






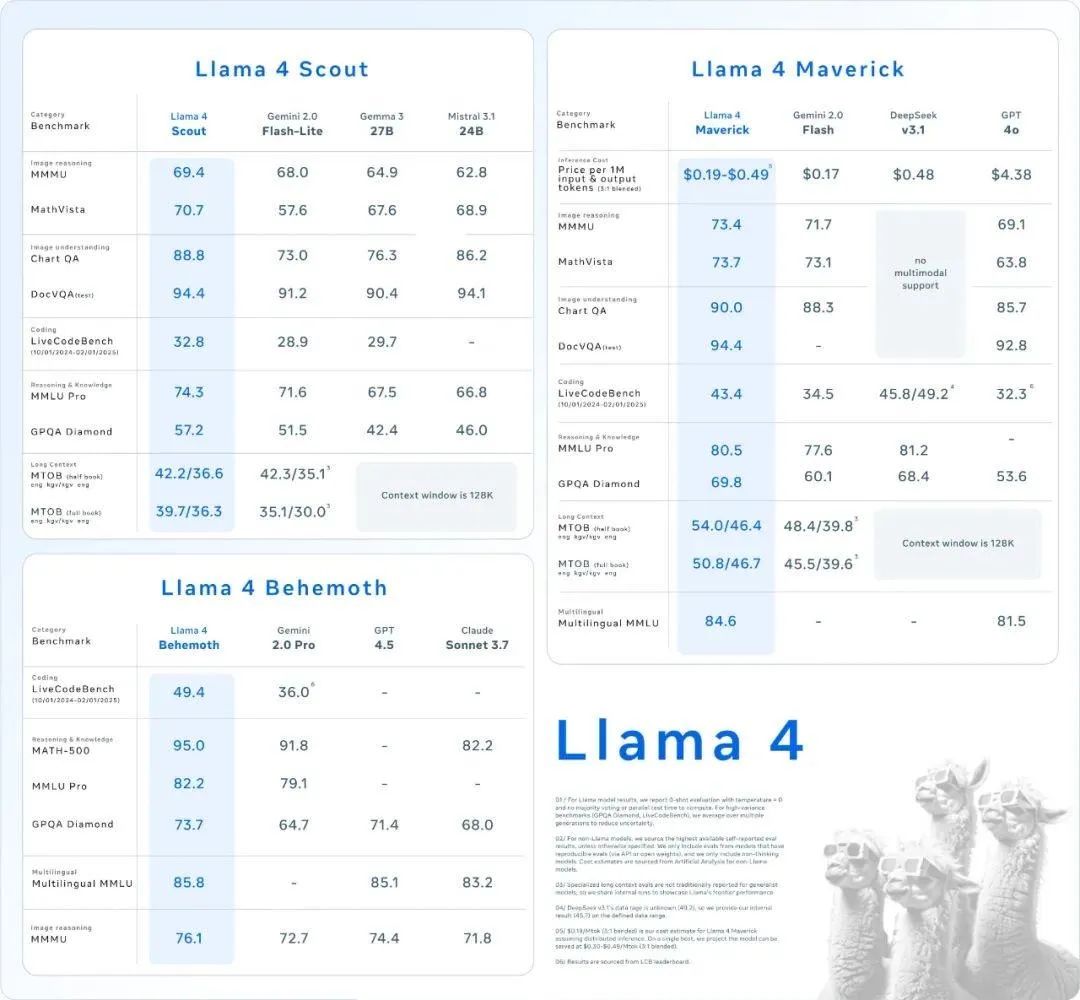
最近,大模型领域的新模型真是层出不穷,前两天Meta 发布了 Llama 4 系列新模型,包括 Llama 4 Scout、Llama 4 Maverick 等,登顶多个榜单,宣称开源第一!
