducer”<”keyin,valuein,keyout,valueout”>”中valueout决定的,因为一个相同的键可能多个不同的值,比如{“a”,<1,2,1,1>}中的a可能有多个值,所以用一个迭代器来存储多个值,可以通过foreach遍历的方法来取出值。最后就是上下文。另外可以在reducer方法中的arg.write(x1,x2)方法中设置特定格式的输出格式(默认的就是以键值的形式,中间用空格隔开),可以在write方法的参数x1或x2中传递一个stringbuffer对象,然后stringbuffer对象的appand的方法来设置具体的格式。
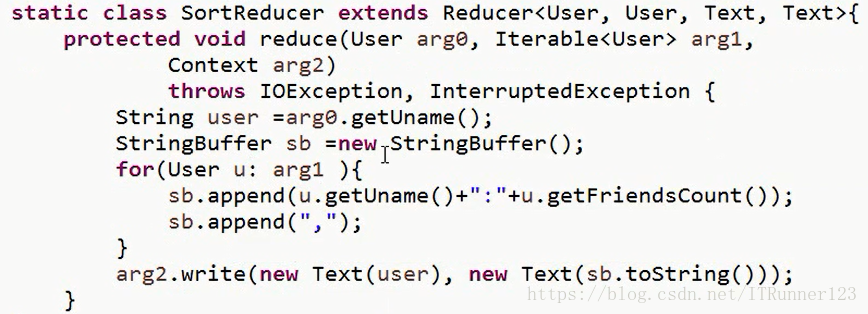
3. 在开发中为了方便的使用分布式文件系统,最好在eclipse中安装一个hdfs插件,详细参考博客:https://blog.csdn.net/ITRunner123/article/details/80906915














 3522
3522











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









