







本文为 「茶桁的 AI 秘籍 - BI 篇 第 36 篇」

Hi,你好。我是茶桁。
上一节课上利用 GCN 去完成了一个恶意软件的检测,同时为了做对比,还使用 LSTM 也完成了一遍。大家可以去我的代码仓库中去找到源代码,然后自己去跑一跑,最好是写一写。
我们在上两节课中主要讲的是图卷积神经网络这个工具,未来有机会有可能你会用到,不要忘记如何去转化成一张图。你所要做的事情就是把它看成一个图的模型,去用 CGN。因为从理论上以及实践上去看 GCN 都足够的强大,可以让你很好的去学习特征。
在模型预测里面有这么一句话:特征决定模型的上限,而模型只是把特征的上限跑出来而已。所以 GCN 能成为一个很有效的 Embedding 工具。而且上节课的项目中,咱们的网络层级也并不是很高,只有两层就达到了差不多 0.96 的一个效果。
在上节课中也预告了,这一节课,就一起来看看强化学习的内容。
其实去年强化学习也还很热,逐渐的多起来了。举个简单例子,在早期其实很多的比赛都是围绕数据挖掘的,也有一些做图像处理,自然语言的,但真正做强化学习其实并没有那么的多。
在 Google 收购了 Kaggle 之后,Kaggle 是最有名的社区,我们以它为风向标。在早些年 Kaggle 上的比赛基本上都属于数据挖掘类,还有一些图像和自然语言处理类。当 Google 收购了它以后,比赛风向标已经发生了一些变化,有越来越多的强化学习的比赛。
记得我在学习强化学习的时候,老师给我看了一个案例,我到 Kaggle 上找了一下,还在,只是奖金已经没了。记得当初这个比赛的奖金是 6000 美刀:https://www.kaggle.com/competitions/google-football/overview
