






一、选择题(每小题 2 分,共 18 分)。
1 、以下数据结构中,( D )是非线性数据结构.
A. python 的 list B. 队列 C. 栈 D. 完全二叉树
解释 简单来说线性数据是“一对一”的,即数据元素首尾相连,且有唯一的“前驱”与“后继”,如线性表,栈,队列,双队列,循环队列,一维数组,串;而非线性数据结构是“一对多”或“多对一”的,一个结点可能会对应多个“前驱”和“后继”,如多维数组(维数在二维以上的)、广义表、数、图。
2、从物理存储上可以把数据结构分为( C )两大类.
A. 线性结构和非线性结构 B. 动态结构和动态结构
C. 顺序结构和链式结构 D.初等结构和构造型结构
解释 从物理存储上,可以把数据结构分为四类,分别是:顺序结构、链表结构、散列结构以及索引结构。
3、设顺序线性表 list 中有 n 个数据元素,则删除表中第 i 个元素(下标为i-1)需要移动( B ) 个元素.
A. n+l-i B. n-i C.n-1-i D. i
解释 假设创建一个长度为8的数组(因为顺序线性表可用数组实现),如图

现在要“删除”第4个元素(索引为3的值),“删除”之后如图

我们发现在索引为3的位置空了出来,那么在其之后的元素都要前移,覆盖原有的空位

那么数组有n=8 个元素,则删除表中第 i=4 个元素(下标为 i-1 = 3)需要移动 n-i = 4 个元素。
4 、设n 是非负整数,变量 x 的初值设为 1 ,下面 python 程序段的时间复杂度是( A ).
while( x < n ): x = 2*x
A. O(log2(n)) B. O(n) C. O(n log2(n)) D. O(n2 )
解释 先看循环条件“ x < n”:若设k为循环次数,那么就要找到达到循环条件的最小循环次数;再看循环体“x = 2*x”:每次将原来x值的2倍赋值给x,即1、2、4、8......也就是要找到最少迭代次数k,使得2*k >= n,即k >= log2(n),即时间复杂度为O(log2(n))。
5、在字符串匹配问题中,设目标串长为 n,模式串长为 m,则字符串KMP 匹配算法的计算 时间复杂度为( C )。
A. O(n) B. O(n*m) C. O(n+m) D. O(m*log n)
解释 在最坏情况下:
对于模式串,需要比较每个字符一次,以确定当前位置的最长公共前后缀长度,时间复杂度为O(m);
对于目标串,需要遍历整个目标串一次,时间复杂度为O(n);
对于整体来说,这两部分是顺序进行的,即算法首先需要O(m)的时间来构建LPS数组,然后需要O(n)的时间来在目标串中使用模式串和LPS数组进行搜索。这两个操作是独立的,所以它们的时间复杂度相加给出了整个算法的时间复杂度O(m+n)。
6 、栈和队列的共同点是( C )。
A. 都是先进先出 B. 都是先进后出
C. 只允许在端点处插入和删除元素 D. 不存在
解释 栈与队列只允许在端点处插入和删除元素,区别是栈----先进后出,队列----先进先出。
7 、 设有序表中有 1010 个元素,则用二分查找元素 X 最多需要比较( B )次.
A. 25 B. 10 C. 7 D. 1
解释 具有n个元素的有序表,使用二分查找方法查找元素X最多需要进行log2(n)次比较,与第四题恰好相反,相当于已知目标值求比较(迭代)次数k。
8 、python 自带的 set 数据类型,其底层实现是( D ).
A. list B. 单链表 C. 平衡二叉树 D. 散列表
解释 Python的集合set数据类型,特性之一是集合中的元素是不可变的,如整数、浮点数、字符串和元组。因为集合底层实现是哈希表(散列表),这样可以保证哈希值的一致性,减少哈希碰撞。
9 、对于 pyhton 自带的 dict 数据结构,其查找操作的时间复杂度为( A ).
A. O(1) B. O(n) C. O(log n) D. O(n2)
解释 由于字典(dict)“键值对”的特性,查找值只需定位其值所对应的键,故时间复杂度为O(1)。
二、填空题( 每空 2 分,共 14 分)。
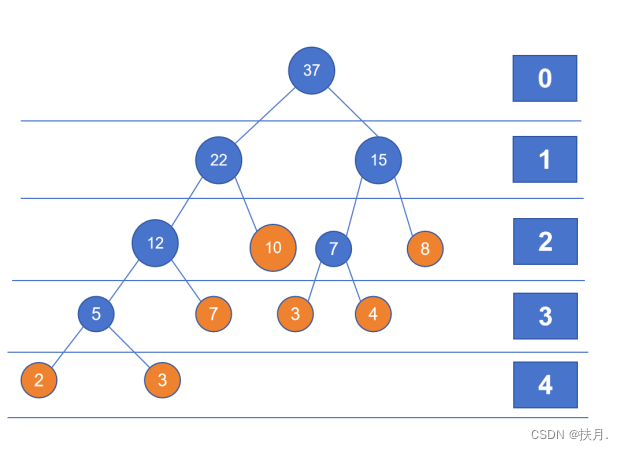
10、用 python 的 list 存储完全二叉树,假定从上到下、从左到右的顺序存放,list 中下标索
引为 1 的位置存放根节点,则下标索引为 i 的节点,其右子节点的下标索引为 2*i+1 ,
其父节点的下标索引为 i//2 .