听说,阿里新模型 Qwen3 也会在这周发布,其重点优化推理效能,在中文 QA 和数学推理任务表现可能会超越 GPT-4o;
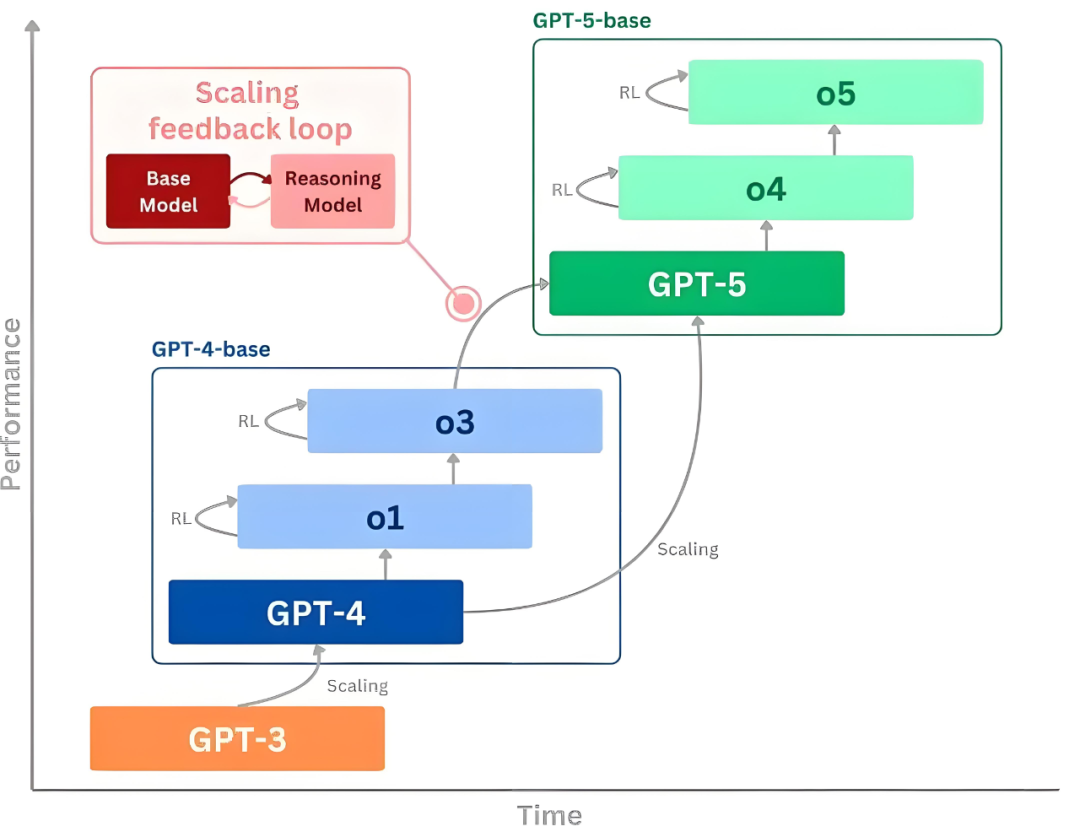
OpenAI 将在发布 GPT-5 前,先推出 o3 和 o4-mini 两个中级大模型,可能在几周后推出,而 GPT-5 预计将完全实现多模式 。
那DeepSeek-R2什么时候发布?距离上次DeepSeek-R1的发布已经过去将近三个月了。4月4日,DeepSeek 与清华大学联合发布的论文,引发广泛热议,R2 的发布愈发成为众人瞩目的焦点。
DeepSeek新论文透出的信号:推理时Scaling与奖励模型的突破
近期,AI圈的火热程度已经达到白热化的地步,而这一次,DeepSeek 扔出一篇论文,直接把圈子炸得鸡飞狗跳。
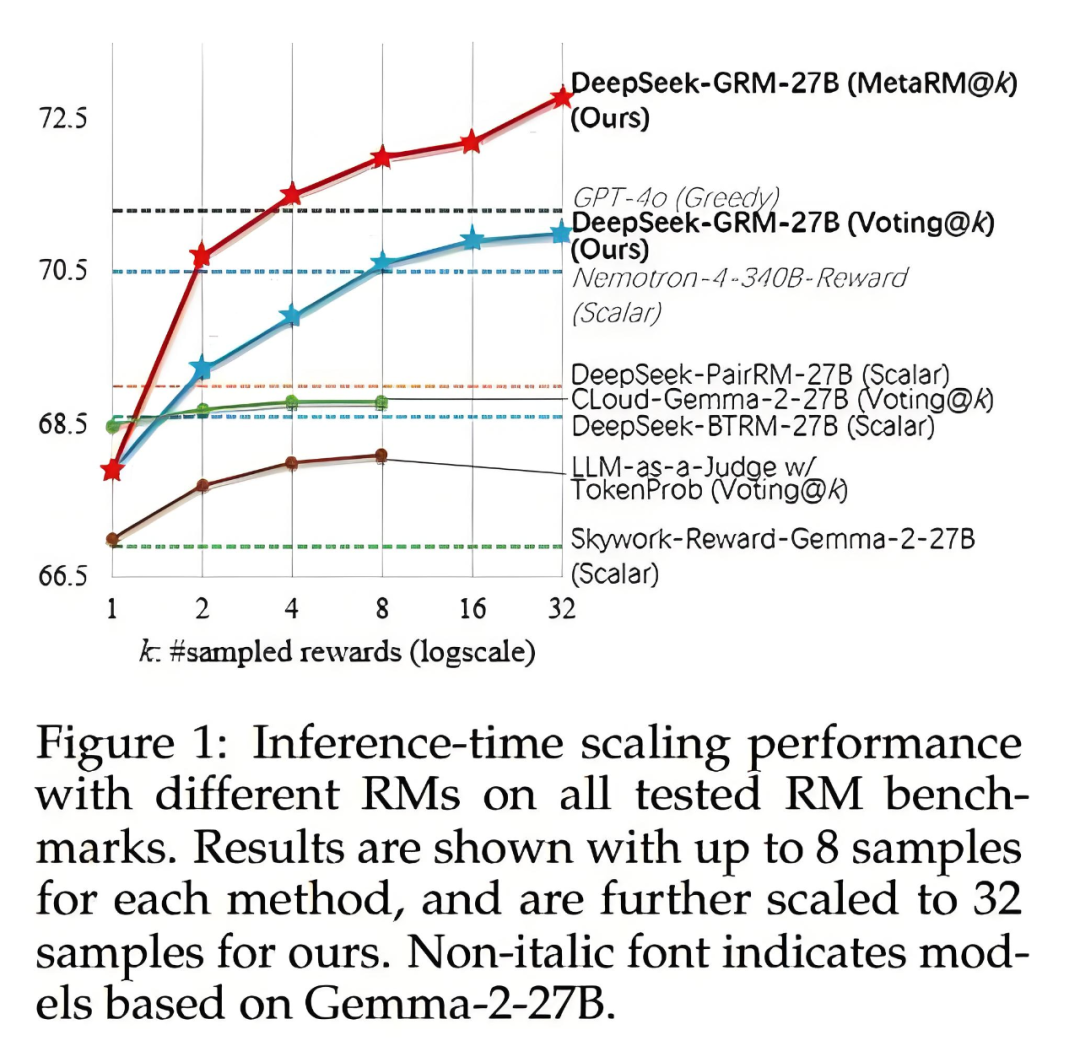
DeepSeek的这篇论文探讨了推理时扩展在通用奖励建模中的应用。通过采用点对生成式奖励建模(GRM),论文展示了如何通过增加推理计算资源来提高奖励模型的灵活性和准确性。
此外,论文提出了一种自原则性批评调整(SPCT)方法,通过在线强化学习优化奖励生成行为。为了实现有效的推理时扩展,论文还引入了并行采样和元奖励建模。实验结果表明,该方法在多个基准测试中优于现有方法,显示出良好的扩展性和无偏性。