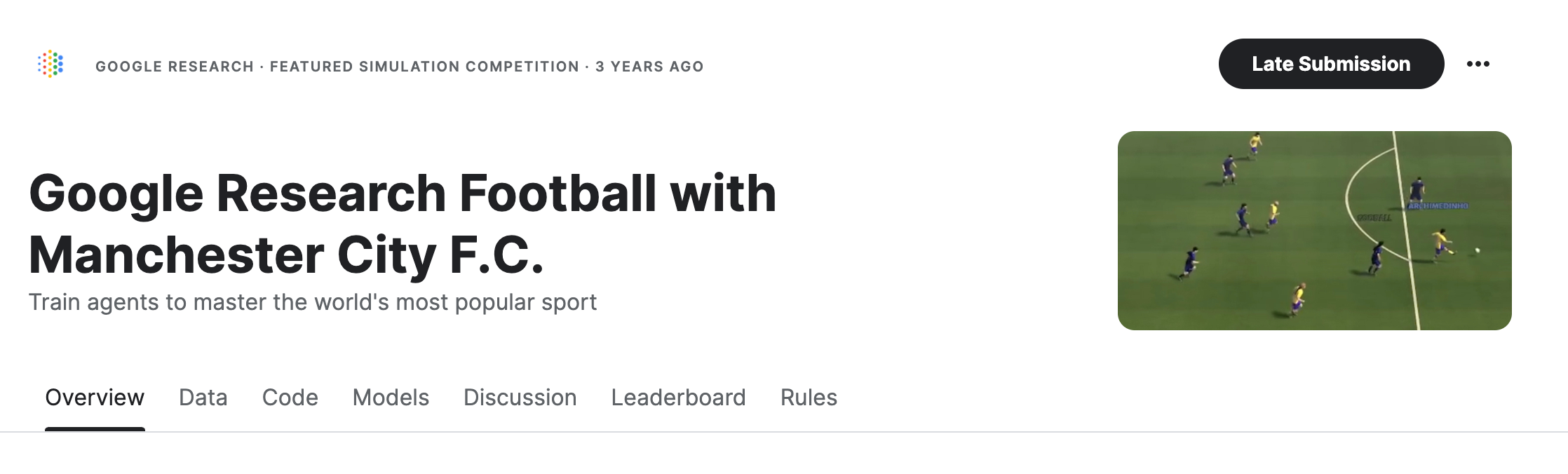
这个比赛就是 Google Research 和曼彻斯特城队去踢一场足球赛,让我们想想这个足球赛怎么踢。并不是人去教他怎么踢,而是要做一个仿真模拟的环境,提交的是你的算法,在模拟环境中去模拟跟机器之间的一些对应的情况。

强化学习实际上就是训练了一个智能体,让你的智能体跟游戏去做PK。这是一个足球赛的一个例子,为了计算方面并没有把它渲染成一个真正的足球队中的人,只是用数字作为一个代表。可以看到现在这个 B 就是那个足球,球是数字来去控制的,有蓝色和红色两队,射门成功得 1 分。
所以如何来进行 action,所有的 action 都在顶部先是,包括长串,铲球,射门等等。它有很多的 action 的方式,有点类似于像咱们 去玩实况足球,自己会回传,回传以后还能过顶长传。有兴趣的可以根据我提供的地址去看看,进入页面之后在 Leaderboard 这个标签内找到相应的比赛视频。
怎么去训练他?这个训练的机制就是用强化学习,在咱们整个课程中会去用两个例子来具体讲解一下。
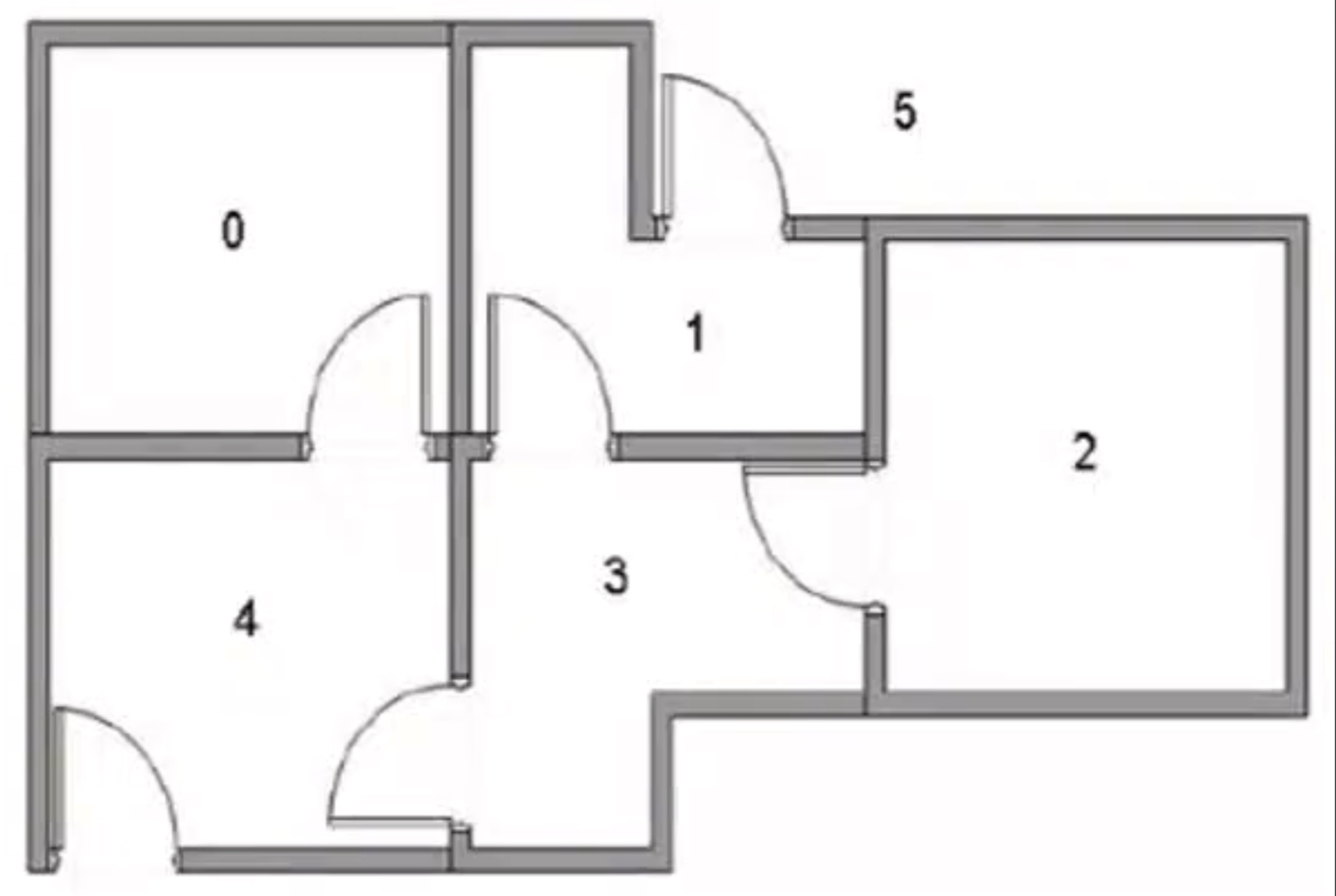
一个是迷宫的例子,迷宫有 5 个房间(实际上可以是 N 个房间),每个房间有些地方是通过门连通的,放到任意的地方怎么样走到出口。假设出口是 5,走到5就 OK。
AI有可能放到任何的地方,那你想怎么走这个路径。
还有一个,第二个例子是大家都有见过的一个小游戏,叫做 Flappy Bird。
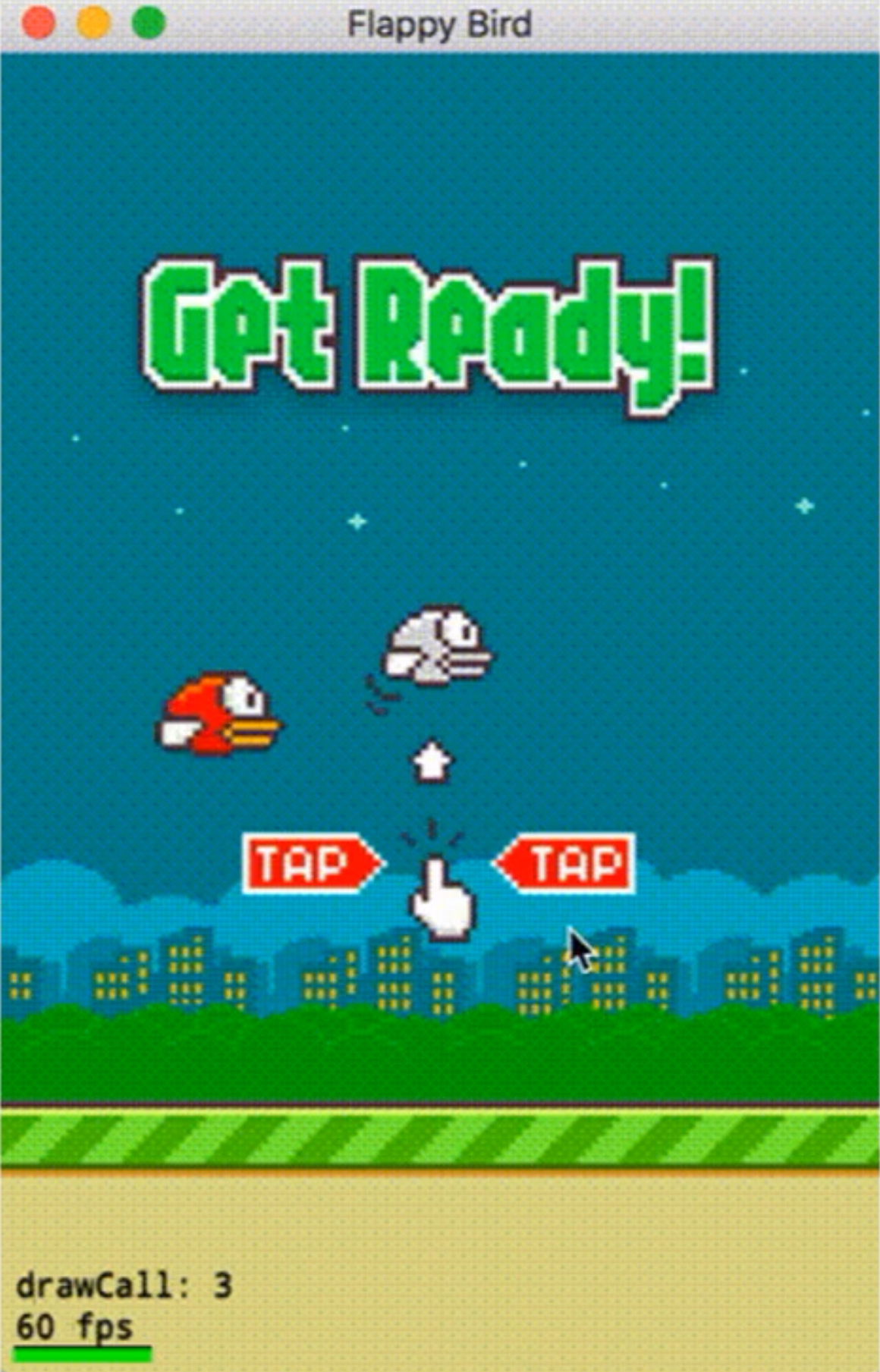
小鸟穿过更多的水管,穿过一个就加 1 分,撞到水管就 Game Over。如何去训练它得到更高的分数呢?
