







缓冲
流中一个相当重要的概念,无论读写流都是通过缓冲来实现的。
可写流和可读流都会在一个内部的缓冲器中存储数据,可以分别使用的 writable.writableBuffer 或 readable.readableBuffer 来获取,可缓冲的数据的数量取决于传入流构造函数的 highWaterMark 选项,默认情况下highWaterMark 64*1024个字节
读写的过程都是将数据读取写入缓冲,然后在将数据读出或者写入文件。
node Stream 重要的概念
- writable.write(chunk[, encoding][, callback])
(1) writable.write() 方法向流中写入数据,并在数据处理完成后调用 callback。如果有错误发生, callback 不一定 以这个错误作为第一个参数并被调用。要确保可靠地检测到写入错误,应该监听 'error’ 事件。(callback返回结果,产生意外需要监听error)
(2) 在确认了 chunk 后,如果内部缓冲区的大小小于创建流时设定的 highWaterMark 阈值,函数将返回 true 。 如果返回值为 false ,应该停止向流中写入数据,直到 ‘drain’ 事件被触发。(传的数据大于highWaterMark ,要通过drain来处理)
(3) 当一个流不处在 drain 的状态, 对 write() 的调用会缓存数据块, 并且返回 false。 一旦所有当前所有缓存的数据块都排空了(被操作系统接受来进行输出), 那么 ‘drain’ 事件就会被触发。 - readable.read([size])
案例
// pipe
let fs = require('fs');
let rs = fs.createReadStream('./1.txt',{
highWaterMark:1
})
let ws = fs.createWriteStream('./5.txt',{
highWaterMark:2
})
let index = 1;
rs.on('data', (data) => {
console.log(index++)
let flag = ws.write(data); // 当内部的可写缓冲的总大小小于 highWaterMark 设置的阈值时,
//调用 writable.write() 会返回 true。 一旦内部缓冲的大小达到或超过 highWaterMark 时,则会返回 false。
// 内部缓冲超过highWaterMark,会返回false 意思就是drain触发了,
if (!flag) {
rs.pause() //将readable stream删掉监听事件 变为 paused 状态(静止态)
}
})
let wsIndex = 1;
ws.on('drain', () => {
console.log('ws'+wsIndex++)
rs.resume()//将readable stream添加监听事件 变为 flowing 状态(流动态)
})
// 1 2 ws1 3 4 ws2 5 6 ws3
前面已经说了所有的流都是 EventEmitter 的实例,那么就可以on,可以emit等等
rs.on('data',()) //读入缓冲
ws.on('drain',()) //写的缓冲被清空
上面的例子中 当写缓冲大于highWaterMark时 我们就要暂停读取,等待监听到drain事件,然后重新启动rs.resume()读取
其实啊,在工作中也是很少直接这用到的,我们可以直接用pipe
rs.pipe(ws) // 即可 这样就给一个可读流写入到一个可写流当中
stream主要作用
减少node数据传输时所占用的内存
解析stream
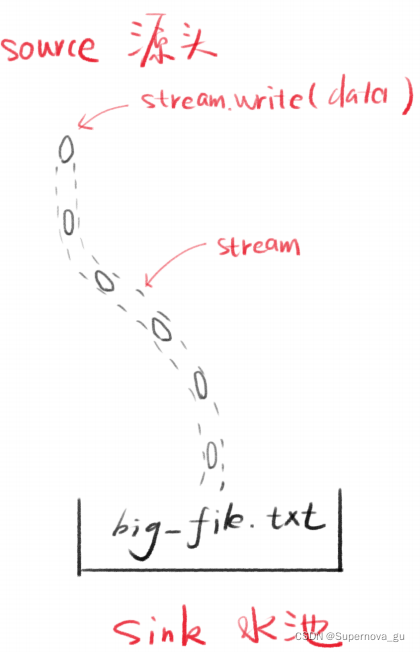
source作为起点,sink作为终点
stream是一个容器,专门将stream.write(data)简称data->从source运送至sink,其中的data被处理成chunk
chunk的类型是buffer:chunk里的数据是二进制buffer换句话说 chunk传的是buffer
// 写法 展示案例
const fs = require('fs')
// 创建一个可写流
const stream = fs.createWriteStream('./big_file.txt')
for(let i=0; i<10000; i++){
// 给文件加一点小目标
stream.write(`第 ${i}行数据,我们需要很多很多内容 \n`)
}
stream.end() // 别忘了关掉stream
console.log('done')
// 案例二 不用流的案例
// 直接readFile文件,node.js的内存占用高达百M
const server = http.createServer()
server.on('request', (request, response)=>{
fs.readFile('./big_file.txt', (error,
data)=>{
if(err) throw err
response.end(data)
console.log('done')
})
})
server.listen(8888)
// 用流 改写案例二
const server = http.createServer()
server.on('request', (request, response)=>{
const stream =
fs.createReadStream('./big_file.txt')
stream.pipe(response)
})
server.listen(8888)
pipe - 管道
两个不同的Stream可以用一个管道相连,流1的数据会流向流2
语法
stream1.pipe(stream2)
链式操作
a.pipe(b).pipe©
// stream1 监听数据,检测有数据就传给stream2
stream1.on('data', (chunk)=>{
stream2.write(chunk)
})
// stream1数据传输停止后 给stream2也停掉
stream1.on('end', ()=>{
stream2.end()
})
Stream对象和原型链

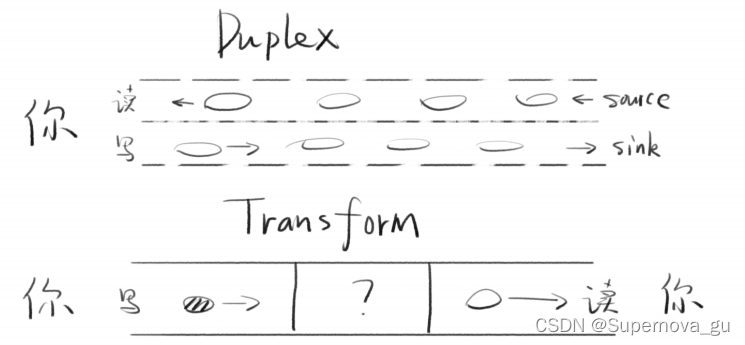
Stream的四种类型
- Readable - - 可读取数据的流(例如 fs.createReadStream())
- Writable - - 可写入数据的流(例如 fs.createWriteStream())
- Duplex - - 可读又可写的流(例如 net.Socket)
- Transform - - 在读写过程中可以修改或转换数据的 Duplex 流(例如 zlib.createDeflate())
Readable Stream

Writable Stream

在调用 stream.end() 方法之后,并且所有数据都已刷新到底层系统,则触发 ‘finish’ 事件。
const writer = getWritableStreamSomehow();
for (let i = 0; i < 100; i++) {
writer.write(`hello, #${i}!\n`);
}
writer.on('finish', () => {
console.log('All writes are now complete.');
});
writer.end('This is the end\n');

Node.js中的Stream
















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