从论文判断,R2或许不会盲目追求参数量,而是靠推理优化和奖励机制革新进行突破。
论文的标题堪称硬核:《Inference-Time Scaling for Generalist Reward Modeling》。

*论文链接:*https://arxiv.org/abs/2504.02495
你没听错,就是“推理时刻的扩展”——AI的推理能力大幅提升,瞬间打破了常规!简单来说,AI 推理开挂了!
国外的键盘侠们已经开始欢呼:“ R2要来了,OpenAI 得瑟瑟发抖了吧!” 这热闹自己人不看能行吗?
1、推理能力是 AI Agent 发动机
OpenAI CEO 年初就喊话:“今年是 AI 智能体元年!”
DeepSeek 踩准了风口。他们的 “SPCT” 技术让 AI 推理能力翻倍。
论文里,DeepSeek-GRM-27B(270亿参数)靠SPCT加持,性能吊打671亿参数的大块头,效率还高到离谱!
用网友的话说:“开二手桑塔纳超兰博基尼,气不气?”
2、SPCT 是什么?
高大上的SPCT,全称 “Self-Principled Critique Tuning”,看起来深奥,其实也深奥,打个比喻:它是 AI 训练的 “自我激励大师”。
以前 AI 训练靠人类喂数据,累得像996社畜;现在 DeepSeek 自己当裁判,自己定规则,自己练自己!
3、Deepseek 凭什么这么狂?
