









constexpr表达式是指值不会改变并且在编译过程就能得到计算结果的表达式。声明为constexpr的变量一定是一个const变量,而且必须用常量表达式初始化:
constexpr int mf = 20; //20是常量表达式
constexpr int limit = mf + 1; // mf + 1是常量表达式
constexpr int sz = size(); //之后当size是一个constexpr函数时才是一条正确的声明语句constexpr 变量
必须明确一点,在constexpr声明中如果定义了一个指针,限定符conxtexpr仅对指针有效,与指针所指的对象无关。
const int*p = nullptr; //p是一个指向整形常量的指针
constexpr int* q = nullptr; //q是一个指向整数的常量指针p是一个指向常量的指针,q是一个常量指针,其中的关键在于constexpr把它所定义的对象置为了顶层const。
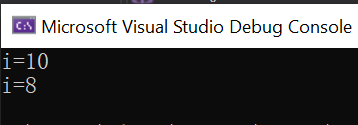
例在微软编译器上:
#include <iostream>
int main()
{
int i = 10;
int j = 100;
std::cout << "i=" << i << std::endl;
constexpr int* p = &i;
*p = 8;
std::cout << "i=" << i << std::endl;
//p = &j; //error
return 0;
}结果如下:
使用GNU gcc编译器时,constexpr指针所指变量必须是全局变量或者static变量(既存储在静态数据区的变量)。
#include <iostream>
int main()
{
static int bufSize = 512;
std::cout << "bufSize=" << bufSize << std::endl;
constexpr int* ptr = &bufSize;
*ptr = 1024;
std::cout << "bufSize=" << bufSize << std::endl;
return 0;
}ps:全局变量和局部变量的存储区域不同,全局变量存放在静态数据区,局部变量存放在栈区。但还有一个小点就是存放在静态数据区的变量是由低地址向高地址存放的,但存放在栈区的变量却是由高地址向低地址存放的,存放在静态数据区的还有静态局部变量和静态全局变量。
constexpr int ver = 4;switch...case tag中,这个ver变量可以作为tag;
#include <iostream>
int main(void)
{
constexpr int ver = 4;
int v = 4;
switch(v)
{
case ver:
std::cout << "ver is 4" << std::endl;
break;
default:
std::cout << "ver is default" << std::endl;
}
}
constexpr int size = 10; size可以用在需要编译时就能确定的代码中:
#include <iostream>
#include <array>
int main(void)
{
constexpr int size = 10;
std::array<int, size> arr{1, 2, 3, 4, 5, 6, 7, 8, 9, 0};
for(const auto i : arr)
{
std::cout << i << ' ';
}
}
constexpr定义的变量值必须由常量表达式初始化;,constexpr是一个加强版的const,它不仅要求常量表达式是常量,并且要求是一个编译阶段就能够确定其值的常量。
#include <iostream>
int main(void)
{
int x = 42;
const int size = x;
int buffer[size] = {};//clang: error: variable-sized object may not be initialized
}上述代码虽然size初始化编译成功, 但是编译器并不一定把它作为一个编译期需要确定的值,所在在GCC上能够编译通过,在clang和MSVC上编译失败;如果把const替换为constexpr,会有不
同的情况发生:
#include <iostream>
int main(void)
{
int x = 42;
constexpr int size = x;//error: constexpr variable 'size' must be initialized by a constant expression
int buffer[size] = {};
}constexpr支持声明浮点数类型的常量表达式而且标准还规定其精度必须至少和运行时的精度相同,例如:
#include <iostream>
constexpr double sum(double d)
{
return d > 0 ? d + sum(d - 1) : 0;
}
int main(void)
{
constexpr double d = sum(5);
std::cout << d;
}constexpr的inline属性
在C++17标准中,constexpr声明静态成员变量时,也被赋予了该变量的内联属性。
class X
{
public:
static constexpr int num{ 5 };
};以上代码从C++17开始等价于:
class X
{
public:
inline static constexpr int num{ 5 };
};在这里X::num既是申明又是定义;可以通过如下代码来测试:
#include <iostream>
class X
{
public:
static constexpr int num{ 5 };
};
int main()
{
auto* ptr = &X::num;//这里取地址符需要有变量的定义
std::cout << *ptr << std::endl;