什么是强化学习
以上这些环境我们使用的方法通通都叫做强化学习,它是机器学习的一个重要的分支。除了强化学习,还有另外两种学习方式叫监督和无监督,这个应该大家都清楚。
强化学习是最自然的一种学习方式,思路和人比较类似,是在实践中学习。
给大家举个例子,已经有孩子的同学不知道有没有观察过自家孩子学走路的过程。宝宝怎么学走路的?宝宝学走路其实并不是你掰着他的脚趾头告诉他该怎么去走,他是一个自我学习的过程。在练习走路过程中有可能摔倒,摔倒了大脑就会收到一个信号,疼。那这个疼就会告诉你,你之前的 action 可能得到的结果并不是很好,这个反馈就是个负反馈。也有些情况下,前面有个妈妈,走着走着就走到妈妈的怀抱里面去了,这个反馈就是一个正反馈。
所以我们让他在一个环境中去练习走路,在走的过程中环境就会给一个反馈,告诉他这是好还是不好。这个是不是还是比较简单的一种判断逻辑?省去了你教他的方式,让他自己来进行探索。所以,这是一个最自然的一种学习方法。
那它跟监督学习之间有没有区别呢?监督学习实际上是需要人提前给出答案,已经准备好训练数据输出值。这个学习方式妈妈会特别累,因为宝宝走每一步你的那个 label 都不是机器打上的,是妈妈给你打上的,所以会比较累。强化学习就不需要,强项学习是事后给出奖励值。你让他走,走完以后好和不好再告诉你,这是一个明显区别。
第二,非监督学习之间有没有区别呢?非监督学习之间它是不太好评估好坏的,非监督学习中没有输出值也没有奖励值,只有数据特征。做强化学习毕竟还是有一个反馈的,这个反馈就是以正和负来做个奖励值。
监督和非监督之间样本都是相互独立的,没有连续性。而强化学习因为是一个事后反馈,所以你要去下棋,下完以后才会有个反馈,因此顺序也是有一个依赖关系的。
这三者之间就构成了机器学习的一个领域,强化学习也是个重要的分支。它用于很多的领域,除了计算机的学科还在神经学科、心理学科、工程领域、数学以及经济领域中都会有广泛的使用。甚至有人去研究脑科学也以强化学习为核心来做了一些研究。
总结一下强化学习的特点,第一个不是人去打上的标记,没有监督数据,替换成了奖励的信号。这个奖励不一定是实时的,可以是延后的,甚至可能延后很多。如果你要下围棋,什么时候有这个奖励呢?下棋过程中裁判告诉你下的好还是坏吗?肯定是要下完为止。一盘围棋的时间会非常非常的长,可能一个多小时都不止,所以这个奖励事后性延迟性还是很多的。既然有个时间消耗顺序,在我们的存储过程中它是一个持续的关系,当前的行为会对后续的行为会有一定的影响,这是强化学习的特点。
强化学习没有老师也没有 label,但是他有严实的反馈。以 AlphaGo 为例,我们再去思考一下,刚才我们说 AlphaGo 是采用强化学习来自我进行学习的,那我们再想一想,在最初设计 AlphaGo 的时候为什么不采用有监督的学习方法?有监督学习方式不需要等到他下完才给反馈信号,在学习之前就已经告诉你学习的方向应该是什么了,这样学习效率不是更高吗?那为什么设计人员并没有采用这种方式呢?
第一,AlphaGo 最终下棋的数量大约有 3,000 万盘棋,如果要做人工标记 3,000万 盘棋需要多少人力?非常非常多。
有一个著名的数据集 ImageNet,那个数据量级有 1,400 万,它是 1,400 万的两倍,而且它的标记还比这个数据集要复杂。因为 ImageNet 这个图像你把它框出来就好了,但是每一盘棋它的标记的方式真的很复杂,很多情况下没有最佳棋步,因为一个棋步的好坏依赖于其后的多个棋步。所以我们需要的人力物力都很多,这是一点。
第二点,如果假设 3,000 万盘棋能找到人做标记,那这种学习的智能体能打败人类吗?实际上是人类教给机器目标方向应该往哪个方向去学,所以它怎么样也很难打败人类,人类就成为了它的上限。
所以,强化学习是可以突破人类的上限。因为机器有了自我学习的一种方法,这种自我学习的方法有可能是人类之前没有探索过的。
以当时的下棋场景为例,李世石在跟 AlphaGo 下棋过程中就反馈,AlphaGo 下了一些他之前没有见过的棋,而且这个棋还很高深。这也就证明其实并不是人类去教给 AI 该怎么去下棋。
所以设计师也很清楚,不论是从时间、金钱的成本,还是从最后学习的效果,他的技术选型都是强化学习。
但是强化学习也有它的局限性,就是时间会非常的长。那强化学习怎么去做?这里就需要有些基本的概念了,我们先看一看这些概念:
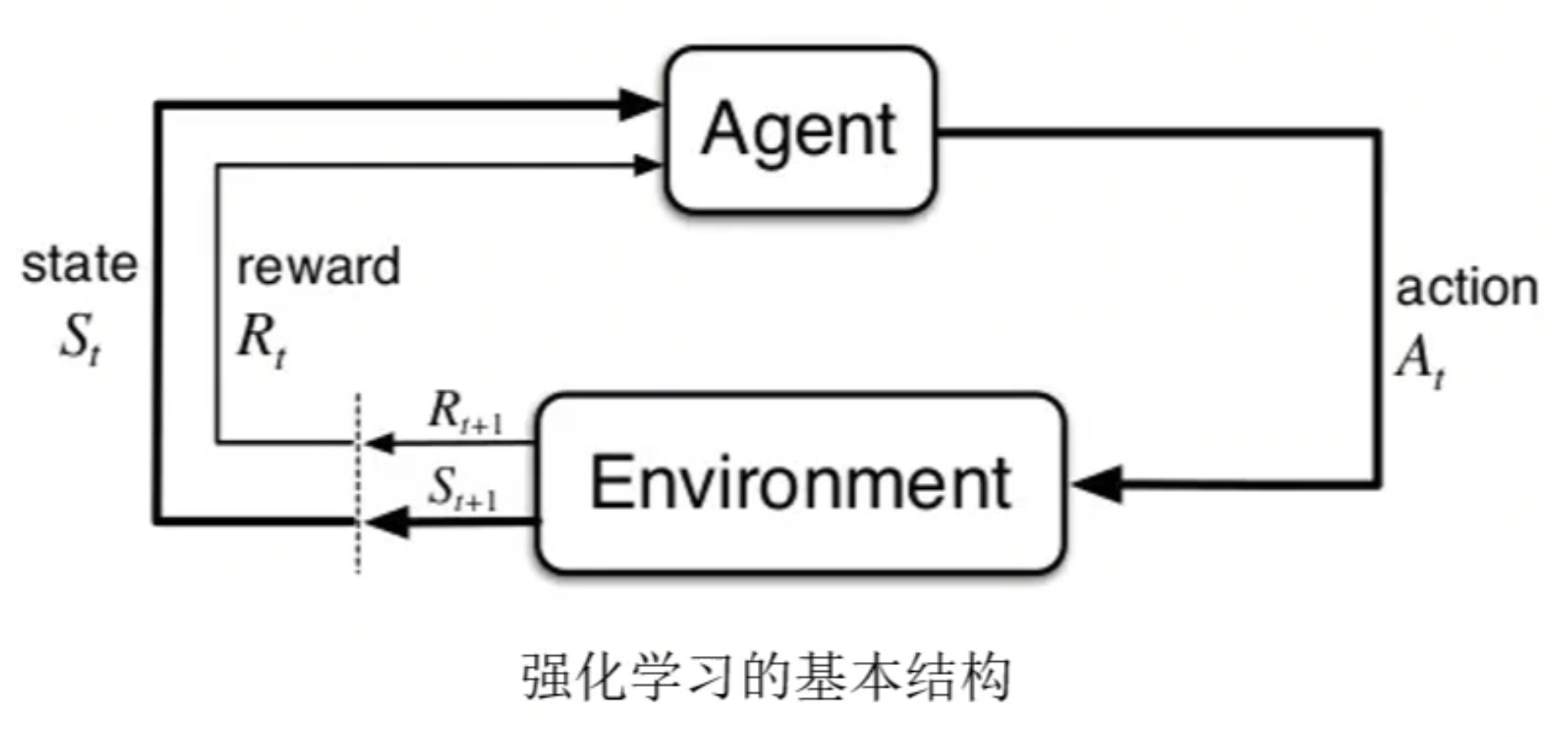
- 个体, Agent, 学习器的角色,也称为智能体
- 环境, Environment, Agent 之外一切组成的、预支交互的事物
- 动作,Action,Agent 的行为
- 状态,State,Agent 从环境获取的信息
- 奖励,Reward,环境对于动作的反馈
- 策略,Policy,Agent 根据状态进行下一步动作的函数
- 状态转移概率,Agent 做出动作后进入下一步状态的概率
第一个概念叫智能体,我们要去训练小 baby 学走路,这个 baby 就是智能体。环境就是妈妈,妈妈会告诉你到底是好还是不好。所以环境跟智能体之间是一种交互关系。智能体希望得到环境的赏识,智能体会有各种各样的一些 action,一些操作,妈妈也会给它返回一些奖励。同时我们也会帮助这个智能体去记录当下的一些状态。以及智能体也会有一些动作,就是一些策略来去完成。
可以看到,在想要学习过程中概念还是非常多的。大体上可能会有 8 个左右的概念,包括转移状态、转移矩阵等等。这么多记不下来怎么办?你可以稍微筛选一下,至少有四个概念是非常核心的,这四个重要的要素就是状态(State)、动作(Action)、策略(Policy)以及奖励(Reward)。
状态就是记录你现在到哪一个位置,有点类似于像一个史记官,他把你整个的行程都给你记录下来,从第一秒到第二秒到第三秒。因为下棋就是一个时间序列的过程,所以他按照时间的顺序把状态做了一个记录。此外还有一些,下棋可以采用的动作和策略以及我们可以知道它的一个 reward。
这四个基本上是属于强化学习里面最重要的一些概念。这四个概念那些是来自于智能体,哪些是来自环境呢?