解释 从划线部分看,是以层序遍历顺序存储,那么可以浅浅举个例子:
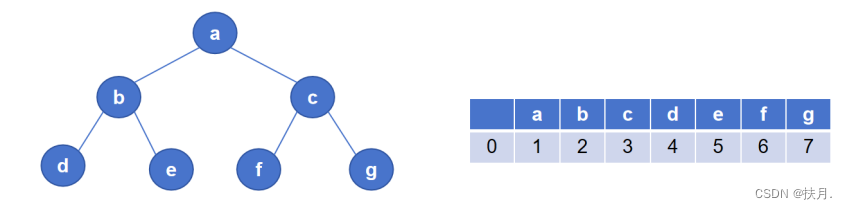
如图,当节点为b(索引值为2)时,其父节点a的索引值为1,右下结点e的索引值为5;当节点为c(索引值为3)时,其父节点a的索引值为1,右下结点g的索引值为7.这样易推出其右下节点的下标索引为2*i+1。而因为每个节点的左子节点的编号是父节点编号的两倍,右子节点的编号是父节点编号的两倍加一,故其父节点的下标索引为n//2。
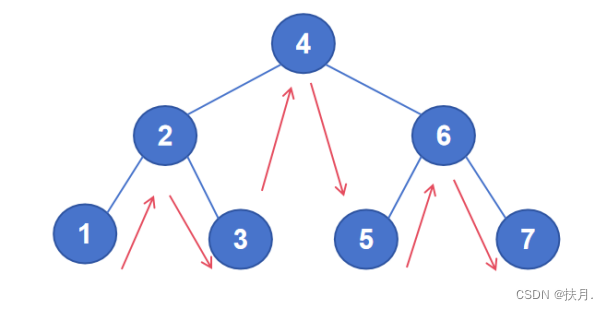
11、层数为h 的满二叉树,其第 k 层共有 2^k-1 个节点(1 ≤ k ≤ h ).
解释 满二叉树(如上题图):一种特殊的二叉树,它的每一层都是满的,即每一层都有最大数量的节点。知道了概念,直接举例子多画几个,公式就推出来了
12、 中序 遍历二叉排序(查找)树中的结点可以得到一个单调递增的关键字序列(选
填“先序”、“中序”或“后序”).
解释 二叉排序树:左子节点值小于其父节点值,右子节点值大于其父节点值的二叉树。如图,显然是中序遍历,因为中序遍历的顺序是“左根右”,顺序恰好是单调递增。
13 、设有 n 个无序数据的 list 进行快速排序,其平均时间复杂度为 O(n*log2(n)) .
解释 快速排序的原理是采用某个元素(通常是第一个元素)作为基准,每一轮循环将基准归位,直至排序完成的排序方法。
最好情况:若每次划分恰好为两个等长的子表,此时的递归树高度最小,性能最好,高度为O[log2(n)],而每层时间为O(n),时间复杂度为O(n*log2(n));
最坏情况:若初始排序表正序或反序,使得每次划分的两个子表一个为空,另一个长度为(n-1),此时递归树的高度最高,性能最差,高度为O(n)(想象拉面师傅把面团扯成一整根面条的样子)。而每层时间为O(n),时间复杂度为O(n^2)。
那么平均时间复杂度为O[n*log2(n)]。
14、具有 n 个顶点的有向图,最多有 n(n-1) 条边.
解释 暴力解法----直接画图!!!任意一点与其余点相连,画多种情形的有向图即可得出答案。
15、针对下面图 1 的无向连通图,按深度优先遍历算法,遍历的节点顺序应为(假定遍历某
节点的相邻节点时,按编号从小到大的顺序进行): 1、2、3、5、6、4
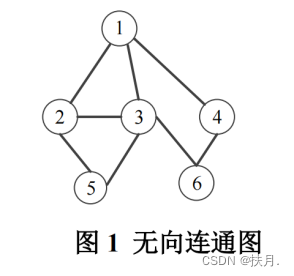
解释 深度优先遍历:任选一节点作为起点,找起点的一个未访问的邻接点,以此为基础重复操作;若邻接点均被访问则回退上个节点,直至所有节点被遍历。
由题可知,找节点的原则是优先找小的数字,所以从1开始,如图,那么答案就一目了然了。
三、简答题(每小题 8 分,共 32 分)。