}if constexpr
1.if constexpr的条件必须是编译期能确定结果的常量表达式。
2.条件结果一旦确定,编译器将只编译符合条件的代码块。
详细请见编译时期if
constexpr 函数
constexpr还能定义一个常量表达式函数,即constexpr函数,常量表达式函数的返回值可以在编译
阶段就计算出来。不过在定义常量表示函数的时候,我们会遇到更多的约束规则[C++14]:
1.函数体允许声明变量,除了没有初始化、static和thread_local变量。
2.函数允许出现if和switch语句,不能使用goto语句。
3.函数允许所有的循环语句,包括for、while、do-while。
4.函数可以修改生命周期和常量表达式相同的对象。
5.函数的返回值可以声明为void。
6.constexpr声明的成员函数不再具有const属性。
另外还有些不允许的:
a. 它必须非虚; [c++20前]
b. 它的函数体不能是函数 try 块; [c++20前]
c. 它不能是协程; [c++20起]
d. 对于构造函数与析构函数 [C++20 起],该类必须无虚基类
e. 它的返回类型(如果存在)和每个参数都必须是字面类型 (LiteralType)
f. 至少存在一组实参值,使得函数的一个调用为核心常量表达式的被求值的子表达式(对于构造函 数为足以用于常量初始化器) (C++14 起)。不要求诊断是否违反这点。
#include <iostream>
constexpr int abs_(int x)
{
if (x > 0)
{
return x;
}
else
{
return -x;
}
}
constexpr int sum(int x)
{
int result = 0;
while (x > 0)
{
result += x--;
}
return result;
}
constexpr int next(int x)
{
return ++x;
}
int main()
{
char buffer1[sum(5)] = { 0 };
char buffer2[abs_(-5)] = { 0 };
char buffer3[next(5)] = { 0 };
}这里可以看到在next函数中++x可以改变传入参数的值,这是基于第4点:函数可以修改生命周期和常量表达式相同的对象。
需要强调一点的是,虽然常量表达式函数的返回值可以在编译期计算出来,但是这个行为并不是确定的。例如,当带形参的常量表达式函数接受了一个非常量实参时,常量表达式函数可能会退化为普通函数:
如果我们传入常量表达式的实参,constexpr函数在编译时期就计算出来;
#include <iostream>
#include <array>
constexpr int size(int i)
{
return i*2;
}
int main(void)
{
std::array<int, size(10)> arr;//传入参数是常量实参,此时constexpr普通函数在编译期就计算出来了
std::cout << arr.size() << std::endl;
}传入实参为非常量表达式时,退化为普通函数:
#include <iostream>
constexpr int size(int i)
{
return i*2;
}
int main(void)
{
int i = 10;
constexpr int s = size(i);//编译错误:传入参数接受了一个非常量实参,此时constexpr退化为普通函数了
}这种退化机制对于程序员来说是非常友好的,它意味着我们不用为了同时满足编译期和运行期计算而定义两个相似的函数。另外,这里也存在着不确定性,因为GCC依然能在编译阶段计算size
的结果,但是MSVC和CLang则不行。
constexpr和class
constexpr还能够声明用户自定义类型;
#include <iostream>
struct X
{
int value;
};
int main()
{
constexpr X x = { 1 };
char buffer[x.value] = { 0 };
}以上代码自定义了一个结构体X,并且使用constexpr声明和初始化了变量x。到目前为止一切顺利,不过有时候我们并不希望成员变量被暴露出来,于是修改了X的结构:
#include <iostream>
class X
{
public:
X() : value(5) {}
int get() const{ return value;}
private:
int value;
};
int main(void)
{
constexpr X x; //error: constexpr variable cannot have non-literal type 'const X
char buffer[x.get()] = { 0 };//无法在编译期计算
}解决上述问题的方法很简单,只需要用constexpr声明X类的构造函数,也就是声明一个常量表达式构造函数,当然这个构造函数也有一些规则需要遵循。
1.构造函数必须用constexpr声明。
2.构造函数初始化列表中必须是常量表达式。
3.构造函数的函数体必须为空(这一点基于构造函数没有返回值,所以不存在return expr)。
根据这个constexpr构造函数规则修改如下:
#include <iostream>
class X
{
public:
constexpr X() : value(5) {}
constexpr X(int i):value{i} {}
constexpr int get() const{ return value;}
private:
int value;
};
int main(void)
{
constexpr X x; //error: constexpr variable cannot have non-literal type 'const X
char buffer[x.get()] = { 0 };
}上面这段代码只是简单地给构造函数和get函数添加了constexpr说明符就可以编译成功,因为它们本身都符合常量表达式构造函数和常量表达式函数的要求,我们称这样的类为字面量类类型
