







基于Python实现的个性化推荐阅读系统的设计与实现背景,可以从以下几个方面进行详细阐述:
一、系统开发背景
随着互联网技术的飞速发展,数字化阅读已成为人们获取信息的重要方式。然而,面对海量的图书和电子资源,用户往往难以快速找到符合自己兴趣和需求的阅读材料。因此,开发一个能够根据用户历史行为和偏好进行个性化推荐的阅读系统显得尤为重要。Python作为一种简洁、高效且易上手的编程语言,在数据分析和机器学习领域具有广泛应用,因此成为构建个性化推荐阅读系统的理想选择。
二、市场需求分析
-
用户群体:
- 广大阅读爱好者:他们希望在阅读过程中能够快速找到符合自己兴趣和需求的书籍或文章。
- 学者和研究人员:他们需要获取与自己研究领域相关的最新文献和资料。
- 教育工作者和学生:他们需要获取与教学和学习相关的书籍和资料,以提高教学效果和学习效率。
-
功能需求:
- 个性化推荐:根据用户画像和内容特征,为用户推荐符合其兴趣的阅读材料。
- 用户反馈机制:允许用户对推荐结果进行反馈,以便系统不断优化推荐算法。
三、技术发展背景
- 数据处理技术:Python拥有丰富的数据处理库,如Pandas、NumPy等,可以高效地处理和分析用户数据。