16、设一棵二叉树的先序序列:A B D F C E G H ,中序序列:B F D A G E H C。请问二叉 树的形态是否唯一?如果唯一,请简要说明确定此二叉树形态的步骤,并画出该二叉树。
答:二叉树形态唯一。方法是交替考虑先序序列和中序序列,由先序序列确定根节点,再由中序序列和前面确定的根节点能得到左右子树的节点集合划分。对左右子树仍然按上述方法进行,直到确定所有的节点位置。此二叉树的形态如下:

解释 一棵二叉树所必备的元素:根节点、左右子树。而中序序列能确定左右子树,先序序列(后序序列)能确定根节点,那么二叉树的形态就被确定下来。
而如何正确画出二叉树呢?口诀就是:中序找子树,先序后序找结点,先序靠前,后序靠后,交替查找。
(1)从先序序列易得A为根节点;再看中序序列,A的左、右区间即为二叉树的左、右子树,左子树为BFD,右子树为GEHC;其次看先序序列中对应的左、右子树,在左子树中,B最靠近A(靠前),故B是其左子树的根节点,同理C为其右子树的根节点。
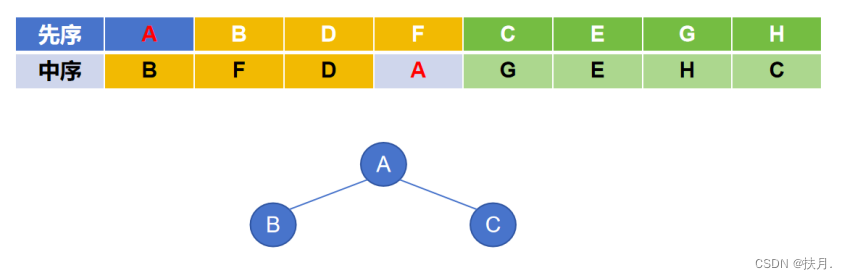
(2)先看中序序列,现在是以B为根节点,找其对应的左右子树,由图可知根节点B仅有右子树FD,无左子树,同理根节点C仅有左子树GEH,无右子树;其次看先序序列对应的左、右子树,在根节点B的右子树中,D最靠近B,故D是其右子树的根节点,同理,在根节点为C的左子树中,E是其左子树的根节点。
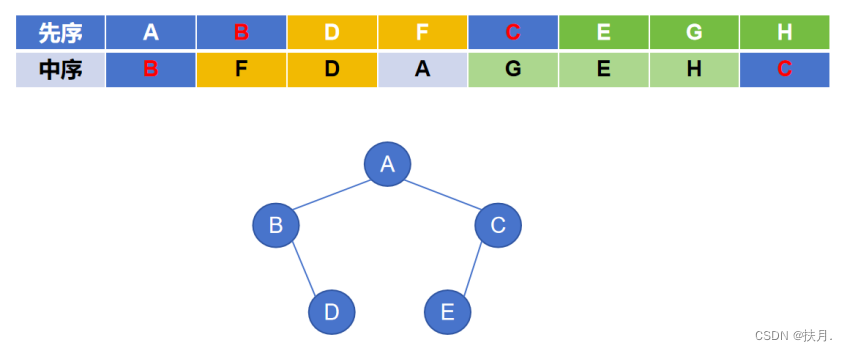
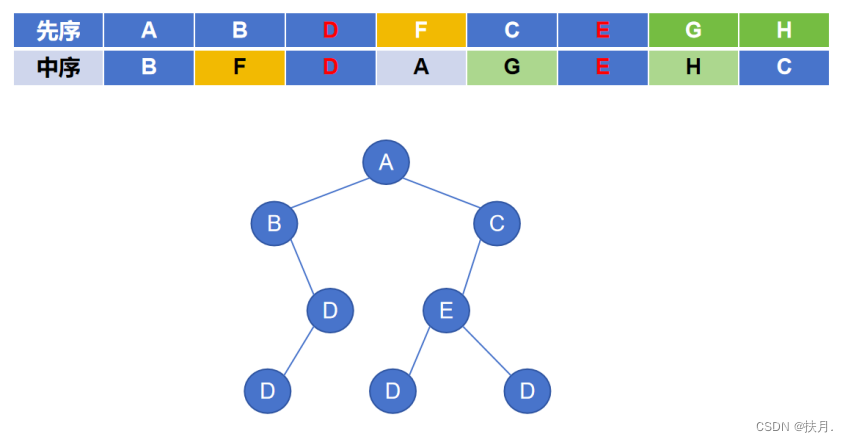
(3)先看中序遍历,对于根节点D,F是D的左子树,同理对于根节点E,G、H分别是E的左、右子树,至此二叉树形态唯一确定。
17、请给出小顶堆的定义,论述小顶堆有哪几种主要操作,以及各种操作的算法时间复杂度, 并举例说明小顶堆的适用场景。
答:
(1)小顶堆是一种完全二叉树,而且其节点存储的数据满足如下特点:每个节点的数据不大于其左、右子节点的数据;小顶堆可用于实现优先队列(根节点优先级最大);小顶堆采用 python 内置的 list 存储数据。
(2)小顶堆的主要操作:插入数据和删除数据,删除数据对应于优先队列的出队操作。插
入数据操作,是先将数据放置于完全二叉树最后一层的最右节点的右边相邻位置,然后做“向上筛选”(子节点与其父节点比较大小),时间复杂度为 O(logn)。删除数据操作,是用完全二叉树最后一层的最右节点替换原来的根节点(根节点已经先被移除),再做“向下筛选”(父节点与其 2 个子节点比较大小),时间复杂度为 O(logn)。
(3)小顶堆可以应用求解哈夫曼树、背包问题等需要贪心算法的场景。
