









PyTorch训练中Dataset多线程加载数据,而不是在DataLoader
背景与需求
现在做深度学习的越来越多人都有用PyTorch,他容易上手,而且API相对TF友好的不要太多。今天就给大家带来最近PyTorch训练的一些小小的心得。
大家做机器学习、深度学习都恨不得机器卡越多越好,这样可以跑得越快,道理好像也很直白,大家都懂。实际上我们在训练的时候很大一部分制约我们的训练的速度快慢被IO限制住了,然面CPU的利用率却不高,就算有8卡了,然而GPU的利用率却长期处理低水平,不能发挥设备本应该有的水平。所以我一直在想,有什么办法能加快IO的读取,当然最直截的就换SSD,那上速度会直接上去了。那如果是我们在服务器或者是普通的电脑就没有办法呢吗?
而且经常用PyTorch的人应该会发现,如果我们把DataLoader的num_workers设置比较大的时候,在训练启动时会等待比较久,而且在每一个epoch之间的切换也是需要等挺久的(更换,加载数据)。
如果是一个程序员的话,肯定会想到多线程、多进程,这是否会能加速我们训练的IO?答案是肯定的。
今天给大家带来的就是,多线程读取数据的实例,本次测试不含训练部分,只是对Dataset, DataLoader数据加载的部分进行测试。
PyTorch DataLoader会产生一个index然后Dataset再进行读取,如果一个batch_size=128的话,那就要产生128次的数据调试,并读取。
我的想法就很简单,我想要不我就直接在Dataset就生成好所需的Batches,这样在DataLoader的batch_size=1的话,那也是对应一个batch的数据,而我在Dataset的可以用线程去加载数据,这样应该能提高读取的效率。
有了想法就是干了。
平时我们重要Dataset的结构如下,这里用到了albumentations作为数据处理的库,而不是torchvision的transforms,其它没有什么区别的
def default_loader(path):
return Image.open(path).convert('RGB')
class AlbumentationsDatasetList(Dataset):
"""
Data processing using albumentation same as torchvision transforms
"""
def __init__(self, imgs, transform=None, loader=default_loader, percentage=1):
# here can control the dataset size percentage
img_num = int(len(imgs) * percentage)
self.imgs = imgs[:img_num]
self.transform = transform
self.loader = loader
def __getitem__(self, index):
fn = self.imgs[index]
img = self.loader(fn)
if self.transform is not None:
image_np = np.array(img)
augmented = self.transform(image=image_np)
img = augmented['image']
return img
def __len__(self):
return len(self.imgs)
方法的实现
说干就干,把多线程加进来进行改造Dataset,下面来看一下代码,代码加入了一些细节,所以会比较长,但结构还是跟上面的是一样的。只是Dataset就已经把batches都处理好了,在加载数据后,是把他们都stack在一起,这样就可以形成[N, C, W, H]结构的数据了。
注意:如果drop_last=False的话,那么最后的一个batch的数量一般不会与batch_size相同,所以在DataLoader的里batch_size要设置成1。还有DataLoader设置成1后,实际加载的数据是[1, N, C, W, H],所以在用的时候要squeeze一下。
class AlbumentationsDatasetList(Dataset):
def __init__(self,
images,
batch_num,
percentage=1,
transform=None,
multi_load=True,
shuffle=True,
seed=None,
drop_last=False,
num_workers=4,
loader=default_loader) -> None:
#==============================================
# Set seed
#==============================================
if seed is None:
self.seed = np.random.randint(0, 1e6, 1)[0] # Fix bug 2021-12-10
else:
self.seed = seed
random.seed(self.seed)
# add some assertation if the image empty donot proceed. Fix 2021-12-12
assert images is not None, f'images must be NOT empty, but got {images}'
self.images = images
self.batch_num = batch_num # use batch_num instead of batch_size, same thing
self.percentage = percentage
self.transform = transform
self.multi_load = multi_load
self.shuffle = shuffle
self.drop_last = drop_last
self.num_workers = num_workers # Dataset num_workers
self.loader = loader