- Web开发框架:使用Django框架,可以方便地构建后端服务,实现数据的存储、检索和推荐结果的展示。这些框架提供了丰富的功能,如用户认证、权限控制、数据库管理等,有助于快速搭建一个稳定、可扩展的推荐系统。
四、系统设计与实现背景
基于Python的个性化推荐阅读系统的设计与实现需要经历以下关键步骤:
- 需求分析:明确系统的功能需求,包括用户画像构建、内容特征提取、个性化推荐和用户反馈机制等。
- 系统设计:设计系统的架构,包括前端展示、后端服务、数据库存储等部分。前端负责展示推荐结果和用户界面,后端负责处理用户请求、执行推荐算法等任务,数据库用于存储用户数据、内容数据以及推荐结果等。
- 算法选择与实现:选择合适的推荐算法,并根据实际需求进行实现和优化。常见的推荐算法包括协同过滤、基于内容的推荐、混合推荐等。在实现过程中,需要考虑算法的准确性、效率以及可扩展性等因素。
- 系统开发与测试:根据系统设计,使用Python和相关框架进行开发。在开发过程中,需要进行单元测试、集成测试等,以确保系统的稳定性和正确性。同时,还需要对系统进行性能评估,包括响应时间、吞吐量等指标的计算和分析。
- 系统部署与运维:将系统部署到服务器上,并进行运维管理。这包括系统的日常维护、数据备份与恢复、安全防护等工作。同时,还需要对系统进行监控和调优,以确保系统的稳定性和高效性。
五、应用前景与挑战
-