首先环境的任务是发奖励,智能体不可能自己给自己奖励。另外环境也像一个史记官一样帮你完成了记录的过程,它告诉你现在所处的位置到底在哪里。想象一下我们去玩红色警戒,游戏环境告诉你现在所处的位置。所以 Environment 记录了我们的 state 和 reward。
那智能体就是剩下的两个部分,智能体可以按上下左右来做 action,智能体也可以采用一些 policy 的策略。那 policy 和 action 之间有什么区别呢?都是智能体的一些操作,为什么还会叫做 policy?
其实这里的 policy 不是一种确定的 action,action 上下左右是一种确定的,policy 是一种随机的,给他几种方向1、2、3,采用哪一种实际上是可以随机出来的,这是他的 policy。
强化学习考虑的就是智能体、环境之间的一个交互。目标就是找到一个最优策略,是的智能体活的尽可能多的来自环境的奖励。学习肯定要确定方向,所以方向就是获得奖励越多越好。
举个场景,以赛车为例,训练一个智能体去驾驶赛车,那赛车的奖励就是如何去得到更高的一个分数。各种各样的动作,只要最后能得到更好的分数就证明你开的好。但有些情况下,智能体其实并不能知道全部的环境,因为全部环境是需要你自己探测出来。就像我们去玩星际争霸,走到先告诉你,但是去到那里才能看到那边的景象。环境是基于你现在所处的状态会告诉你当下的一个状态。所以这个是需要通过环境的观察来得到一个反馈,只能看到你身边周围的一个信息。
我们现在再来明确一下中间一些具体的变量,第一个 Reward。
R t R_t Rt 是信号的反馈,下标 t 是 time 的一个缩写,Reward 本身就是反映在哪一个时刻给你奖励,本身是一个标量,反映智能体在 t 时刻做的怎么样,智能体的工作就是最大化累计奖励。
R t R_t Rt 很关键,因为所有学习的本质就是想要得到更多的奖励,然后让机器来做决策。我们可以把它看成是一个序列 Sequence。所以这个奖励实际上是在时间的累积上面得到最大化。
为什么要加上这样一个数据列呢?比如我当下给你两种选择,第一是现在如果你需要的话就给你5块钱,第二个是一周之后给你10块钱。请问如果是你的话会选择哪一个?两种 reward 的情况,马上给你5块钱还是现在不给你,一周之后给你10块钱。张一鸣就会喜欢后面的那种延迟满足,因为延迟满足是整体的一个最优解。
所以在做强化学习的过程中,其实并不是看当下的一个收益,或者说近期的收益,而是要把它看成一个终极的状态。在终极状态中你能得到多少收益,这是一个目标的优化。这就是第二个具体的变量,序列决策(Sequential Decision Making)。
智能体有时候也会牺牲短期的收益来获取长期的一个利益。举个例子,有的时候下围棋就是需要有这样一些智慧,让对方可以多赢几个子,但是这只是短期的,我们却获得了长期的一个更大的一个奖励。
个体和环境之间是怎么交互的呢?
我们先看个体的视角: 在第 t 个时刻,我们的个体是可以收到环境的观察结果 Q t Q_t Qt 的,同时还可以基于观察的状态做出一种行为 A t A_t At,这里的 A 就是 action,t 是时间。个体做出一个 A t A_t At,环境就会给你一个反馈,得到一个奖励信号 R t + 1 R_{t+1} Rt+1,它是在下一个时刻如果有反馈会给你一个结果。
换个角度来看看环境,环境本身接收的是个体的动作 A t A_t At。接收完成以后就可以更新环境信息,同时把状态返回给个体,个体得到了下一个观测 Q t + 1 Q_{t+1} Qt+1,同时会给个体当下的一个反馈的奖励信号 R t + 1 R_{t+1} Rt+1
从上面可以看到,个体和环境之间是在一个不断交互的状态里面。个体就在做一些行为,而环境会给他一些反馈。
以上都是一些概念性的内容,下面用一个例子一起来写一写,算一下。
迷宫问题
咱们就拿刚才说迷宫问题为例
上图是一个迷宫,在这个迷宫中如何让机器自我进行学习呢?介绍一种方法:Q-Learning,也把它称为Q函数。
Q 函数也称为动作值函数,有两个输入:「状态 」和「动作」,它将返回在这个状态下执行该动作的未来奖励期望。
人就需要给它做一个状态的定义,输入的这样一个状态,想让机器采用一种行为,通过奖励矩阵的方式来告诉他该采用怎样的一个动作。
对于机器来说,目标就是终极状态的奖励。或者换个角度,如果我已经可以把终极状态的奖励做了一个贴现,「贴现」就是你未来能得到100块钱,现在可以得到比如说50块钱。这样一种贴现的操作我们就可以知道该采用怎样的方法会更合理一点。