18 、以实数集 W={2, 3, 7, 10, 4, 3, 8}作为叶子节点的权重集,构造出相应的哈夫曼树,画出 该二叉树并计算其带权路径总和。
答:
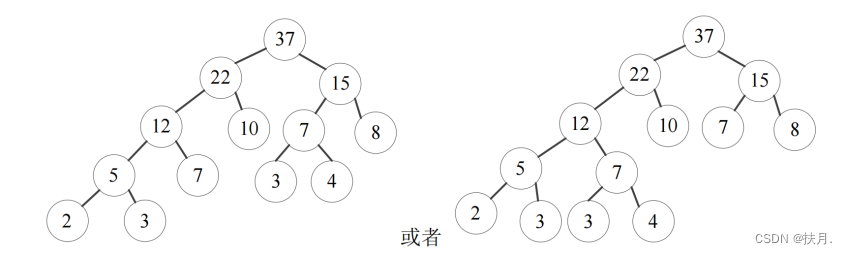
带权总路径和:(2+3)*4 +(7+3+4)*3+(10+8)*2 = 98
解释 介绍一种最简单的方法:
(1)首先找出权重集里最小的两个元素生成新的二叉树,二者相加的结果即为新二叉树的根节点;
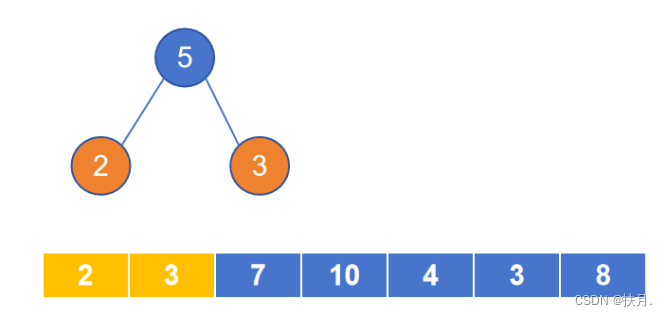
(2)将权重集里用于生成二叉树的元素替换成新的根节点值,继续找最小的两个元素;
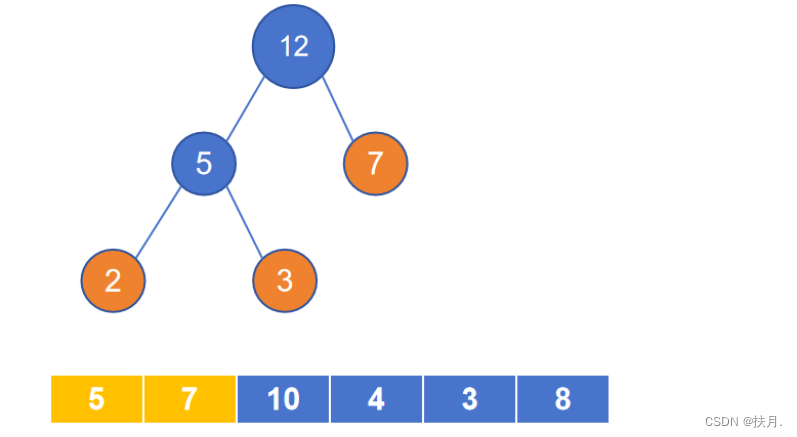
(3)若根节点值本身与权重集中另一元素为最小元素时,将另一元素写在根节点旁边即可;若不构成,就在权重集中继续找最小的两个元素,形成另一个二叉树;
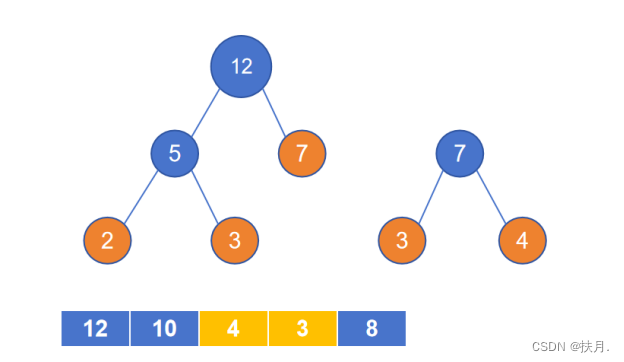
(4)当权重集为空时,调整树,使得邻接距离相等,即为哈夫曼树。
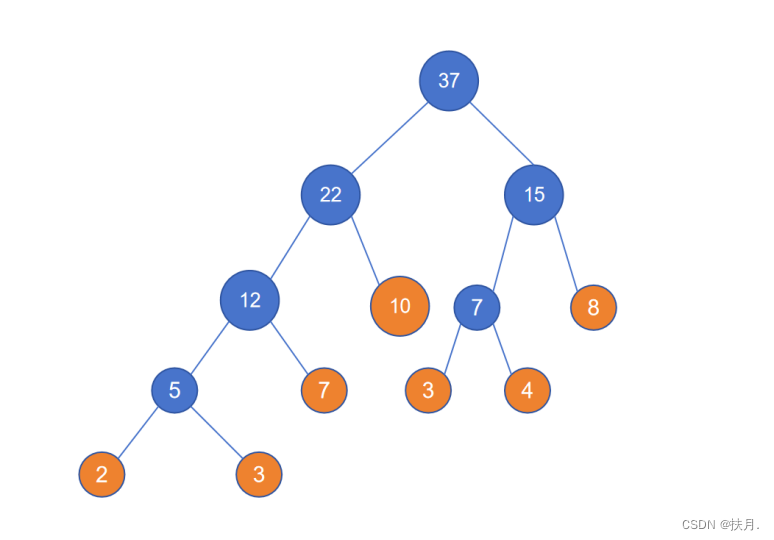
(5)分层,WPL=每层的权重集之和 * 层数
所以,WPL=(2+3)*4 + (7+3+4)*3 + (10+8)*2 = 20+42+36 = 98
需要注意的是,并不是每层的元素都要相加,而是每层所对应的权重集元素!!!
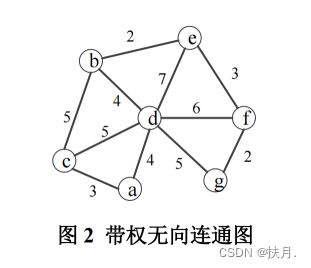
19、针对下图 2 的带权无向连通图,请简要论述求最小生成树的过程,求出其最小生成树, 画出图形,并求其总权值。
答:最小生成树如下图,
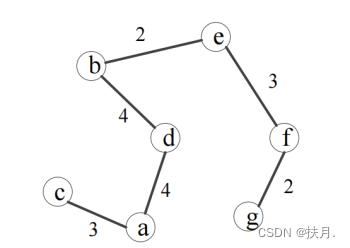
因此,总权值为 2 + 2 + 3 + 3 + 4 + 4 = 18。
解释 一般处理最小生成树问题有三种方法:普里姆算法(Prim)、克鲁斯卡尔算法(Kruskal)以及管梅谷算法,在这里讲讲克鲁斯卡尔算法。
(1)从小到大,依次选择权重小的边,同时选择的边不能与之前与选择的边成环,直至连结每个节点为止;
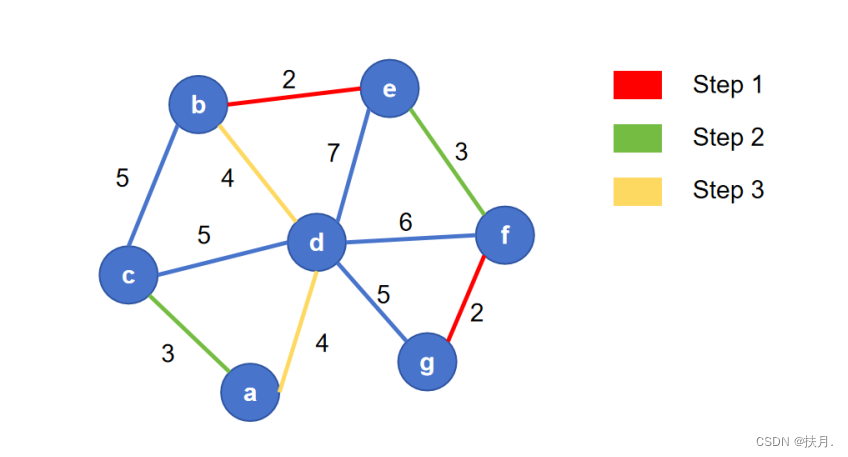
(2)去掉多余的边,即为最小生成树。
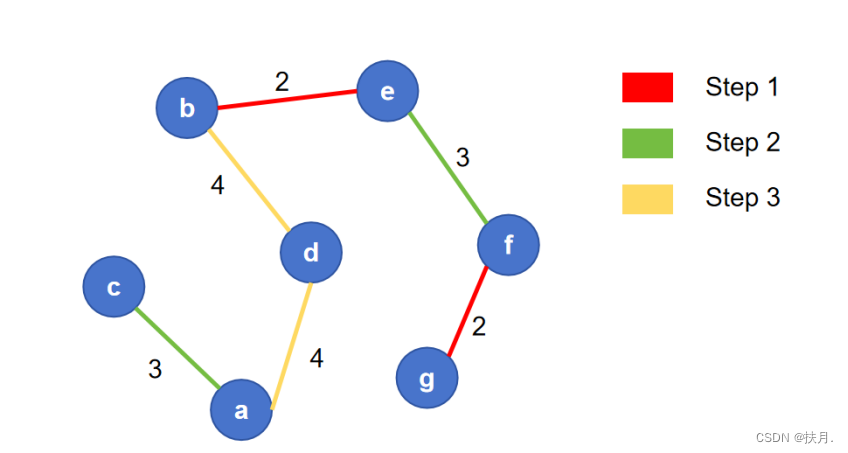
最后将权值相加,得出总权值3+4+4+2+3+2 = 18。
四、程序填空题(每小题 6 分,共 12 分)
20 、下面程序段的功能是实现冒泡排序算法,请在下划线处填上正确的语句。
def bubble(r, n): # r 为需要排序的数组(用 python 的 list 存储数据),n 为数据总数
for i in range(0, n): # 比较的轮次
