







大部分内容源于https://segmentfault.com/a/1190000038173886, 本人手敲一边加强印象方便复习
消息系统的作用
解耦
冗余
扩展性
灵活性(峰值处理
可恢复
顺序保证
缓冲
异步
- 解耦:扩展两边处理过程,只需要让他们遵守约束即可
- 冗余:持久化数据:规避丢失风险。采用 插入-获取-删除范式明确指出消息被处理完毕
- 扩展性:解耦处理过程,容易扩展处理过程增大消息处理频率
- 灵活性(峰值处理:访问激增情况不常见,无需投入过多标准资源。使用消息队列顶住访问压力
- 可恢复:系统失效时仍可保证队列消息在系统恢复后处理
- 顺序保证:kafka保证partition内消息有序
- 缓冲:控制和优化 数据经过系统的速度,解决生产、消费速度不一致的问题
- 异步:允许用户把一个或若干个消息放入队列,且不立即被处理
架构
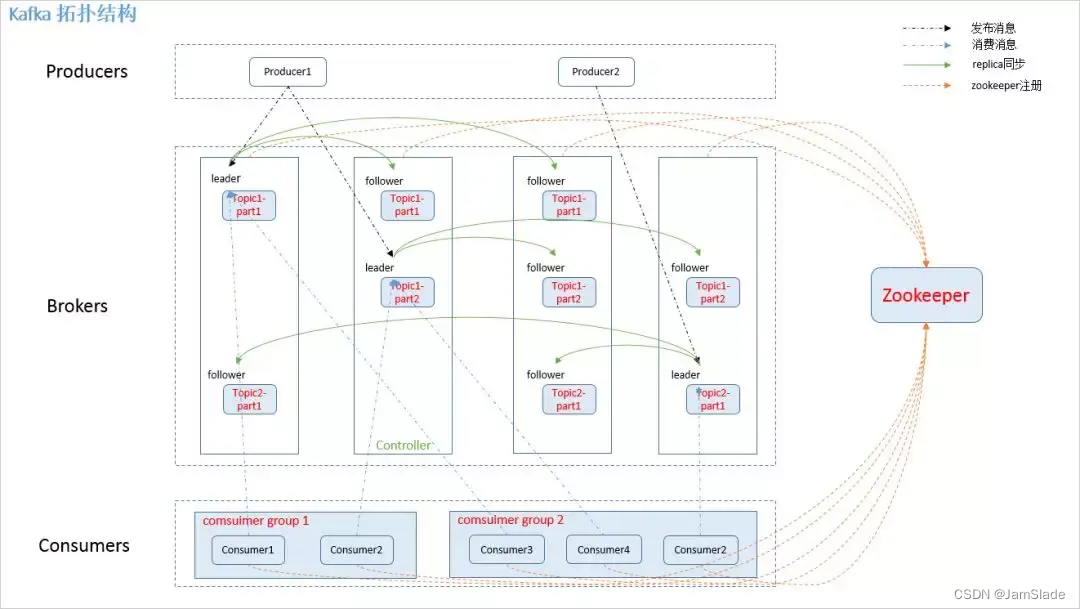
- producer,消息生产者
- broker:kafka集群的服务器
- topic:消息的类别
- partition:kafka分配单位,一个topic包含一个或多个partition
- consumer:消息消费者,终端或服务
- comsumer group:
high-level consumer API 中,每个 consumer 都属于一个 consumer group,每条消息只能被 consumer group 中的一个 Consumer 消费,但可以被多个 consumer group 消费。 - replica:partition副本
- leader:特殊的replica,producer和consumer只和leader交互
- follower:除了leader的replica都为follwer,复制数据
- controller:服务器:用于leader选举和failover
- zookepper,存储集群meta信息
发布消息
producer用push发布到broker,消息被append到partition,顺序写磁盘
消息路由
//构造函数
public ProducerRecord(String topic, Integer partition, Long timestamp, K key, V value) {
if (topic == null)
throw new IllegalArgumentException("Topic cannot be null");
if (timestamp != null && timestamp < 0)
throw new IllegalArgumentException("Invalid timestamp " + timestamp);
this.topic = topic;
this.partition = partition;
this.key = key;
this.value = value;
this.timestamp = timestamp;
}
private int partition(ProducerRecord<K, V> record, byte[] serializedKey , byte[] serializedValue, Cluster cluster) {
Integer partition = record.partition();
if (partition != null) {//指定了 partition 则直接使用
List<PartitionInfo> partitions = cluster.partitionsForTopic(record.topic());
int lastPartition = partitions.size() - 1;
if (partition < 0 || partition > lastPartition) {
throw new IllegalArgumentException(String.format("Invalid partition given with record: %d is not in the range [0...%d].", partition, lastPartition));
}
return partition;
}//否则使用 key 计算
return this.partitioner.partition(record.topic(), record.key(), serializedKey, record.value(), serializedValue, cluster);
}
public int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster) {
List<PartitionInfo> partitions = cluster.partitionsForTopic(topic);
int numPartitions = partitions.size();
if (keyBytes == null) {//轮询
int nextValue = counter.getAndIncrement();
List<PartitionInfo> availablePartitions = cluster.availablePartitionsForTopic(topic);