来一起看看这个情况是怎么做的。将 Agent 随机放在人一房间内,每打开一个房门返回一个 reward,根据房间之间连通性的关系,可以得到 Reward 矩阵,也就是一个 R 矩阵。
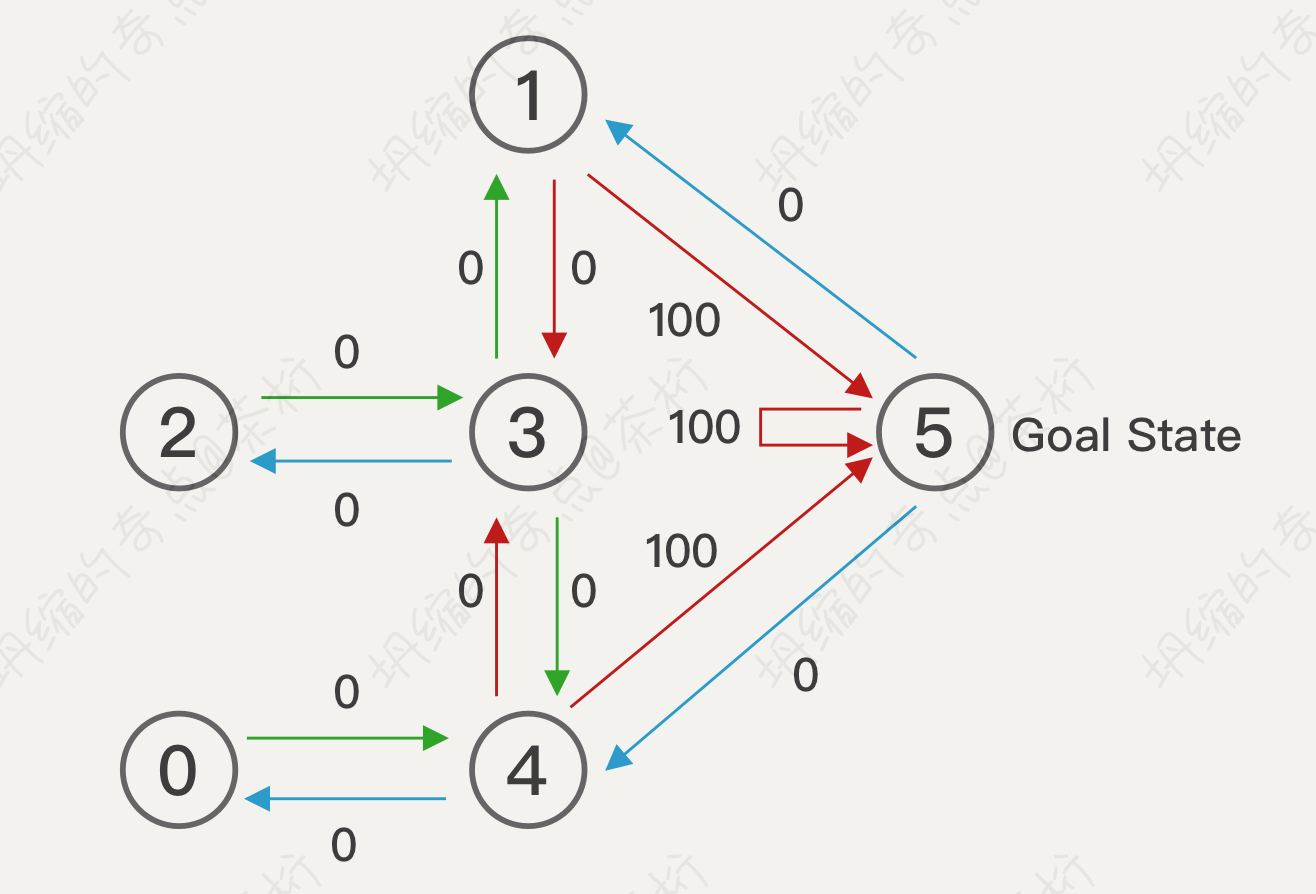
因为奖励是一个持续的关系,我们现在不能一一的定义它每一个时刻的奖励,但是可以知道它最终的奖励。什么是最终的奖励,最终奖励就是我们如何走到 5 这个位置,1 到 5 就可以吧?如果现在状态在 1,直接会给你一个 action,等于100分,1 到 5 的就是100分。还有哪个地方?4 到 5 也是 100分,5 到 5 也是100分。这个就是最终奖励的状态。
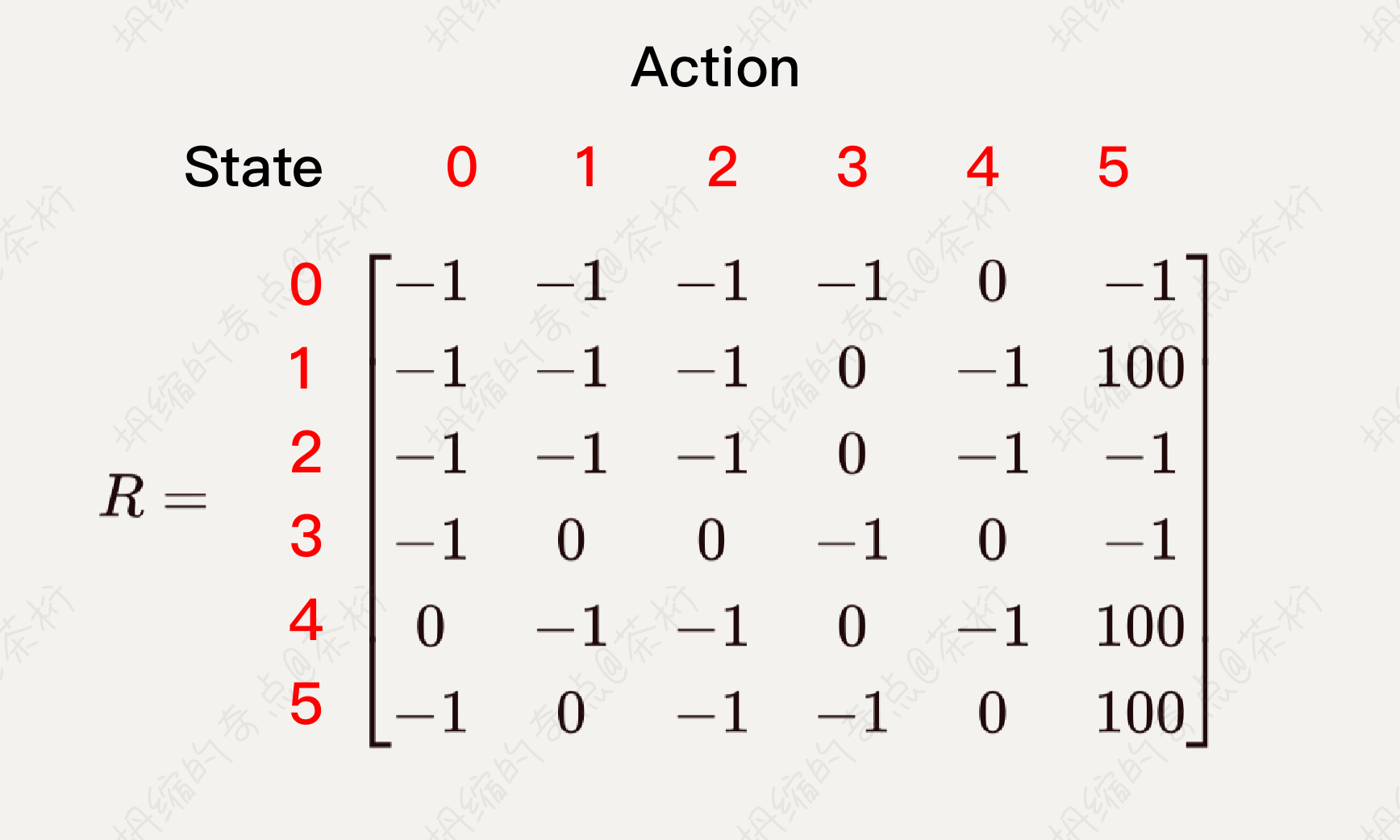
最开始的时候我们就直接把这个状态给它标记出来,中间 -1 代表不能走, Reward 等于负数,所以会禁止你走。为什么禁止走,因为它没有门。0 到 0 是不允许停留的,0 到 1 走不了,如果两者之间没有门用 -1,有门用 0。0 是现在目前可以通达的一个状态。
这个 R 矩阵可以把它当成一个初始化的矩阵,也就是说我们在某些点上面拿它做个初始化,要做计算的时候,需要给它附一个 reward,后面就会基于这个 reward 去指导你采用怎样的 action。在最早期我们需要把这个 reward 给构建出来。
那 Q-Learning 要怎么去学呢?Q-Learning 是典型的基于价值(Value)函数的强化学习方法。因为 Q-Learning 不是直接到终极的状态,实际上是一个序列的关系,通过每一次的演化才能到,所以我们需要给它构造一个转换的函数来进行迭代。
其中 Q 是一个数值(即价值 value),在初始化时可能被赋予一个任意数值。
在迭代时刻 t,我们有状态
S
t
S_t
St 此时代理做出动作
a
t
a_t
at,然后得到奖励
r
t
r_t
rt,从而进入到一个更新的状态
S
t
+
1
S_{t+1}
St+1,然后对 Q 值进行更新:
Q
(
s
t
,
a
t
)
←
(
1
−
α
)
⋅
Q
(
s
t
,
a
t
)
⏟
o
l
d
v
a
l
u
e
+
α
⏟
l
e
a
r
n
i
n
g
r
a
t
e
⋅
[
r
t
⏟
r
e
w
a
r
d
+
γ
⏟
d
i
s
c
o
u
n
t
f
a
c
t
o
r
⋅
m
a
x
a
Q
(
s
t
+
1
,
a
)
⏟
e
s
t
i
m
a
t
e
o
f
o
p
t
i
m
a
l
f
u
t
u
r
e
v
a
l
u
e
]
⏞
l
e
a
r
n
e
d
v
a
l
u
e
\begin{align*} Q(s_t, a_t) \gets (1-\alpha) \cdot \underbrace{Q(s_t, a_t)}_{old \ value}+\underbrace{\alpha}_{learning\ rate}\cdot \overbrace{\begin{bmatrix} \underbrace{r_t}_{reward} + \underbrace{\gamma}_{discount\ factor} \cdot \underbrace{max_{a}Q(s_{t+1}, a)}_{estimate\ of\ optimal\ future\ value} \end{bmatrix}}^{learned\ value} \end{align*}
Q(st,at)←(1−α)⋅old value
Q(st,at)+learning rate
α⋅[reward
rt+discount factor
γ⋅estimate of optimal future value
maxaQ(st+1,a)]
learned value
状态做出来这个动作会得到一个奖励,同时会进入到下一个状态。
首先, Q ( s t , a t ) Q(s_t, a_t) Q(st,at) 是属于原来状态的一个分数,然后下一时刻的状态是 m a x a Q ( s t + 1 , a ) max_a Q(s_{t+1}, a) maxaQ(st+1,a),这是等于预估的最好的一个值。如果你下一时刻可以达到最好的值的话属于你的目标的期望最大值。把最大的值乘上了一个 gamma,gamma 称为「贴现因子」。也就说我们并不能直接吃到这块糖,假设一周之后是 100,可能前面一天就90、80、70、60,所以在前面时间越长损失越大。如果你现在想要吃到这块糖,现在吃的就很少,但如果存到后面实际上这个奖励就会更多一点。所以先用贴现因子可以把未来的算到当下做一个折现。
