







继续这个Lucene总结系列吧。今天要讲的是一个Lucene的业务全程操作,然后这系列的以后都是以Lucene优化以及原理为主了。OK,开始!!!
本系列:
(1)SSM框架构建积分系统和基本商品检索系统(Spring+SpringMVC+MyBatis+Lucene+Redis+MAVEN)(1)框架整合构建
(2)SSM框架构建积分系统和基本商品检索系统(Spring+SpringMVC+MyBatis+Lucene+Redis+MAVEN)(2)建立商品数据库和Lucene的搭建
(3)Redis系列(一)–安装、helloworld以及读懂配置文件
(4) Redis系列(二)–缓存设计(整表缓存以及排行榜缓存方案实现)
(5) Lucene总结系列(一)–认识、helloworld以及基本的api操作。
文章结构:(1)业务说明以及技术说明;(2)业务实现(配合SynonymFilterFactory实现高精度地切割检索);
一、业务说明以及技术说明:
以下是我们要实现的效果喔!

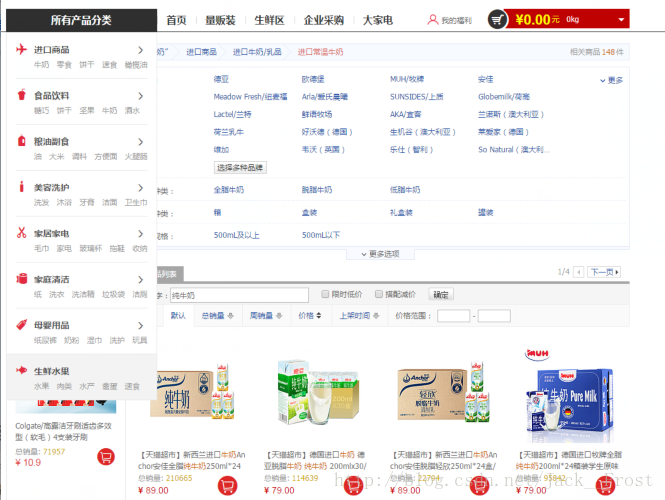
(1)业务说明:文字检索商品
流程:
1. 我们预先建立商品的索引库在服务器。(根据商品的类别以及商品表的id和名字建立索引)
2. 文字检索商品,先往索引库去查询索引信息。比如:商品id、名字、价格…
3. 查询出一个list装载着商品索引信息后就根据索引到的id往数据库查询商品详细信息。
(2)技术说明:文字检索商品
1.Lucene索引建立
2.根据建立好的lucene索引去查询
3.得到的索引信息后,再根据索引中的商品id去查询数据库,得到商品的详细信息。
二、业务实现
(1)索引建立:
@RunWith(SpringJUnit4ClassRunner.class) // 使用Springtest测试框架
@ContextConfiguration("/spring/spring-*.xml") // 加载配置
public class GoodIndexAdd {
private LuceneDao luceneDao = new LuceneDao();
@Autowired
private GoodClassifyDao goodClassifyDao;
@Test
public void addIndexForAll() throws IOException {
/**
* 8-62:商品种类ID的起始Commodity_classification
* 根据商品种类ID查询所属类别的商品信息,建立你的商品种类和商品索引,原因我只伪造了两个商品种类假数据,就是id=15和16的商品,所以我们只建立对他的索引咯
* */
for(int i = 15; i <= 16; i++){
System.out.println("goodClassifyDao "+goodClassifyDao);
List<GoodDetails> list = goodClassifyDao.findGoodDetailsByClassifyID(i);
System.out.println("junitTest:list.size()="+list.size());
for (int index = 0; index < list.size(); index++) {
luceneDao.addIndex(list.get(index));
System.out.println(list.get(index).toString());
}
}
}
}
联查一个
<!-- 根据商品种类ID查询所属类别的商品信息 ,目前用于建立索引-->
<select id="findGoodDetailsByClassifyID"
parameterType="integer" resultType="com.fuzhu.entity.GoodDetails">
select
d.Good_ID ,
d.Classify_ID,
d.Good_Name
from
Commodity_classification c,
Commodity_list d
where
c.Classify_ID=#{value} and d.Classify_ID=c.Classify_ID
</select>
(2)Controller层:
// 文字检索
@RequestMapping(value = "/findGoodByName",produces="text/html;charset=UTF-8", method = {RequestMethod.GET,RequestMethod.GET})
public Object findGoodByName(String goodName, HttpServletResponse response)
throws Exception {
response.setHeader("Access-Control-Allow-Origin", "*");//解决跨域问题
System.out.println("查找商品名参数:" + goodName);
System.out.println("-------------------------------");
List<GoodDetails> goodDetailsList = goodService.findIndex(goodName, 0,
2);// 100