if (availablePartitions.size() > 0) {
int part = DefaultPartitioner.toPositive(nextValue) % availablePartitions.size();
return availablePartitions.get(part).partition();
} else {
return DefaultPartitioner.toPositive(nextValue) % numPartitions;
}
} else {
//对 keyBytes 进行 hash 选出一个 patition
return DefaultPartitioner.toPositive(Utils.murmur2(keyBytes)) % numPartitions;
}
}
- 指定partition直接用
- 未指定partition但指定了key,对key进行hash得到partition
- 都未指定,使用轮询
写入流程

- producer从zk的/brokers/…/state找到leader
- producer发消息给leader
- leader把消息写入log
- follower从leader拉取消息写入log后发送ACK给leader
- leader收到所有replica的ACK后,增加high watermark(位置信息,即位移(offset))给producer发送ack
投递保证
① At most once 消息可能会丢,但绝不会重复传递
② At least one 消息绝不会丢,但可能会重复传递
③ Exactly once 每条消息肯定会被传输一次且仅传输一次,很多时候这是用户想要的
默认 at least one
接收消息的行为
- comsumer从broker读取消息后,可以选择commit或处理消息
- 如果commit
- zookeeper存在comsumer在partition下读取消息的offset
- comsumer下次读取partition从下一条开始读取
- 未commit
- 下次读取位置和上次commit后开始位置相同
- 如果commit
at most once
读完消息先commit再处理消息。
若commit后未处理消息系统崩坏,下次重新开始工作无法读到已提交但未处理的消息
At least once
读完消息先处理再commit消费状态(保存offset)
若处理消息后未commit系统崩坏,重新工作的时候会处理未commit的消息(处理两次)
Exactly once 两阶段提交
协调offset和实际操作的输出。但由于许多输出系统不支持两阶段提交,更为通用的方式是将offset和操作输入存在同一个地方
- consumer拿到数据后可能把数据放到HDFS
- 最新的offset和数据一起写到HDFS
- 保证offset更新和数据输出同时完成
(目前就high level API而言,offset是存于Zookeeper中的,无法存于HDFS,而low level API的offset是由自己去维护的,可以将之存于HDFS中)。
消息保存
topic分为多个partition,每个partition对应一个文件夹
无论消息是否被消费,kafka 都会保留所有消息。有两种策略可以删除旧数据
- 基于时间:log.retention.hours=168
- 基于大小:log.retention.bytes=1073741824
log.cleanup.policy=delete启用删除策略
直接删除,删除后的消息不可恢复。可配置以下两个策略:
清理超过指定时间清理:
log.retention.hours=16
超过指定大小后,删除旧的消息:
log.retention.bytes=1073741824

topic的创造
- controller在ZK的/brokers/topics 节点上注册 watcher
,topic被创建的时候,controller 会通过 watch 得到该 topic 的 partition/replica 分配。 - controller从 /brokers/ids 读取当前所有可用的 broker 列表,对于 set_p 中的每一个 partition:
- 分配给partition的所有replica(称为AR)任选一个可用的broker作为leader并将AR设置为ISR
- 新的 leader 和 ISR 写入 /brokers/topics/[topic]/partitions/[partition]/state
- controller 通过 RPC 向相关的 broker 发送 LeaderAndISRRequest。
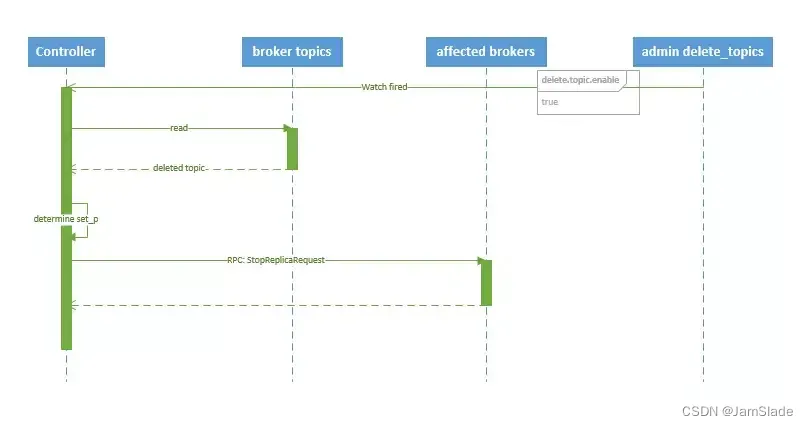
删除 topic 的序列
- controller 在 zooKeeper 的 /brokers/topics 节点上注册 watcher
- topic 被删除,则 controller 会通过 watch 得到该 topic 的 partition/replica 分配
- 若 delete.topic.enable=false,结束;反之controller 注册在 /admin/delete_topics 上的 watch 被 fire,controller 通过回调向对应的 broker 发送 StopReplicaRequest