乘上贴现因子再加上一个 r t r_t rt,就代表我们可以学到一个内容。因为现在如果你要走到这个位置上面来,我们实际上要学习它可以达到一个结果是怎样的。 Q ( s t , a t ) Q(s_t, a_t) Q(st,at) 是一个现在的值,matrix 内的的那一串 r t + γ ⋅ m a x a Q ( s t + 1 , a ) r_t + \gamma \cdot max_{a}Q(s_{t+1}, a) rt+γ⋅maxaQ(st+1,a) 是他未来的目标值,我们可以把目标值往前走一步, α \alpha α 就是沿着目标的方向走一步。
假设极端一点,Learning Rate 等于 1,也就是 α = 1 \alpha = 1 α=1,因为 1-1 = 0,那么前面 ( 1 − α ) = 0 (1 - \alpha) = 0 (1−α)=0,所以原来状态的值其实就等于是没有了,就把每个状态都等于后面的状态,就等于你目标的一个最大值。这个是一个极端的情况。
那么更合理的情况,会给他设一个 Learning Rate,这样每次迭代的时候并不是一个一次达成的迭代状态,会在原有的基础上逐渐的去进行学习。
再举个例子大家体验一下,为什么我们会用一个贴现因子。IPO 是一个公司终极的目标,很多时候是奔着上市去的,这个上市把它称为叫 IPO,终极状态。如果你的市场估值很高,终极状态假设 100 亿美金,那在早期还有几个时刻点,有天使轮、a 轮、b 轮、c 轮、d 轮,最后是 IPO。
哪一轮估值是最低的呢?投资人最关心的是上市的时候空间多大,会经常说到一个问题:你市场空间太小,不感兴趣。因为你要贴现到现在,目前为止这个价值就看不到了。实际上应该是天使轮,天使轮的估值可能只有 2,000万,而 a 轮有可能是 1 个亿,b 轮有可能就是 5 个亿,后面可能 20 个亿、50 个亿。
那这个估值一轮一轮会越来越大,会放大到 IPO,到一个终极的状态。投资人怎么去对你的天使轮去做一个估值呢?就是假设你终极是多少,前面还需要几轮,每一轮的贴现是多少,这样就会把天使轮的目标状态
给它求出来。
天使轮是来自于 a 轮,a 轮又是依来于 b 轮,b 轮是来自于 c 轮,c 轮来自于 d, d 又来自于 IPO。所以现在只需要管理下一轮就好了,这是一个迭代的过程。那下一轮的贴现乘上它,再加上你当下时刻的一个奖励,就等于整个的一个公式的更新。
所以 Q-table 实际上是一个 Q 函数,这个 Q 函数的意义是标明指导你该采用怎样的决策,或者说可以给你一个千里眼,把未来折现到现在,对现在作出指导。这种折现的方式会更新你的 Q 值。
接着来举例,以原来的这个 Q 值为例。
只要到了 1 这个位置,很明确走 5 就好了,因为 100 已经把方向告诉你了。只不过这个是个初始化的过程,所以在不断的更新、不断的更新,让他去迭代,迭代到你前一步,再迭代到你再前一步等等。这样就可以把一张 Q-table 学出来,就可以指导你的前进。
那怎么去做呢?我们来一起看看:初始化 Q 表,用于记录状态-动作对的值,每个 episode 中的每一步都会根据公式更新一次 Q 表。
Q
(
S
t
,
A
t
)
←
Q
(
S
t
,
A
t
)
+
α
⋅
[
R
t
+
1
+
γ
⋅
m
a
x
a
Q
(
s
t
+
1
,
a
)
−
Q
(
S
t
,
A
)
]
\begin{align*} Q(S_t, A_t) \gets Q(S_t, A_t) + \alpha \cdot \begin{bmatrix} R_{t+1} + \gamma \cdot max_{a}Q(s_{t+1}, a) - Q(S_t, A) \end{bmatrix} \end{align*}
Q(St,At)←Q(St,At)+α⋅[Rt+1+γ⋅maxaQ(st+1,a)−Q(St,A)]
原来的 Q 值加上学到的内容,沿着学习的方向去学了一个
α
\alpha
α,这里的
α
\alpha
α 称之为学习率。稍微极端一点,把这个学习率设为最大值 1,就可以把这个
Q
(
S
t
,
A
)
Q(S_t, A)
Q(St,A) 消掉了,那公式就可以更新为:
Q
(
S
t
,
A
)
←
R
t
+
1
+
γ
m
a
x
a
Q
(
S
t
+
1
,
a
)
\begin{align*} Q(S_t, A) \gets R_{t+1} + \gamma max_a Q(S_{t+1}, a) \end{align*}
Q(St,A)←Rt+1+γmaxaQ(St+1,a)