(literal class type)。
对于constexpr int get()const 函数,在C++11中,constexpr会自动给函数带上const属性。而从C++14起constexpr返回类型的类成员函数不在是const函数了;
请注意,常量表达式构造函数拥有和常量表达式函数相同的退化特性,当它的实参不是常量表达式的时候,构造函数可以退化为普通构造函数,当然,这么做的前提是类型的声明对象不能为常量表达式值:
int i = 8;
constexpr X x(i); // 编译失败,不能使用constexpr声明
X y(i); // 编译成功由于i不是一个常量,因此X的常量表达式构造函数退化为普通构造函数,这时对象x不能用constexpr声明,否则编译失败。
C++14对constexpr规则的修改同样也影响到了constexpr构造函数:
#include <iostream>
class X {
public:
constexpr X() : value(5) {}
constexpr X(int i) : value(0)
{
if (i > 0)
{
value = 5;
}
else
{
value = 8;
}
}
constexpr void set(int i)
{
value = i;
}
constexpr int get() const
{
return value;
}
private:
int value;
};
constexpr X make_x()
{
X x;
x.set(42);
return x;
}
int main()
{
constexpr X x1(-1);
constexpr X x2 = make_x();
constexpr int a1 = x1.get();
constexpr int a2 = x2.get();
std::cout << a1 << std::endl;
std::cout << a2 << std::endl;
}constexpr声明的x1、x2、a1和a2都是编译期必须确定的值。constexpr构造函数内可以使用if语句并且对value进行赋值操作。根据规则5:函数的返回值可以声明为void:返回类型为void的set函数也被声明为constexpr,这也意味着该函数能够运用在constexpr声明的函数体内,make_x函数就是利用了这个特性。
根据规则4:函数可以修改生命周期和常量表达式相同的对象。 和规则6:constexpr声明的成员函数不再具有const属性。set函数也能成功地修改value的值。
使用constexpr声明自定义类型的变量,必须确保这个自定义类型的析构函数是平凡的,否则也是无法通过编译的。平凡析构函数必须满足下面3个条件。
1.自定义类型中不能有用户自定义的析构函数。
2.析构函数不能是虚函数。
3.基类和成员的析构函数必须都是平凡的。
constexpr lambda
从C++17开始,lambda表达式在条件允许的情况下(常量表达式函数的规则)都会隐式声明为constexpr。
#include <iostream>
#include <array>
constexpr int foo()
{
return []() { return 58; }();
}
auto get_size = [](int i) { return i * 2; };
int main(void)
{
std::array<int,foo()> arr1= { 0 };
std::array<int, get_size(5)> arr2= { 0 };
}例子中的lambda表达式却可以用在常量表达式函数和数组长度中,可见该lambda表达式的结果在编译阶段已经计算出来了。实际上这里的[](int i) { return i * 2; }相当于:
class GetSize {
public:
constexpr int operator() (int i) const
{
return i * 2;
}
};当lambda表达式不满足constexpr的条件时,lambda表达式也不会出现编译错误,它会作为运行时lambda表达式存在:
// 情况1
int i = 5;
auto get_size = [](int i) { return i * 2; };
char buffer1[get_size(i)] = { 0 }; // 编译失败,get_size需要运行时调用
int a1 = get_size(i);
// 情况2
auto get_count = []()
{
static int x = 5;
return x;
};
int a2 = get_count();以上代码中情况1和常量表达式函数相同,get_size可能会退化为运行时lambda表达式对象。当这种情况发生的时候,get_size的返回值不再具有作为数组长度的能力,但是运行时调用get_size对
象还是没有问题的。GCC在这种情况下依然能够在编译阶段求出get_size的值,MSVC和CLang则不行。对于情况2,由于static变量的存在,lambda表达式对象get_count不可能在编译期运算,因此它最终会在运行时计算。
值得注意的是,我们也可以强制要求lambda表达式是一个常量表达式,用constexpr去声明它即可。这样做的好处是可以检查lambda表达式是否有可能是一个常量表达式,如果不能则会编译报错,例如:
auto get_size = [](int i) constexpr -> int { return i * 2; };
char buffer2[get_size(5)] = { 0 };
auto get_count = []() constexpr -> int
{
static int x = 5; // 编译失败,x是一个static变量
return x;
};
int a2 = get_count();C++17 if constexpr
在使用if constexpr(…)语法时,编译器在编译时期使用编译时期表达式决定是否使用if语句或then部分或else部分(如果有的话)。如果其中一个分支条件成立,则另一部分(如果有的话)被丢弃,这样也就不会生成被丢弃部分的代码。但是,这并不意味着被丢弃的部分完全被忽略,它就像未使用模板的代码一样检查语法等。
