








更多相关内容可查看
索引使用
验证索引效率(1000w数据量)
在说索引的使用原则之前,先通过一个简单的案例,来验证一下索引,看看是否能够通过索引来提升数据查询性能。在演示的时候,我们使用准备的一张表 tb_sku , 在这张表中准备了1000w的记录。

这张表中id为主键,有主键索引,而其他字段是没有建立索引的。 我们先来查询其中的一条记录,看看里面的字段情况,执行如下SQL:
select * from tb_sku where id = 1;

可以看到即使有1000w的数据,根据id进行数据查询,性能依然很快,因为主键id是有索引的。 我们再来根据 sn 字段进行查询,执行如下SQL:
SELECT * FROM tb_sku WHERE sn = '100000003145001';

我们可以看到根据sn字段进行查询,查询返回了一条数据,结果耗时 20.78sec,就是因为sn没有索引,而造成查询效率很低。
那么我们可以针对于sn字段,建立一个索引,建立了索引之后,我们再次根据sn进行查询,再来看一下查询耗时情况。
创建索引:
create index idx_sku_sn on tb_sku(sn) ;

然后再次执行相同的SQL语句,再次查看SQL的耗时。
SELECT * FROM tb_sku WHERE sn = '100000003145001';

我们明显会看到,sn字段建立了索引之后,查询性能大大提升。建立索引前后,查询耗时都不是一个数量级的。
单列索引与联合索引性能比对
单列索引:即一个索引只包含单个列。
联合索引:即一个索引包含了多个列。
我们先来看看 tb_user 表中目前的索引情况

在查询出来的索引中,既有单列索引,又有联合索引。接下来,我们来执行一条SQL语句,看看其执行计划:

通过上述执行计划我们可以看出来,在and连接的两个字段 phone、name上都是有单列索引的,但是最终mysql只会选择一个索引,也就是说,只能走一个字段的索引,此时是会回表查询的。
紧接着,我们再来创建一个phone和name字段的联合索引来查询一下执行计划。
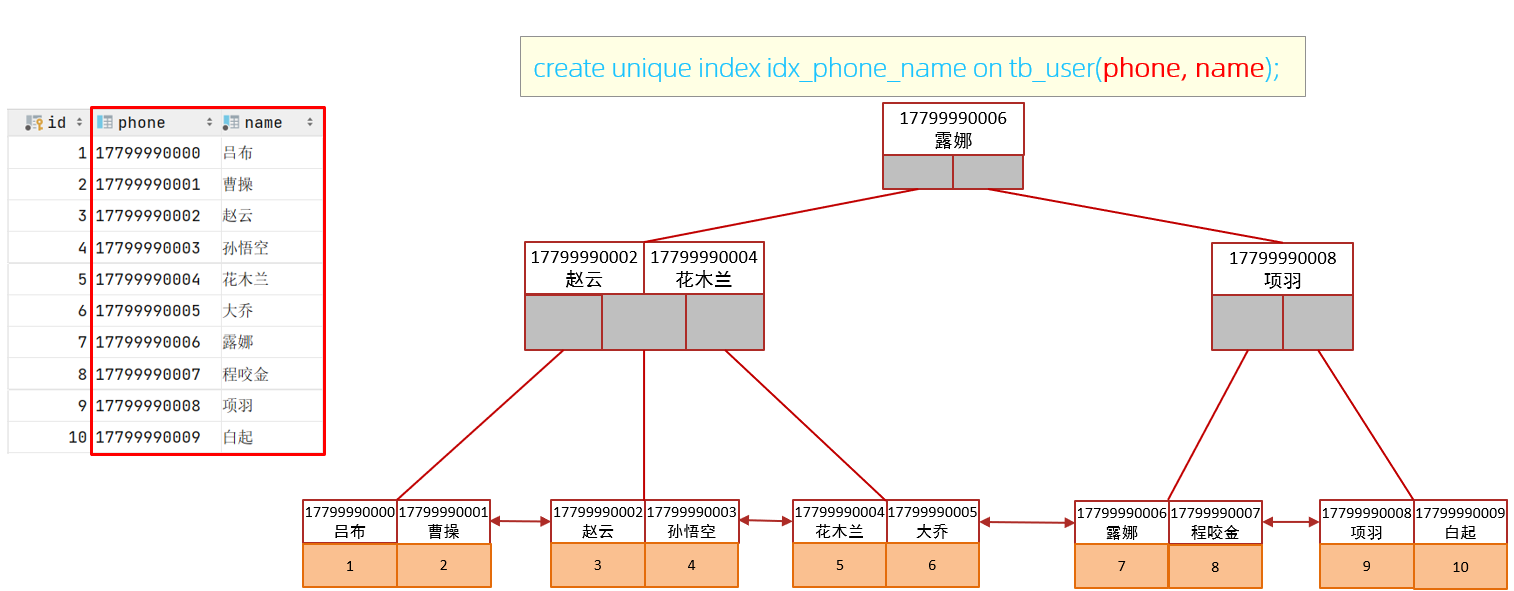
create unique index idx_user_phone_name on tb_user(phone,name);

