







用梯度下降 对线性模型做优化。
如果有两个或两个以上的自变量,用多元线性回归 。
用多项式回归 来描述非线性关系的变量.
用正则化 来确保你的模型不仅训练误差小,而且测试误差也小 (泛化好)。
1、绝对值
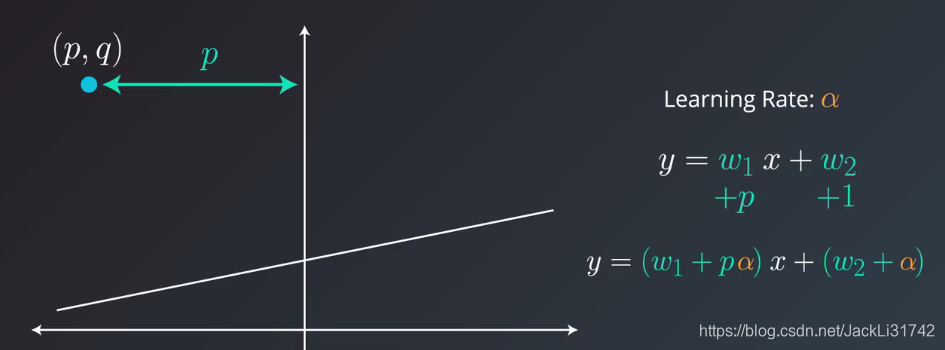
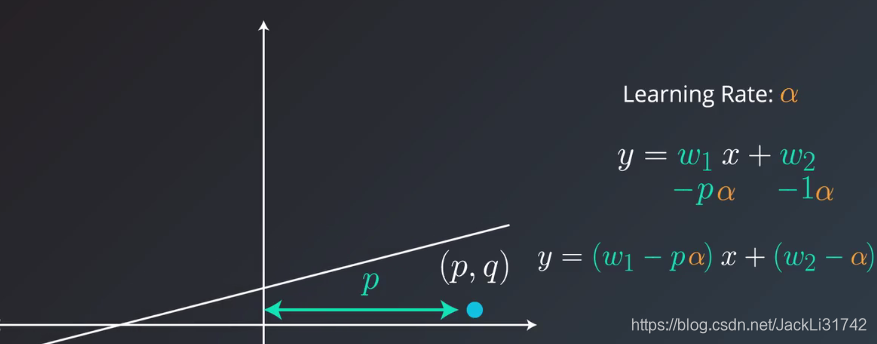
2、

3、平均绝对值误差
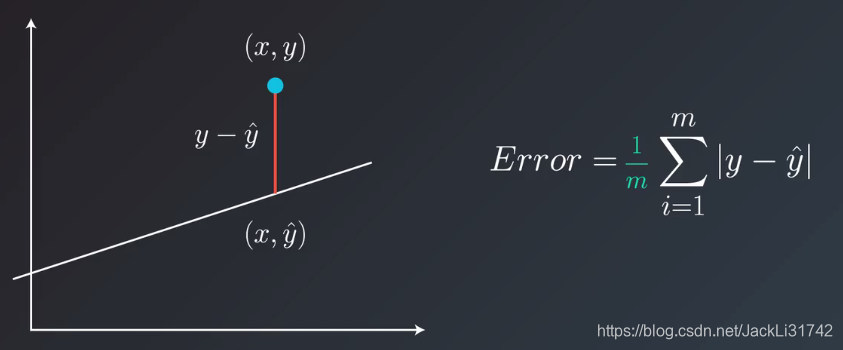
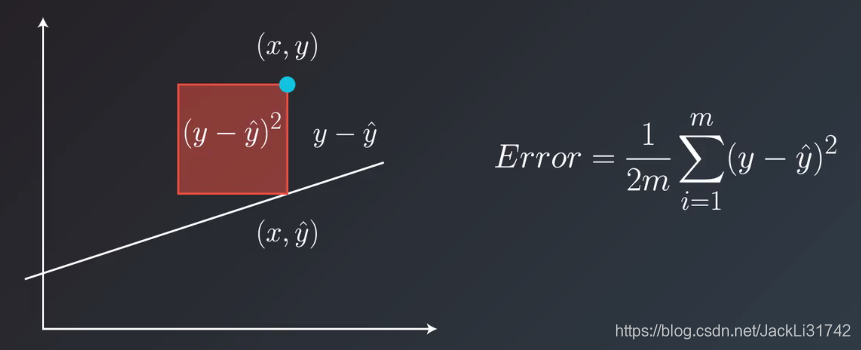
4、均方误差
到目前为止,我们已经见过两种线性回归方法。
(1)逐个地在每个数据点应用均方(或绝对)误差,并重复这一流程很多次。
(2)同时在每个数据点应用均方(或绝对)误差,并重复这一流程很多次。
具体而言,向数据点应用均方(或绝对)误差时,就会获得可以与模型权重相加的值。我们可以加上这些值,更新权重,然后在下个数据点应用均方(或绝对)误差。或者同时对所有点计算这些值,加上它们,然后使用这些值的和更新权重。
后者第二种方法叫做批量梯度下降法。前者第一种方法叫做随机梯度下降法
线性回归的最佳方式是将数据拆分成很多小批次。每个批次都大概具有相同数量的数据点。然后使用每个批次更新权重。这种方法叫做小批次梯度下降法。
from sklearn.linear_model import LinearRegression
model = LinearRegression()
model.fit(x_values, y_values)
print(model.predict([ [127], [248] ]))
5、小批量梯度下降
import numpy as np
# Setting a random seed, feel free to change it and see different solutions.
np.random.seed(42)
# TODO: Fill in code in the function below to implement a gradient descent
# step for linear regression, following a squared error rule. See the docstring
# for parameters and returned variables.
def MSEStep(X, y, W, b, learn_rate = 0.005):
"""
This function implements the gradient descent step for squared error as a
performance metric.
Parameters
X : array of predictor features
y : array of outcome values
W : predictor feature coefficients
b : regression function intercept
learn_rate : learning rate
Returns
W_new : predictor feature coefficien 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 4万+
4万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