System.out.println("goodDetailsList=" + goodDetailsList.size());
String realGoodid = null;
GoodDetails goodAllDetails = new GoodDetails();
goodList = new ArrayList<GoodDetails>();
if (goodDetailsList != null && goodDetailsList.size() > 0) {
long start = System.nanoTime();
for (int index = 0; index < goodDetailsList.size(); index++) {
realGoodid = goodDetailsList.get(index).getGoodId();
goodAllDetails = goodService.findGoodAllDetailsById(realGoodid);
if (goodAllDetails == null) {
System.out.println("realGoodid=" + realGoodid);
}
if (goodAllDetails != null) {
goodAllDetails.setGoodName(goodDetailsList.get(index)
.getGoodName() + realGoodid);
goodList.add(goodAllDetails);
}
}
long time = System.nanoTime() - start;
System.out.println("测试耗时!!!!"+time);
}
System.out.println("现在北京时间是:" + new Date());
if (goodList != null) {
System.out.println("根据商品名找到的商品数目" + goodList.size());
}
return JSON.toJSONString(goodList);
}
(3)Service层调用检索索引:
@Autowired
private LuceneDao luceneDao;//交给spring管理这个
@Override
public List<GoodDetails> findIndex(String keyword, int start, int row) {
// LuceneDao luceneDao = new LuceneDao();//交给spring管理这个
System.out.print("luceneDao "+luceneDao);
List<GoodDetails> goodDetailsList;
try {
goodDetailsList = luceneDao.findIndex(keyword, start, row);
return goodDetailsList;
} catch (Exception e) {
e.printStackTrace();
}
return null;
}
(4)Service层调用根据索引id检索商品细节:
@Override
public GoodDetails findGoodAllDetailsById(String goodId) {
GoodDetails goodDetails = goodDetailsDao.findGoodDetailsById(goodId);
return goodDetails;
}
(5)LuceneDao检索索引库细节:
/*
* 分页:每页10条
* */
public List<GoodDetails> findIndex(String keywords, int start, int rows) throws Exception {
Directory directory = FSDirectory.open(new File(Constant.INDEXURL_ALL));//索引创建在硬盘上。
IndexSearcher indexSearcher = LuceneUtils.getIndexSearcherOfSP();
/**同义词处理*/
// String result = SynonymAnalyzerUtil.displayTokens(SynonymAnalyzerUtil.convertSynonym(SynonymAnalyzerUtil.analyzeChinese(keywords, true)));
// Analyzer analyzer4 = new IKAnalyzer(false);// 普通简陋语意分词处理
// TokenStream tokenstream = analyzer4.tokenStream("goodname", new StringReader(keyword));
String result = keywords;//不作分词处理直接检索
//需要根据哪几个字段进行检索...
String fields[] = {"goodName"};
//查询分析程序(查询解析)
QueryParser queryParser = new MultiFieldQueryParser(LuceneUtils.getMatchVersion(), fields, LuceneUtils.getAnalyzer());
//不同的规则构造不同的子类...