例 1:
#include <iostream>
#include <string>
template <typename T>
std::string asString(T x)
{
if constexpr (std::is_same_v<T, std::string>) {//第一个判断语句
std::cout << "satement 1 output: ";
return x; // statement invalid, if no conversion to string
}
else if constexpr (std::is_arithmetic_v<T>) { 第二个判断语句
std::cout << "satement 2 output: ";
return std::to_string(x); // statement invalid, if x is not numeric
}
else { 第三个判断语句
std::cout << "satement 3 output: ";
return std::string(x); // statement invalid, if no conversion to string
}
}
int main()
{
std::cout << asString(42) << '\n';
std::cout << asString(std::string("hello")) << '\n';
std::cout << asString("hello") << '\n';
std::cout << asString("x2");
}这里使用编译时期if这个特性来决定在编译时是否只返回传递的字符串,或者传递的参数是整数或浮点值则调用std::to_string()做为返回值,或者尝试将传递的参数转换为std::string。由于无效的调用会被丢弃,上面的代码将被编译(如果使用常规运行时,则不会出现这种情况)。
结果如下:

使用compile-time if语法后,其声明如下:
- 传递一个std::string值,第二个判断语句和第三个判断语句丢弃;
- 传递一个数值,第一个判断语句和第三个判断语句丢弃;
- 传递一个字符串字面值,第一个判断语句和第二个判断语句丢弃。
所以,在编译时期的if语句只要配到了合法的语句,其他的语句都被丢弃了。
1. compile-time if的动机
如果对于上面介绍的代码不使用compile-if,按照运行时的方式写
#include <iostream>
#include <string>
template <typename T>
std::string asString(T x)
{
if (std::is_same_v<T, std::string>) {
return x; // statement invalid, if no conversion to string
}
else if (std::is_arithmetic_v<T>) {
return std::to_string(x); // statement invalid, if x is not numeric
}
else {
return std::string(x); // statement invalid, if no conversion to string
}
}
int main()
{
std::cout << asString(42) << '\n';
std::cout << asString(std::string("hello")) << '\n';
std::cout << asString("hello") << '\n';
std::cout << asString("x2");
}这段代码是无法编译的。这是因为函数模板要么不被编译[没有调用]要么做为一个整体编译,不会出现只编译部分的情况,因为if条件的检查是一个运行时特性。上面代码在编译时,当传递std::string或字符串字面值时,因为传递的参数无法使用std::to_string()调用,编译会失败;当传递数值时,编译也会失败,因为第一个和第三个判断返回语句无效。
注意,丢弃代码语句的语发检查不会被忽略,其结果是,当依赖于模板参数时,它不会被实例化[丢弃了说明没有被调用]。不依赖于模板参数的调用语法必须正确。所有static_assert必须是有效的,即使在未编译的分支中也是如此。
template<typename T>
void foo(T t)
{
if constexpr(std::is_integral_v<T>)
{
if (t > 0)
{
foo(t-1); // OK
}
}
else
{
undeclared(t); // error if not declared and not discarded (i.e., T is not integral)
undeclared(); // error if not declared (even if discarded)
static_assert(false, "no integral"); // always asserts (even if discarded)
}
}这个例子的代码编译错误,原因有如下两个:
- 即便T是整数类型,undeclared函数在else部分虽然被丢弃,但是undeclared函数不依赖于模板参数,没有声明这个函数编译错误。
- static_assert所在那部分的语句即便被丢弃,其语法必须正确,因为static_assert不依赖于模板参数。
2. 使用compile-time if
原则上,可以使用编译时期的if就像是运行时的if中提供了一个编译时期的表达式一样。即可以混用编译时期if和运行时期if:
if constexpr (std::is_integral_v<std::remove_reference_t<T>>)
{
if (val > 10)
{
if constexpr (std::numeric_limits<char>::is_signed)
{
...