应用前景:
- 提升用户体验:通过个性化推荐,帮助用户快速找到符合其兴趣和需求的阅读材料,提高阅读效率和满意度。
- 促进内容分发:对于内容提供商来说,个性化推荐系统可以提高内容的曝光率和阅读量,从而增加收益和影响力。
- 推动阅读产业发展:个性化推荐系统有助于推动数字化阅读产业的发展和创新,为阅读市场带来更多的机遇和挑战。
综上所述,基于Python实现的个性化推荐阅读系统具有广阔的应用前景和重要的技术价值。通过不断优化算法和模型、提升系统的准确性和性能、加强用户体验和内容分发能力等方面的努力,可以为用户提供更加优质的阅读体验和服务。
软件开发环境及开发工具:
开发语言:python
使用框架:Django
前端技术:JavaScript、VUE.js(2.X)、css3
开发工具:pycharm、Visual Studio Code、HbuildX
数据库:MySQL 5.7.26(版本号)
数据库管理工具:phpstudy/Navicat或者phpstudy/sqlyog
python版本:python3.0及以上
浏览器:谷歌浏览器
本系统功能完整,适合作为计算机项目设计参考 以及学习、就业面试、商用皆可。
下面是资料信息截图:
功能介绍:
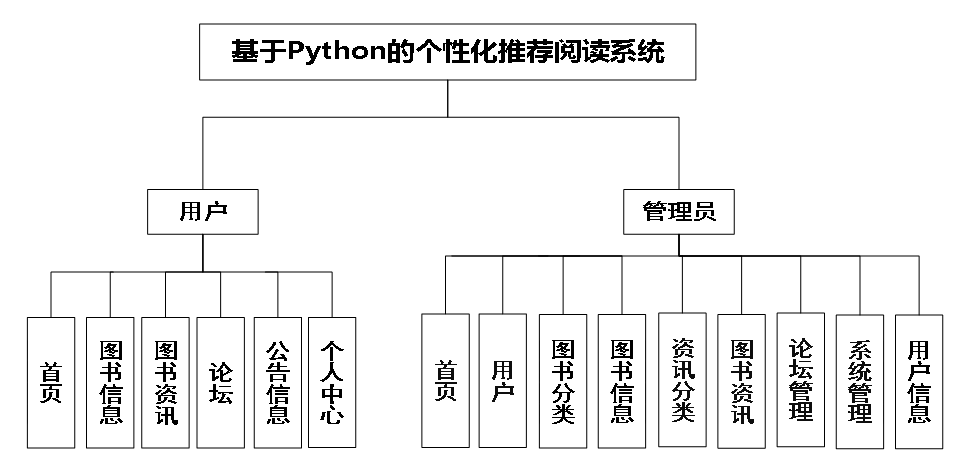
