










详解注意力(Attention)机制
注意力机制在使用encoder-decoder结构进行神经机器翻译(NMT)的过程中被提出来,并且迅速的被应用到相似的任务上,比如根据图片生成一段描述性语句、梗概一段文字的内容。从一个高的层次看,允许decoder从多个上下文向量(context vector)中选取需要的部分,使得Encoder从只能将上下文信息压缩到固定长度的向量中这个束缚中解放出来,进而可以表示更多的信息。
目前,注意力机制在深度学习模型中十分常见,而不仅限于encoder-decoder层次结构中。值得一提的是,注意力机制可以仅应用在encoder上,以解决诸如文本分类或者表示学习的任务上。这种注意力机制的应用被称为自聚焦或者内部聚焦机制。
下面我们从神经机器学习(NMT)使用的encoder-decoder结构开始介绍聚焦机制,之后我们会介绍自聚焦机制。
1.1 Encoder-decoder聚焦机制
1.1.1 Encoder-decoder的简介
从一个抽象的层次上看,encoder将输入压缩成一个高维的上下文向量,而decoder则可以从这个上下文向量中产生输出。

在神经机器翻译(NMT)中,输入和输出都是单词的序列,分别表示为 x = ( x 1 , . . . , x T x ) x = (x_1, ..., x_{T_x}) x=(x1,...,xTx)和 y = ( y 1 , . . . , y T y ) y=(y_1, ..., y_{T_y}) y=(y1,...,yTy), x x x和 y y y称为源句(source sentence)和目标句(target sentence)。当输入和输出都是句子序列时,这样的encoder-decoder结构也被成为是seq2seq模型。由于encoder-decoder结构处处可微的性质,模型中的参数集 θ \theta θ的最优解等效于在整个语料库上计算似然函数的最大值(MLE),这种训练的方式成为端到端(end-to-end)
a r g m a x θ { ∑ ( x , y ) ∈ c o r p u s l o g P ( y ∣ x ; θ ) } argmax_\theta\{\sum _{(x,y)\in corpus} logP(y|x;\theta)\} argmaxθ{(x,y)∈corpus∑logP(y∣x;θ)}
这里我们想要最大化的函数是预测正确单词的概率的对数。
1.1.2 Encoder
我们有很多种方法对源句子做嵌入(embedding),比如CNN、全连接等等。在机器翻译中通常使用深度RNN来实现。[论文][1]论文中首次使用了双向RNN,这个模型由两个深度RNN组成,除了使用的词嵌入矩阵之外的所有参数都不一样。第一个RNN从左到右处理输入的句子序列,而另外一个RNN从右到左处理输入的句子序列。得到的两个句子Embedding在RNN处理的每一步都合并成一个双向RNN的内部表示: h t = [ h t ⃗ ; h t ← ] h_t = [\vec {h_t};\overleftarrow{h_t}] ht=[ht;ht]
双向RNN在对source words进行编码时考虑了整个上下文的信息,而不仅仅是之前的信息。其结果是, h t h_t ht依赖于以某个词 x t x_t xt为中心的窗口的上下文,而单向的RNN下的 h t h_t ht则依赖于单词 x t x_t xt及其之前出现的词汇。聚焦于 x t x_t xt附近的小窗口可能存在一些优势,但不一定是决定性的。事实上,Luong使用双向RNN获得了最高水平的结果。在下面的段落中,encoder的隐藏状态(hidden state)表示为 h t ⃗ \vec {h_t} ht,也常称为annotations。
1.1.3 Decoder
与encoder可以使用不同的模型不同,神经机器学习中decoder通常只使用单向RNN(unidirectional RNN),这是因为常识下文本生成的过程也是单向的。decoder每一次生成一个新的词汇。
关键点 :让decoder只使用encoder的最近的annotation h T x h_{T_x} hTx促使encoder尽可能将信息压缩到 h T x h_{T_x} hTx中。因为 h T x h_{T_x} hTx是一个固定形状的向量,它能携带的信息是有限的,所有这个表示方法会丢失部分的信息。我们可以让decoder关注encoder的所有step产生的annotation h T i h_{T_i} hTi的集合 ( h 1 , . . . , h T x ) (h_1, ..., h_{T_x}) (h1,...,hTx)来起到关注整个句子序列的目的。这样做的结果是encoder可以通过调整annotations的分布来保存更多的信息,而decoder能够决定哪一个step的annotation需要进行聚焦。
更加准确的说,目标句子
y
=
(
y
1
,
.
.
.
,
y
T
y
)
y = (y_1, ..., y_{T_y})
y=(y1,...,yTy)中每步生成的
y
t
y_t
yt基于如下分布:
P
[
y
t
∣
{
y
1
,
.
.
.
y
t
−
1
}
,
c
t
]
=
s
o
f
t
m
a
x
(
W
s
h
~
t
)
P[y_t|\{y_1, ... y_{t-1}\}, c_t] = softmax(W_s {\widetilde h}_t)
P[yt∣{y1,...yt−1},ct]=softmax(Wsh
t)
其中
h
~
t
{\widetilde h}_t
h
t意为聚焦化的隐藏状态,有下面公式计算得到:
h
~
t
=
t
a
n
h
(
W
c
[
c
t
;
h
t
]
)
{\widetilde h}_t = tanh(W_c[c_t; h_t])
h
t=tanh(Wc[ct;ht])
h t h_t ht意为decoder的隐藏状态(当堆叠多个RNN时,表示最上层RNN的隐藏状态) ( y 1 , . . . , y t − 1 ) ({y_1, ..., y_{t-1}}) (y1,...,yt−1)表示生成之前输出单词的信息, c t c_t ct表示源上下文的向量(source context vector), [ ; ] [;] [;]表示合并操作(concatenation)。 W s 和 W c W_s和W_c Ws和Wc是可训练的参数矩阵,简单起见,省略偏置(bias)。这个source context vector c t c_t ct有两种方法进行计算:globally和locally。下面的两个子部分将会分别介绍。
集束搜索:尝试词汇表中所有单词可能的组合再找到概率最高的组合的方法是很难实现的。从另一个角度考虑贪婪的生成每一个单词,也就是每次都选择最可能单词,这样能够达到次最优的结果。实际应用中,我们使用集束搜索的方式一次探索K个待选词这中启发式的算法。大的K值可以生成更好的目标句子,但是会降低decodeing的速度。