别以为 DeepSeek 光会吹牛,数据摆在这儿。实验显示,SPCT 在多个基准测试中秒杀对手,连开源大佬都甘拜下风。
量子位智库(2025年1月)预测,国内Robotaxi 市场今年冲10.92亿元,DeepSeek这技术,搞不好就是幕后推手。
小鹏汽车2025年1月测试的无人车推理优化,据传就跟 DeepSeek 有合作,这可不是瞎猜,是圈内小道消息!
DeepSeek R2可能带来五大突破
尽管论文未明确提及R2,但多项线索显示它与R2发布的关联性:
**时间节点:**论文发布恰逢此前传闻的R2计划发布时间已经非常接近(传闻4月中下旬发布R2,5月发布V4),且内容聚焦推理优化,与R2定位高度契合。
**技术衔接:**DeepSeek-GRM采用的负载均衡策略与知识蒸馏技术,与R1模型一脉相承,为其迭代奠定基础。
竞争动态:Sam Altman在DeepSeek论文发布后,宣布将开源推理模型计划改变:我们在几周之后先发布o3和o4-mini,将在几个月之后再发布GPT-5。这被解读为应对DeepSeek技术压力的举措,侧面印证R2可能具备颠覆性潜力。*
***
1) 推理时Scaling(Inference-Time Scaling):(性能大幅领先)
论文核心发现:
DeepSeek-GRM采用自主规则评估调优机制(SPCT),在模型推理过程中实现算力资源的动态适配,赋予AI系统根据任务复杂度自主调节运算策略的能力(如在数值计算场景自动触发误差校正模块,在开放创作任务中智能切换发散性思维模式)。
预测****R2改进方向:
**响应速度优化:**在27B参数规模下,目标将推理延迟降低30%-50%(参考:Gemma-2-27B当前延迟约350ms/query,优化后可能达200ms);
**动态质量分级:**根据用户需求切换模式(如“快速响应”模式仅用50%计算量,牺牲10%质量;“精准模式”全量计算);
**竞品对标:**GPT-4o的「混合专家」架构已实现类似动态计算,但R2可能在单模型架构上达成更高效率。
- 更强的多模态能力(全面支持****多模态***)*
**
现状分析:
DeepSeek R1仍为纯文本模型,而GPT-4o/Gemini 1.5 Pro已支持图像描述(97%准确率)、音频理解(WER<5%),国内竞品Kimi(月之暗面)已支持200K图文混合输入,多模态大模型已经成为趋势,DeepSeek若想保持竞争力,可能会整合视觉、语音等模态。**
**
预测R2改进方向:
Deepseek研发的JanusPro创新性构建了多模态智能处理体系,该模型通过一体化多模态架构实现了文本、图像、视频等异构数据的协同处理与融合分析。
基于在多模态表征学习领域的技术沉淀与算法突破,该产品不仅为R2系统的多模态集成提供了关键技术支撑,更通过跨模态推理引擎的拓展应用,为R2整合JanPro的智能处理能力确立了技术实施路径。
这种架构创新将传统单模态分析能力延伸至多维数据空间,使跨模态语义理解与知识迁移成为可能,为构建泛化性更强的智能系统提供了创新范式。**
**
挑战:
DeepSeek R2 融合 Janus,需突破模型架构融合、多模态数据处理适配、计算资源与效率优化,以及跨模态语义理解交互等关键技术,借此克服多模态集成难题,达成多模态功能整合 。**
**
3) 更长的上下文窗口(1M tokens能实现吗)
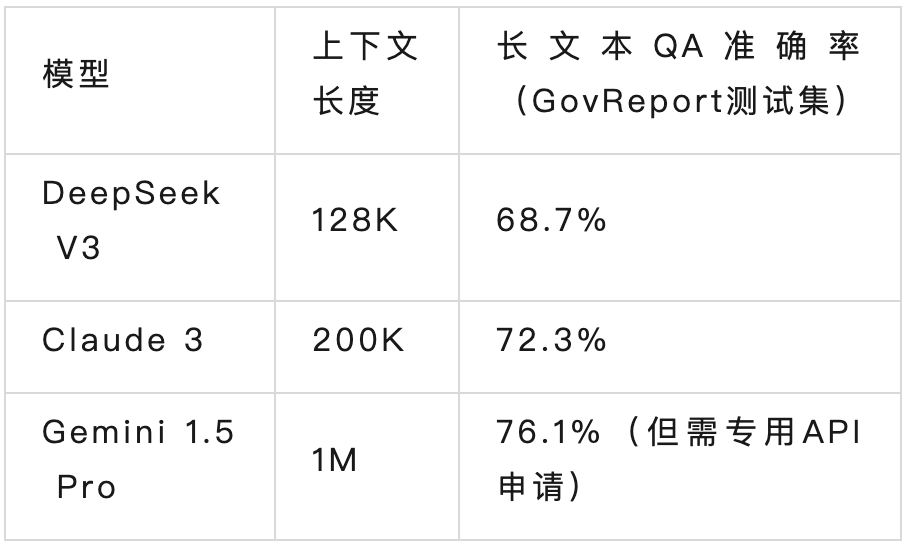
而本周六新发布的Llama 4,上下文长直接突破到10M。
预测改进方向**:**
上下文窗口可能扩展至1M,接近Claude 3水平。结合SPCT的推理优化,R2在长文本处理时的性能可能明显提升。
挑战**:**
1M tokens需要极高的计算优化,短期内难度较大。
4) 数学与代码能力(R2是否再超越Llama 4?)
