






进程、线程、协程的适用场景对比
进程、线程、协程是实现linux server高并发的三种主要方式,其各有优缺点和适用场景:
一、核心概念对比
| 维度 | 进程 | 线程 | 协程 |
|---|---|---|---|
| 执行单元 | 操作系统分配资源的基本单位 | 进程内的执行流 | 用户态轻量级线程(纤程) |
| 资源隔离 | 完全隔离(独立地址空间) | 共享进程资源 | 共享线程资源 |
| 调度方式 | 操作系统内核调度 | 操作系统内核调度 | 用户程序控制(非抢占式) |
| 切换开销 | 高(涉及地址空间切换) | 中(仅切换寄存器和栈) | 低(仅切换用户态上下文) |
| 创建成本 | 高(需分配独立内存空间) | 中(共享进程内存) | 低(仅需少量栈空间) |
| 并发数量 | 数十到数百量级 | 数百到数千量级 | 数万到数百万量级 |
二、适用场景分析
- 选择进程的场景
-
强隔离需求:当任务需要完全隔离资源(如内存、文件句柄),避免因一个任务崩溃导致整个系统故障时,例如:
- 微服务架构中的独立服务(如 Web 服务器、数据库服务)
- 安全沙箱环境(如浏览器的多进程架构)
- 处理不可信代码(如在线编译器、病毒扫描程序)
-
多核 CPU 密集型计算:利用多核 CPU 并行处理计算任务,每个进程绑定到独立核心,例如:
- 视频转码、3D 渲染
- 科学计算(如气象模拟、物理仿真)
- 大数据处理(如 Hadoop 分布式计算)
-
跨平台兼容性:
进程模型在不同操作系统中实现一致,适合需要跨平台的场景。
- 选择线程的场景
-
IO 密集型任务: 当任务需要频繁等待 IO 操作(如网络请求、文件读写),通过多线程并发提高资源利用率,例如:
- 服务器端编程(Web 服务器、数据库客户端)
- 桌面应用(如文本编辑器的异步加载图片)
- 网络爬虫(并发请求多个 URL)
-
共享资源协作: 当任务需要共享数据并协作完成目标,例如:
- 多线程下载器(不同线程下载文件分片)
- 图形界面应用(UI 线程与逻辑线程分离)
- 实时音视频处理(采集、编码、传输线程协作)
-
中等并发量需求:
当并发量在数百到数千量级,线程模型足够高效(如 Java 的 Tomcat 服务器默认用线程处理请求)。
- 选择协程的场景
-
超高并发场景:当需要处理数万到数百万并发连接(如 C10K 问题),协程的轻量级特性可大幅降低资源消耗,例如:
- 高性能网络服务器(如 Nginx 的事件驱动模型、Go 的 goroutine)
- 实时通信系统(WebSocket 长连接、游戏服务器)
- 高并发爬虫(同时处理数万请求)
-
用户态调度优化:当需要精确控制任务调度时机(如避免内核抢占导致的上下文切换开销),例如:
- 游戏引擎(协程实现帧同步逻辑)
- 异步编程框架(Python 的 asyncio、Node.js 的事件循环)
- 微服务中的请求链路调度
-
降低上下文切换开销:
协程切换仅涉及用户态数据(如寄存器、栈指针),适合需要频繁切换的场景(如事件驱动编程)。
三、典型应用案例
| 场景 | 推荐模型 | 示例技术 |
|---|---|---|
| 后端 Web 服务器 | 线程 / 协程 | 线程:Tomcat、Jetty;协程:Gin、Node.js |
| 大数据计算 | 进程 | Hadoop、Spark |
| 实时游戏服务器 | 协程 | ENet、KCP 协议结合协程框架 |
| 桌面应用(如 IDE) | 线程 | VS Code 的多线程文件索引 |
| 高并发网络爬虫 | 协程 | Python 的 Scrapy+Twisted |
| 科学计算(矩阵运算) | 进程 / 线程 | 进程:MPI;线程:OpenMP |
四、选择策略总结
-
优先考虑协程:
- 目标:处理超高并发(>10 万连接)、降低调度开销
- 条件:任务为 IO 密集型,且可接受用户态调度(非抢占式)
-
其次考虑线程:
- 目标:中等并发(数百到数千)、需要内核级抢占调度
- 条件:任务包含 IO 和计算混合逻辑,或需要跨平台兼容
-
最后考虑进程:
- 目标:强隔离性、多核 CPU 密集型计算
- 条件:任务间需要完全资源隔离,或对调度开销不敏感
五、实战建议
- 混合模型:在复杂系统中,可结合多种模型(如 “主进程 + 多线程 + 协程”),例如:
- 主进程负责资源管理,工作线程用协程处理具体任务(如 Nginx 的多进程 + 事件驱动模型)。
- 语言特性:根据编程语言选择合适的模型:
- Go 语言:天然支持 goroutine(协程),适合高并发网络服务
- Python:多线程受 GIL 限制,更适合用协程(asyncio)或多进程
- C/C++:可手动实现协程(如 ucontext),或使用线程库(pthread)
六、linux c实现协程
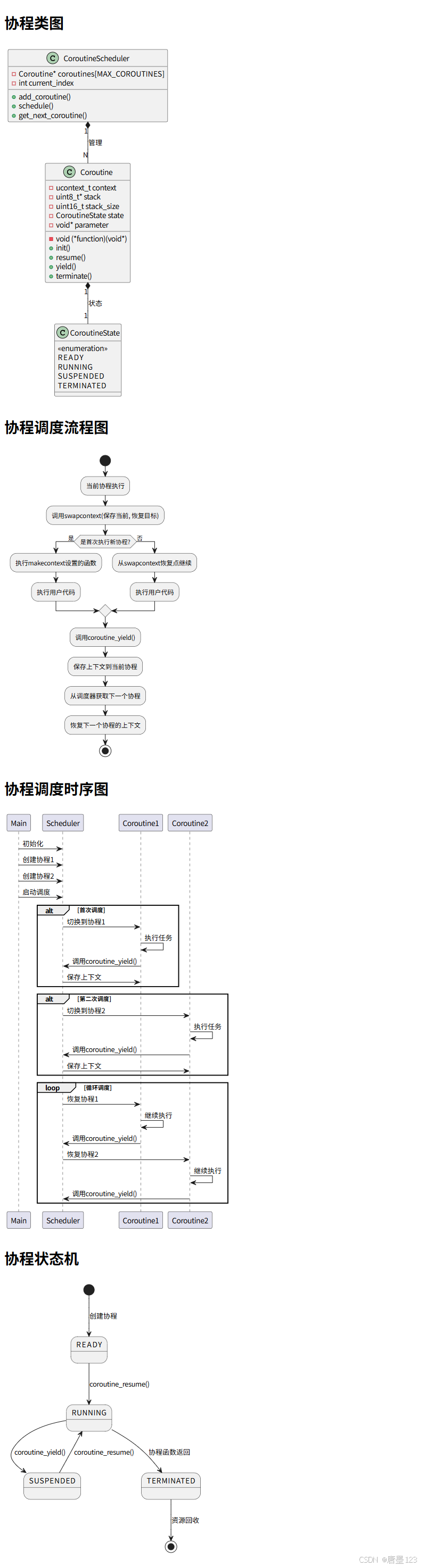
协程类图
@startuml Coroutine Class Diagram
class Coroutine {
-ucontext_t context
-uint8_t* stack
-uint16_t stack_size
-CoroutineState state
-void (*function)(void*)
-void* parameter
+init()
+resume()
+yield()
+terminate()
}
class CoroutineScheduler {
-Coroutine* coroutines[MAX_COROUTINES]