所以我们学到的这个内容可以理解成是未来下一步的最大值,里面加一个贴现,再加上当前的 reward。这就是 Q 值计算的方法,强化学习的 Q-Learning。应该相对来说还比较好理解。方式就直接把价值算出来,把终局 IPO 的情况不断的贴现到你眼前,即使你是天使轮我也可以知道这个价值是多少。
现在可以想一下,我们如何去解决迷宫问题。
首先先设置参数,贴现因子是一个常参数,Q以及初始化的 reward 矩阵:
# 模拟迷宫问题
GAMMA = 0.8
Q = np.zeros((6, 6))
R = np.asarray([[-1, -1, -1, -1, 0, -1],
[-1, -1, -1, 0, -1, 100],
[-1, -1, -1, 0, -1, -1],
[-1, 0, 0, -1, 0, -1],
[0, -1, -1, 0, -1, 100],
[-1, 0, -1, -1, 0, 100]])
假设最终达到出口为100,这是设置的值。每一次要进行操作,要取他下一步的最大值,期望里面有这个值。那怎么取呢?就是用 Max 来取一个最大就可以了。
# 取每一行的最大值
def getMaxQ(state):
# 通过选取最大动作值来进行最优策略学习
return max(Q[state, :])
我们来看一看整个的计算流程,Q-Learning 现在是有 6 种 action:
# Q-Learning 函数
def QLearning(state):
# 选择的动作
curAction = None
# 遍历所有节点,查看是否可以移动下一步
for action in range(6):
# 如果不能走,价值函数为 0
if(R[state][action] == -1):
Q[state, action] = 0
# 可以走,记录 curAction, 并且等于 curAction 最大值的贴现 + 当前的反馈
else:
curAction = action
# 选择动作最大的,假设学习率为1
# 环境给当下的奖励 + 未来最大收益的贴现
Q[state, action] = R[state][action] + GAMMA * getMaxQ(curAction)
0-5,数一数,0 到 5 是有 6 个。需要做一个遍历,每一次要去看一看下一次从当前的位置走到 0,走到1,走到 2、3、4、5 能不能走,如果它等于 -1,说明当前这个状态要找到下一个 action 就走不了。走不了下一时刻的奖励应该就为0。
否则就可以走,我们需要对这个过程 state 到 action 的奖励做一个更新。所以我们采用了当下的 action,然后在当下 action 里面去求一个最大值,这是学习率为 1 的情况,因为我们采用的是这样一个公式:
Q
(
S
t
,
A
)
←
R
t
+
1
+
γ
m
a
x
a
Q
(
S
t
+
1
,
a
)
\begin{align*} Q(S_t, A) \gets R_{t+1} + \gamma max_a Q(S_{t+1}, a) \end{align*}
Q(St,A)←Rt+1+γmaxaQ(St+1,a)
这个公式之前咱们讲了,就是假设学习率为 1 的时候变化而来的。
最终咱们一共模拟了 1,000 次,每次都计算这个过程,最终把结果打印出来:
# 模拟100次
for count in range(1000):
# 遍历
for i in range(6):
QLearning(i)
# 显示保留小数点后一位
np.set_printoptions(precision = 1)
print(Q/5)
---
[[ 0. 0. 0. 0. 80. 0. ]
[ 0. 0. 0. 64. 0. 100. ]
[ 0. 0. 0. 64. 0. 0. ]
[ 0. 80. 51.2 0. 80. 0. ]
[ 64. 0. 0. 64. 0. 100. ]
[ 0. 80. 0. 0. 80. 100. ]]
可以看一下最后计算出来的结果,这个计算的结果相当于不断的迭代。不断迭代就可以把当下决策的这个奖励给计算出来。
那这个最终结果怎么去指导我们的动作?我们来看最后学出来的 Q-table:
0
1
2
3
4
5
[
0
0
0
0
80
0
0
0
0
64
0
100
0
0
0
64
0
0
0
80
51
0
80
0
64
0
0
64
0
100
0
80
0
0
80
100
]
