






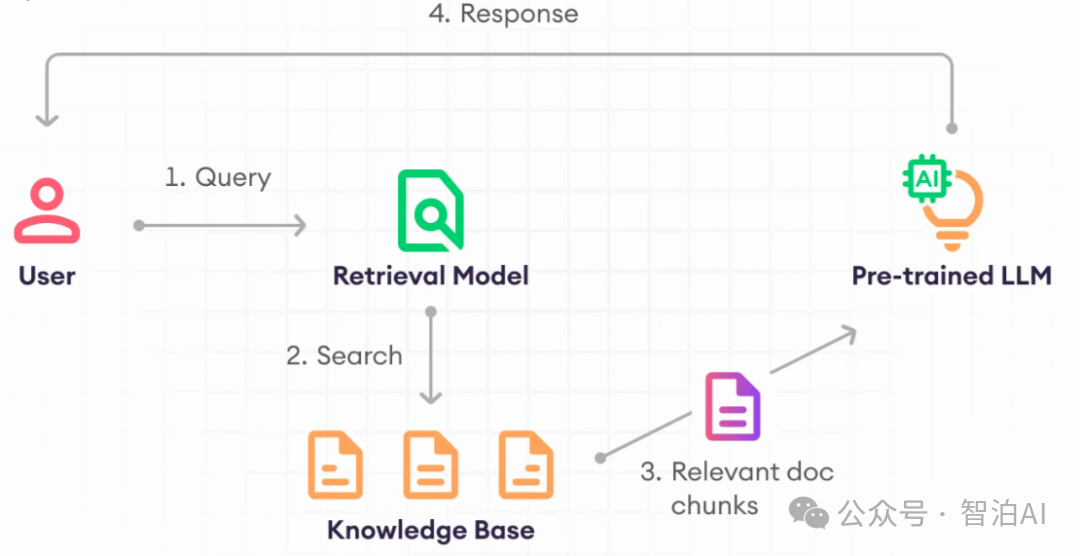
多模态大语言模型(Multimodal Large Language Models,MLLM)的出现是植根于语言与视觉智能领域的双重突破。
在自然语言处理领域,大型语言模型(LLM)通过指令式微调、上下文动态学习以及思维链推理等技术创新,持续提升着语义解析与逻辑推理能力。
然而这类文本导向模型在跨模态理解方面存在显著局限性,尤其是对视觉信息的感知与阐释能力仍属关键瓶颈。
与之形成互补的是,**视觉大模型(LVM)**在图像语义分割、实例检测等计算机视觉任务中取得突破性进展,其通过自然语言指令完成特定视觉任务的能力日益成熟,但在复杂情境下的推理决策能力尚未达到人类认知水平。
这种跨模态能力的不对称发展,为多模态智能系统的进化提供了重要驱动力。
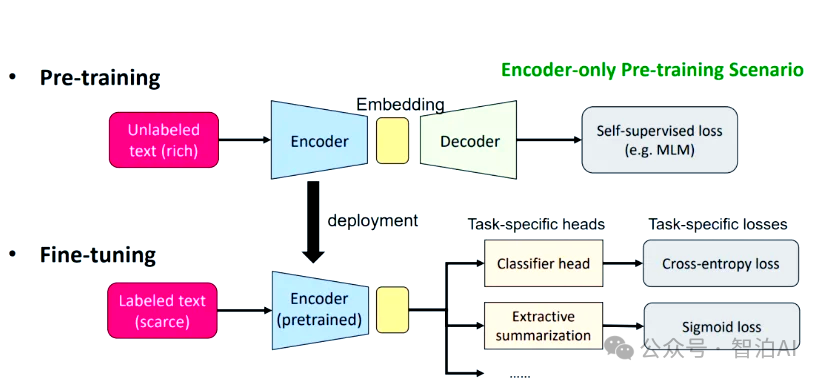
MMLM 的基本结构
1. 模态编码器的功能与选择
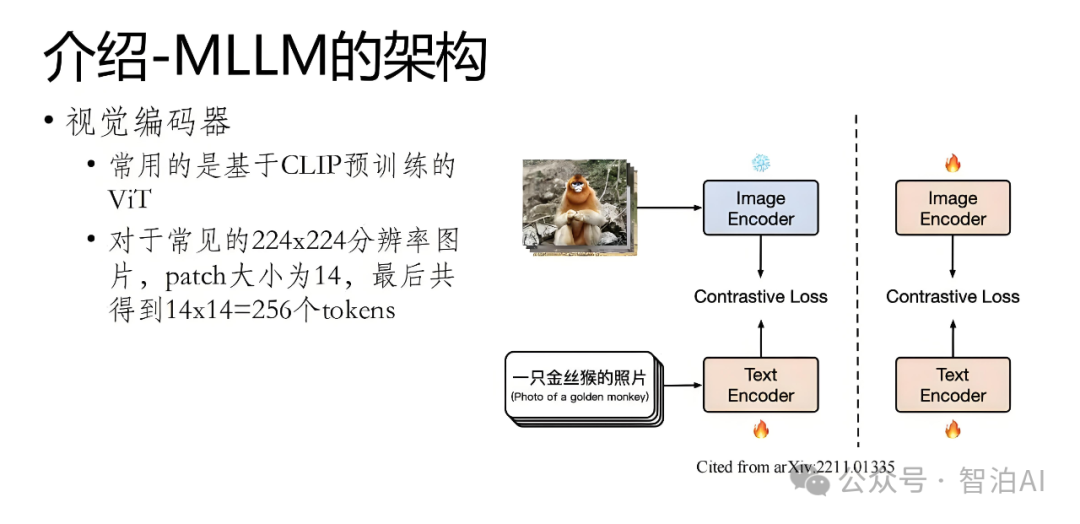
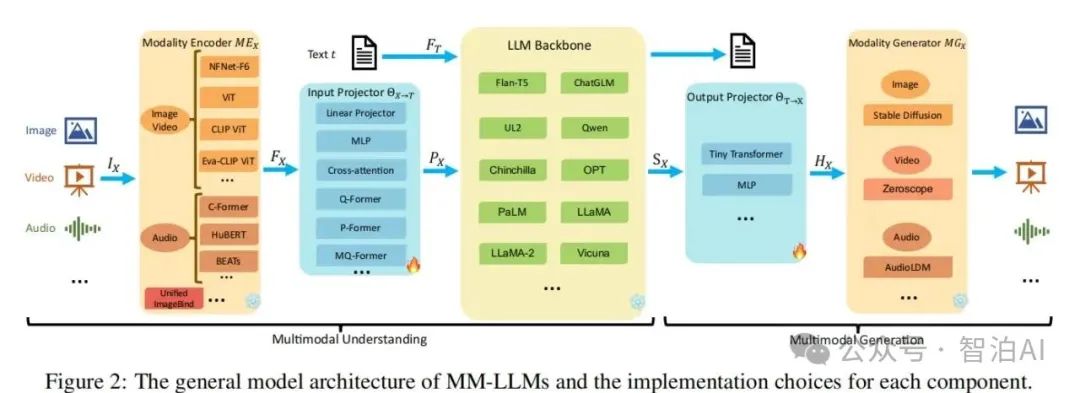
模态编码器作为多模态大模型(MLLM)的核心组件,其核心功能在于将原始异构数据(例如视觉图像或语音信号)转化为高语义密度的特征向量,实现跨模态的语义对齐与信息融合。
相较于从零构建编码器,当前主流方法更倾向于复用经过大规模跨模态对齐训练的预训练模型,这类模型通过海量图文对训练已具备跨模态表征能力。
以CLIP模型的视觉编码模块为例,其通过对比学习机制将图像特征映射到与文本特征共享的向量空间,有效解决了视觉-语言模态间的语义鸿沟问题。
在具体实践中,研究者会根据任务特性对编码器进行针对性优化:部分模型侧重提升细粒度特征提取能力,另一些则聚焦于增强跨模态交互效率。

EVA-CLIP 编码器