-int current_index
+add_coroutine()
+schedule()
+get_next_coroutine()
}
class CoroutineState {
<<enumeration>>
READY
RUNNING
SUSPENDED
TERMINATED
}
Coroutine "1" *-- "1" CoroutineState : 状态
CoroutineScheduler "1" *-- "N" Coroutine : 管理
@enduml
协程调度流程图
@startuml Context Switch Flow
start
:当前协程执行;
:调用swapcontext(保存当前, 恢复目标);
if (是首次执行新协程?) then (是)
:执行makecontext设置的函数;
:执行用户代码;
else (否)
:从swapcontext恢复点继续;
:执行用户代码;
endif
:调用coroutine_yield();
:保存上下文到当前协程;
:从调度器获取下一个协程;
:恢复下一个协程的上下文;
stop
@enduml
协程调度时序图
@startuml Coroutine Sequence Diagram
participant Main
participant Scheduler
participant Coroutine1
participant Coroutine2
Main->Scheduler: 初始化
Main->Scheduler: 创建协程1
Main->Scheduler: 创建协程2
Main->Scheduler: 启动调度
alt 首次调度
Scheduler->Coroutine1: 切换到协程1
Coroutine1->Coroutine1: 执行任务
Coroutine1->Scheduler: 调用coroutine_yield()
Scheduler->Coroutine1: 保存上下文
end
alt 第二次调度
Scheduler->Coroutine2: 切换到协程2
Coroutine2->Coroutine2: 执行任务
Coroutine2->Scheduler: 调用coroutine_yield()
Scheduler->Coroutine2: 保存上下文
end
loop 循环调度
Scheduler->Coroutine1: 恢复协程1
Coroutine1->Coroutine1: 继续执行
Coroutine1->Scheduler: 调用coroutine_yield()
Scheduler->Coroutine2: 恢复协程2
Coroutine2->Coroutine2: 继续执行
Coroutine2->Scheduler: 调用coroutine_yield()
end
@enduml
协程状态机
@startuml Coroutine State Diagram
[*] --> READY : 创建协程
READY --> RUNNING : coroutine_resume()
RUNNING --> SUSPENDED : coroutine_yield()
RUNNING --> TERMINATED : 协程函数返回
SUSPENDED --> RUNNING : coroutine_resume()
TERMINATED --> [*] : 资源回收
@enduml
上面的文档需要配置plantuml插件,下面是导出为png图片之后的效果:
ucontext.h 是 C 语言中用于实现用户级上下文切换的头文件,主要提供了创建和管理协程(或称为用户级线程)的机制。它允许程序在不同的执行上下文之间切换,而不需要经过内核,因此上下文切换的开销较小。 由于不需要写x86汇编,适合应用开发程序员做一些轻量级的切换调度。
主要功能和数据结构
ucontext.h 定义了以下关键数据结构和函数:
数据结构:
ucontext_t:表示一个用户级执行上下文,包含寄存器状态、栈指针、程序计数器等信息
sigset_t:信号掩码,用于指定在上下文中阻塞的信号集
核心函数:
getcontext(ucontext_t *ucp):获取当前执行上下文并存储到 ucp 中
setcontext(const ucontext_t *ucp):恢复 ucp 所保存的上下文并继续执行
makecontext(ucontext_t *ucp, void (*func)(), int argc, …):修改上下文 ucp,使其在恢复时执行指定函数 func
swapcontext(ucontext_t *oucp, const ucontext_t *ucp):保存当前上下文到 oucp,然后恢复 ucp 上下文
工作原理
使用 ucontext.h 实现协程的基本流程是:
创建一个 ucontext_t 结构体并初始化
设置上下文的栈空间(uc_stack 字段)
使用 makecontext() 指定该上下文恢复时执行的函数
使用 swapcontext() 或 setcontext() 切换到该上下文
上代码:
coroutine.h
#ifndef COROUTINE_H
#define COROUTINE_H
#include <ucontext.h>
#include <stddef.h>
// 协程状态
typedef enum {
COROUTINE_READY, // 就绪状态
COROUTINE_RUNNING, // 运行状态