self.batches = self._create_batches()
self.batches = self._get_len_batches(self.percentage)
def _get_len_batches(self, percentage):
"""
Description:
- you could control how many batches you want to use for training or validating
indices sort, so that could keep the batches got in order from originla batches
Parameters:
- percentage: float, range [0, 1]
Return
- numpy array of the new bags
"""
batch_num = int(len(self.batches) * percentage)
indices = random.sample(list(range(len(self.batches))), batch_num)
indices.sort()
new_batches = np.array(self.batches, dtype='object')[indices]
return new_batches
def _create_batches(self,):
if self.shuffle:
random.shuffle(self.images)
batches = []
ranges = list(range(0, len(self.images), self.batch_num))
for i in ranges[:-1]:
batch = self.images[i:i + self.batch_num]
batches.append(batch)
#== Drop last ===============================================
last_batch = self.images[ranges[-1]:]
if len(last_batch) == self.batch_num:
batches.append(last_batch)
elif self.drop_last:
pass
else:
batches.append(last_batch)
return batches
def __getitem__(self, index):
batch = self.batches[index]
#== Stack all images, become a 4 dimensional tensor ===============
if self.multi_load:
batch_images = self._multi_loader(batch)
else:
batch_images = []
for image in batch:
img = self._load_transform(image)
batch_images.append(img)
batch_images_tensor = torch.stack(batch_images, dim=0)
return batch_images_tensor
def _load_transform(self, tile):
img = self.loader(tile)
if self.transform is not None:
image_np = np.array(img)
augmented = self.transform(image=image_np)
img = augmented['image']
return img
def _multi_loader(self, tiles):
images = []
executor = ThreadPoolExecutor(max_workers=self.num_workers)
results = executor.map(self._load_transform, tiles)
executor.shutdown()
for result in results:
images.append(result)
return images
def __len__(self):
return len(self.batches)
代码与数据测试
接下来就是拿数据进行测试了,这里还设置了multi_load的参数,这样我们可以方便控制是否用多线程与否,这样我们就可以对比一下在相同的机器,相同的数据下,多线程加载数据是否比单线程快。
-
测试的目的:
- 1,是否多线程多单线程快;
- 2,多线程能比单线路快多少;
- 3,找到这机器最快(或者比较全适)的越参数,可作为其它机器的参考。
-
测试平台:Window10
-
CPU:Intel Core i7-9850H @ 2.60GHz
-
RAM: 32 GB
-
测试的数据:是5000张图像,全部都是3通道RBG,8位的512x512像素图像,图像格式是.PNG。
-
测试方法:
-
超参数如下:搜索空间为1024
-
multi_loads = [True, False] prefetch_factors = list(range(0, 17, 2))[1:] # [2, 4, 6, 8, 10, 12, 14, 16] dataset_workers = list(range(0, 17, 2))[1:] dataloader_workers = list(range(0, 17, 2))[1:]
-
-
利用grid search方法,每一个搜索空间都对Dataset, DataLoader设置不同的参数,而且每轮数据都是读完、并处理完5000张图像,drop_last=False
-
数据增强:只做了resize,normalize
-
下面是全部的测试代码。
albumentations_valid = album.Compose([
album.Resize(480, 480),
album.Normalize(mean=[0.7347, 0.4894, 0.6820, ], std=[0.1747, 0.2223, 0.1535, ]),