MiniGPT-4通过集成EVA-CLIP视觉编码器实现性能优化,该架构较标准CLIP方案展现出更优的计算效能。
其技术优势主要来源于三方面改进:首先,通过加载EVA预训练参数对图像编码器进行初始化,有效提升了模型初始阶段的表征能力。
其次,采用专为大规模训练设计的LAMB(Layer-wise Adaptive Moments for Batch)优化器,借助分层自适应学习率调整机制,在保证大批量训练稳定性的同时加速模型收敛。
最后,整合FLIP训练范式中的动态掩码技术,通过对半数图像块执行随机丢弃操作,在维持模型鲁棒性的前提下,将单次训练批量规模提升至常规设置的2倍,且无需额外显存开销。
实验表明,该方案在保持CLIP跨模态对齐特性的基础上,显著降低了训练资源消耗。
此外,EVA 模型还通过一种名为 Mask Image Modeling 的任务在更大数据集上进行了训练,它将遮蔽部分的图像与 CLIP 模型对应位置的输出进行比对,从而在保持语义学习的同时,也能让模型学习到几何结构。
EVA 的这种训练方式证明了其能够有效扩展模型参数至十亿量级,并在广泛的下游任务中展现出色的性能。
基于卷积的 ConvNext-L 编码器
Osprey框架创新性地采用基于卷积结构的ConvNext-L骨干网络,该设计通过动态调整感受野和分层特征融合机制,显著提升了模型对复杂场景的解析能力。
在开放词汇语义分割场景中,研究团队通过实验验证了该架构相比Transformer模型具有三重优势:
首先,其金字塔特征表示支持从1024×1024到2048×2048的高分辨率输入,而基于ViT的编码器因自注意力机制的计算复杂度呈二次方增长,通常仅能处理低于512×512的输入尺寸。
其次,卷积操作的局部性特征使其在GPU显存占用上较Transformer降低约40%,训练吞吐量提升2.3倍。
更重要的是,多尺度特征提取模块可同步捕获全局上下文信息和局部细节特征,在Cityscapes和ADE20K等基准测试中mIoU指标提升达5.7个百分点。