1.1.4 Global attention
这里,上下文向量(context vector) c t c_t ct通过计算源句子(source sentence)的所有注释(annotation),也即encoder的所有隐藏状态(hidden state)的加权和得到。一共有 T x T_x Tx个注释(source sentence的长度),每一个注释都是大小为encoder隐藏层单元数的向量, c t c_t ct和所有注释的形状相同。分配向量(alignment vector) α t \alpha _t αt的形状和source sentence的长度 T x T_x Tx相同,是一个变量。
c t = ∑ i = 1 T x α t , i h ‾ i c_t = \sum _{i=1} ^{T_x} \alpha_{t, i} {\overline h}_i ct=i=1∑Txαt,ihi
α t , i = e x p ( s c o r e ( h t , h ‾ i ) ) ∑ i ‘ T x e x p ( s c o r e ( h t , h ‾ i ‘ ) ) \alpha_{t,i} = \frac {exp(score(h_t, {\overline h}_i))}{\sum _{i^‘} ^{T_x} exp(score(h_t, {\overline h}_{i^‘}))} αt,i=∑i‘Txexp(score(ht,hi‘))exp(score(ht,hi))
分配向量的计算过程分为两步,首先分别计算decoder当前step的隐藏状态 h t h_t ht和encoder的所有隐藏状态 h ‾ i {\overline h}_i hi的alignment运算的结果(alignment运算下面会介绍),再应用softmax函数计算 e x p ( s c o r e ( h t , h ‾ i ) ) exp(score(h_t, {\overline h}_i)) exp(score(ht,hi))在所有 ∑ i ‘ T x e x p ( s c o r e ( h t , h ‾ i ‘ ) ) {\sum _{i^‘} ^{T_x} exp(score(h_t, {\overline h}_{i^‘}))} ∑i‘Txexp(score(ht,hi‘))中的比重。
换句话说,
c
t
c_t
ct可以看作是所有encoder的隐藏状态的分布律(每个状态的概率处于
[
0
,
1
]
[0,1]
[0,1]并且和为1),进而预示source sentence中对预测下一个单词最优帮助的词汇。
s
c
o
r
e
(
)
score()
score()函数理论上可以是任意的比较函数。Luong在他的论文中使用点积(dot product)(
s
c
o
r
e
(
h
t
,
h
‾
i
)
=
h
t
⊤
h
‾
i
score(h_t, {\overline h}_i) = {h_t}^{\top}{\overline h}_i
score(ht,hi)=ht⊤hi),一个更加通用的方程是在点积基础上增加一个由全连接神经网络层训练的参数矩阵
W
α
W_ \alpha
Wα,方程表示为
s
c
o
r
e
(
h
t
,
h
‾
i
)
=
h
t
⊤
W
α
h
‾
i
score(h_t, {\overline h}_i) = {h_t}^{\top} W_ \alpha{\overline h}_i
score(ht,hi)=ht⊤Wαhi,实验发现dot product在gloabal attention中表现更好,而general方程在local attention中表现更好。下面一节将会介绍local attention。