}
else
{
...
}
}
else
{
...
}
}
else
{
...
}注意,不能在函数体外部使用if constexpr。因此,不能使用它来替换条件预处理器指令。
2.1编译时注意事项
- 编译时if影响返回值
编译时if可能会影响函数的返回类型。例如,下面的代码总是编译,但是返回类型可能不同:
#include <iostream>
auto foo()
{
if constexpr (sizeof(int) > 4)
{
return 42;
}
else
{
return 42u;
}
}
int main(void)
{
auto ret = foo();
return 0;
}这里,因为我们使用auto,函数的返回类型取决于返回语句,返回语句取决于int的大小:
a. 如果int大小大于4,则只有一个返回42的有效返回语句,因此返回类型为int。
b. 否则,只有一个返回语句返回42u,因此返回类型变为无符号整型。
注意,如果这里使用的是运行时if,那么这段代码永远不会编译,因为这两个返回语句都会被考虑进去,因此返回类型的推断是不明确的。
这样,if constexpr函数的返回类型可能会有更大的差异。例如,如果我们没有else部分,返回类型可能是int或void:
auto foo() // return type might be int or void
{
if constexpr (sizeof(int) > 4)
{
return 42;
}
}- if...else...返回类型的其他影响
对于运行时if语句,有一种模式不适用于编译时if语句:如果在then和else部分都编译带有返回语句的代码,则始终可以跳过运行时if语句中的else。也就是说,
if (...)
{
return a;
}
else
{
return b;
}可以替换为:
if (...)
{
return a;
}
return b;这种模式不适用于编译时if,因为在第二种形式中,返回类型依赖于两个返回语句,而不是一个返回语句,这可能会造成不同。例如,修改上面的例子会导致代码可能会编译(constexpr if为false),也可能不会编译:
auto foo()
{
if constexpr (sizeof(int) > 4)
{
return 42;
}
return 42u;
}如果条件为真(int的大小大于4),编译器推断出两种不同的返回类型,这是无效的。否则,我们只有一个重要的返回语句,这样代码才能编译。
再举个具体的例子:
#include <iostream>
#include <type_traits>
template<class T> auto minus(T a, T b)
{
if constexpr (std::is_same<T, double>::value)
{
if (std::abs(a - b) < 0.0001)
{
return 0.;
}
else
{
return a - b;
}
}
else
{
return static_cast<int>(a - b);
}
}
int main()
{
std::cout << minus(5.6, 5.11) << std::endl;
std::cout << minus(5.60002, 5.600011) << std::endl;
std::cout << minus(6, 5) << std::endl;
}以上是一个带精度限制的减法函数,当参数类型为double且计算结果小于0.0001的时候,我们就可以认为计算结果为0。当参数类型为整型时,则不用对精度做任何限制。上面的代码编译运行没有任何问题,因为编译器根据不同的类型选择不同的分支进行编译。但是如果修改一下上面的代码,结果可能就很难预料了:
#include <iostream>
#include <type_traits>
template<class T> auto minus(T a, T b)
{
if constexpr (std::is_same<T, double>::value)
{
if (std::abs(a - b) < 0.0001)
{
return 0.;
}
else
{
return a - b;
}
}
return static_cast<int>(a - b);
}
int main()
{
std::cout << minus(5.6, 5.11) << std::endl;
std::cout << minus(5.60002, 5.600011) << std::endl;
std::cout << minus(6, 5) << std::endl;
} 当实参为整型时一切正常,编译器会忽略if的代码块,直接编译return static_cast<int>(a − b),这样返回类型只有int一种。但是当实参类型为double的时候,情况发生了变化。if的代码块会被正常地编译,代码块内部的返回结果类型为double,而代码块外部的return static_cast<int>(a − b)
同样会照常编译,这次的返回类型为int。编译器遇到了两个不同的返回类型,只能报错。
- 短路条件编译时
考虑以下代码:
template<typename T>
constexpr auto foo(const T& val)
{
if constexpr (std::is_integral<T>::value)
{
if constexpr (T{} < 10)
{
return val * 2;
}
}
return val;
}这里,我们有两个编译时条件来决定是返回传递的原值,还是返回乘以2的值。
这编译为两个:
constexpr auto x1 = foo(42); // yields 84