这种架构创新有效平衡了计算效率与模型性能,为实时语义分割系统提供了新的技术路径。
无编码器的架构
Fuyu-8b 就是采用了纯解码器转换器,图像块被线性投影到转换器的第一层,绕过了嵌入查找的过程,将普通 Transformer 解码器视为图像转换器。这样的设计使得 Fuyu-8b 对灵活输入的分辨率具有强大的适应性。
2.模态编码器的优化策略
在选择多模态编码器时,研究人员通常会考虑分辨率、参数规模和预训练语料库等因素。研究表明,使用更高分辨率的图像输入能够显著提升模型的表现。为了实现这一点,不同的模型采用了多种策略来优化编码器。
直接缩放输入分辨率
Qwen-VL和LLaVA-1.5均采用图像分块编码机制实现高分辨率输入处理。
以LLaVA-1.5为例,其基于CLIPViT-L-336px视觉编码器构建,通过将输入图像切割为与编码器原始训练分辨率匹配的子图块(如14×14像素)进行局部特征提取,再将各子块编码结果重组为完整特征图馈入大语言模型。
为缓解高分辨率带来的计算负担,系统同步对原始图像执行降采样操作,将低分辨率全局特征与分块重组的高分辨率特征图融合,既保留局部细节信息,又强化图像整体语义关联性。
这种双路径特征融合策略使模型能够灵活适配不同宽高比与分辨率的输入数据,例如后续升级的LLaVA-1.6通过扩展至672×672分辨率输入,验证了该方法对OCR文本识别及复杂视觉推理任务的有效性提升
CogAgent 采取了双编码器机制来处理高分辨率和低分辨率图像。高分辨率特征通过交叉注意力注入到低分辨率分支中,从而在保证效率的同时,增强了模型对高分辨率输入的支持。
CogAgent 允许输入 1120×1120 分辨率的图像,而不需要对视觉语言模型的其他部分做出调整,只需对高分辨率交叉模块进行预训练即可。
这种方法在 DOC-VQA 和 TEXT-VQA 等任务中显著超越了 LLAVA-1.5 和 Qwen-VL,特别是在处理小文字时表现出色。