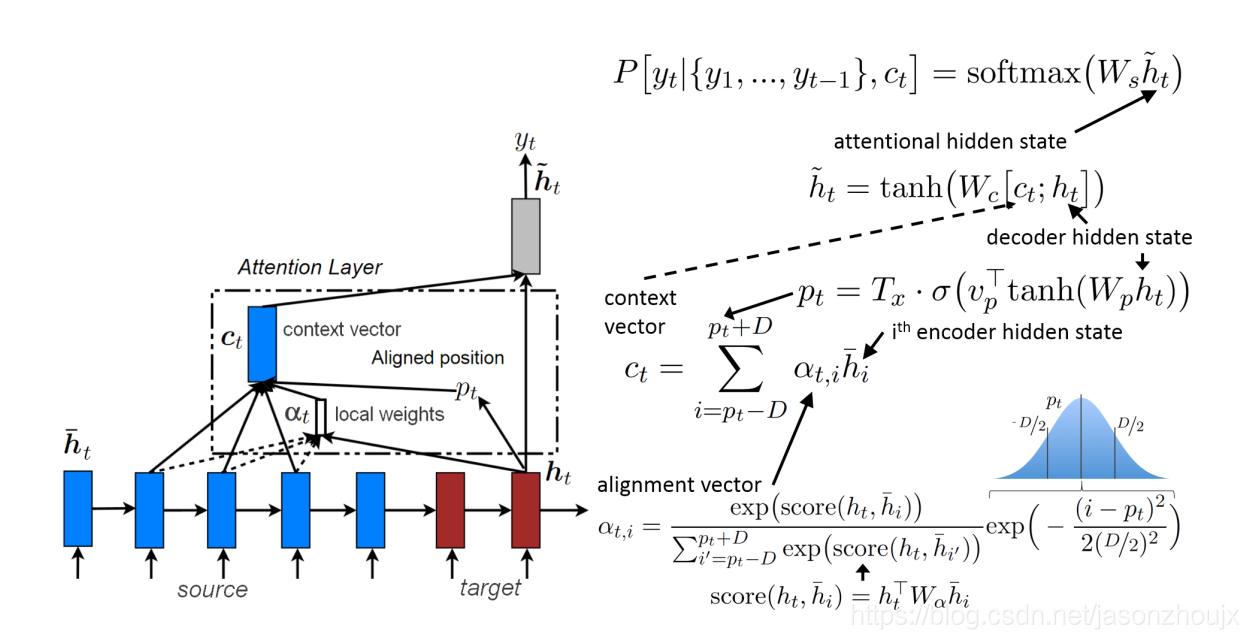
1.1.5 Local attention
每一次生成目标单词(target word)都分析source sentence中所有单词的做法代价太高,也许也是没有必要的。为了缓解这个问题,[Luong et at.][2]论文中建议只集中关注一个固定大小2D+1窗口中的source sentence 的注释(annotation),即只关注最能帮助预测下一个词汇的source sentence中某个词汇前后step的隐藏状态(hidden state):
c
t
=
∑
i
=
p
t
−
D
p
t
+
D
α
t
,
i
h
‾
i
c_t = \sum _{i=p_t -D} ^{p_t +D} \alpha_{t,i} {\overline h}_i
ct=i=pt−D∑pt+Dαt,ihi
其中,D由用户自定义,而窗口中心即聚焦的annotation p t p_t pt可以也设为 t t t或者基于保存了之前target words ( y 1 , . . . y t − 1 ) (y_1, ...y_{t-1}) (y1,...yt−1)信息的decoder隐藏状态的 h t h_t ht决定: p t = T x ⋅ σ ( v p ⊤ t a n h ( W p h t ) ) pt = T_x · \sigma(v_p ^{\top} tanh(W_p h_t)) pt=Tx⋅σ(vp⊤tanh(Wpht)), T x T_x Tx表示source sentence 的长度, σ \sigma σ表示sigmoid函数, v p v_p vp和 W p W_p Wp是可训练的参数矩阵。分配矩阵(alignment weights)的计算过程和global attention中的相似,仅仅是增加了一项均值为 p t p_t pt,标准差为 D / 2 D/2 D/2的标准正太分布乘积项:
α t , i = e x p ( s c o r e ( h t , h ‾ i ) ) ∑ i ‘ T x e x p ( s c o r e ( h t , h ‾ i ‘ ) ) e x p ( − ( i − p t ) 2 2 ( D / 2 ) 2 ) \alpha_{t,i} = \frac {exp(score(h_t, {\overline h}_i))}{\sum _{i^‘} ^{T_x} exp(score(h_t, {\overline h}_{i^‘}))} exp(- \frac{(i-p_t)^2}{2(D/2)^2}) αt,i=∑i‘Txexp(score(ht,hi‘))exp(score(ht,hi))exp(−2(D/2)2(i−pt)2)
注意 p t ∈ R ∩ [ 0 , T x ] a n d i ∈ R ∩ [ p t − D , p t + D ] p_t \in \mathbb{R} \cap [0, T_x] \ and \ i \in \mathbb{R} \cap [p_t-D, p_t+D] pt∈R∩[0,Tx] and i∈R∩[pt−D,pt+D]。添加的高斯分布项使得alignment权重随着 i i i在窗口中远离中心 p t p_t pt移动逐渐降低,也就是说对于给予靠近 p t p_t pt的annotation更多的影响力。另外和global attention不同的是 α t \alpha _t αt的大小被固定为 2 D − 1 2D-1 2D−1,只有处于窗口范围内的annotation才对输出有影响。local attention可以看成是alignment权重与一个截断高斯分布相乘后的global attention(窗口外的annotation取值为0)。local attention的示意图如下所示:
1.2 self-attention
现在我们将encoder简单设置为单独的RNN处理长度为T的句子 ( x 1 , x 2 , . . . x T ) (x_1, x_2, ... x_T) (x1,x2,...xT)。RNN将输出映射成annotation ( h 1 , . . . , h T ) (h_1, ... , h_T) (h1,...,hT)。正如将attention机制引入到encoder-decoder结构中一样,不同于只关注当前的隐藏状态 h t h_t ht,将其作为整个句子的综合概括会失去许多信息,self attention不同的机制也能够将所有的annotation纳入学习的范围。
