







1、MySQL的基本架构
- 架构图
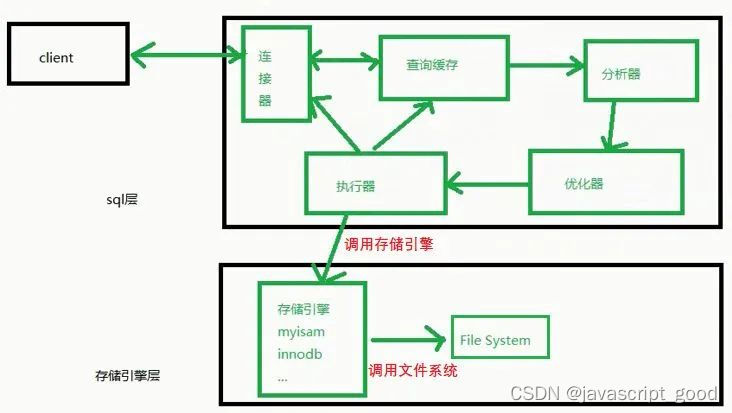
左边的client可以看成是客户端,客户端有很多,像我们经常你使用的CMD黑窗口,像我们经常用于学习的WorkBench,像企业经常使用的Navicat工具,它们都是一个客户端。右边的这一大堆都可以看成是Server(MySQL的服务端),我们将Server在细分为sql层和存储引擎层。
当查询出数据以后,会返回给执行器。执行器一方面将结果写到查询缓存里面,当你下次再次查询的时候,就可以直接从查询缓存中获取到数据了。另一方面,直接将结果响应回客户端。
- 查询数据库的引擎
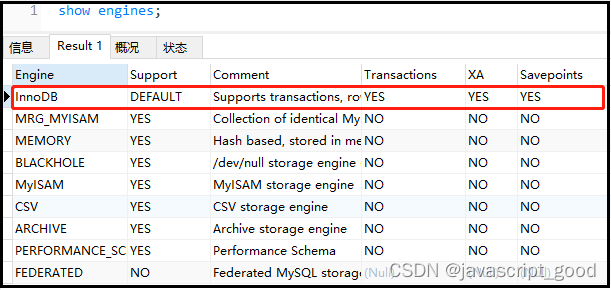
① show engines;
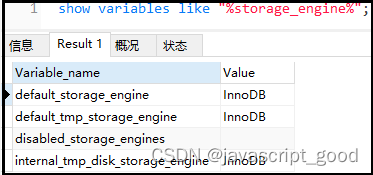
show variables like “%storage_engine%”;
- 指定数据库对象的存储引擎
create table tb(
id int(4) auto_increment,
name varchar(5),
dept varchar(5),
primary key(id)
) engine=myISAM auto_increment=1 default charset=utf8;
2、SQL优化
优化SQL,最重要的就是优化SQL索引。
索引相当于字典的目录。利用字典目录查找汉字的过程,就相当于利用SQL索引查找某条记录的过程。有了索引,就可以很方便快捷的定位某条记录
索引就是帮助MySQL高效获取数据的一种【数据结构】。索引是一种树结构,MySQL中一般用的是【B+树】。
树形结构的特点是:子元素比父元素小的,放在左侧;子元素比父元素大的,放在右侧。
这个图示只是为了帮我们简单理解索引的,真实的关于【B+树】的说明,我们会在下面进行说明。
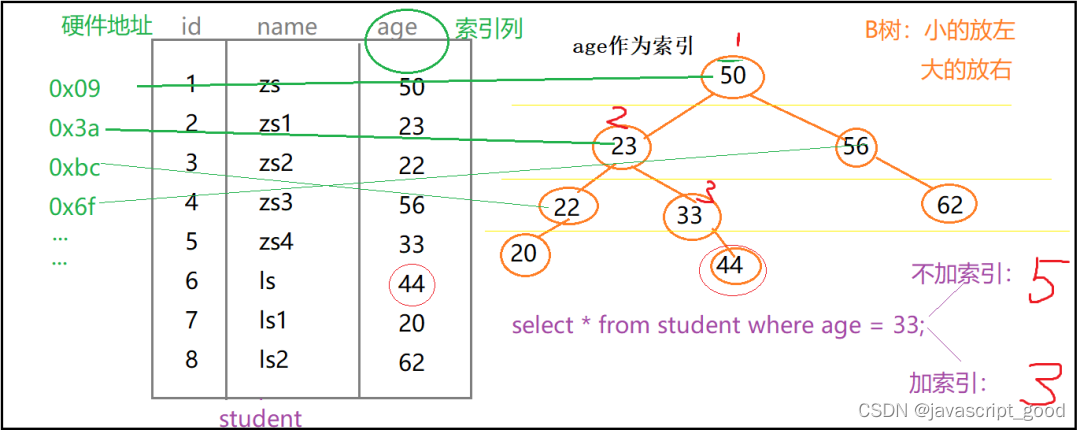
索引是怎么查找数据的呢?两个字【指向】,上图中我们给age列指定了一个索引,即类似于右侧的这种树形结构。mysql表中的每一行记录都有一个硬件地址,例如索引中的age=50,指向的就是源表中该行的标识符(“硬件地址”)。
也就是说,树形索引建立了与源表中每行记录硬件地址的映射关系,当你指定了某个索引,这种映射关系也就建成了,这就是为什么我们可以通过索引快速定位源表中记录的原因。
以【select * from student where age=33】查询语句为例。当我们不加索引的时候,会从上到下扫描源表,当扫描到第5行的时候,找到了我们想要找到了元素,一共是查询了5次。
当添加了索引以后,就直接在树形结构中进行查找,33比50小,就从左侧查询到了23,33大于23,就又查询到了右侧,这下找到了33,整个索引结束,一共进行了3次查找。是不是很方便,假如我们此时需要查找age=62,你再想想“添加索引”前后,查找次数的变化情况。
- 索引的弊端
1.当数据量很大的时候,索引也会很大(当然相比于源表来说,还是相当小的),也需要存放在内存/硬盘中(通常存放在硬盘中),占据一定的内存空间/物理空间。
2.索引并不适用于所有情况:a.少量数据;b.频繁进行改动的字段,不适合做索引;c.很少使用的字段,不需要加索引;
3.索引会提高数据查询效率,但是会降低“增、删、改”的效率。当不使用索引的时候,我们进行数据的增删改,只需要操作源表即可,但是当我们添加索引后,不仅需要修改源表,也需要再次修改索引,很麻烦。尽管是这样,添加索引还是很划算的,因为我们大多数使用的就是查询,“查询”对于程序的性能影响是很大的。
- 索引的优势
1.提高查询效率(降低了IO使用率)。当创建了索引后,查询次数减少了。
