






原文:添加链接描述
总体介绍:
Image Captioning(图像描述)就是描述一张图里面的内容,最近几年比较突出的是一种利用LSTM(RNN)的方法。尽管LSTM有着出色的记忆能力并且能减轻梯度消失的问题,但是它太复杂并且必须按照时序来训练。作者提出了一种利用卷积来进行图像描述的方法来解决这个问题,并通过实验验证发现这种方法和LSTM相比更好。
RNN方法
在介绍RNN方法之前,先介绍一下RNN的Encoder-Decoder结构。在原始RNN结构中,输入和输出必须是等长的。而对于要解决的翻译等问题中,两种语言的长度往往是不同的,所以需要将其映射。Encoder-Decoder就解决了这个长度不一的问题,先把输入的单词序列进行one-hot,然后转为word embedding形式再输入到RNN网络。Encoder部分相当于编码,它把所有的输入“编码”成一个向量表示(也就是最后一个隐层状态 h n h_n hn),Decoder部分就是利用 h n h_n hn里的信息进行解码,最终输出单词序列。
然后介绍RNN方法,大致框图如下:

Encoder部分用的VGG16,也就是CNN来处理;Decoder部分则用的是LSTM。图中的
<
S
>
<S>
<S>是开始的标志,
<
E
>
<E>
<E>是结束的标志。
首先利用VGG16提取图像的特征,然后利用image embedding编码后输入到LSTM,记此时时间为T,并获得状态输出 h 0 h_0 h0。 h 0 h_0 h0作为输入传到下一个时刻T=1时的LSTM,然后将单词embedding后按顺序一个个地传进LSTM。每一步都会获得一个概率分布 p i , w ( y i ∣ I ) p_{i,w}(y_i|I) pi,w(yi∣I)(w是参数,I是输入图像),选择这个分布中概率最大的作为当前单词的输出,一直到结束标志出现或者达到了设定的最大句长。
对于
p
i
,
w
(
y
i
∣
I
)
p_{i,w}(y_i|I)
pi,w(yi∣I),
y
i
y_i
yi的获得与之前所有
y
<
i
y_{<i}
y<i单词有关,由于LSTM具有记忆性,可以认为
h
i
h_i
hi包含了这种依赖性。这个概率可以用下面的公式来计算:
p
i
,
w
(
y
i
∣
h
i
,
I
)
=
g
w
(
y
i
,
h
i
,
I
)
p_{i,w}(y_i|h_i,I)=g_w(y_i,h_i,I)
pi,w(yi∣hi,I)=gw(yi,hi,I)
g
w
g_w
gw可以是任何可微函数/深度网络。而
h
i
h_i
hi也与以前的状态、输入图像、单词输入有关(LSTM的性质):
h
i
=
f
w
(
h
i
−
1
,
y
i
−
1
,
I
)
h_i=f_w(h_{i-1},y_{i-1},I)
hi=fw(hi−1,yi−1,I)
word embedding和LSTM的参数w可以通过最小化训练数据的负对数似然来获得:
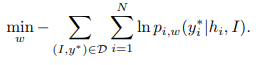
但为了避免更复杂的gradient flows(?),训练期间传给下一时序LSTM的单词用的是ground-truth
y
i
−
1
∗
y_{i-1}^*
yi−1∗而不是上一时序预测到的
y
i
−
1
y_{i-1}
yi−1。
h
i
=
f
w
(
h
i
−
1
,
y
i
−
1
∗
,
I
)
h_i=f_w(h_{i-1},y_{i-1}^*,I)
hi=fw(hi−1,yi−1∗,I)
这样虽然简化了gradient flows,但是很明显地导致了训练和测试时输入数据的不同。
RNN的不足:1.必须按时序来;2.分类准确率低;3.仍然存在梯度消失问题。
这部分可以参考《Show and Tell: A Neural Image Caption Generator》
论文:添加链接描述
Convolutional方法
作者提出的这种方法大致结构如下图:

输入输出和RNN一样,都进行了word embedding,但中间的LSTM部分换成了masked convolutions。
对于最后输出的概率分布
p
i
,
w
(
y
i
∣
I
)
p_{i,w}(y_i|I)
pi,w(yi∣I),这种方法也可以近似的表示为
p
i
,
w
(
y
i
∣
y
<
i
,
I
)
=
f
w
(
y
i
,
y
<
i
,
I
)
p_{i,w}(y_i|y_{<i},I)=f_w(y_i,y_{<i},I)
pi,w(yi∣y<i,I)=fw(yi,y<i,I)
而为了不让卷积操作使用当前单词之后的单词,使用masked convolutional层来只针对”过去“的单词。就好比图中输出
y
3
y_3
y3的卷积层,它的输入只能包括
y
1
∗
,
y
2
∗
y_1^*,y_2^*
y1∗,y2∗,后面的
y
4
∗
,
y
5
∗
y_4^*,y_5^*
y4∗,y5∗等都不能作为它的输入。这样做其实就是模仿LSTM(当然也是为了使得生成的句子更通顺),LSTM就是当前时序的输出只与前面的单词有关。
至于masked convolutions,作者提到他参考了《Conditional Image Generation with PixelCNN Decoders》中的结构,简单来说其实就是只保留卷积核中心点之前的像素信息。
整个实现过程和RNN其实差不多,训练期间输入的也是GT( f w ( y i , y < i ∗ , I ) f_w(y_i,y_{<i}^*,I) fw(yi,y<i∗,I))。由于在训练时GT是已知的,而且CNN模型不需要像RNN一样按时序来一个个预测,所以可以并行训练整个句子中的所有单词。
重点来了,具体结构见下面这张大图,假设GT为
y
1
∗
,
.
.
.
,
y
5
∗
=
"
a
,
w
o
m
a
n
,
i
s
,
p
l
a
y
i
n
g
,
t
e
n
n
i
s
"
y_1^*,..., y_5^∗ ="a, woman, is, playing, tennis"
y1∗,...,y5∗="a,woman,is,playing,tennis"。