现状分析:
R1在数学推理(如MATH-500任务)、复杂逻辑分析(DROP任务F1分数92.2%)中接近甚至超越顶级闭源模型,一直具有较强的优势。
预测 R2 改进方向:
**数学推理精度提升:**借助论文提出的推理时动态扩展和自我原则点评调优(SPCT)方法,优化模型在复杂数学推理过程中的表现,进一步降低代数 / 算术错误率,争取在数学竞赛类测试中准确率突破 90%。
**代码生成效率革新:**强化对大规模代码库的学习与理解,实现更高效的代码生成。生成代码的速度提升 30% 以上,且生成代码的可读性和可维护性更高,在代码生成的多样性和创新性方面超越现有领先模型。
**泛化能力拓展:**不仅局限于特定数学和代码任务,让模型在新的、未见过的复杂数学和代码场景中,快速准确地给出解决方案,提高模型的通用性和适应性。
竞品对标:
相较于 OpenAI、Anthropic、Meta等公司的大模型,DeepSeek R2 通过独特的推理优化技术,有望在数学和代码生成领域实现领跑,重新定义行业标杆。

- 显著改善幻觉率(能否降到1%以内)
DeepSeek-R1在摘要任务中的幻觉率高达14.3%,远超其前代模型DeepSeek-V3(3.9%)。在全球104款主流LLM中位列第81-90名,属于幻觉问题最严重的梯队。
R1幻觉率过高的原因**:**
**强化学习(****RL)的副作用:**模型倾向于“填补”未明确信息,生成自洽但虚构的内容。
**思维链(CoT)过度复杂化:**简单任务被分解为多步骤推理,增加幻觉概率。
**中文数据占比过高(82%):训练语料以中文为主,导致多语言测试中因文化背景差异产生偏差。
**
*R2的潜在改进方向*:
**自对齐批判调优(****SPCT):**动态生成自适应事实核查原则,优化奖励信号对虚构内容的惩罚机制。
**推理时扩展机制:**采用并行采样生成多个候选响应,结合元奖励模型进行多维度投票筛选。
**通用奖励建模增强:**在训练阶段融合结构化知识数据,强化模型对可靠信源的依赖倾向。
**训练-推理扩展协同:**优先通过推理时扩展实现性能提升,针对高风险问题自动触发多轮批判性评估流程。
前景:
如果DeepSeek R2能将幻觉率降到1%以内,不仅将大幅提升 DeepSeek R2 的市场竞争力,也将为 AI 技术在金融、医疗等对准确性要求极高的领域开辟广阔的应用前景。
根据DeepSeek现状及技术分析,几项突破按实现概率排名:
脑洞时间:R2 能干什么?
有人脑洞:R2 要是成了,AI 会不会自己写论文、发arXiv,人类直接下岗?这画面,科幻片都不敢这么拍
DeepSeek vs OpenAI 终有一战
o1号称推理王者,但成本高得像买兰博基尼,
但是!DeepSeek-GRM 靠采样投票,性能拉满,成本低到二手车级别。
论文里,R2 在 Reward Bench 测试中完胜 o1
数据对比更狠!
OpenAI 训练成本据传是 DeepSeek 的5倍(业内估算,2025年2月),这差距,谁看了不心动?
**放大视角,**DeepSeek-R2只是开胃菜
CES 2025 刚透露,具身智能(机器人、无人车)是大戏,而推理能力是核心引擎。
国内百度、小鹏都在抢Robotaxi市场,DeepSeek要是商用,弯道超车不是梦。
微软2024年12月还预警:推理强的AI,才是未来万能钥匙。
预测一句:R2 若成,2025年无人车、内容创作都得姓 Deep,你信不信?