2.降低CPU使用率。比如说【…order by age desc】这样一个操作,当不加索引,会把源表加载到内存中做一个排序操作,极大的消耗了资源。但是使用了索引以后,第一索引本身就小一些,第二索引本身就是排好序的,左边数据最小,右边数据最大。
- B+树图示说明
MySQL中索引使用的就是B+树结构。
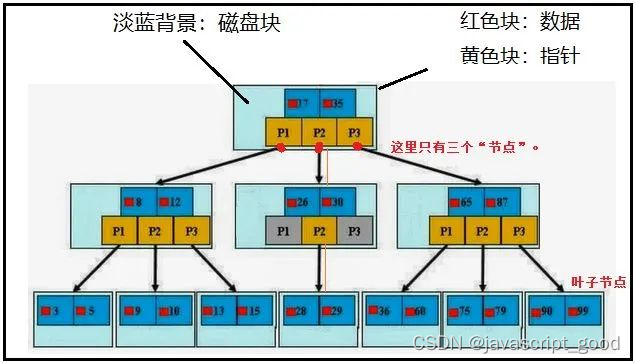
关于B+树的说明:
首先,Btree一般指的都是【B+树】,数据全部存放在叶子节点中。对于上图来说,最下面的第3层,属于叶子节点,真实数据部份都是存放在叶子节点当中的。
那么对于第1、2层中的数据又是干嘛的呢?答:用于分割指针块儿的,比如说小于26的找P1,介于26-30之间的找P2,大于30的找P3。
其次,三层【B+树】可以存放上百万条数据。这么多数据怎么放的呢?增加“节点数”。图中我们只有三个节点。
最后,【B+树】中查询任意数据的次数,都是n次,n表示的是【B+树】的高度。
索引的分类与创建
1、索引分类
- 单值索引 :利用表中的某一个字段创建单值索引。一张表中往往有多个字段,也就是说每一列其实都可以创建一个索引,这个根据我们实际需求来进行创建。还需要注意的一点就是,一张表可以创建多个“单值索引”。
假如某一张表既有age字段,又有name字段,我们可以分别对age、name创建一个单值索引,这样一张表就有了两个单值索引。 - 唯一索引:也是利用表中的某一个字段创建单值索引,与单值索引不同的是:创建唯一索引的字段中的数据,不能有重复值。像age肯定有很多人的年龄相同,像name肯定有些人是重名的,因此都不适合创建“唯一索引”。像编号id、学号sid,对于每个人都不一样,因此可以用于创建唯一索引。
- 复合索引:多个列共同构成的索引。比如说我们创建这样一个“复合索引”(name,age),先利用name进行索引查询,当name相同的时候,我们利用age再进行一次筛选。注意:复合索引的字段并不是非要都用完,当我们利用name字段索引出我们想要的结果以后,就不需要再使用age进行再次筛选了。
2、创建索引
语法:create 索引类型 索引名 on 表(字段);
- 创建索引的第一种方式
创建单值索引
create index dept_index on tb(dept);
创建唯一索引:这里我们假定name字段中的值都是唯一的
create unique index name_index on tb(name);
创建复合索引
create index dept_name_index on tb(dept,name);
- 创建索引的第二种方式
先删除之前创建的索引以后,再进行这种创建索引方式的测试;
语法:alter table 表名 add 索引类型 索引名(字段)
创建单值索引
alter table tb add index dept_index(dept);
创建唯一索引:这里我们假定name字段中的值都是唯一的
alter table tb add unique index name_index(name);
创建复合索引
alter table tb add index dept_name_index(dept,name);
如果某个字段是primary key,那么该字段默认就是主键索引。
主键索引和唯一索引非常相似。相同点:该列中的数据都不能有相同值;不同点:主键索引不能有null值,但是唯一索引可以有null值。
3、索引删除和索引查询
- 索引删除
语法:drop index 索引名 on 表名;
drop index name_index on tb;
- 索引查询
语法:show index from 表名;
show index from tb;
















 4947
4947











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