exchange = 0 # 某一轮比较,是否做了交换
for j in range(0,n-i-1): # 逐个相邻比较
if ( r[j] > r[j+1] ):
temp = r[j+1]
r[j+1] = r[j] # 交换数据
r[j] = temp
exchange = 1
if (exchange == 0):
return
解释 冒泡排序顾名思义就像水里的小泡泡浮出水面,那么肯定将数字小的元素移动到前端咯......在第一空之前的注释“逐个相邻比较”提示了循环体的作用,那么if判断语句的条件自然是“前一个元素数值大于后一个元素数值”,这样才有意义;
注释“交换数据”一句,再结合上下代码,就很容易得出“r[j+1] = r[j]”。
21 、已知二叉树的结点类定义如下: class Node( ):
def init (self, dat, left = None, right = None):
self.data = dat # 节点的数据
self.leftChild = left # 该节点的左子节点
self.rightChild = right # 该节点的右子节点
多个 Node 对象按其 data 进行排序,形成某二叉排序(查找)树。下面的递归程序将实 现在二叉排序树中查找数据为 dataSearch 的节点对象,试将其填写完整。
def bt_search(btree, dataSearch): # btree 是二叉排序树的根节点对象
bt = btree
while bt is not None:
if dataSearch < bt.data: # 查找左子树
bt = bt.leftChild
elif dataSearch > bt.data: # 查找右子树
bt = bt.rightChild
else:
return bt
return None
解释 二叉排序树我再讲一遍:左子节点值小于其父节点值,右子节点值大于其父节点值的二叉树。其实就是在单调递增的数组中进行类似的“二分查找”。若查找的值要比根节点小,那么要查找的值只能在左子树,所以让左子节点成为新的根节点(bt = bt.leftChild),反之则在右子树(bt = bt.rightChild)。
五、应用编程题(每小题 8 分,共 24 分)。
22 、某班的学生成绩信息包括姓名(name)、语文(yw)、数学(sx)、英语(yy) 、语数英三科的总 成绩(zcj)。请用 class 定义学生类 Student,存储单个学生的成绩信息;并利用 python 的 list 存储全体的学生成绩信息。最后,编写一个程序,利用 python 自带的 sort( )函数实现按总成 绩(zcj)排序,并输出排序后的学生成绩信息。除了题目给定信息外,请根据需要自行定义使 用到的其他函数名和变量名,并给出注释。