ToTensorV2(),
])
from utils import get_specified_files
path = r"xxxxx"
images = get_specified_files(path, suffixes=[".png"], recursive=True) # glob.glob
images = images[:5000]
print(len(images))
results = []
log_file = open(r"grid_search_log.txt", mode='a', encoding='utf-8')
multi_loads = [True, False]
prefetch_factors = list(range(0, 17, 2))[1:] # [2, 4, 6, 8, 10, 12, 14, 16]
dataset_workers = list(range(0, 17, 2))[1:]
dataloader_workers = list(range(0, 17, 2))[1:]
for multi_load in multi_loads:
for prefetch_factor in prefetch_factors:
for dataset_worker in dataset_workers:
for dataloader_worker in dataloader_workers:
multi_load = multi_load
if multi_load:
prefetch_factor = prefetch_factor
else:
prefetch_factor = prefetch_factor
dataloader_worker = dataloader_worker
train_dataset = AEDataset(images,
batch_num=128,
percentage=1,
transform=albumentations_valid,
multi_load=multi_load,
shuffle=True,
seed=0,
drop_last=False,
num_workers=dataset_worker,
)
train_loader = DataLoader(dataset=train_dataset,
batch_size=1,
shuffle=False,
num_workers=dataloader_worker,
pin_memory=True,
prefetch_factor=prefetch_factor,
persistent_workers=False)
print("Start loading")
start_time = time.time()
for i, (batches) in enumerate(train_loader):
i+1
elapse = time.time() - start_time
print(f"multi_load: {multi_load}, prefetch_factors: {prefetch_factor}, dataset_workers: {dataset_worker}, data_loader_workers: {dataloader_worker}, elapse: {elapse:.4f}")
log_file.write(f"multi_load: {multi_load}, prefetch_factors: {prefetch_factor}, dataset_workers: {dataset_worker}, data_loader_workers: {dataloader_worker}, elapse: {elapse:.4f}\n")
测试结果
回到我们上面的测试目标
测试的目的:
- 1,是否多线程多单线程快;
- 2,多线程能比单线程快多少;
- 3,找到这台机器最快(或者比较全适)的越参数,可作为其它机器的参考。
我们带着这3个问题,看一下下面的测试结果:
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
path = "C:/Users/jasne/Desktop/grid_search_multi_load.csv"
df = pd.read_csv(path)
df.head()
| multi_load | prefetch_factors | dataset_workers | data_loader_workers | elapse | |
|---|---|---|---|---|---|
| 0 | True | 14 | 14 | 2 | 19.9746 |
| 1 | True | 14 | 10 | 2 | 19.9816 |
| 2 | True | 14 | 12 | 2 | 20.0205 |
| 3 | True | 8 | 10 | 2 | 20.0514 |
| 4 | True | 14 | 16 | 2 | 20.0943 |
Max elapse
也是我们平时用的普通load的方法,时间是72.28秒
df[df["elapse"]==df["elapse"].max()]
| multi_load | prefetch_factors | dataset_workers | data_loader_workers | elapse | |
|---|---|---|---|---|---|
| 1024 | False | 1 | 1 | 1 | 72.2857 |
Multi Load Max elapse
多线程时最慢的时间
multi_load = df[df["multi_load"]==True]
multi_load[multi_load["elapse"]==multi_load["elapse"].max()]
| multi_load | prefetch_factors | dataset_workers | data_loader_workers | elapse | |
|---|---|---|---|---|---|
| 1023 | True | 6 | 14 | 16 | 48.3309 |
Min elapse
