






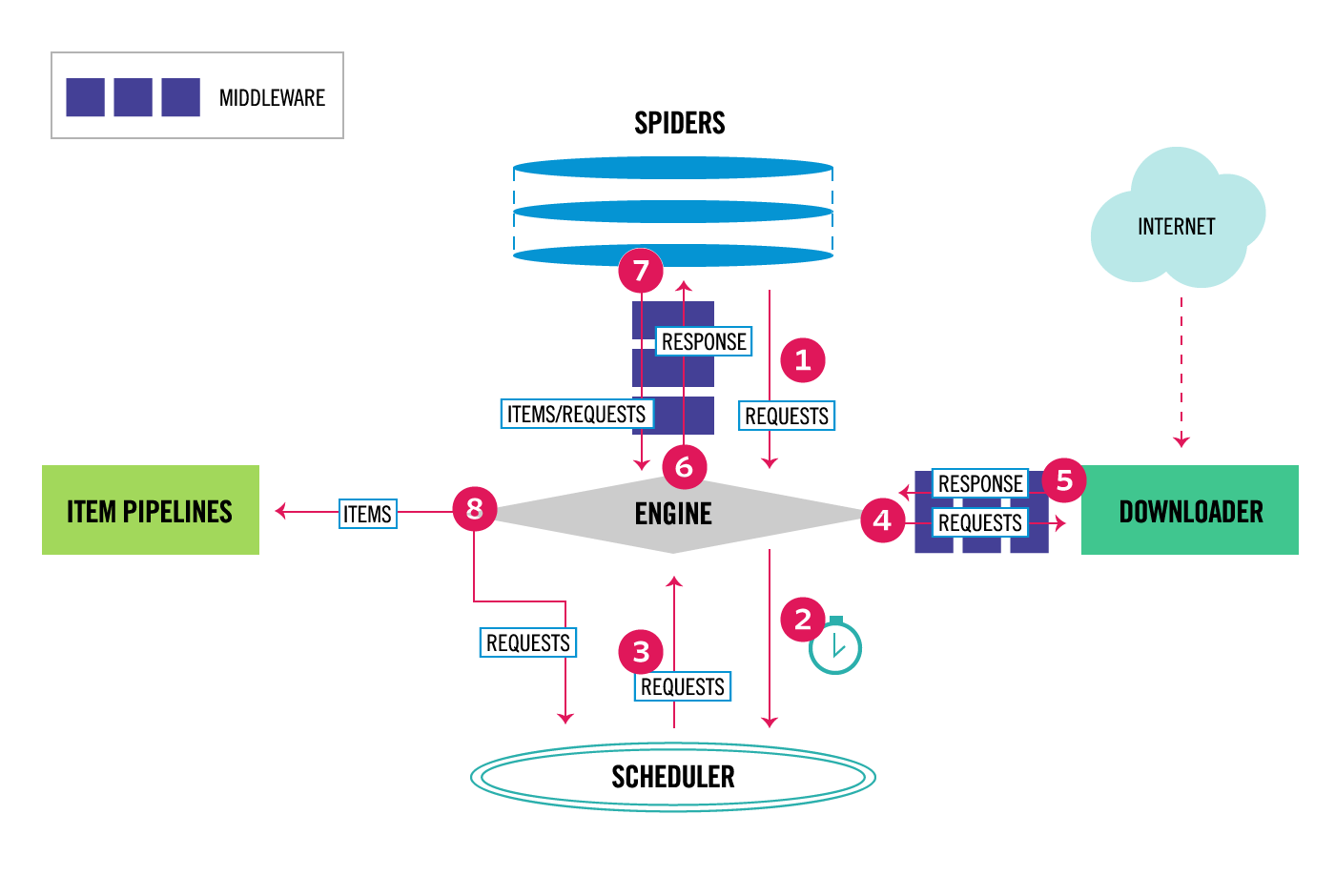
官方文档给出的图片
组件
middleware 中间件
spiders 爬虫,爬取网页,自定义解析爬取的数据
engine 引擎,也就是框架核心处理的部分
scheduler 调度器,调度发起的请求的,框架采用的是异步请求
downloader 下载 ,
item pipelines 管道,用来处理解析数据,进行存储数据等操作
流程
1、spiders向engine发出request
2、engine将request放入scheduler中,有个表的图标,应该想说明的是请求是异步的把
3、scheduler取出request交给engine
4、engine发送通过中间件把request发给downloader,
5、downloader会生成一个Response(带有该页面)并将其通过中间件(请参阅 参考资料process_response())发送到Engine,
6、engine 把通过 downloader 中间件接收来自downloader 的 response
通过爬虫中间件(见process_spider_input())并将其发送给爬虫处理,
7、spiders 通过中间件(见 process_spider_output()),
把处理响应后的item 或 request 发送给engine,
8、engine把要处理的item发送给 itempipelines,
把可能爬取的请求的交给scheduler,
该过程重复(从步骤1开始),直到调度程序不再有请求为止 。
Event-driven networking
Scrapy is written with Twisted, a popular event-driven networking framework for Python. Thus, it’s implemented using a non-blocking (aka asynchronous) code for concurrency.
框架采用Twisted异步请求,抽空了解下
官网
https://doc.scrapy.org/en/latest/topics/architecture.html
高人总结
https://www.cnblogs.com/kongzhagen/p/6549053.html















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