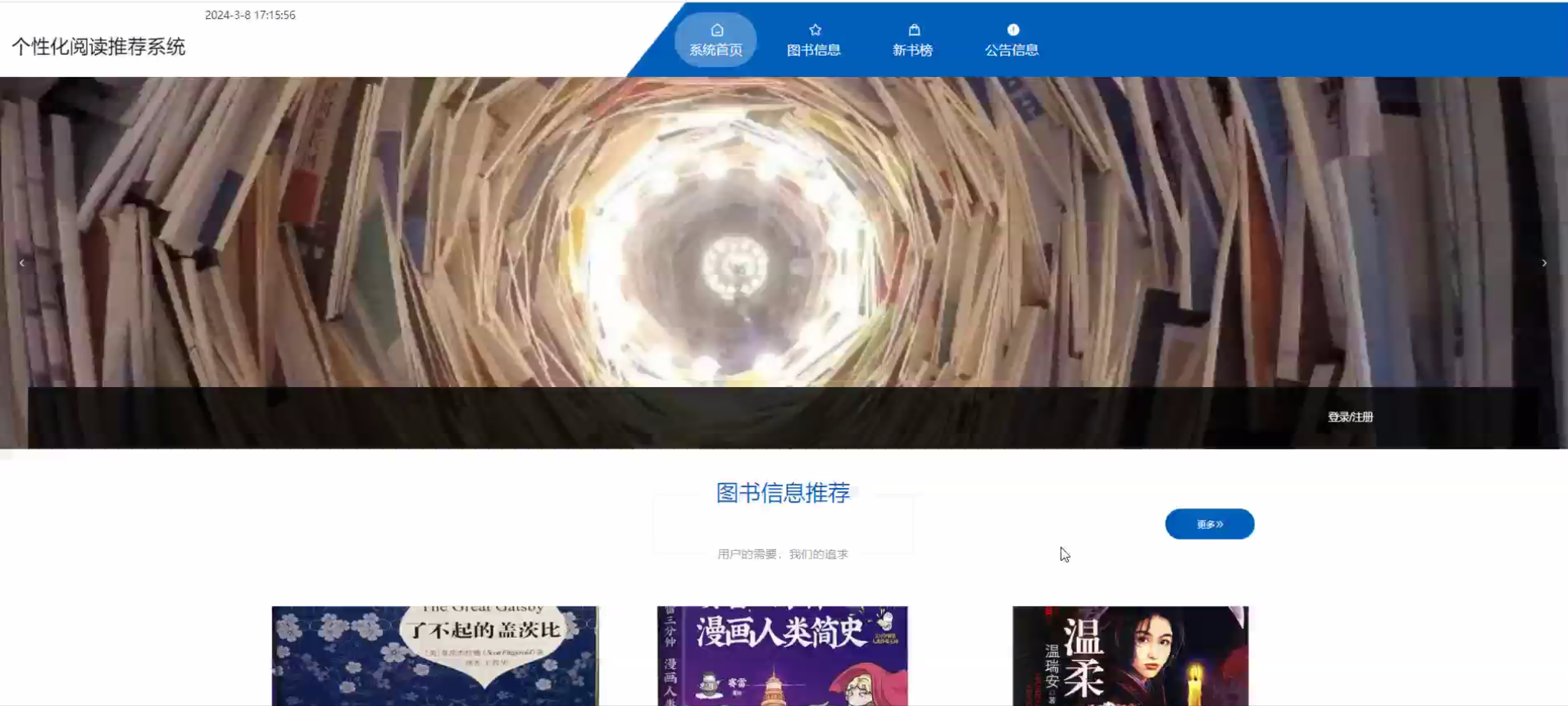
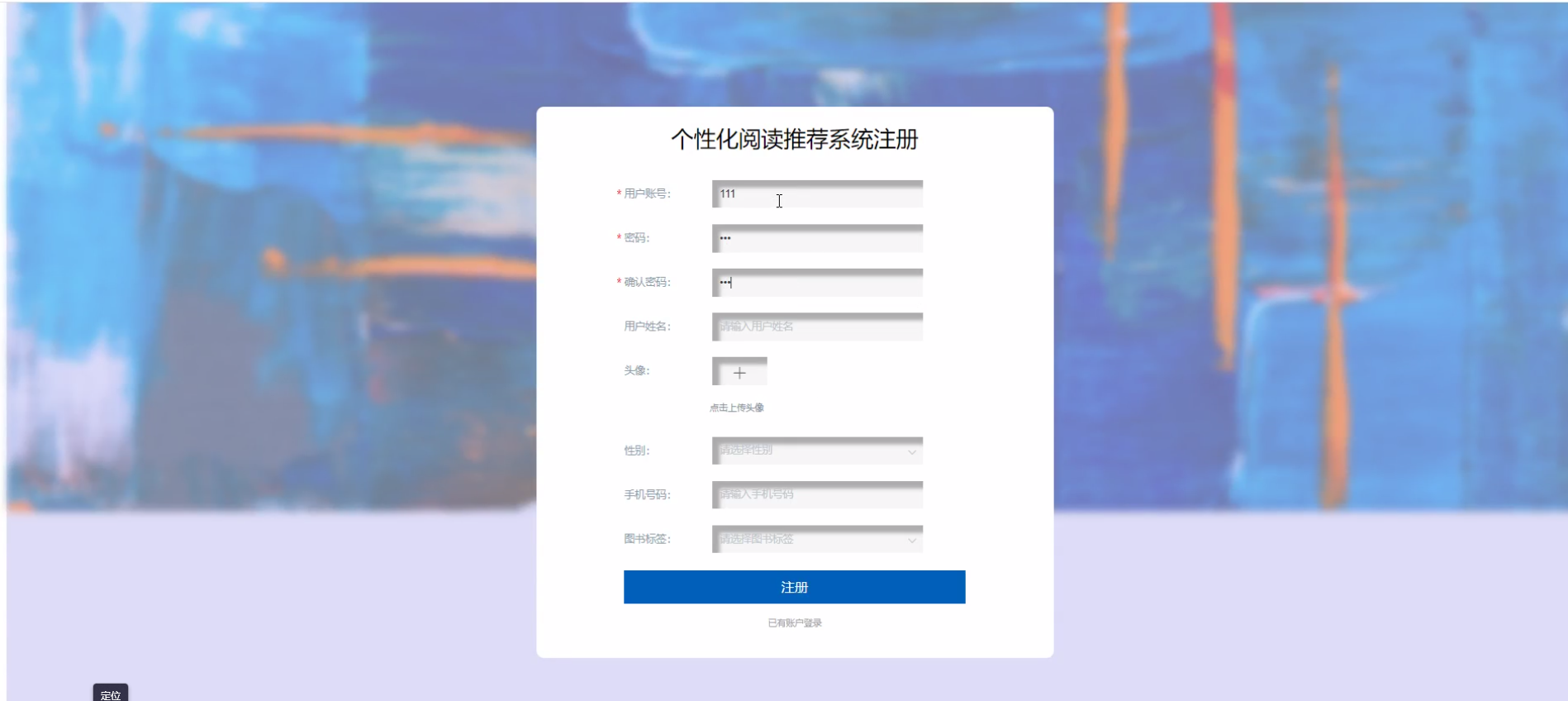
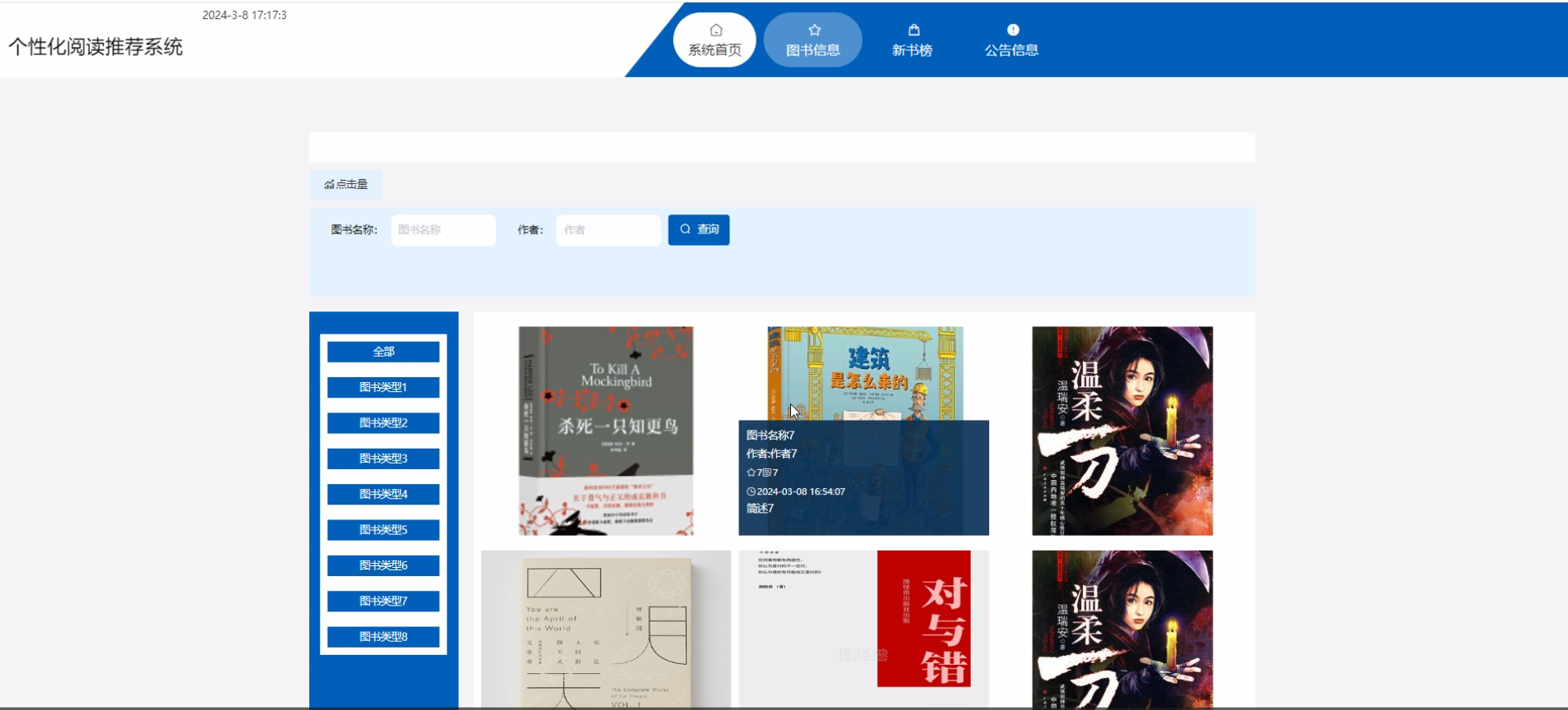
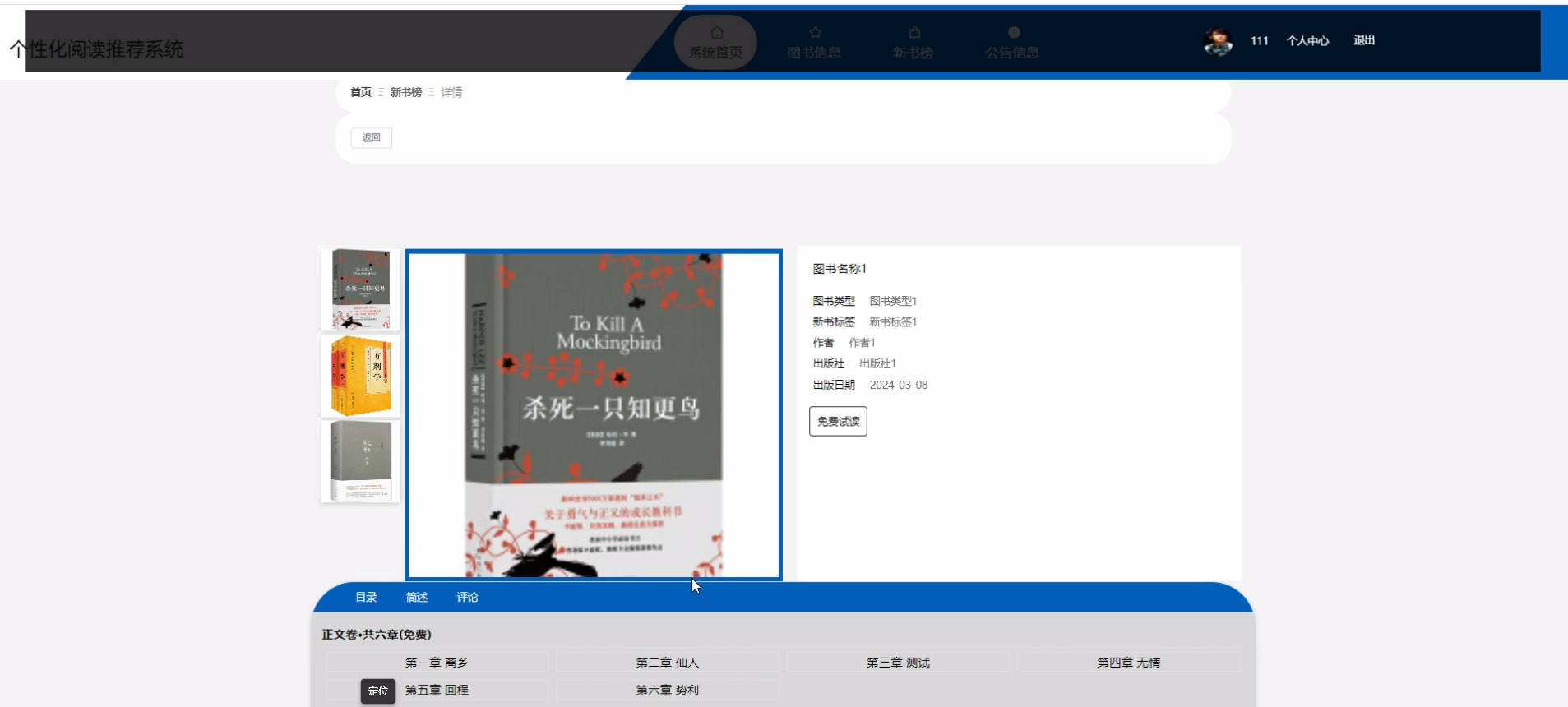
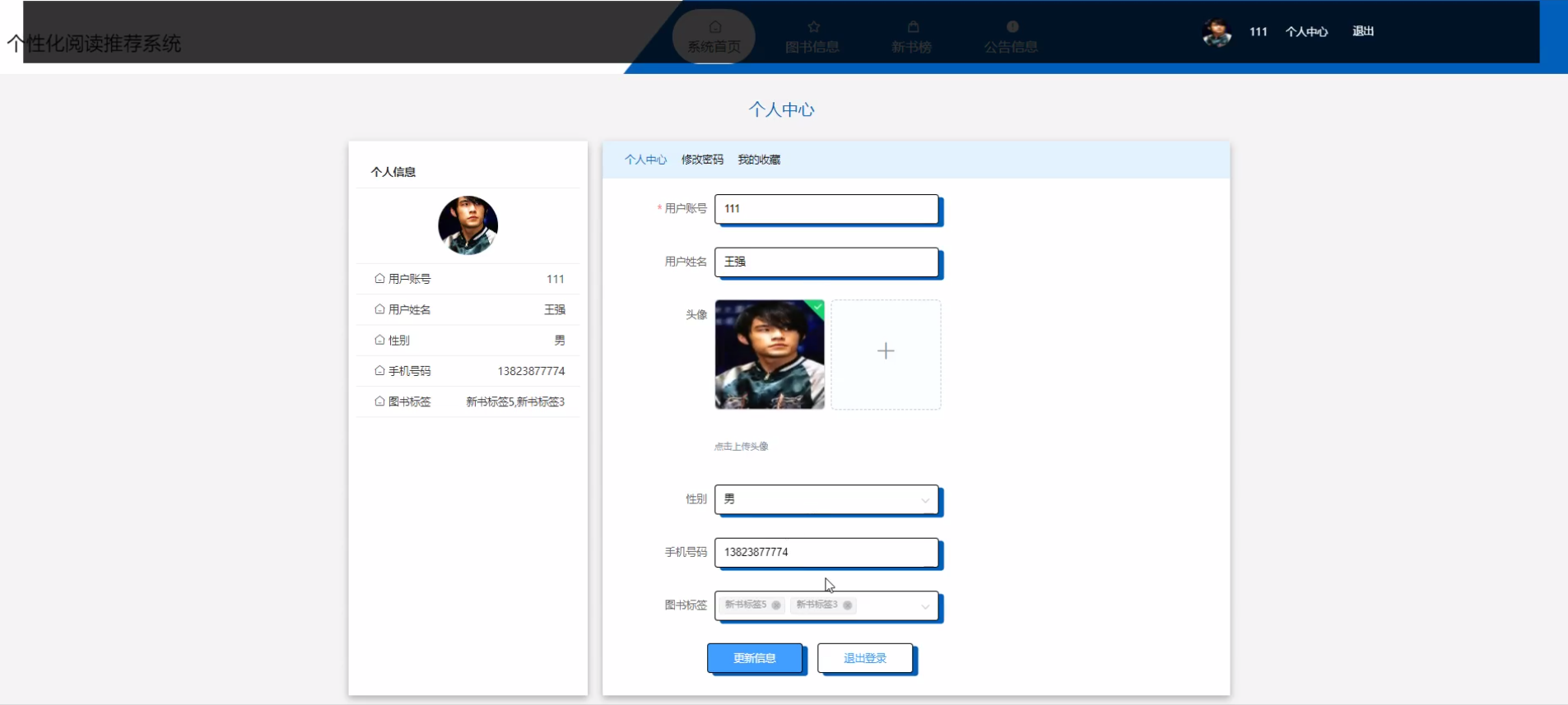
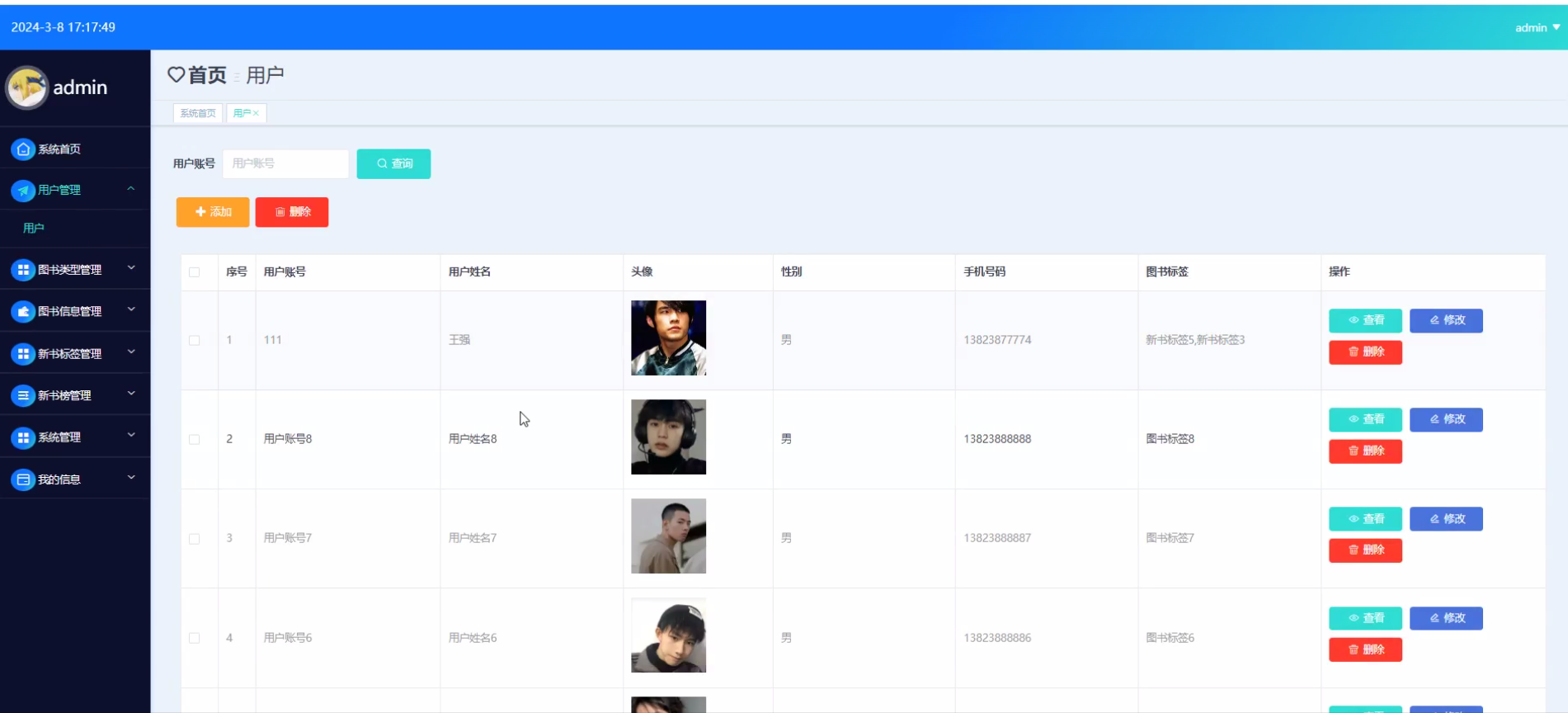
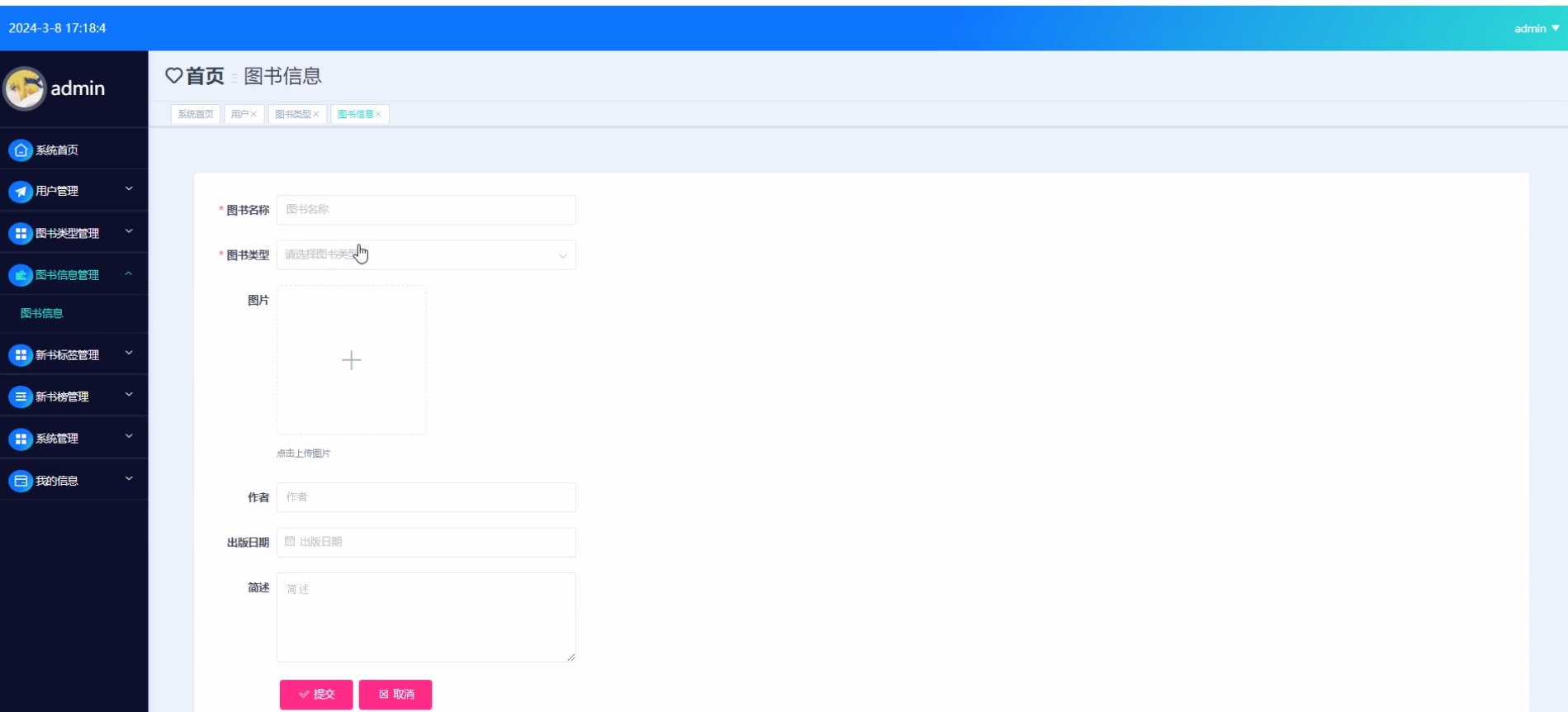
