







 本文介绍了RFAConv,一种用于YOLOv5的新型空间注意力机制,旨在提升卷积神经网络的性能。RFAConv通过关注感受野空间特征,解决参数共享问题,并提高大尺寸卷积核的效率,从而改善目标检测的精度和速度。文章详细解析了RFAConv的结构,提供了核心代码和修改教程,以及不同位置添加RFAConv的建议。
本文介绍了RFAConv,一种用于YOLOv5的新型空间注意力机制,旨在提升卷积神经网络的性能。RFAConv通过关注感受野空间特征,解决参数共享问题,并提高大尺寸卷积核的效率,从而改善目标检测的精度和速度。文章详细解析了RFAConv的结构,提供了核心代码和修改教程,以及不同位置添加RFAConv的建议。
一、本文介绍
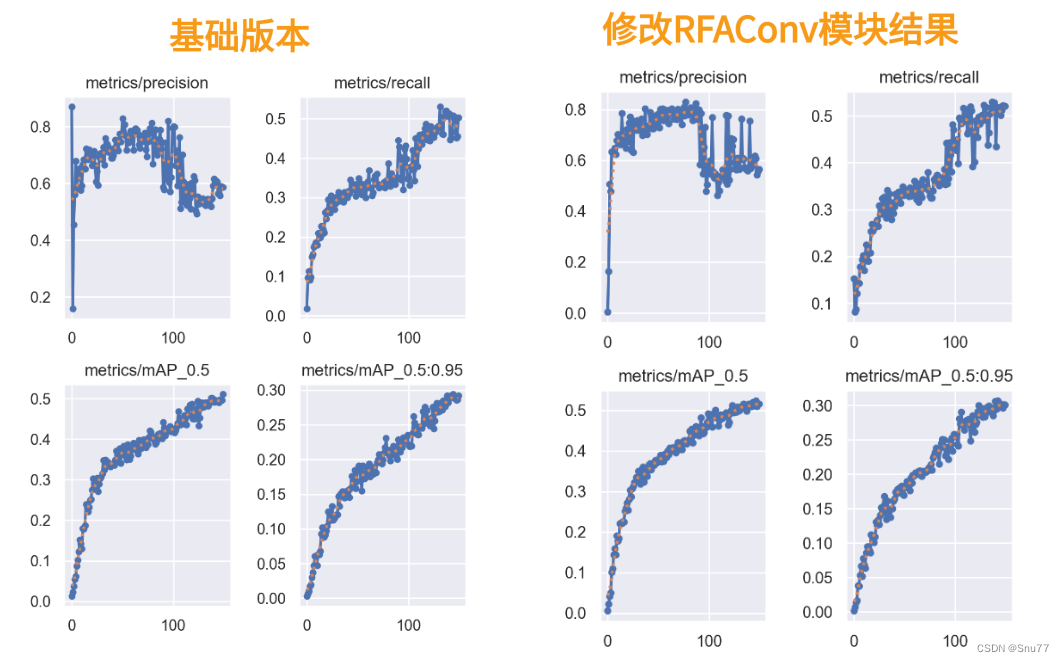
本文给大家带来的改进机制是RFAConv,全称为Receptive-Field Attention Convolution,是一种全新的空间注意力机制。与传统的空间注意力方法相比,RFAConv能够更有效地处理图像中的细节和复杂模式(适用于所有的检测对象都有一定的提点)。这不仅让YOLOv5在识别和定位目标时更加精准,还大幅提升了处理速度和效率。本文章深入会探讨RFAConv如何在YOLOv5中发挥作用,以及它是如何改进在我们的YOLOv5中的。我将通过案例的角度来带大家分析其有效性(结果训练结果对比图)。
适用检测目标:亲测所有的目标检测均有一定的提点
推荐指数:⭐⭐⭐⭐⭐
目录

 订阅专栏 解锁全文
订阅专栏 解锁全文



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