相差的倍数的计算公式为
(
max
−
min
)
/
min
(\text{max} - \text{min}) / \text{min}
(max−min)/min
时间是19.97秒,比最长的时间少了 52.31秒,快了2.6倍的时间,所以可以看出用multi_load肯定是比single load要快的。
多线程的时间,也受prefetch_factors, dataset_workers, dataloader_workers的影响。而且影响还是比较大的。
多线程时,最快与最慢的相差1.42倍
df[df["elapse"]==df["elapse"].min()]
| multi_load | prefetch_factors | dataset_workers | data_loader_workers | elapse | |
|---|---|---|---|---|---|
| 0 | True | 14 | 14 | 2 | 19.9746 |
下面来看是否 data_loader_workers越大越好?
dataloader_workers = multi_load[(multi_load["prefetch_factors"]==2) & (multi_load["dataset_workers"]==2)]
dataloader_workers.sort_values("data_loader_workers", inplace=True)
dataloader_workers
| multi_load | prefetch_factors | dataset_workers | data_loader_workers | elapse | |
|---|---|---|---|---|---|
| 376 | True | 2 | 2 | 2 | 28.6076 |
| 102 | True | 2 | 2 | 4 | 24.4866 |
| 144 | True | 2 | 2 | 6 | 26.3106 |
| 410 | True | 2 | 2 | 8 | 30.3909 |
| 536 | True | 2 | 2 | 10 | 33.2621 |
| 724 | True | 2 | 2 | 12 | 36.9114 |
| 946 | True | 2 | 2 | 14 | 41.3437 |
| 986 | True | 2 | 2 | 16 | 44.4443 |
plt.figure(figsize=(8, 5))
plt.scatter(dataloader_workers["data_loader_workers"], dataloader_workers["elapse"])
plt.show()
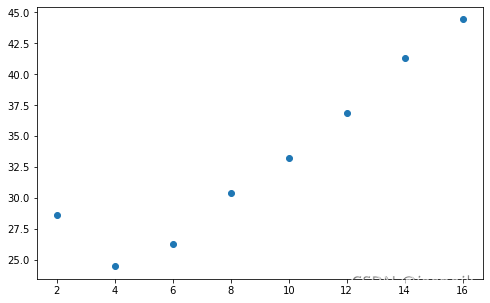
从图上可以看出,dataloader_workers并非越大越好,dataloader_workers=4时是在2-8之间是比较好的选择。随着dataloader_workers的增加,所需要的时间也呈线性的增加。
下面来看是否 dataset_workers越大越好
dataset_workers = multi_load[(multi_load["prefetch_factors"]==2) & (multi_load["data_loader_workers"]==2)]
dataset_workers.sort_values("dataset_workers", inplace=True)
dataset_workers
| multi_load | prefetch_factors | dataset_workers | data_loader_workers | elapse | |
|---|---|---|---|---|---|
| 376 | True | 2 | 2 | 2 | 28.6076 |
| 75 | True | 2 | 4 | 2 | 23.5092 |
| 52 | True | 2 | 6 | 2 | 22.4270 |
| 49 | True | 2 | 8 | 2 | 22.2465 |
| 26 | True | 2 | 10 | 2 | 21.7578 |
| 37 | True | 2 | 12 | 2 | 22.0112 |
| 46 | True | 2 | 14 | 2 | 22.1947 |
| 35 | True | 2 | 16 | 2 | 21.9832 |
plt.figure(figsize=(8, 5))
plt.scatter(dataset_workers["dataset_workers"], dataset_workers["elapse"])
plt.show()
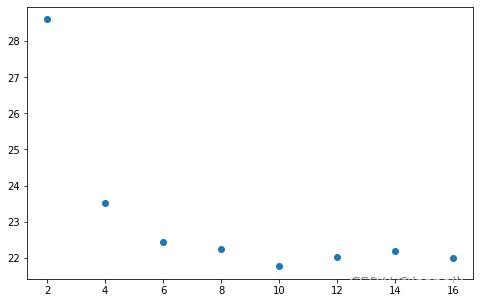
从图上可以看出,dataset_workers增加也可以明显减少数据加载所需要时间。但是当dataset_workers超过10后,不再呈现出减少的趋势,当达到12、14时有一点点上降。由于测试平台有限,这里所应该让测试一下dataset_workers达到128或者更高的数之间,是否会达到更少的数据加载时间。
下面来看是否 prefetch_factors越大越好
prefetch_factors = multi_load[(multi_load["dataset_workers"]==2) & (multi_load["data_loader_workers"]==2)]
prefetch_factors.sort_values("prefetch_factors", inplace=True)
prefetch_factors
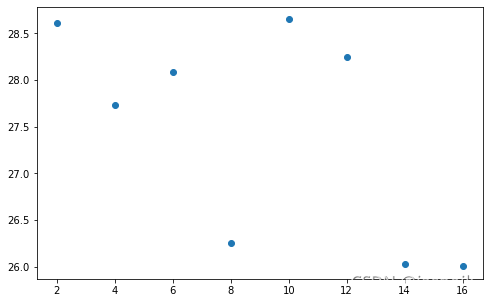
| multi_load | prefetch_factors | dataset_workers | data_loader_workers | elapse | |
|---|---|---|---|---|---|
| 376 | True | 2 | 2 | 2 | 28.6076 |
| 289 | True | 4 | 2 | 2 | 27.7318 |