先介绍四部分:
- Input Embedding。每个单词一开始是one-hot的,总共9221维(因为设定的单词集有9221个),然后进行embedding变成512维的向量,与RNN方法保持一致。
- Image Embedding。图像I经过VGG16提取其特征,然后经过dropout、ReLU、线性层最终获得一个512维的embedding。它与上面的input embedding共同作为输入传至CNN模型。
- CNN模型。这个CNN模型有三层masked convolutions,每一层卷积的padding都补0以保证最后输出也是512维。激活函数用的是GLU,后续过程还使用了参数归一化、dropout等。Masked convolutions的接受域为5,设置句长最大为15。
- 分类层。使用的是一个线性层来将最终输出的512维向量转为256维,然后通过全连接上采样到9221维,其实就是one-hot型,再softmax一下就可以获得单词的概率。
一些训练细节:利用交叉熵损失来训练CNN和embedding层;微调VGG16训练8epochs;初始学习率是 5 e − 5 5e^{-5} 5e−5,每隔15个epochs将其除以10,总共训练30个epochs。
接下来是我对这个模型的理解(先不考虑图中左上角那个attention部分):
- 原图最开始是224x224x3——经过VGG16后变成4096维——然后经过dropout、ReLU、线性层变成512维——维度扩充变成512x15(因为设定N=15)
- 句子这边,先是给一个开始符号 < S > <S> <S>,然后对每个one-hot的9221维单词进行word embedding,获得512维的向量,同理因为句长维15,所以维度也扩充维512x15
- 把1、2的结果连接,维度是1024x15
- 把3的连接结果作为输入传至第一个masked convolution,依次经过dropout、卷积、GLU、attention(后续会细讲)
- 3的结果经过线性变化后再加上4的结果
- 5的结果作为第二个masked convolution的输入,与第4步相似,也经过dropout、卷积、GLU、attention
- 把5的结果直接和6的结果相加,并类似6、7步循环一次,最终获得512x15的向量
- 三层masked convolution后,经过线性变换变成256x15维,然后利用全连接上采样到9221x15维,最终经过softmax获得15个单词的概率分布
然后是Attention部分,每个单词的attention部分的参数都是不一样的,并且在每一层masked convolution中都有使用,是一个512维的向量。假设参数是7x7的,因为传给Attention的图像特征维数是7x7x512。它的大致结构如下图:

也可以用下面这个公式表示:
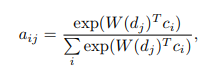
d
j
d_j
dj是第j个单词的GLU之后的输出,W是
d
j
d_j
dj的一个线性变换,
c
i
c_i
ci是从VGG16后得到的7x7x512的特征,
a
i
j
a_{ij}
aij表示Attention的参数。最终可以把
a
i
j
a_{ij}
aij与
c
i
c_i
ci相乘的和作为Attention的输出。
实验分析
这部分做的实验有点多,我选择性地放一部分。作者是在MSCOCO上进行实验的。

上面这个表格是作者在利用beam search的情况下的表现,可以看出在beam size为3时,这些评价标准都达到了最好的。
beam search 简单理解一下就是在测试的时候,第一个时间点输出top-k个候选词,然后分别输入到第二个时间点,得到第一个和第二个词的候选词组合,再选top-k,以此迭代。

这张表也能说明性能不错,c5是指这些图的参考描述有5种。


上面两张图是一些实例,可看出分成了7x7格,attention对于突出的事物比较关注,在预测一些”a, of ,on“等单词的时候是均匀的。
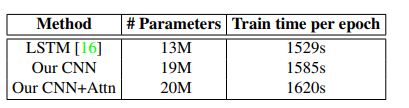
这张表是作者想说明他的方法训练每个参数所需要的时间比LSTM的方法要好。
然后作者将Attention机制撤除来和LSTM方法比较性能,因为LSTM方法没有使用空间图像特征。

这张图作者想表示,虽然CNN的损失比较高(a图可见),但概率分布中并不会产生峰值(b图),作者认为对于图像描述来说多样的预测并不坏(??!!);然后c图可以看出CNN方法的准确率是更高的。
后面还有图表示RNN/LSTM方法梯度消失问题比CNN方法要严重,以及一些相关工作。
讨论:(这些问题来源于网上)
1.解决了什么问题?
图像描述
2.提出了怎样的方法?
masked convolutions来代替原来的RNN/LSTM
3为什么会提出这个方法?
RNN方法要按照时序来,训练有点耗时;准确率不高;仍存在梯度消失问题。
4.设计了怎样的模型?
VGG16+masked convolutions+attention
5建立在什么样的假设上?
我记得的好像只有一个attention的参数为7x7维
6.这篇文章的关键点是什么?
masked convolutions来代替LSTM的方法是首次提出,因为这种需要记忆的网络往往想的都是RNN/LSTM这种有记忆单元的网络,如果用CNN的方法的话就会简单很多,并且可以并行。
7.贡献是什么?
如6,启发了可以用CNN来做一些需要按照时序来的东西
8.如何通过这个模型验证了作者所提出的观点?
Masked convolutions通过改变卷积核里面的数,就能做到当前预测只与”过去“的单词有关。
9.这个模型为什么能work?
@_@ 这个问题有点难,应该跟8差不多。















 250
250











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