如下面公式所示,annotation h t h_t ht先被传输到一个全连接层,得到的输出 u t u_t ut被用于和一个可训练的用来表示上下文信息的参数矩阵 u u u(随机初始化)进行比较以得到annotation的分配系数(alignment coefficient),随后用softmax进行归一化。最后得到的聚焦化的向量 s s s是所有annotation的加权和。
u t = t a n h ( W h t ) u_t = tanh(W h_t) ut=tanh(Wht)
α t , i = e x p ( s c o r e ( u t , u ) ) ∑ t ‘ = 1 T e x p ( s c o r e ( u t ‘ , u ) ) \alpha_{t,i} = \frac {exp(score(u_t, u))}{\sum _{t^‘=1} ^{T} exp(score(u_{t^‘},u))} αt,i=∑t‘=1Texp(score(ut‘,u))exp(score(ut,u))
s = ∑ t = 1 T α t h t s = \sum _{t=1} ^{T} \alpha_t h_t s=t=1∑Tαtht
score函数理论上可以是任意的比较函数。一个简单的得分函数是 s c o r e ( u t , u ) = u t ⊤ u score(u_t, u) = u_t^ \top u score(ut,u)=ut⊤u
1.2.1
上面提及的上下文向量(context vector)和seq2seq模型的中context vector毫无联系!在seq2seq模型中,context vector c t c_t ct是encoder所有隐藏状态的加权和 ∑ i = 1 T x α t , i h ‾ i \sum _{i=1} ^{T_x} \alpha _{t,i} {\overline h}_i ∑i=1Txαt,ihi,然后 c t c_t ct 和decoder的隐藏状态 h t h_t ht共同用于计算聚焦化的隐藏状态 h ~ = t a n h ( W c [ c t ; h t ] ) \widetilde h = tanh(W_c [c_t;h_t]) h =tanh(Wc[ct;ht])。self attention中的上下文向量只是用来代替decoder的隐藏状态用于计算 s c o r e ( ) score() score(),实际上self attention模型中并没有decoder模块。所以,self attention中的分配系数矩阵指示了上下文中各个单词之间的关联,而seq2seq模型中的上下文向量 α t \alpha _t αt代表的是source sentence中各词和即将生成的target词汇之间的关联。
1.2.2
下面图片展示了一个实际应用self attention的层次模型,其中self attention在两个层次起作用:单词层次和句子层次。这样做的理由有两个:如何自然语言的层次结构,词汇组成语句,语句组成文本;第二,这样使得模型可以学习到句子中需要重点关注的词和文本中需要重点关注的句子。由于各个sentence的attentonal coefficient不同,各个句子下的各单词的attentional coefficients可以是不同的,这使得一个句子中某个单词的十分重要,到到了另一个句子中这个单词就变的不那么重要了。

[1] Bahdanau, Dzmitry, Kyunghyun Cho, and Yoshua Bengio. “Neural machine translation by
jointly learning to align and translate.” arXiv preprint arXiv:1409.0473 (2014).
[2] Luong, Minh-Thang, Hieu Pham, and Christopher D. Manning. “Effective approaches to
attention-based neural machine translation.” arXiv preprint arXiv:1508.04025 (2015).















 1147
1147











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









