









工具:
1、VMware® Workstation 12 Pro
2、centos7
3、xshell
4、三台linux虚拟机
- 192.168.20.20 (master节点)
- 192.168.20.21 (node节点)
- 192.168.20.22 (node节点)
安装时最好在纯净的机器上,否则会有很多问题。不过碰到问题也有好处,可以涨姿势~。耐心去逐个解决就是了。
说明:这个教程安装出来的是kubernetes1.5版本,安装目前的k8s最新版(k8s1.20)可以参考这个教程: linux安装最新版kubernetes及使用_水是睡着的冰的博客-CSDN博客
一、安装3台虚拟机
鉴于本次主要是介绍K8s集群搭建,使用VMware安装linux虚拟机的步骤就不介绍了,可以自行去网上搜索教程,很多。
切记,虚拟机要设置固定IP
我们最终得到3台linux机器,如下:
192.168.20.20 (master节点)
192.168.20.21 (node节点)
192.168.20.22 (node节点)
二、部署
如下操作在所有机器执行:
1、安装epel-release源
yum -y install epel-release2、关闭防火墙服务和selinx,避免与docker容器的防火墙规则冲突。
systemctl stop firewalld
systemctl disable firewalld
setenforce 0如下操作在master上执行:
3、yum安装etcd和kubernetes-master
yum install etcd
yum install kubernetes-master4、编辑/etc/etcd/etcd.conf文件:
ETCD_NAME=default
ETCD_DATA_DIR="/var/lib/etcd/default.etcd"
ETCD_LISTEN_CLIENT_URLS="http://0.0.0.0:2379"
ETCD_ADVERTISE_CLIENT_URLS="http://localhost:2379"5、编辑/etc/kubernetes/apiserver文件
KUBE_API_ADDRESS="--insecure-bind-address=0.0.0.0"
KUBE_API_PORT="--port=8080"
KUBELET_PORT="--kubelet-port=10250"
KUBE_ETCD_SERVERS="--etcd-servers=http://127.0.0.1:2379"
KUBE_SERVICE_ADDRESSES="--service-cluster-ip-range=10.254.0.0/16"
KUBE_ADMISSION_CONTROL="--admission-control=NamespaceLifecycle,NamespaceExists,LimitRanger,SecurityContextDeny,ResourceQuota"
KUBE_API_ARGS=""6、启动并设置开机启动etcd、kube-apiserver、kube-controller-manager、kube-scheduler等服务。
for SERVICES in etcd kube-apiserver kube-controller-manager kube-scheduler;
do systemctl restart $SERVICES;
systemctl enable $SERVICES;
systemctl status $SERVICES ;
done注意:上面这段代码要整体复制到命令行执行
7、etcd中定义flannel网络
etcdctl mk /atomic.io/network/config '{"Network":"172.17.0.0/16"}'如下操作在node1、node2:
8、yum安装flannel和kubernetes-node
yum install -y flannel
yum install -y kubernetes-node9、为flannel网络指定etcd服务
修改 /etc/sysconfig/flanneld文件:
FLANNEL_ETCD="http://192.168.20.20:2379" FLANNEL_ETCD_KEY="/atomic.io/network" 注意:这里的192.168.20.20是我们的master的IP
修改/etc/kubernetes/config文件:
KUBE_LOGTOSTDERR="--logtostderr=true" KUBE_LOG_LEVEL="--v=0" KUBE_ALLOW_PRIV="--allow-privileged=false" KUBE_MASTER="--master=http://192.168.20.20:8080"
修改对应node的配置文件/etc/kubernetes/kubelet
Node1:
KUBELET_ADDRESS="--address=0.0.0.0" KUBELET_PORT="--port=10250" KUBELET_HOSTNAME="--hostname-override=192.168.20.21" #修改成Node1的IP KUBELET_API_SERVER="--api-servers=http://192.168.20.20:8080" #指定Master节点的 API Server KUBELET_POD_INFRA_CONTAINER="--pod-infra-container-image=registry.access.redhat.com/rhel7/pod-infrastructure:latest" KUBELET_ARGS=""
Node2:
KUBELET_ADDRESS="--address=0.0.0.0"
KUBELET_PORT="--port=10250"
KUBELET_HOSTNAME="--hostname-override=192.168.20.22" #修改成Node2的IP
KUBELET_API_SERVER="--api-servers=http://192.168.20.20:8080" #指定Master节点的 API Server
KUBELET_POD_INFRA_CONTAINER="--pod-infra-container-image=registry.access.redhat.com/rhel7/pod-infrastructure:latest"
KUBELET_ARGS=""
10、在Node1、Node2上启动kube-proxy,kubelet,docker,flanneld等服务,并设置开机启动
for SERVICES in kube-proxy kubelet docker flanneld;
do systemctl restart $SERVICES;
systemctl enable $SERVICES;
systemctl status $SERVICES;
done注意:上面这段代码要整体复制到命令行执行
三、验证
验证集群是否安装成功
在Master节点上执行:
kubectl get node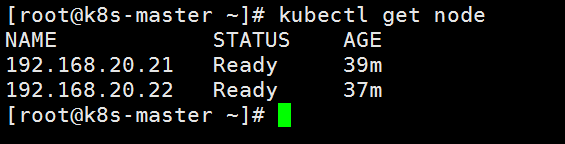
两个Node节点都是Ready状态,至此,部署完毕。很晚了,洗洗睡了~~~
有疑问欢迎大家留言,互相学习,共同进步。
想了一下,我是用之前的旧虚拟机部署的,之前安装过很多软件,中间出现过几个问题。也一起记录到这里:
1、k8s版本冲突出现安装失败,卸载旧的k8s,指令如下:
kubeadm reset -f
modprobe -r ipip
lsmod
rm -rf ~/.kube/
rm -rf /etc/kubernetes/
rm -rf /etc/systemd/system/kubelet.service.d
rm -rf /etc/systemd/system/kubelet.service
rm -rf /usr/bin/kube*
rm -rf /etc/cni
rm -rf /opt/cni
rm -rf /var/lib/etcd
rm -rf /var/etcd
yum clean all
yum remove kube*
2、docker启动失败
Failed to start Docker Application Container Engine.
对应症状如下图:

解决办法:
首先,按照如下内容修改/etc/docker/daemon.json
{
"registry-mirrors":["https://bjtzuljb.mirror.aliyuncs.com"]
}其次,重新加载daemon.json :
systemctl daemon-reload然后,重启docker:
systemctl restart docker最后查看docker启动状态:
systemctl status docker正确的结果如下图:

问题3、yum提示“Cannot retrieve metalink for repository: epel/x86_64” 解决方法:
打开 /etc/yum.repos.d/epel.repo;
注释掉mirrorlist,取消注释baseurl;
将:
[epel]
name=Extra Packages for Enterprise Linux 7 - $basearch
#baseurl=http://download.fedoraproject.org/pub/epel/7/$basearch
mirrorlist=https://mirrors.fedoraproject.org/metalink?repo=epel-7&arch=$basearch
修改为:
[epel]
name=Extra Packages for Enterprise Linux 7 - $basearch
baseurl=http://download.fedoraproject.org/pub/epel/7/$basearch
#mirrorlist=https://mirrors.fedoraproject.org/metalink?repo=epel-7&arch=$basearch
随后再执行
yum clean all
再次使用yum命令即正常!
4、
错误:docker-ce-cli conflicts with 2:docker-1.13.1-203.git0be3e21.el7.centos.x86_64
错误:docker-ce conflicts with 2:docker-1.13.1-203.git0be3e21.el7.centos.x86_64
您可以尝试添加 --skip-broken 选项来解决该问题
您可以尝试执行:rpm -Va --nofiles --nodigest
网上有人说要使用,yum clean all,但是并没有啥用。根本原因还是docker版本冲突了。执行:
yum remove docker*清理掉已经安装的版本,再重试安装就行了。
四、资源操作 问题记录
1、创建pod失败
错误内容:
open /etc/docker/certs.d/registry.access.redhat.com/redhat-ca.crt: no such file or directory
执行命令:
以下需要在kubernetes的master节点和所有node节点上执行
①下载认证相关的插件:
②然后执行安装:
rpm2cpio python-rhsm-certificates-1.19.10-1.el7_4.x86_64.rpm | cpio -iv --to-stdout ./etc/rhsm/ca/redhat-uep.pem | tee /etc/rhsm/ca/redhat-uep.pem
然后删除pod,重新创建。
2、上面第一步的问题解决之后,又出现一个新的问题:
kubelet does not have ClusterDNS IP configured and cannot create Pod using "ClusterFirst" policy. Falling back to DNSDefault policy.
解决方案:
在Node节点的 /etc/kubernetes/kubelet 配置文件中添加如下内容即可:
KUBE_ARGS="--cluster-dns=192.168.1.10 --cluster-domain=cluster.local"
注意上面的IP是master的IP
重启 systemctl daemon-reload; systemctl restart kubelet 即可
部分参考自: k8s入门系列之集群安装篇 - Tivens - 博客园。















 257
257











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