kafka HA 高可用性
replica
同一个 partition 可能会有多个 replica —— erver.properties 配置中的 default.replication.factor=N
若没有replica,broker死机
- patition 的数据都不可被消费
- producer 也不能再将数据存于其上的 patition
引入replica,需要选取leader,leader与producer和consumer交互,其他replica与leader复制数据
分配规则
- 将所有 broker(假设共 n 个 broker)和待分配的 partition 排序
- 将第 i 个 partition 分配到第(i mod n)个 broker 上
- 将第 i 个 partition 的第 j 个 replica 分配到第((i + j) mode n)个 broker上
leader failover
partition 对应的 leader 宕机时,需要从 follower 中选举出新 leader
新的 leader 必须拥有旧 leader commit 过的所有消息
zookeeper 中(/brokers/…/state)动态维护了一个 ISR(in-sync replicas)。只有 ISR 里面的成员才能选为 leader。若有f个replica,partition可以保证f-1个replica失效情况下消息不丢失
failover方案
- 等待 ISR 中的任一个 replica 活过来,并选它作为 leader。可保障数据不丢失,但时间可能相对较长。
- 选择第一个活过来的 replica(不一定是 ISR 成员)作为 leader。无法保障数据不丢失,但相对不可用时间较短
多用第二种方式
broker failover
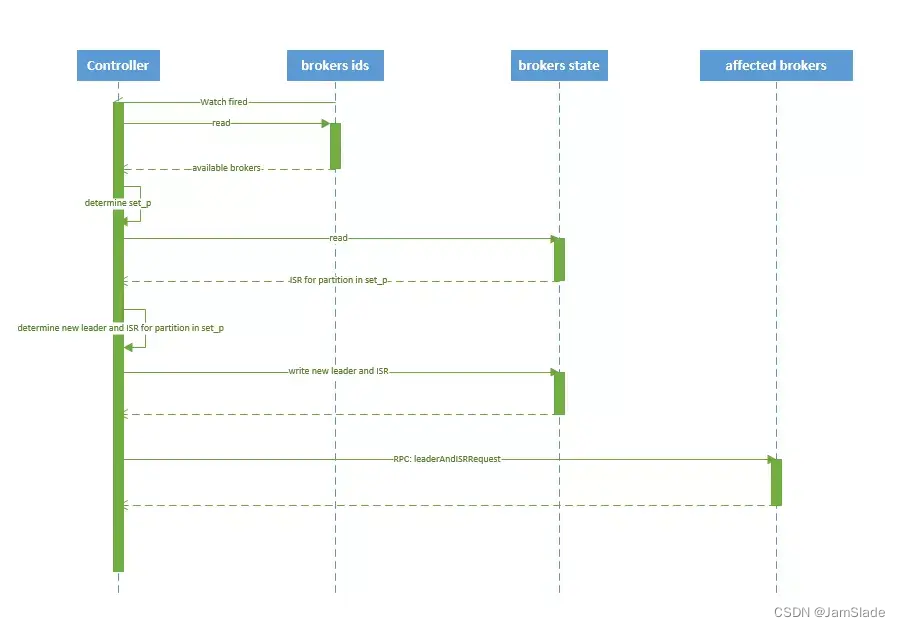
- controller在zookeeper的/brokers/ids/[brokerId] 节点注册 Watcher,当 broker 宕机时 zookeeper 会 fire watch
- controller从/brokers/ids 节点读取可用broker
- controller决定set_p,集合包含死机broker上所有partition
- 对set_p所有partition进行: 1. 读取/brokers/ids 节点读取可用broker的ISR 2. 决定新leader, 新leader ISR controller_epoch和leader_epoch信息写入state结点
- 通过RPC给broker发送 leaderAndISRRequest 命令
controller failover
controller 宕机时会触发 controller failover
- broker在zookeeper的controller节点注册watcher
- controller宕机时,zookeeper临时节点消失
- 所有存活broker收到fire通知
- 每个broker尝试创建新的controller path,其中一个竞选成功为controller
- 当选成功触发KafkaController.onControllerFailover
1. 读取并增加 Controller Epoch。
2. 在 reassignedPartitions Patch(/admin/reassign_partitions) 上注册 watcher。
3. 在 preferredReplicaElection Path(/admin/preferred_replica_election) 上注册 watcher。
4. 通过 partitionStateMachine 在 broker Topics Patch(/brokers/topics) 上注册 watcher。
5. 若 delete.topic.enable=true(默认值是 false),则 partitionStateMachine 在 Delete Topic Patch(/admin/delete_topics) 上注册 watcher。
6. 通过 replicaStateMachine在 Broker Ids Patch(/brokers/ids)上注册Watch。
7. 初始化 ControllerContext 对象,设置当前所有 topic,“活”着的 broker 列表,所有 partition 的 leader 及 ISR等。
8. 启动 replicaStateMachine 和 partitionStateMachine。
9. 将 brokerState 状态设置为 RunningAsController。
10. 将每个 partition 的 Leadership 信息发送给所有“活”着的 broker。
11. 若 auto.leader.rebalance.enable=true(默认值是true),则启动 partition-rebalance 线程。
12. 若 delete.topic.enable=true 且Delete Topic Patch(/admin/delete_topics)中有值,则删除相应的Topic。