此时,查询时,就走了联合索引,而在联合索引中包含 phone、name的信息,在叶子节点下挂的是对应的主键id,所以查询是无需回表查询的。
在业务场景中,如果存在多个查询条件,考虑针对于查询字段建立索引时,建议建立联合索引,而非单列索引。
如果查询使用的是联合索引,具体的结构示意图如下:
单例索引与联合索引特点及适用场景
单例索引特点
- 仅针对一个列进行排序和查询优化。
- 查询条件中必须包含该索引列,才能有效地利用该索引。
- 在某些情况下,单列索引可能会导致不必要的I/O操作,因为即使只需要查询少量数据,也可能需要读取整个索引条目。
单例索引特点适用场景:
- 当经常需要根据某一列的值进行快速查询时。
- 该列的值具有较高的唯一性或选择性(即不同的值较多)。
联合索引特点
- 可以基于多个列进行排序和查询优化。
- 查询条件中必须包含索引的最左列(称为最左前缀原则),才能有效地利用该索引。但某些数据库(如MySQL)允许在某些条件下跳过最左列。
- 可以提高多列查询的性能,特别是当这些列经常一起出现在查询条件中时。
- 相对于多个单列索引,联合索引通常占用的存储空间更少,因为索引条目只需要存储一次。
联合索引适用场景:
- 当经常需要根据多个列的值进行快速查询时。
- 这些列的值组合在一起时具有较高的唯一性或选择性。
注:
- 索引选择:在选择使用单列索引还是联合索引时,需要仔细考虑查询模式和数据特性。在某些情况下,使用联合索引可能更有效率,而在其他情况下,使用多个单列索引可能更为合适。
- 索引维护:索引虽然可以提高查询性能,但也会增加数据插入、更新和删除的开销。因此,在创建索引时需要权衡这些成本。
- 查询优化:在编写SQL查询时,应尽量利用索引来提高性能。例如,可以通过重新排列查询条件中的列顺序来匹配联合索引的最左前缀原则。
- 索引分析:定期分析索引的使用情况和性能影响,并根据需要进行调整和优化。这可以通过查询数据库的性能统计信息或使用专门的工具来完成。
最左前缀法则
如果索引了多列(联合索引),要遵守最左前缀法则。最左前缀法则指的是查询从索引的最左列开始,并且不跳过索引中的列。如果跳跃某一列,索引将会部分失效(后面的字段索引失效)。
以 tb_user 表为例,查看一下之前 tb_user 表所创建的索引。

在 tb_user 表中,有一个联合索引,这个联合索引涉及到三个字段,顺序分别为:profession,age,status。
对于最左前缀法则指的是,查询时,最左边的列,也就是profession必须存在,否则索引全部失效。 而且中间不能跳过某一列,否则该列后面的字段索引将失效。 接下来,我们来演示几组案例,看一下具体的执行计划:
explain select * from tb_user where profession = '软件工程' and age = 31 and status = '0';

explain select * from tb_user where profession = '软件工程' and age = 31;

explain select * from tb_user where profession = '软件工程';

以上的这三组测试中,我们发现只要联合索引最左边的字段 profession存在,索引就会生效,只不过索引的长度不同。 而且由以上三组测试,我们也可以推测出profession字段索引长度为47、age字段索引长度为2、status字段索引长度为5。
explain select * from tb_user where age = 31 and status = '0';

explain select * from tb_user where status = '0';

而通过上面的这两组测试,我们也可以看到索引并未生效,原因是因为不满足最左前缀法则,联合索引最左边的列profession不存在。
explain select * from tb_user where profession = '软件工程' and status = '0';

上述的SQL查询时,存在profession字段,最左边的列是存在的,索引满足最左前缀法则的基本条件。但是查询时,跳过了age这个列,所以后面的列索引是不会使用的,也就是索引部分生效,所以索引的长度就是47。
思考题:
当执行SQL语句:explain select * from tb_user where age = 31 and status = '0' and profession = '软件工程'时是否满足最左前缀法则,走不走上述的联合索引
可以看到,是完全满足最左前缀法则的,索引长度54,联合索引是生效的。
注意 : 最左前缀法则中指的最左边的列,是指在查询时,联合索引的最左边的字段(即是第一个字段)必须存在,与我们编写SQL时,条件编写的先后顺序无关。

本篇小结
有小伙伴对其他数据库内容感兴趣,可以通过以下链接进行查看
数据库-索引(基础篇)
数据库-索引结构(B-Tree,B+Tree,Hash,二叉树)
数据库-索引语法(增删查)
数据库-索引分类(主键索引、唯一索引、普通索引、全文索引)
数据库-索引使用(验证索引效率、单列索引与联合索引、最左前缀法则)
索引失效情况

















 408
408

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