注:考虑数据规模过大不便手工输入,仅以下面 4 名学生的成绩信息(姓名、语文成绩、数 学成绩、英语成绩)为例。(1)张军:88,51,62;(2)周杰:93, 30, 30;(3)黄恒:92, 27, 75;
(4):李亚男: 92, 43, 80。
答:
class Student():
def __init__(self, name, yw1, sx1, yy1):
self.name = name
self.yw = yw1 # 语文
self.sx = sx1 # 数学
self.yy = yy1 # 英语
self.zcj = self.yw + self.sx + self.yy # 总成绩
# 下面调用 Student 类,生成 4 个学生实例
student1 = Student('张军',88,51,62)
student2 = Student('周杰',93,30,30)
student3 = Student('黄恒',92,27,75)
student4 = Student('李亚男',92,43,80)
student_list = [student1,student2,student3,student4] # 所有学生放入 list
# 调用 sort()函数,按照总成绩(zcj)从大到小排序
student_list.sort(key=lambda x: x.zcj, reverse=True) # reverse==True 时逆向排序
for i in student_list: # 输出排序后的学生成绩信息
print(i.name, i.yw, i.sx, i.yy, i.zcj)
解释 主要考察python的类与对象、列表操作以及排序方法。在期末考试中一般是怎么简单怎么来,基础不好的话求稳是关键。这题难点在于lambda函数(也叫匿名函数)的应用,在“student_list.sort(key=lambda x: x.zcj, reverse=True)”中,lambda函数的作用在于告诉sort函数根据每一个student实例的zcj 属性来排序,而 x代表每一个student实例。
23 、已知二叉树的结点类定义如下: class Node( ):
def init (self, dat, lft = None, rht = None):
self.data = dat # 节点的数据
self.leftChild = lft # 该节点的左子节点
self.rightChild = rht # 该节点的右子节点
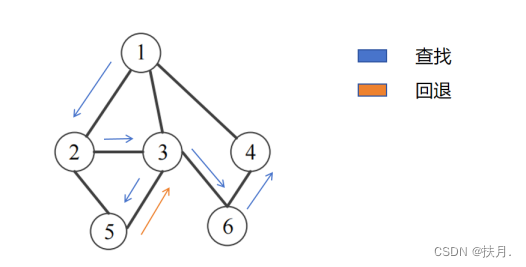