消费
kafka 提供了两套 consumer API:
The high-level Consumer API
The SimpleConsumer API
consumer API
high-level提供kafka消费数据的抽象
- 提供了 consumer group 的语义
- 消息只能被group内一个consumer消费
- 消费的时候不关注offset
- 最后一个offset由zookeeper保存
使用high-level consumer API可以是多线程应用
if(消费线程 > partition){
部分线程收不到消息
}
if(消费线程 < partition){
有些线程收到多个partition消息
}
if(一个线程消费多个 patition){
无法保证收到消息的顺序
}
** SimpleConsumer API**
适用以下情况
- 多次读取一个消息
- 只消费一个 patition 中的部分消息
- 使用事务来保证一个消息仅被消费一次
partition, offset, broker, leader不透明,需要自己管理
- 追踪offset确定下一条消费的信息
- 找出每个partition的follower
- 处理leader变更
流程如下
- 查找到一个“活着”的 broker,并且找出每个 partition 的 leader
- 找到partition的follower
- 定义好请求,该请求应该能描述应用程序需要哪些数据
- fetch数据
- 识别leader变化并做出响应
consumer group
kafka分配单位是partition,consumer属于一个group
一个partition被一个group内的一个consumer消费(但是多个group可以同时消费这个partition)
实现离线处理与实时处理
- spark 实时处理
- hadoop 离线处理
消费方法
consumer用pull模式从broker读数据
push 模式很难适应消费速率不同的消费者
- 消息发送速率是由 broker 决定的
- 尽可能以最快速度传递消息
- 容易造成 consumer 来不及处理消息(拒绝服务、网络拥塞
pull模式,consumer根据自己的能力消费信息
pull的优点
- 简化broker设计
- consumer自主控制消费速率
- consumer自主控制消费方式 —— 批量/逐条
- 选择不同提交方式
消费者递送保证
consumer 设置为 autocommit,consumer 一旦读到数据立即自动 commit(Exactly once
实际使用过程中,并不是consumer读完消息就结束了,还需要进一步处理。
处理和commit顺序决定了 consumer delivery guarantee
- 先commit,后处理消息(At most once
- consumer 在 commit 后还没来得及处理消息就 crash
- 重新开始工作后就无法读到刚刚已提交而未处理的消息
- 先处理再commit( At least once
- 处理完消息之后 commit 之前 consumer crash
- 恢复工作:处理刚刚未 commit 的消息
- 两阶段提交
(offset 和操作输入存在同一个地方,会更简洁和通用)
(若不支持,consumer 拿到数据后可能把数据放到 HDFS,如果把最新的 offset 和数据本身一起写到 HDFS,那就可以保证数据的输出和 offset 的更新要么都完成,要么都不完成,间接实现 Exactly once) —— high-level API里面offset存于zookeeper中,无法存于HDFS,simple可以存于HDFS
consumer rebalance
触发机制
- consumer加入退出
- partition改变(broker 加入退出
算法如下
- 目标topic的partition排序,存于PT
- 选择consumer group下所有consumer排序, 存于CG
- N = ⌈ s i z e ( P T ) / s i z e ( C G ) ⌉ N = \lceil size(PT)/size(CG)\rceil N=⌈size(PT)/size(CG)⌉
- 对group内原本的分配partition解除关系
- 然后每N个partition分配给一个consumer
consumer调整了单个partition后,为了保证一致性,group内其他consumer也应触发balance
导致以下问题
herd effect
- broker,comsumer增减触发rebalance
split brain
- 每个consumer单独通过zk判断broker和consumer宕机,不同的consumer同时从zookeeper看到的view可能不一致 —— 导致不正确的rebalance
- 所有consumer不知道其他consumer的rebalance是否成功,导致kafka工作状态不正确
- 因此0.9开始使用中心coordinator空值rebalance,计划在consumer客户端分配方案















 918
918











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