| 309 | True | 6 | 2 | 2 | 28.0899 |
| 141 | True | 8 | 2 | 2 | 26.2518 |
| 378 | True | 10 | 2 | 2 | 28.6515 |
| 332 | True | 12 | 2 | 2 | 28.2445 |
| 135 | True | 14 | 2 | 2 | 26.0284 |
| 134 | True | 16 | 2 | 2 | 26.0025 |
plt.figure(figsize=(8, 5))
plt.scatter(prefetch_factors["prefetch_factors"], prefetch_factors["elapse"])
plt.show()
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-UUp7MHiu-1634438695527)(C:/Users/jasne/Desktop/Untitled/output_18_0.png)]
从图上可以看出,prefetch_factors似乎好像越大,加载的时间越少,但似乎也相差不多,最多的时间与最小的时间相差也仅为2.6秒。
prefetch_factors的外一个筛选条件
prefetch_factors = multi_load[(multi_load["dataset_workers"]==10) & (multi_load["data_loader_workers"]==4)]
prefetch_factors.sort_values("prefetch_factors", inplace=True)
prefetch_factors
| multi_load | prefetch_factors | dataset_workers | data_loader_workers | elapse | |
|---|---|---|---|---|---|
| 70 | True | 2 | 10 | 4 | 23.3808 |
| 103 | True | 4 | 10 | 4 | 24.4975 |
| 108 | True | 6 | 10 | 4 | 24.6660 |
| 53 | True | 8 | 10 | 4 | 22.5058 |
| 90 | True | 10 | 10 | 4 | 24.1555 |
| 92 | True | 12 | 10 | 4 | 24.1825 |
| 39 | True | 14 | 10 | 4 | 22.0710 |
| 120 | True | 16 | 10 | 4 | 25.0829 |
plt.figure(figsize=(8, 5))
plt.scatter(prefetch_factors["prefetch_factors"], prefetch_factors["elapse"])
plt.show()
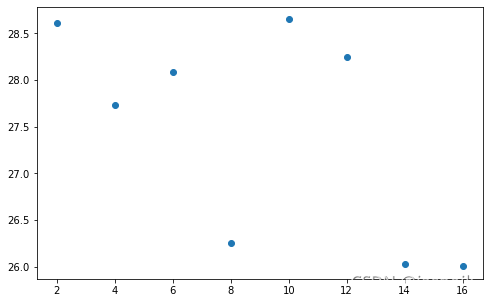
从图上可以看出,prefetch_factors数量似乎对加载时间的影响似乎不太明显,最多的时间与最小的时间相差也仅为2.6秒。
| multi_load | prefetch_factors | dataset_workers | data_loader_workers | elapse | |
|---|---|---|---|---|---|
| 70 | True | 2 | 10 | 4 | 23.3808 |
| 103 | True | 4 | 10 | 4 | 24.4975 |
| 108 | True | 6 | 10 | 4 | 24.6660 |
| 53 | True | 8 | 10 | 4 | 22.5058 |
| 90 | True | 10 | 10 | 4 | 24.1555 |
| 92 | True | 12 | 10 | 4 | 24.1825 |
| 39 | True | 14 | 10 | 4 | 22.0710 |
| 120 | True | 16 | 10 | 4 | 25.0829 |
plt.figure(figsize=(8, 5))
plt.scatter(prefetch_factors["prefetch_factors"],
prefetch_factors["elapse"])plt.show()
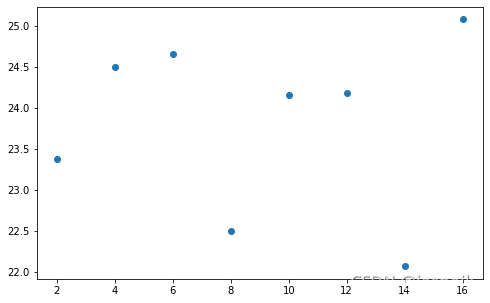
从图上可以看出,prefetch_factors数量似乎对加载时间的影响似乎不太明显,最多的时间与最小的时间相差也仅为2.6秒。
结论
- 多线程加载数据肯定是比单线程快的?
- 这点是不用质疑的,单从计算机的运行方式就可以得出这个结论,这也是并行的优势。
- 多线程能比单线程快多少?
- 从上面的结果,我们看到,当选用合适的超参数时,多线程加载相同的数据与相同的处理方法,比单线程快了52.31秒,快了2.6倍有多。就算是最不好的参数,多线和最长的加载时间为48.33秒,也比单线程的72.28秒,快差不多0.5倍。
- 找到这台机器最快(或者比较全适)的越参数,可作为其它机器的参考
- dataset_workers 越大越好,但达到了一个临界值后,不会再增加了,本测试平台的值为10
- data_loader_workers,不是越大越好,本测试平台最好的值为4,在4左右的值都是较好的参考值。然后随着此参数的数量的增加,所需要的时间也呈线性的增涨,这也说明了PyTorch大data_loader_workers启动需要等待更久的时间
- prefetch_factors的数量似乎对数据的加载时间影响不大,但最好不要是1。
本次测试没有监测内存还有CPU的使用率,但在过程中观察了一下,CPU使用率基本都可以达到100%。也可以把这些参数也监测起来,形成更多的超参数,以便参考。
注意:由于在训练的过程中也是需要利用CPU的,所以尽量不要太多的dataset_workers,尽量不要把CPU都使用到100%,而造成死机。


















 823
823

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