COROUTINE_SUSPENDED, // 暂停状态
COROUTINE_TERMINATED // 终止状态
} CoroutineState;
// 协程函数类型
typedef void (*coroutine_func_t)(void*);
// 协程控制块
typedef struct Coroutine {
ucontext_t context; // 协程上下文
CoroutineState state; // 协程状态
coroutine_func_t func; // 协程函数
void* arg; // 协程参数
char* stack; // 协程栈
size_t stack_size; // 栈大小
struct Coroutine* next; // 指向下一个协程的指针
} Coroutine;
// 初始化协程库
extern void coroutine_init(void);
// 创建一个新协程
extern Coroutine* coroutine_create(coroutine_func_t func, void* arg, size_t stack_size);
// 让出CPU,暂停当前协程
extern void coroutine_yield(void);
// 恢复执行指定协程
extern void coroutine_resume(Coroutine* co);
// 结束当前协程
extern void coroutine_exit(void);
// 运行协程调度器
extern void coroutine_scheduler(void);
#endif // COROUTINE_H
coroutine.c
#include "coroutine.h"
#include <stdlib.h>
#include <stdio.h>
static Coroutine* current_coroutine = NULL; // 当前正在运行的协程
static Coroutine* coroutine_list = NULL; // 协程链表头
static ucontext_t main_context; // 主协程上下文
static ucontext_t scheduler_context; // 调度器上下文
// 初始化协程库
void coroutine_init(void) {
coroutine_list = NULL;
current_coroutine = NULL;
}
// 协程入口函数
static void coroutine_entry(void) {
// 执行协程函数
current_coroutine->func(current_coroutine->arg);
// 协程函数返回后,标记为终止状态
current_coroutine->state = COROUTINE_TERMINATED;
// 返回调度器
coroutine_yield();
}
// 创建一个新协程
Coroutine* coroutine_create(coroutine_func_t func, void* arg, size_t stack_size) {
Coroutine* co = (Coroutine*)malloc(sizeof(Coroutine));
if (!co) {
perror("Failed to allocate coroutine");
return NULL;
}
// 初始化协程控制块
co->func = func;
co->arg = arg;
co->state = COROUTINE_READY;
co->stack_size = stack_size;
co->stack = (char*)malloc(stack_size);
if (!co->stack) {
perror("Failed to allocate stack");
free(co);
return NULL;
}
// 获取当前上下文
getcontext(&co->context);
// 设置上下文的栈
co->context.uc_stack.ss_sp = co->stack;
co->context.uc_stack.ss_size = stack_size;
co->context.uc_stack.ss_flags = 0;
co->context.uc_link = &scheduler_context;
// 设置上下文的执行函数
makecontext(&co->context, (void (*)(void))coroutine_entry, 0);
// 将协程添加到链表
co->next = coroutine_list;
coroutine_list = co;
return co;
}
// 让出CPU,暂停当前协程
void coroutine_yield(void) {
if (!current_coroutine) return;
// 保存当前状态
if (current_coroutine->state == COROUTINE_RUNNING) {
current_coroutine->state = COROUTINE_SUSPENDED;
}
// 切换到调度器
swapcontext(¤t_coroutine->context, &scheduler_context);
}
// 恢复执行指定协程
void coroutine_resume(Coroutine* co) {