假定某棵二叉树按照上述节点定义,已经构造完毕,其根节点对象为 t 。请在 Node 类 外面,写出按先根序遍历(先序遍历)该二叉树节点的递归程序和非递归程序。编程时,注 意以下几点:
(1)递归程序的函数名为 preorder(t),非递归程序的函数名为 preorderNonrec(t),其中 参数 t 表示二叉树的根节点。
(2)写非递归程序时,则采用栈实现,假定栈的数据结构及实现已写好,栈的类名为 SStack,其包含的入栈和出栈函数分别为 push()和 pop(),判断栈为空的函数是 is_empty()。
(3)此处的遍历节点,即打印(用 print()函数)节点的数据 data。除了题目给定信息外,请根据需要自行定义使用到的其他函数名和变量名,并给出注释。
答:递归程序
def preorder(t):
if t is None:
return
print(t.data)
preorder(t.leftChild)
preorder(t.rightChild)
非递归程序(利用栈)
def preorderNonrec(t):
s = SStack()
while t is not None or not s.is_empty():
while t is not None: # 向左边分支节点探索
s.push(t.rightChild) # 将右子节点压入栈
print(t.data) # 遍历当前节点
t = t.leftChild # 向左边分支节点探索
t = s.pop() # 没有左分支了,回溯(考虑刚进栈的右子节点)
解释 写递归程序是很多小伙伴头疼的问题,而要想做对,就要知道“递归三部曲”。
1.最简单情况(basecase):当节点为空时(也就是遍历到最底层之后或者二叉树为空),返回空值,一定程度上承担了终止条件的作用;
2.递归条件(Recursive Case):首先访问当前节点,然后递归地对左子树进行先序遍历,最后递归地对右子树进行先序遍历;
3.递归调用(Recursive Call):在递归条件中,函数将自身调用两次,一次用于左子树,一次用于右子树。
那么递归程序自然而然就写出来了。
然后再讲讲非递归写法,二叉树的先序遍历的非递归程序主要是以栈来实现,栈具有“先进后出”的特性,存储左子树节点固然容易,那怎么才能存储右子树?那么就用栈来存储右子节点,每次当左子节点遍历完,将出栈元素作为新的遍历节点,即可得到先序序列。
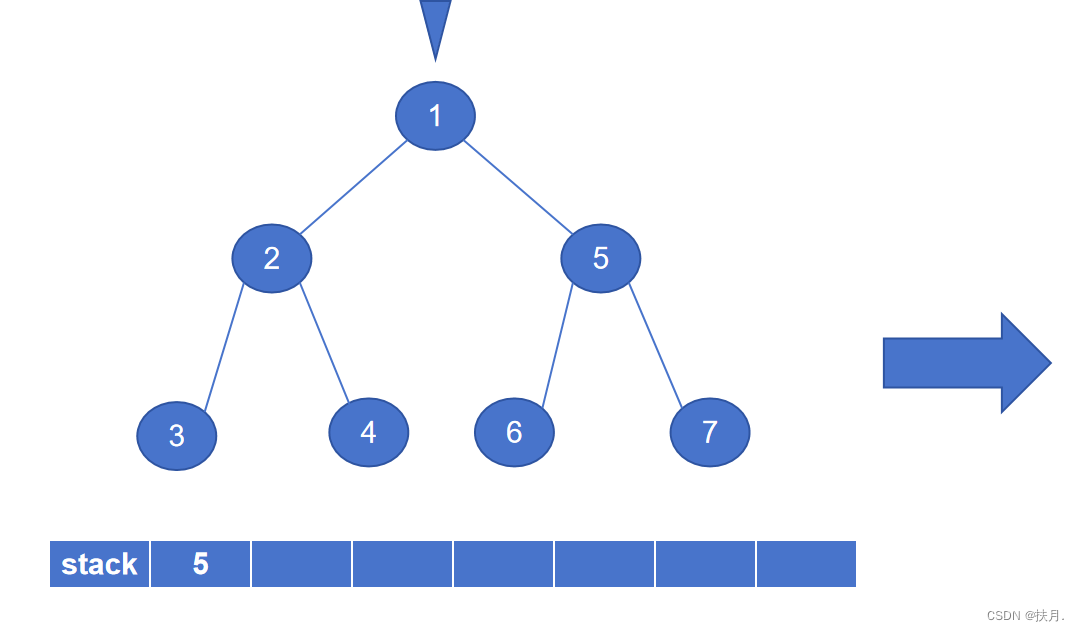
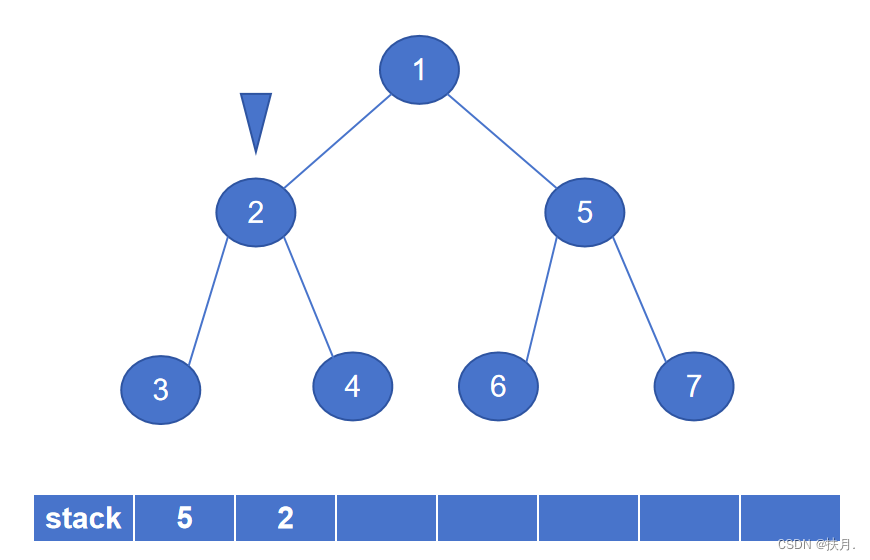
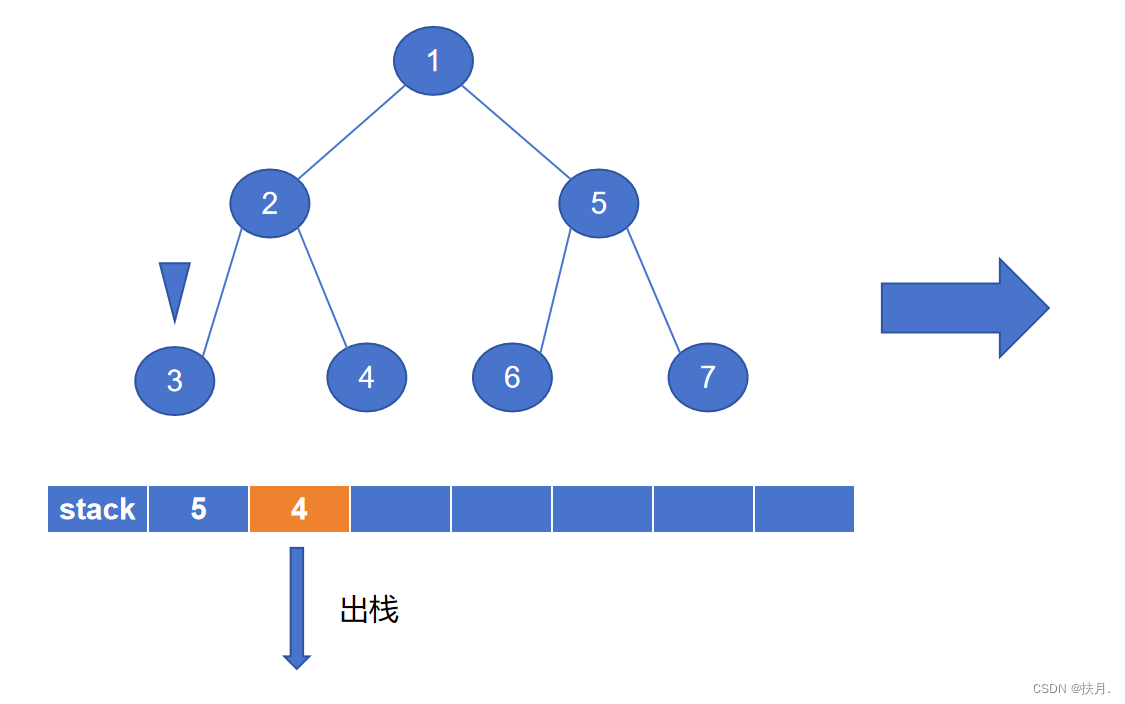
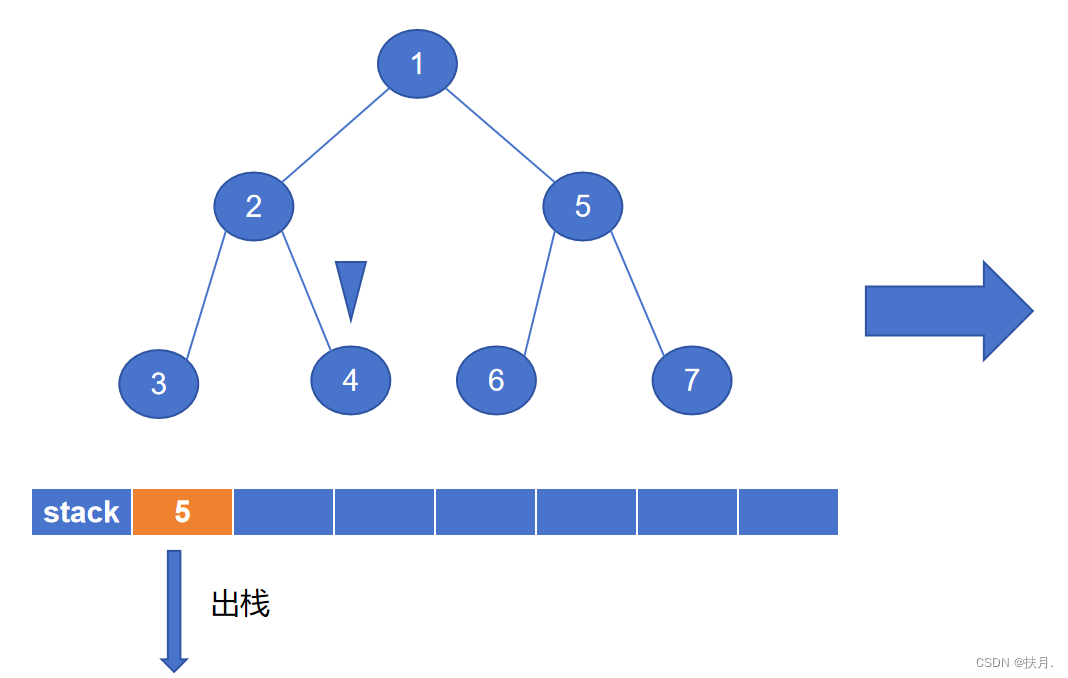