//title:keywords content:keywords
Query query = queryParser.parse(result);
//这里检索的是索引目录,会把整个索引目录都读取一遍
//根据query查询,返回前N条
TopDocs topDocs = indexSearcher.search(query, start+rows);
System.out.println("总记录数="+topDocs.totalHits);
ScoreDoc scoreDoc[] = topDocs.scoreDocs;
/**添加设置文字高亮begin*/
//htmly页面高亮显示的格式化,默认是<b></b>即加粗
Formatter formatter = new SimpleHTMLFormatter("<font color='red'>", "</font>");
Scorer scorer = new QueryScorer(query);
Highlighter highlighter = new Highlighter(formatter, scorer);
//设置文字摘要(高亮的部分),此时摘要大小为10
//int fragmentSize = 10;
Fragmenter fragmenter = new SimpleFragmenter();
highlighter.setTextFragmenter(fragmenter);
/**添加设置文字高亮end*/
List<GoodDetails> goodDetailslist = new ArrayList<GoodDetails>();
//防止数组溢出
int endResult = Math.min(scoreDoc.length, start+rows);
GoodDetails goodDetails = null;
for(int i = start;i < endResult ;i++ ){
goodDetails = new GoodDetails();
//docID lucene的索引库里面有很多的document,lucene为每个document定义了一个编号,唯一标识,自增长
int docID = scoreDoc[i].doc;
System.out.println("标识docID="+docID);
Document document = indexSearcher.doc(docID);
/**获取文字高亮的信息begin*/
System.out.println("==========================");
TokenStream tokenStream = LuceneUtils.getAnalyzer().tokenStream("goodName", new StringReader(document.get("goodName")));
String goodName = highlighter.getBestFragment(tokenStream, document.get("goodName"));
System.out.println("goodName="+goodName);
System.out.println("==========================");
/**获取文字高亮的信息end*/
//备注:document.get("id")的返回值是String
goodDetails.setGoodId((document.get("id")));
goodDetails.setGoodName(goodName);
goodDetailslist.add(goodDetails);
}
return goodDetailslist;
}
(6)检索精确优化,实现中文拆分:
public class SynonymAnalyzerUtil {
/**
*
* 此方法描述的是:进行中文拆分
*/
public static String analyzeChinese(String input, boolean userSmart) throws IOException {
StringBuffer sb = new StringBuffer();
StringReader reader = new StringReader(input.trim());
// true 用智能分词 ,false细粒度
IKSegmenter ikSeg = new IKSegmenter(reader, userSmart);
for (Lexeme lexeme = ikSeg.next(); lexeme != null; lexeme = ikSeg.next()) {
sb.append(lexeme.getLexemeText()).append(" ");
}
return sb.toString();
}
/**
*
* 此方法描述的是:针对上面方法拆分后的词组进行同义词匹配,返回TokenStream
* synonyms.txt:同义词表,在resources目录下
*/
public static TokenStream convertSynonym(String input) throws IOException{
Version ver = Version.LUCENE_44;
Map<String, String> filterArgs = new HashMap<String, String>();
filterArgs.put("luceneMatchVersion", ver.toString());
filterArgs.put("synonyms", "synonyms.txt");
filterArgs.put("expand", "true");
SynonymFilterFactory factory = new SynonymFilterFactory(filterArgs);
factory.inform(new FilesystemResourceLoader());
Analyzer IKAnalyzer = new IKAnalyzer();
TokenStream ts = factory.create(IKAnalyzer.tokenStream("someField", input));
return ts;
}
/**
*
* 此方法描述的是:将tokenstream拼成一个特地格式的字符串,交给IndexSearcher来处理,再进行精确度高的检索
*/
public static String displayTokens(TokenStream ts) throws IOException
{
StringBuffer sb = new StringBuffer();
CharTermAttribute termAttr = ts.addAttribute(CharTermAttribute.class);
ts.reset();
while (ts.incrementToken())
{
String token = termAttr.toString();
sb.append(token).append(" ");
System.out.print(token+"|");
}
System.out.println();
ts.end();
ts.close();
return sb.toString();
}
}















 373
373

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









