







作者丨崔权
学校丨早稻田大学硕士生
研究方向丨深度学习,计算机视觉
知乎专栏丨サイ桑的炼丹炉
前言
由于最近在做一个 Image Caption 的任务,读了一些最新的论文,把 CVPR2017 里比较中规中矩的 Image Caption 论文给拿出来总结一下。
说中规中矩是因为有一些 Caption 的论文做的方向比较偏,比如有一篇叫做 StyleNet,生成一些具有特定风格的描述,比如幽默风趣的 caption。而这篇总结里挑出来的论文都是在 MSCOCO 的 caption 任务上取得了不错效果的。
没有接触过 Image Caption 的同学这里有之前我在给研究生新生介绍 Image Caption 时用的 slides,Introduction of Image Caption[1]。没有什么文字,都是直观上的图片解释。
一共四篇论文,列表如下:
1. SCA-CNN: Spatial and Channel-wise Attention in Convolutional Networks for Image Captioning
2. Knowing When to Look: Adaptive Attention via A Visual Sentinel for Image Captioning
3. Skeleton Key: Image Captioning by Skeleton-Attribute Decomposition
4. Deep Reinforcement Learning-based Image Captioning with Embedding Reward
SCA-CNN: Spatial and Channel-wise Attention in Convolutional Networks for Image Captioning
由于这篇文章应该是效果最好的,所以放在最前面,如果对 encoder-decoder 模型不熟悉可以先看第二篇,第二篇基于的是传统的 visual attention 方法。
这篇论文出自于腾讯 AI Lab,文章一开始就肯定了 visual attention 在 image caption 中起到的重要作用,并且指出其原因主要是人类的视觉系统在进行相关任务时并不是处理一整张图片而是根据需要每次处理图片的 selective part,这和 attention机制想要模拟的过程是相同的。
这篇文章使用的还是传统的 CNN-RNN 模型,也称为 Encoder-Decoder 模型,但是文章指出,在之前别人的研究中使用的 attention 模型仅仅通过空间 attention 权重对上下文语义和 conv layer 输出的最后的 feature map 进行了映射,在 CNN 环节中并没有进行 attention 的相关操作。
在这篇文章中,作者们充分利用了 CNN 的三个特性,来提出一种新的 attention 机制。
具体来说,这是一种 spatial and channel-wise 的 attention 机制,这种 attention 机制学习的是多层 3D-feature map 中的每一个 feature 与 hidden state 之间的联系,也就是在 CNN 中引入 attention,而不是单单使用 CNN 部分的输出。
结合下图阐述两点 SCA 的 motivation:
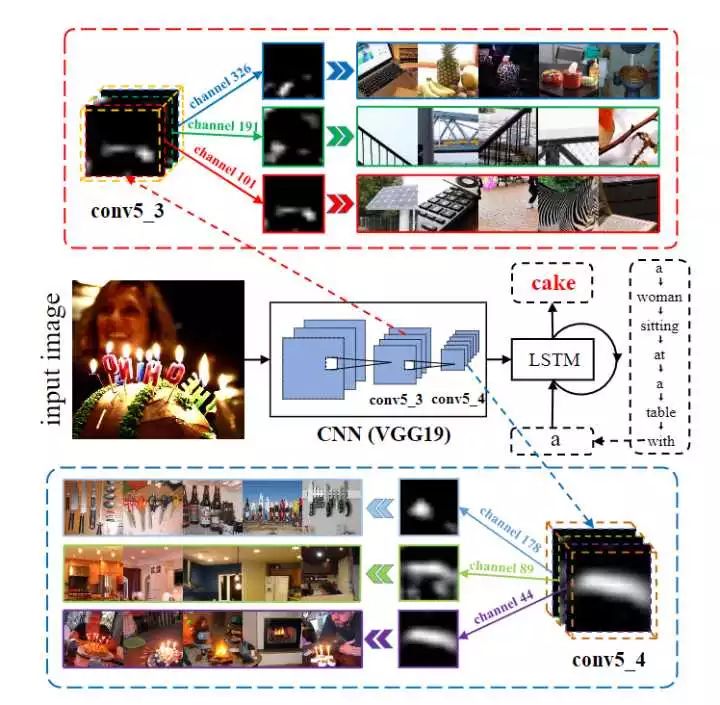
因为一张 channel-wise的feature map 本质上就是一个对应 filter 产生的 detector response map(feature map 中 element 较大的地方说明 response 大,也就是该处含有某种 semantic attribute,比如眼睛、鼻子等),那么基于 channel-wise 的 attention 机制就可以被视为是一个根据上下文语义选取相关语义特征的过程。
比如图中的例子,当我想预测 cake 这个单词时,channel-wise attention 就会给含有蛋糕、火焰、灯光和蜡烛形状物体的 feature map 分配更大的权重。
由于一张 feature map 依赖于前层的 feature map 们,一个很自然的想法就是对多层 feature map 使用 attention 机制,以便能够获得多层语义抽象概念。
比如,在前层中对 feature map 中含有的较低级的 semantic attributes,例如圆柱体(蛋糕的形状)、阵列(蜡烛的排放),赋予更大的权重,对于 cake 这个单词的预测是很有益的。 SCA-CNN 的大概运作方式如图:
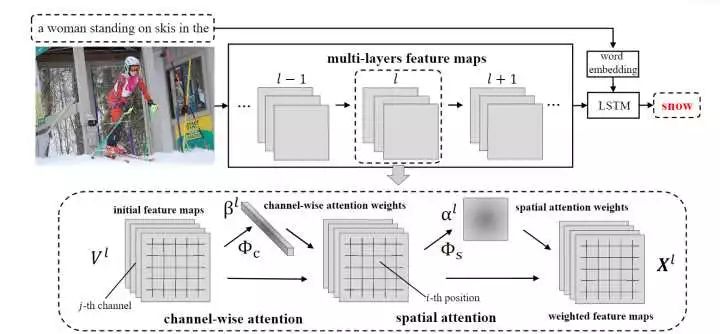
对第 l 层来说,未进行 attention 的 feature map![]() 是第(l-1)卷积层的输出,网络首先通过 channel-wise attention 函数
是第(l-1)卷积层的输出,网络首先通过 channel-wise attention 函数![]() 来计算 channel-wise attention 权重
来计算 channel-wise attention 权重
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