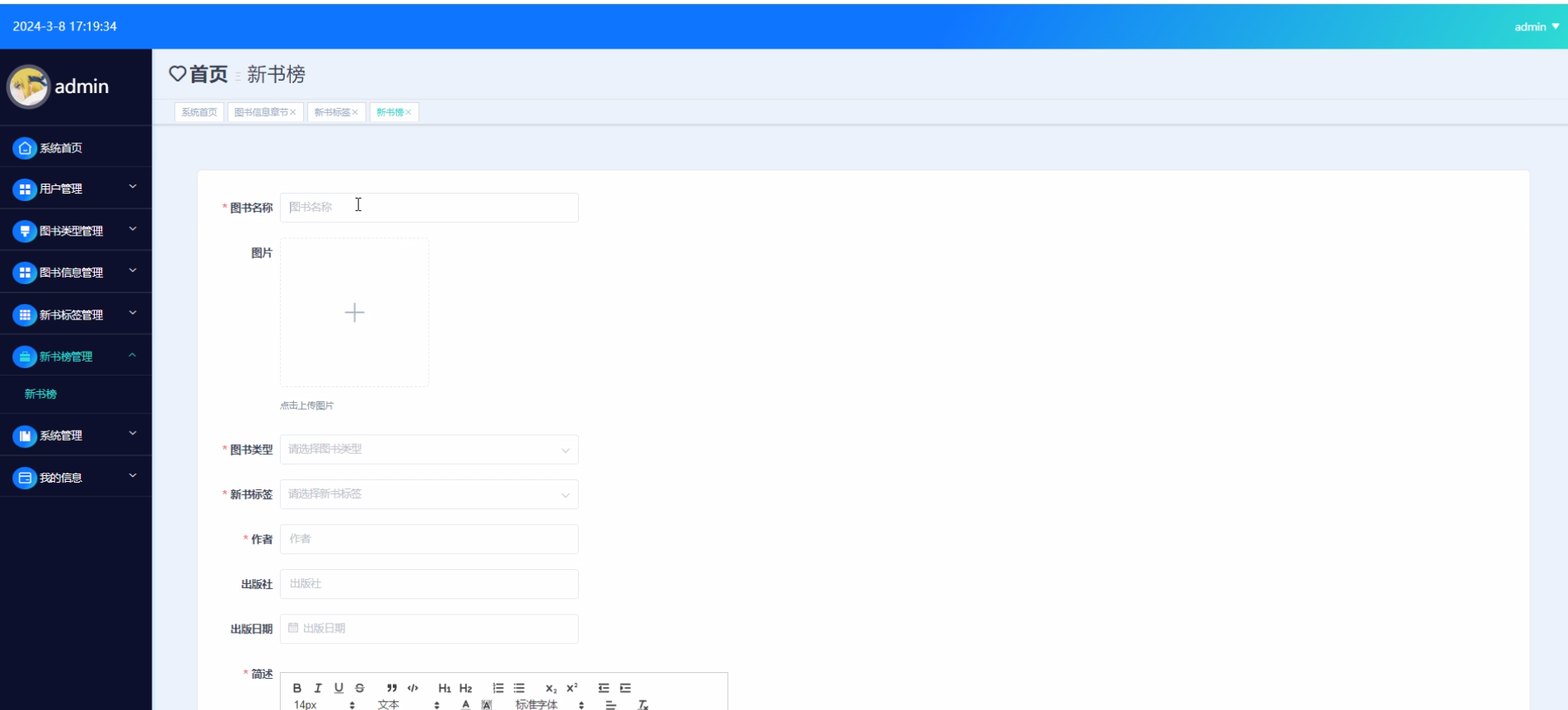
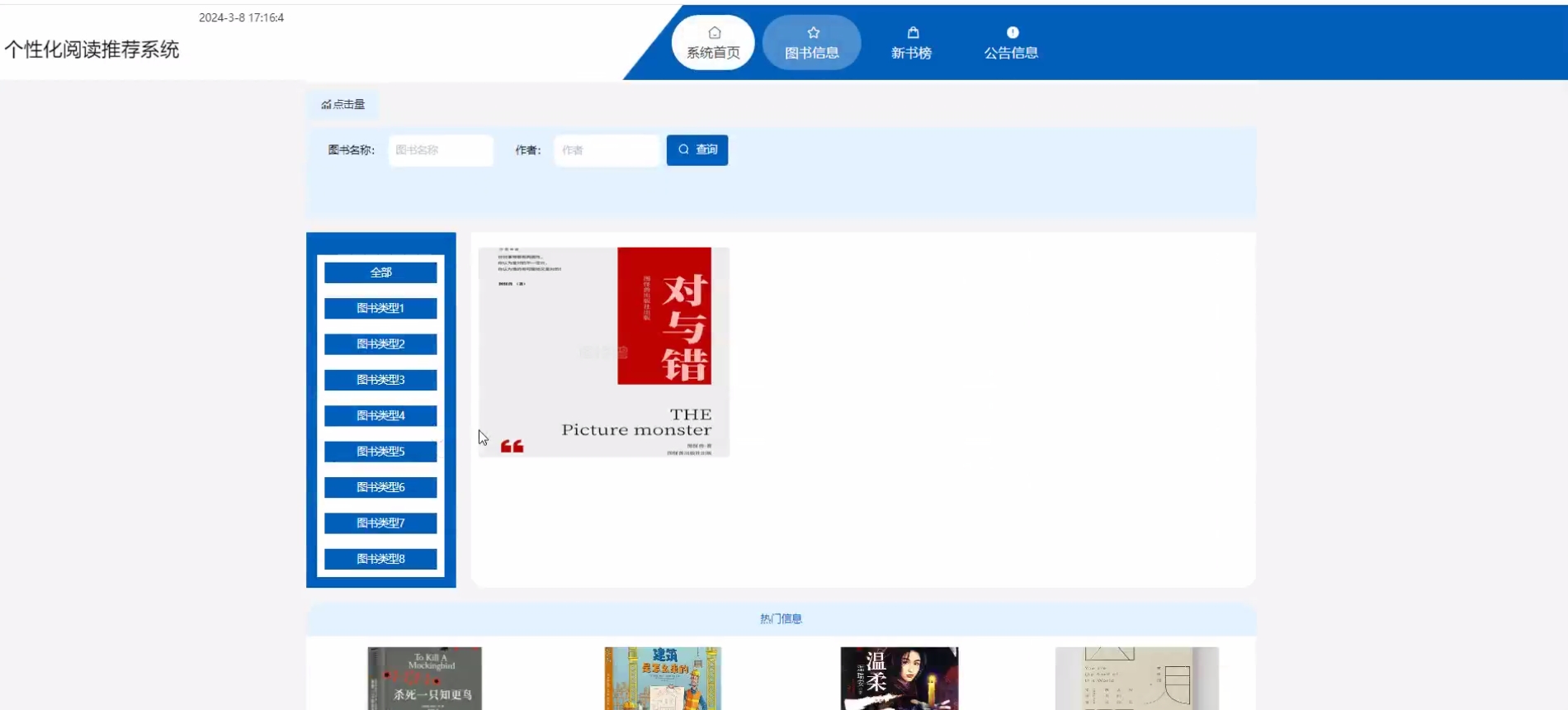
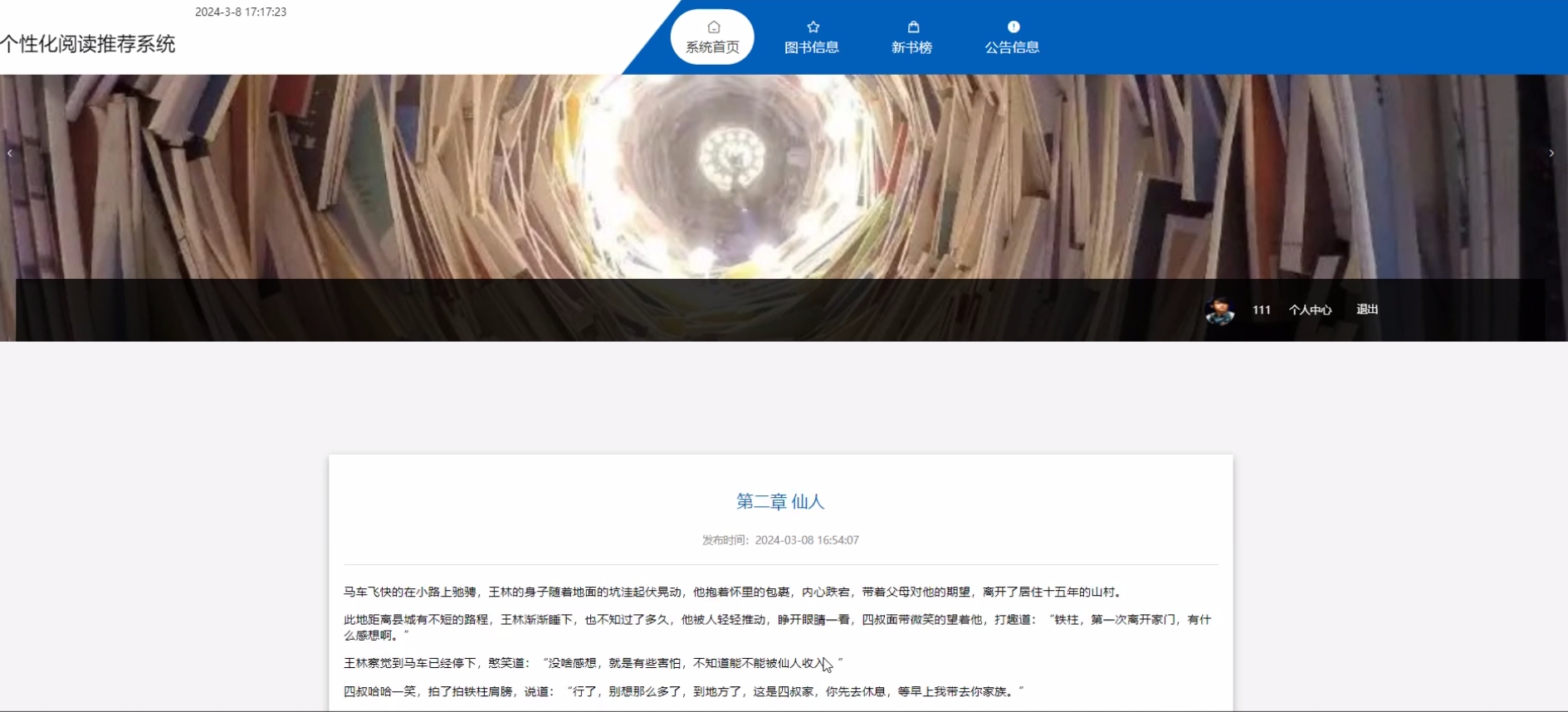
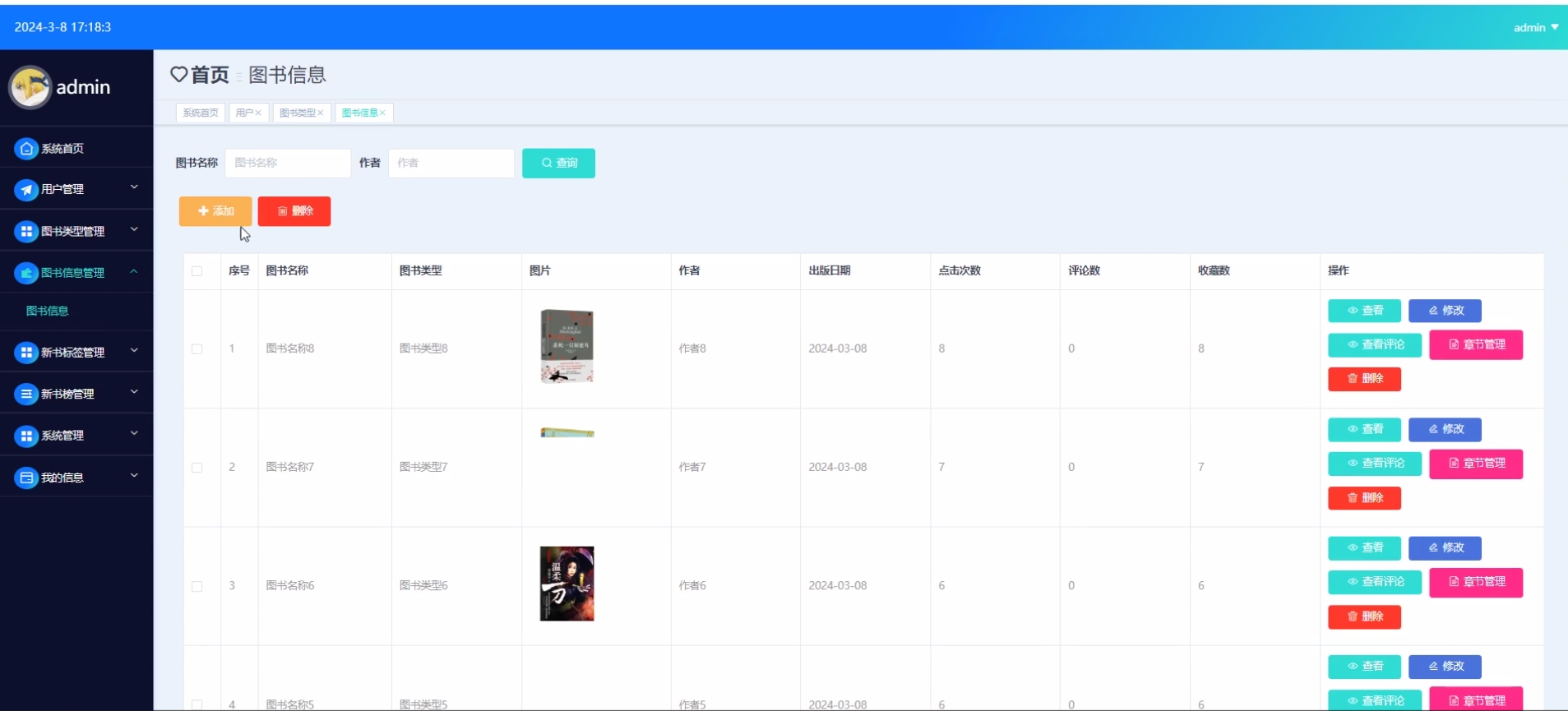
下面是系统运行起来后的一些截图:

















 54
54

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