constexpr auto x2 = foo("hi"); // OK, yields ”hi”运行时if短路中的条件(使用&&只评估第一个为假的条件,使用||只评估第一个为真的条件)。这可能导致预期的,如果:
template<typename T>
constexpr auto bar(const T& val)
{
if constexpr (std::is_integral<T>::value && T{} < 10)
{
return val * 2;
}
return val;
}但是,编译时if的条件总是实例化的,并且需要作为一个整体语句有效,这样传递的类型有可能是不支持<10的类型就会编译错误:
constexpr auto x2 = bar("hi"); // compile-time ERROR因此,编译时if不会使实例化短路(即if中做为整体语句实例化代码)。
如果编译时条件的有效性依赖于早期的编译时条件,则必须像在foo()中那样嵌套它们。另一个例子,你必须写:
if constexpr (std::is_same_v<MyType, T>)
{
if constexpr (T::i == 42)
{
...
}
}代替:
if constexpr (std::is_same_v<MyType, T> && T::i == 42)
{
...
}举个例子:
#include <iostream>
#include <string>
#include <type_traits>
template<class T> auto any2i(T t)
{
if constexpr (std::is_same<T, std::string>::value && T::npos ==-1)
{
return atoi(t.c_str());
}
else
{
return t;
}
}
int main()
{
std::cout << any2i(std::string("6")) << std::endl;
//std::cout << any2i(6) << std::endl;//error: type 'int' cannot be used prior to '::' because it has no members
return 0;
}上面的代码很好理解,函数模板any2i的实参如果是一个std::string,那么它肯定满足std::is_same<T,std::string>::value && T::npos == −1的条件,所以编译器会编译if分支的代码。
当函数实参为int时,std::is_same<T, std::string>::value和T::npos == −1都会被编译,由于int::npos显然是一个非法的表达式,因此会造成编译失败。这里正确的写法是通过嵌套if constexpr来替换上面的操作:
#include <iostream>
#include <string>
#include <type_traits>
template<class T> auto any2i(T t)
{
if constexpr (std::is_same<T, std::string>::value)
{
if constexpr(T::npos == -1)
{
return atoi(t.c_str());
}
}
else
{
return t;
}
}
int main()
{
std::cout << any2i(std::string("6")) << std::endl;
std::cout << any2i(6) << std::endl;//OK
return 0;
}2.2 其他编译时if的例子
- 泛型值的完美返回
编译时if的一个应用程序是返回值的完美转发,在返回值之前必须对它们进行处理。因为decltype(auto)不能对void进行推导
(因为它是一个不完整的类型),你必须这样写:
#include <functional> // for std::forward()
#include <type_traits> // for std::is_same<> and std::invoke_result<>
template<typename Callable, typename... Args>
decltype(auto) call(Callable op, Args&&... args)
{
if constexpr(std::is_void_v<std::invoke_result_t<Callable, Args...>>)
{
op(std::forward<Args>(args)...);
... // do something before we return
return; // return type is void:
}
else
{
decltype(auto) ret{op(std::forward<Args>(args)...)};
... // do something (with ret) before we return
return ret; // return type is not void:
}
}- 编译时if的标记调度
编译时if的一个典型应用是标记调度。在c++ 17之前,必须为希望处理的每种类型提供一个重载集,其中每个重载包含一个单独的函数。现在,使用编译时if,可以将所有逻辑放在一个函数中。例如,代替重载std::advance()算法:
template<typename Iterator, typename Distance>
void advance(Iterator& pos, Distance n)
{
using cat = std::iterator_traits<Iterator>::iterator_category;
advanceImpl(pos, n, cat); // tag dispatch over iterator category
