






 本文介绍了迁移学习中两种关键方法——相对熵KL散度和最大均值差异MMD,阐述了它们如何衡量源域和目标域的分布差异,以及KL散度在模型预测中的应用。核函数在高维空间中的作用被用来比较分布,支持向量机的核函数映射原理得以展示。
本文介绍了迁移学习中两种关键方法——相对熵KL散度和最大均值差异MMD,阐述了它们如何衡量源域和目标域的分布差异,以及KL散度在模型预测中的应用。核函数在高维空间中的作用被用来比较分布,支持向量机的核函数映射原理得以展示。
为什么要衡量分布之间的差异,因为我们想要减少源域和目标域的差异,这是迁移学习中基于特征的核心思想。
迁移学习
华仔,公众号:算法设计与优化学习笔记2—迁移学习
这里介绍两种不同的方法:相对熵KL散度、最大均值差异MMD
一、相对熵KL散度
KL散度(Kullback-Leibler divergence)是衡量两个概率分布P和Q差异的一种方式,那为什么要说信息熵和交叉熵呢,因为他们三个之间有关系:
KL散度=交叉熵-信息熵(这个公式很重要,帮你理清他们的关系)
那我们来分别看一下交叉熵和信息熵:
信息熵就是客观的信息量的期望,信息量就是事情发生概率P(x)的倒数即1/P(x),因为事情发生概率越大,信息量就越小,就好比人们都知道的事情新闻去报道它的可能性就变低了,因为它包含的信息量太少了。那么对信息量求期望,就得到了著名的信息熵公式,如下所示:(取log方便后续运算)
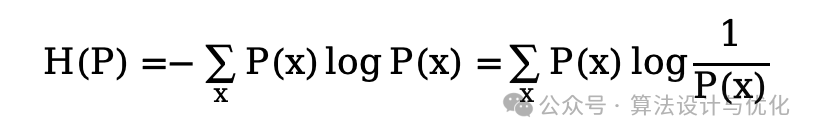
交叉熵就是主观的信息量的期望,主观的信息量就是你认为这个事情的发生概率Q(x),跟事情客观发生概率P(x)是不一样的,如果你认为的和客观的一样,那交叉熵就等于信息熵。那么将上式客观的信息量1/P(x)替代为主观的信息量1/Q(x)就得到了交叉熵公式,如下所示:
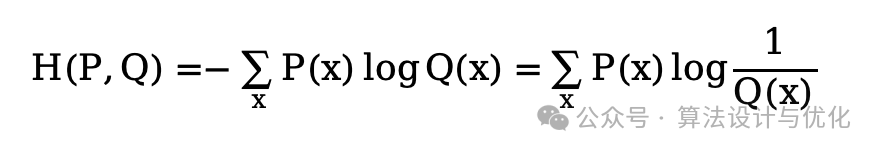
相对熵KL散度就是主观的信息量的期望减去客观的信息量的期望,我们就可以知道我们主观认为的和客观的相差多少,如下所示:
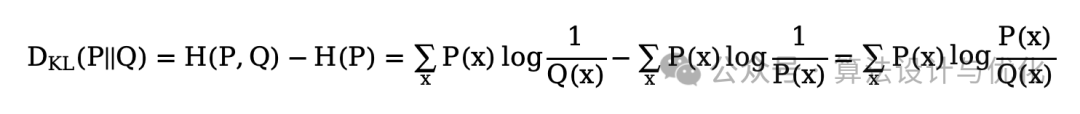
所以说KL散度就可以帮助我们来衡量一个模型预测的结果和真实结果之间的差距,但又由于真实结果是固定的常数,因此我们就不需要再去计算信息熵了,直接用交叉熵作为分类模型的损失函数即可,而KL散度则通常用于迁移学习。
二、最大均值差异MMD
最大均值差异MMD(Maximum Mean Discrepancy)是一个比较常用的分布差异度量指标,其核心思想在于如果两个分布相同,那么其在高维空间的均值分布也应该相同。那么两个分布越相似,差异就越小。
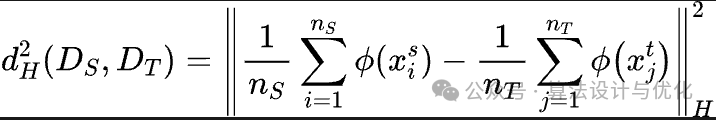
公式花里胡哨,什么意思呢?就是两个分布我不能直接比较,那我就把它俩都通过一个核函数映射到另一个空间再进行比较。SVM支持向量机对于线性不可分的数据就是通过核函数将数据映射到高维空间再划分。参照下图,在左侧平面中我无法有效划分两种数据点,那我把它映射到三维就可以找到一个平面进行划分了。右侧的俯视图其实就是左侧的平面图,这说明数据的相对位置其实没有改变。再往高维走,映射到4维空间、5维、乃至无限维(再生核希尔伯特空间)也是一样的道理。
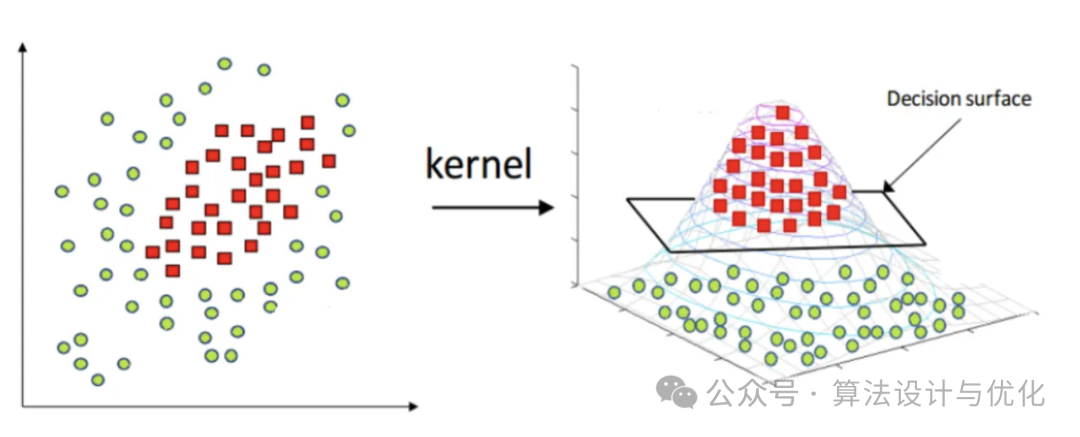
核函数就是一个复杂的函数,可以表征高维空间的分布,那我便不需要知道具体的高维空间是如何分布的,只需要对比两个分布对应的核函数的值即可。















 662
662

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