\begin{align*} \begin{matrix} 0 \\ 1 \\ 2 \\ 3 \\ 4 \\ 5 \end{matrix} \begin{bmatrix} 0 & 0 & 0 & 0 & 80 & 0 \\ 0 & 0 & 0 & 64 & 0 & 100 \\ 0 & 0 & 0 & 64 & 0 & 0 \\ 0 & 80 & 51 & 0 & 80 & 0 \\ 64 & 0 & 0 & 64 & 0 & 100 \\ 0 & 80 & 0 & 0 & 80 & 100 \end{bmatrix} \end{align*}
012345
0000640000800800005100064640640800080080010000100100
假设现在是在 2 这个位置,按照 Q-table,下一步会走到哪里去?通过下面这张图应该会很明显:
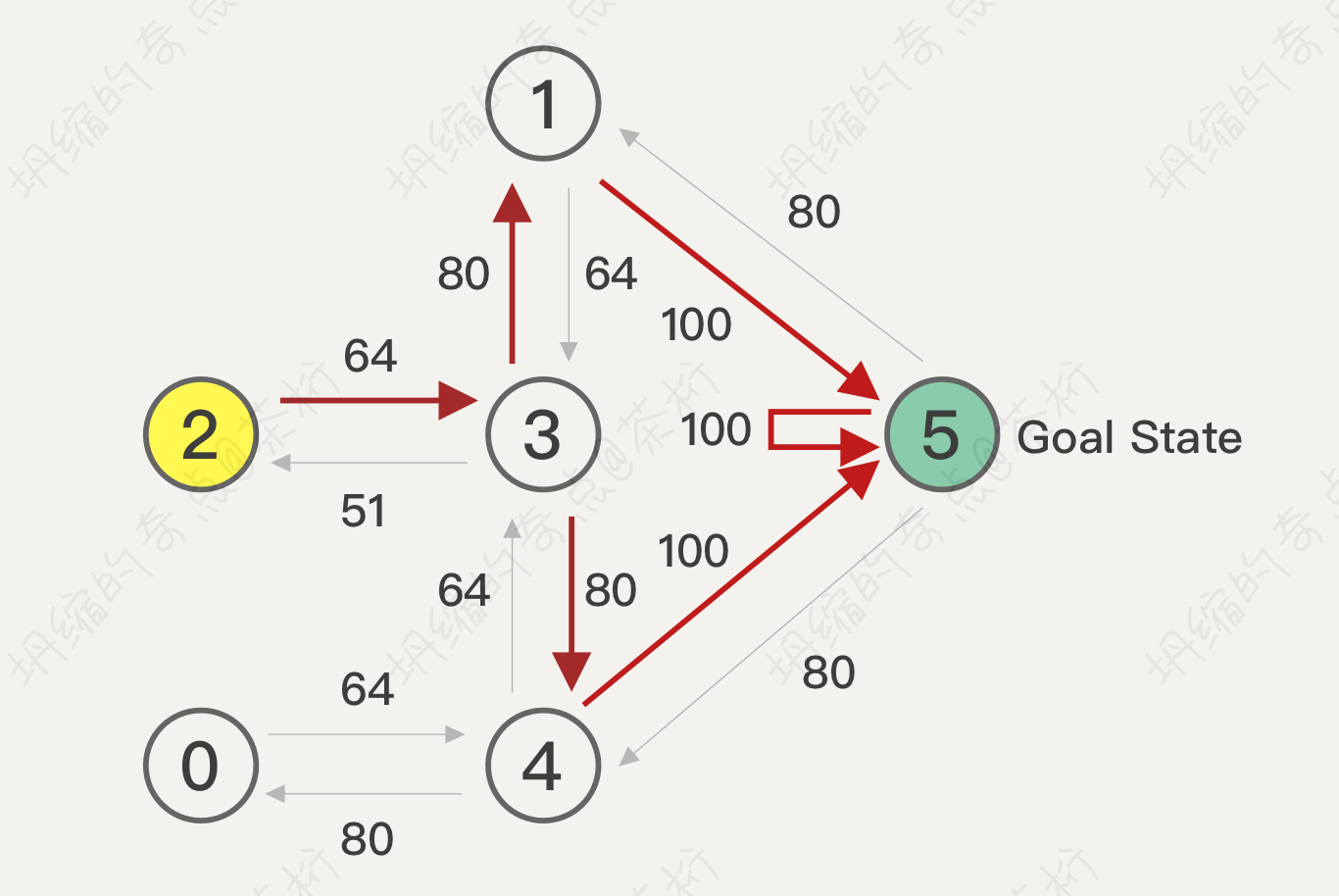
因为这个值已经学好了,学好其实就已经看得比较长远了。那么现在就不能说我是一个短视的情况,我已经把终局的状态都完全迭代到当下的这个情况里面去了,是应该走到哪里去呢?2 这里应该就走到 3,因为 64 是最大的。走到 3 之后在 3 这个位置上做 action 应该走到哪里去呢?走到 1 和 4,应该选哪一个?它现在不是一个最大值,有多个最大值,如果遇到多个最大值的话实际上是做一个随机数的选择。我们来看结果,如果是走到 1 下一步就是 100, 走到 4 呢下一步也是 100,所以路径的决策都是一样的,只要选一个随机数就可以了。
以上的流程就给大家看完了,我们的 Q-table 如何指导运算的,Q-table 指导运算使用起来还是很方便的,因为价值已经都帮你计算好了。难点是如何去模拟,模拟就是如何去把后面的结果倒推回来,揉到现在的状态里面去,从而影响你当前的状态。所以很多时候创业时去倒推的情况,先去看 IPO 的估值,再去看你当下的状态来决定采用怎样的动作,价值最大化。
整个流程大体上梳理一下,第一个 reward 状态应该可以求解出来。模拟的本质是把未来贴到现在,假设第1,000步,总会有 999 步跟 1,000 步之间的一个关系,会给他贴现过来。所以通过不断的贴现,也就说这个 Q-table 不断的更新。更新以后,最终如果达到了稳定的状态,就认为这个 Q-table 可以指导我们现在的决策。
总结一下,我们的 Q-table 实际上是这样的,一个(s, a) a 对应一个 Q 值,可以把 Q 值看作一个很大的表格,这个表格横列代表 s, 纵列代表 a,数值为 Q 值。
| a1 | a2 | a3 | a4 | |
|---|---|---|---|---|
| s1 | Q(1, 1) | Q(1, 2) | Q(1, 3) | Q(1, 4) |
| s2 | Q(2, 1) | Q(2, 2) | Q(2, 3) | Q(2, 4) |
| s3 | Q(3, 1) | Q(3, 2) | Q(3, 3) | Q(3, 4) |
| s4 | Q(4,1) | Q(4, 2) | Q(4, 3) | Q(4, 4) |
给了 state 和所有可以采取的 action,计算好一个数值评估这个state,采取这种 action 的价值是多少。那在一个稍微复杂一点的游戏中,我们的 state 和 action 这样的表格就非常大。刚才那个迷宫本身不是很复杂,如果把它换成其他的,我们可以采用的状态的种类会很多,之前那个状态只要在哪个屋子里就好了。
应对非常复杂的情况,像下棋这种就很难,应用不了了。下棋这种情况下我们可能还有其他的技术,不一定是 Q-Learning,那 Q-Learning 可以方便大家先去入门强化学习,有些情况下比较明确的决策可以用 Q-Learning。
因为下棋存在不确定性,而走迷宫实际上是一个相对比较确定的一个内容。如果是一个相对确定的内容用 Q-Learning 会更好一点。
本节课也只是用一个简单例子先体验一下它的流程,整个的原理也都是一样的。
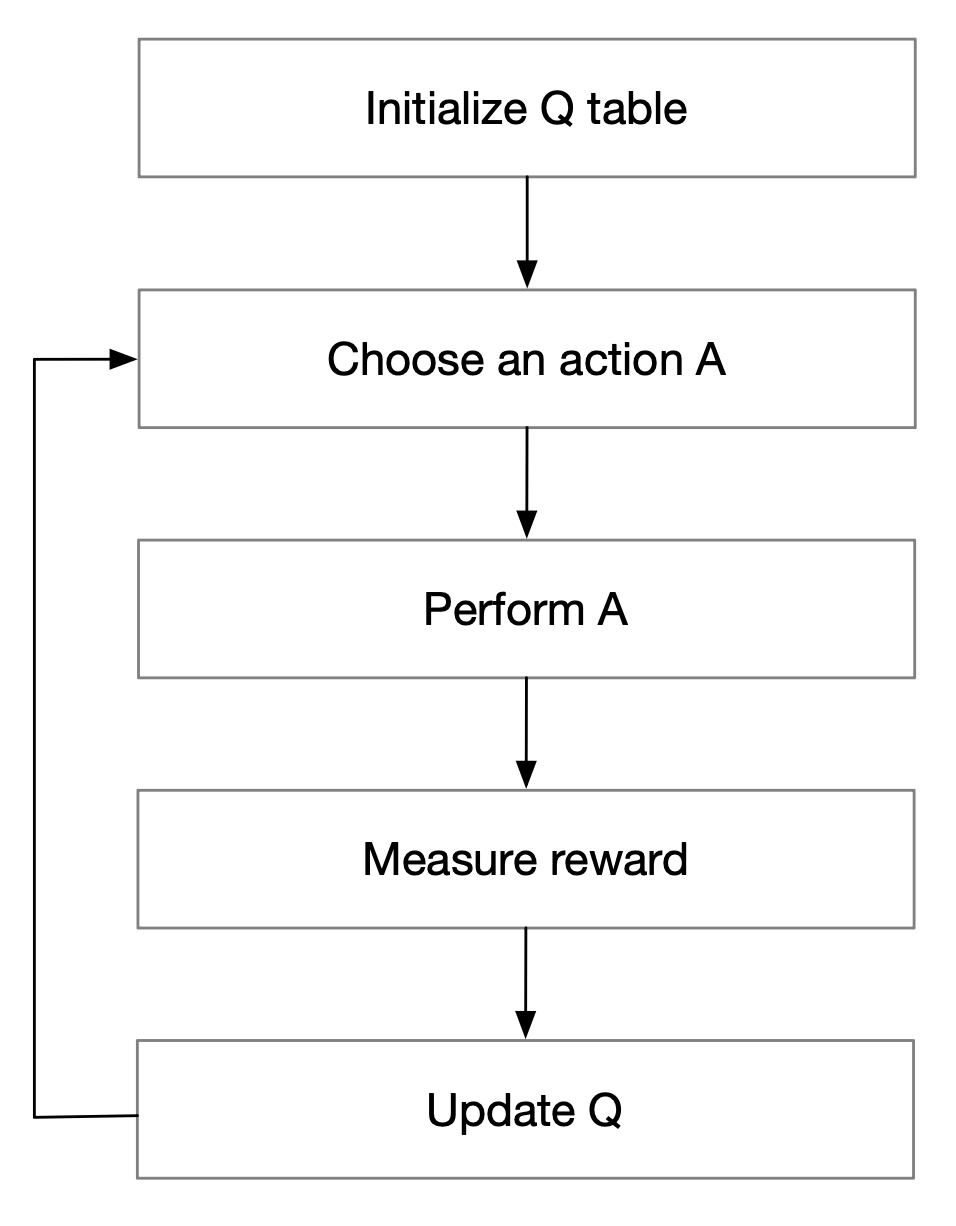
初始化 Q-table,选取一个 A 去执行它,去衡量我们的奖励,然后再去更新它。不断的选取,不断的去更新,让我们的状态 Q 学的更精准一点。
好,那下一节课中,咱们回来看一个更为复杂一点的例子,就是 Flappy Bird 这个游戏,看看这个游戏中该如何去学习、
















 5584
5584

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