}
template<typename Iterator, typename Distance>
void advanceImpl(Iterator& pos, Distance n,
std::random_access_iterator_tag)
{
pos += n;
}
template<typename Iterator, typename Distance>
void advanceImpl(Iterator& pos, Distance n,
std::bidirectional_iterator_tag)
{
if (n >= 0)
{
while (n--)
{
++pos;
}
}
else
{
while (n++)
{
--pos;
}
}
}
template<typename Iterator, typename Distance>
void advanceImpl(Iterator& pos, Distance n, std::input_iterator_tag)
{
while (n--)
{
++pos;
}
}现在可以实现所有的行为在一个函数中:
template<typename Iterator, typename Distance>
void advance(Iterator& pos, Distance n)
{
using cat = std::iterator_traits<Iterator>::iterator_category;
if constexpr (std::is_same_v<cat, std::random_access_iterator_tag>)
{
pos += n;
}
else if constexpr (std::is_same_v<cat, std::bidirectional_access_iterator_tag>)
{
if (n >= 0)
{
while (n--)
{
++pos;
}
}
else
{
while (n++)
{
--pos;
}
}
}
else // input_iterator_tag
{
while (n--)
{
++pos;
}
}
}在某种程度上,我们现在有一个编译时切换,不同的情况必须由if constexpr子句来表示。不过,请注意一个可能很重要的区别:
- 这组重载函数为您提供了最佳匹配语义。
- 带有编译时if的实现提供了第一个匹配语义。
3.3 编译时if初始化
编译时if还可以使用if的新形式进行初始化。例如,如果有一个constexpr函数foo()可以接受传递的类型,则可以使用此代码提供关于foo(x)是否生成与x相同的类型的不同行为。:
template<typename T>
void bar(const T x)
{
if constexpr (auto obj = foo(x); std::is_same_v<decltype(obj), T>)
{
std::cout << "foo(x) yields same type\n";
...
}
else
{
std::cout << "foo(x) yields different type\n";
...
}
}要决定foo(x)返回的值,可以这样写:
constexpr auto c = ...;
if constexpr (constexpr auto obj = foo(c); obj == 0)
{
std::cout << "foo() == 0\n";
...
}注意,obj必须声明为constexpr才能在条件中使用它的值。
3.4 模板外使用编译时if
如果constexpr可以用在任何函数中,而不仅仅是模板中。我们只需要一个编译时表达式,生成一些可转换为bool的东西。然而,在这种情况下,then和else部分中的所有语句都必须是有效的,即使被丢弃。
例如,下面的代码总是无法编译,因为undeclare()的调用必须是有效的,即使字符被签名,其他部分被丢弃:
#include <limits>
template<typename T>
void foo(T t)
{};
int main()
{
if constexpr(std::numeric_limits<char>::is_signed)
{
foo(42); // OK
}
else
{
undeclared(42); // ALWAYS ERROR if not declared (even if discarded)
}
}此外,以下代码永远无法成功编译,因为其中一个静态断言总是会失败:
if constexpr(std::numeric_limits<char>::is_signed)
{
static_assert(std::numeric_limits<char>::is_signed);
}
else
{
static_assert(!std::numeric_limits<char>::is_signed);
}编译时if在泛型代码中好处是可能会丢弃语句中的部分代码,虽然它必须是有效的,但它不会成为结果程序的一部分,这将减少结果可执行程序的大小。
#include <limits>
#include <string>
#include <array>
int main()
{
if (!std::numeric_limits<char>::is_signed)
{
static std::array<std::string,1000> arr1;
...
}
else
{
static std::array<std::string,1000> arr2;
...
}
}ar1或arr2都是最终可执行文件的一部分,但不是两者都是。

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