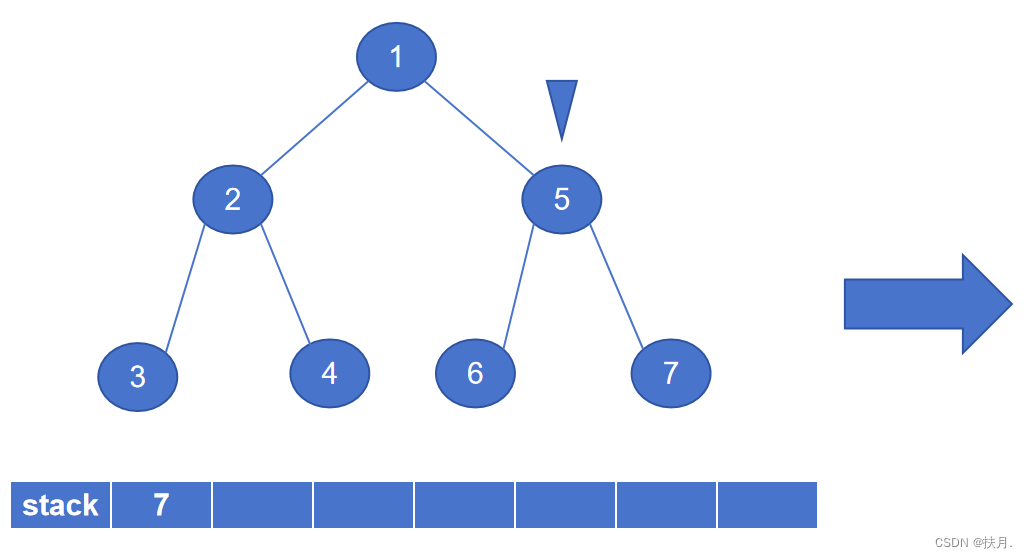
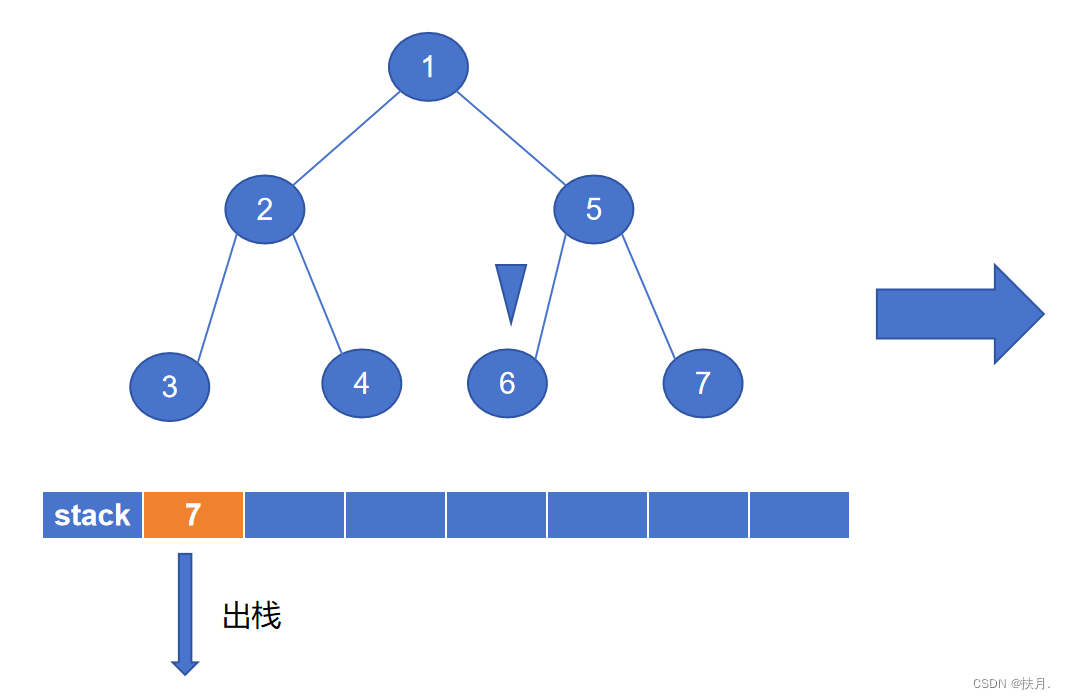
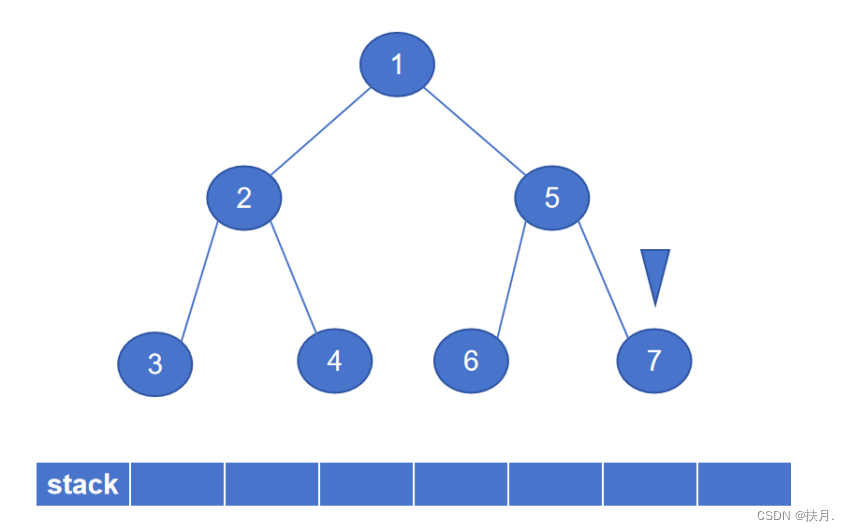
如图,最后生成的先序序列为1234567。
24 、设 n 个人围成一圈,编号依次为 1 ,2 ,ⅆ , n。现从编号为 1 的第 1 个人开始报数 1 , 第 2 个人开始报数 2 , ⅆ , 依次报数,直到报数m(小于 n)时,此人出圈。某人出圈后, 从其下一个人重新开始报数 1 ,一直循环下去,直到最后全部人出圈。请利用普通队列,设 计模拟该过程的算法,编程给出出圈人的编号顺序。例如 N=6,M=5,出队列的顺序是:5, 4 ,6 ,2 ,3 ,1。
注:假定普通队列的数据结构及实现已写好,队列的类名为 deque,进队函数 append(),出 队函数 popleft(),队列的求长度函数 len();求解约瑟夫问题的函数名为 yuesefu(n,m) 。除了 题目给定信息外,请根据需要自行定义使用到的其他函数名和变量名,并给出注释。
解释 答案不太好理解,有一种易于理解的写法:
def yuesefu(n, m): # n为总人数,m为出队的序数
people = deque(range(1,n+1))
res = []
while len(people) > 1:
for _ in range(m-1):
people.append(people.popleft())
res.append(people.popleft())
res.append(people[0])
return res
在这个问题中,n个人围成一圈,从第一个人开始报数,每数到m的人就会被淘汰,然后从下一个人重新开始报数,直到所有人都被淘汰。这个函数yuesefu就是模拟这个过程的。
在函数中,deque被用来创建一个双端队列,里面包含了从1到n的所有整数,代表这n个人。res列表被用来存储被淘汰人的编号。
接下来,进入一个循环,只要队列中的人数大于1,循环就会继续。在循环中,首先进行m-1次操作,每次都把队首的人放到队尾,这样实际上就是模拟了从第一个人开始报数,每数到m-1的时候,第m个人就会被淘汰。然后,这个被淘汰的人(即队首的人)会被加到res列表中,并且从队列中移除。
当队列中只剩下一个人的时候,循环结束,这个最后剩下的人就是最后的胜者,他的编号也会被加到res列表中。
最后,res列表被返回,里面包含了所有人被淘汰的顺序。















 1167
1167

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