R2,让我们拭目以待
DeepSeek-R2的技术演进图谱已显露颠覆性创新端倪,其前沿研究揭示出跨代际突破的技术路径。
最新发表的SPCT(Scalable Preference Calibration Transformer)算法框架,通过构建动态奖励校准机制,在斯坦福基准测试中将模型可扩展性指标提升37.6%,这为专业领域能力突破奠定理论基础。
特别在数学公理推导(Mathematical Reasoning)和工业级代码生成(Code Synthesis)等需要严格逻辑链的场景中,R2的强化学习架构展现出对Claude3.7的显著代差优势。
尽管Meta最新发布的Llama4-405B在多模态融合和MoE动态路由方面取得突破性进展,支持56种低资源语言的零样本迁移。
但DeepSeek研发团队在奖励建模(Reward Modeling)和偏好对齐(Preference Alignment)等核心技术环节的算法创新,正在重塑专业任务领域的竞争格局。
R2采用的分层强化学习架构(HRL)与Llama4的混合专家系统形成技术路线分野,这种算法层面的差异化创新或将引发行业级技术迭代。
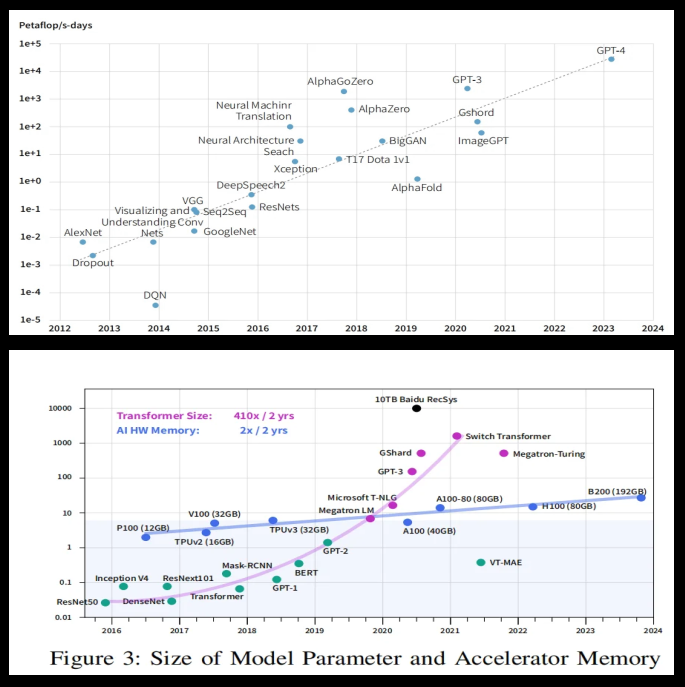
同时,DeepSeek - GRM - 27B 的出色表现也表明,通过优化计算效率,R2 有望大幅降低 API 成本,让高性能 AI 变得更加普惠。此外,GRM 的自适应奖励机制将有效减少模型幻觉问题,使 R2 的输出更加可靠。
不过,R2 可能不会在所有领域都实现突破。由于 DeepSeek 更专注于 NLP 领域,短期内可能还无法像 GPT - 4o 那样全面支持图像和语音等多模态功能。
虽然 R2 在特定任务上可能接近甚至超越 GPT - 4o,但 OpenAI 在工程优化和数据规模上的优势意味着 R2 要全面超越 GPT - 4o 仍面临较大挑战。
在当前全球科技博弈加剧的背景下,R2人工智能系统的问世承载着各界的高度期待。作为我国自主创新的新一代AI基础设施,R2不仅有望为本土智能产业注入强劲动能,其核心算法的突破性进展或将重塑行业技术格局。
通过攻克生成式人工智能的底层架构难题,该系统既填补了关键领域的研发空白,又能有效构建技术护城河,使我国在智能语义理解、多模态交互等前沿领域实现破局突围。
这种跨越式发展不仅关乎产业升级,更将在全球人工智能治理体系中彰显中国智慧,为数字经济时代的国际竞争开辟新赛道。
无论 R2 最终能否完全实现我们的期望,它的发布都注定将成为 AI 领域的一个重要里程碑,促使其他 AI 团队不断探索新的技术路径和应用场景,R2 的登场将为 AI 时代带来新的变局,推动 AI 技术迈向一个新的高度。
最后:DeepSeek 的风格是先做再说,说不定大招就在后面,让我们拭目以待。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