if (!co || co->state == COROUTINE_TERMINATED) return;
Coroutine* prev = current_coroutine;
current_coroutine = co;
if (co->state == COROUTINE_READY) {
co->state = COROUTINE_RUNNING;
// 首次执行协程
swapcontext(&scheduler_context, &co->context);
} else if (co->state == COROUTINE_SUSPENDED) {
co->state = COROUTINE_RUNNING;
// 恢复执行协程
swapcontext(&scheduler_context, &co->context);
}
current_coroutine = prev;
}
// 结束当前协程
void coroutine_exit(void) {
if (!current_coroutine) return;
// 标记为终止状态
current_coroutine->state = COROUTINE_TERMINATED;
// 切换到调度器
swapcontext(¤t_coroutine->context, &scheduler_context);
}
// 运行协程调度器
void coroutine_scheduler(void) {
// 保存主上下文
getcontext(&main_context);
while (1) {
// 查找下一个可运行的协程
Coroutine* co = coroutine_list;
Coroutine* prev = NULL;
while (co) {
if (co->state == COROUTINE_READY || co->state == COROUTINE_SUSPENDED) {
// 恢复执行这个协程
coroutine_resume(co);
// 检查协程是否已终止
if (co->state == COROUTINE_TERMINATED) {
// 从链表中移除
if (prev) {
prev->next = co->next;
} else {
coroutine_list = co->next;
}
// 释放资源
free(co->stack);
Coroutine* temp = co;
co = co->next;
free(temp);
continue;
}
}
prev = co;
co = co->next;
}
// 如果没有可运行的协程,退出调度器
if (!coroutine_list) {
break;
}
}
}
main.c
#include "coroutine.h"
#include <stdio.h>
#include <unistd.h>
// 协程函数1
void task1(void* arg) {
int count = 0;
while (1) {
printf("Task 1: Count = %d\n", count++);
sleep(1); // 模拟工作1秒
coroutine_yield(); // 让出CPU
}
}
// 协程函数2
void task2(void* arg) {
char* msg = (char*)arg;
while (1) {
printf("Task 2: %s\n", msg);
sleep(2); // 模拟工作2秒
coroutine_yield(); // 让出CPU
}
}
int main(int argc, char **argv) {
// 初始化协程库
coroutine_init();
// 创建两个协程
coroutine_create(task1, NULL, 16384);
coroutine_create(task2, "Hello i am task 2", 16384);
// 启动调度器
coroutine_scheduler();
printf("All coroutines have terminated.\n");
return 0;
}
makefile
root@iZwz99zhkxxl5h6ecbm2xwZ:~/coroutine# cat Makefile
all:
gcc -o coroutine main.c coroutine.c -Wall -O2
clean:
rm -rf coroutine
root@iZwz99zhkxxl5h6ecbm2xwZ:~/coroutine#
test:
root@iZwz99zhkxxl5h6ecbm2xwZ:~/coroutine# make
gcc -o coroutine main.c coroutine.c -Wall -O2
root@iZwz99zhkxxl5h6ecbm2xwZ:~/coroutine# ./coroutine
Task 2: Hello i am task 2
Task 1: Count = 0
Task 2: Hello i am task 2
Task 1: Count = 1
Task 2: Hello i am task 2
^C
root@iZwz99zhkxxl5h6ecbm2xwZ:~/coroutine#


















 1443
1443

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