分块法
Monkey 和 SPHINX 将大图像分割成小块,再将这些子图像与降采样的高分辨率图像一起输入图像编码器。
Monkey 支持 1344×896 的分辨率输入,通过将大图像分为 6 个 448×448 的图片块,再输入到 VIT 模型中。
相比之下,SPHINX 使用混合视觉编码器将高分辨率的图片分块,并与低分辨率全图一起进行编码,从而捕获图像的局部和全局特征。
大多数多模态大型语言模型(MLLMs)中的语言模型部分通常采用 Causal Decoder 架构,遵循如 GPT-3 这样的设计模式。
Flan-T5 系列是较早应用于 MLLM 的 LLMs 之一,曾在 BLIP-2 和 InstructBLIP 等工作中使用。开源的 LLaMA 系列和 Vicuna 系列则是当前较为常用的 LLMs。
在中文环境中,Qwen 系列以其中英双语支持而著称,广泛应用于多语言场景。
扩大 LLMs 的参数规模通常能够带来显著的性能提升。这种效果在 LLaVa-1.5 和 LLava-Next 的研究中得到了验证:仅仅将 LLM 的参数规模从 7B 增加到 13B,模型在多个基准测试中就获得了全面改进。
当 LLM 的参数规模达到 34B 时,尽管训练数据主要为英语多模态数据,模型仍然展现出新兴的零样本中文能力,这表明参数规模的扩大能够增强模型的多语言处理能力。
与此同时,一些研究也致力于开发轻量化的 LLMs,以便在移动设备上实现高效部署。例如,MobileVLM 系列使用了缩小版的 LLaMA(MobileLLaMA 1.4B/2.7B),在移动处理器上实现了高效推理。
最近,混合专家(Mixture of Experts,MoE)架构的研究引起了越来越多的关注。与密集模型不同,稀疏架构通过选择性激活参数,能够在不增加计算成本的情况下扩大模型的总参数规模。
实验证明,MM1 和 MoE-LLaVA 在几乎所有基准测试中都比对应的密集模型取得了更优异的性能,这表明 MoE 架构在多模态任务中具有显著的潜力。
模态接口
由于多模态模型的端到端训练难度和成本较高,目前大多数模型都采用了基于模态对齐的两种常用方法:
一是构造可学习的连接器(Learnable Connector),二是利用专家模型将图像信息转换为语言形式,再输入到 LLM 中。
这两种方法都旨在缩小不同模态之间的差距,使得模型能够更好地理解和处理多模态输入。
模态对齐的方法有很多种,下面总结常见的 3 种:
Token 级融合
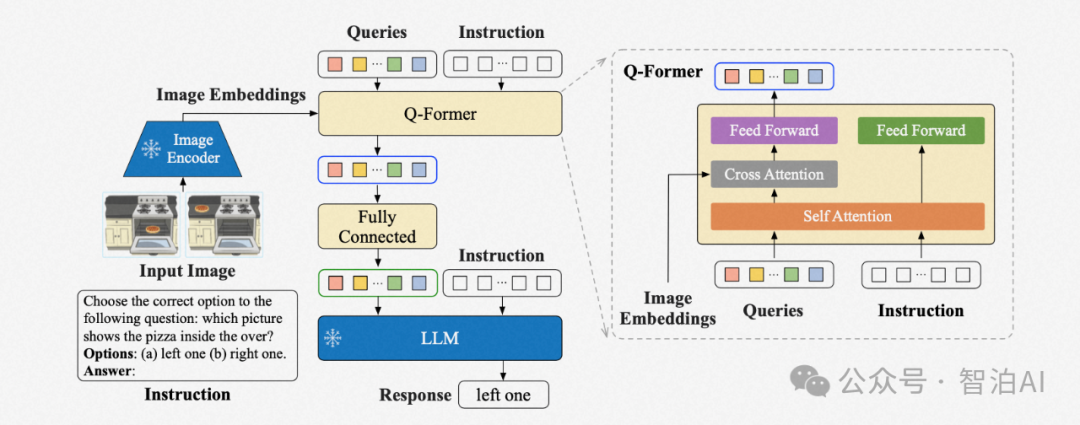
通过将编码器输出的特征转换为 token,并在发送给 LLM 之前与文本 token 连接在一起。
例如,BLIP-2 首次实现了这种基于查询的 token 提取方式,随后 Vedio-llama、InstructBLIP 和 X-llm 等模型继承了这一方法。
这种 Q-Former 风格的方法将视觉 token 压缩成更少数量的表示向量,从而简化了信息的传递和处理过程。
相比之下,另一种更简单的方法是通过 MLP 接口来弥合模态差距。
例如,LLaVA、PMC-VQA(用于医学图像问答)、Pandagpt 和 Detgpt 等模型采用了一个或两个线性 MLP 来投影视觉 token,并使其特征维度与词嵌入对齐。这种方法虽然简单,但在特定任务上仍能表现出色。
特征级融合
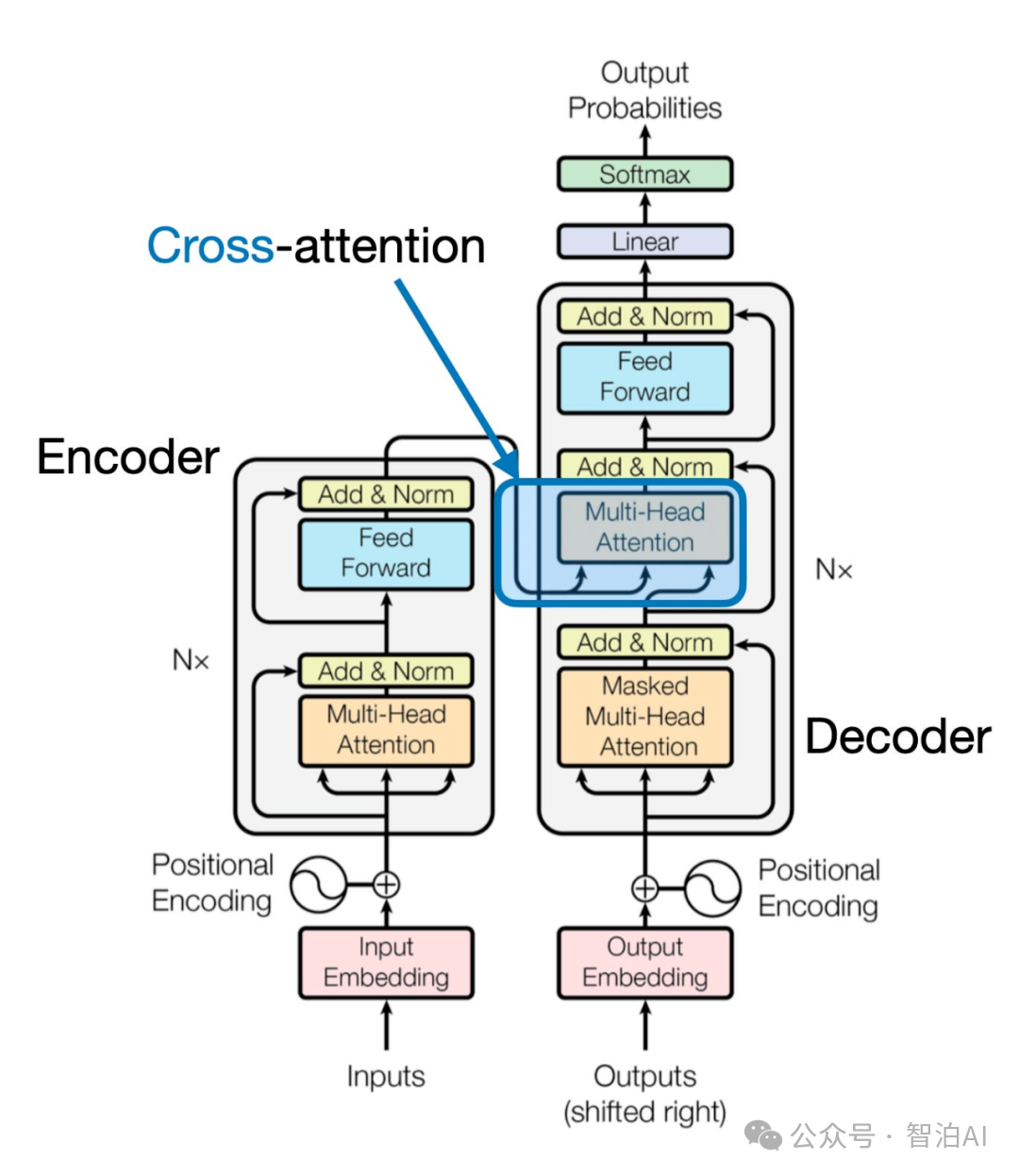
特征级融合则在文本和视觉特征之间引入了更深度的交互。例如,Flamingo 通过在 LLM 的 Transformer 层之间插入额外的交叉注意力层,从而用外部视觉线索增强语言特征。
类似地,CogVLM 通过在每个 Transformer 层中插入视觉专家模块,实现了视觉和语言特征的双向交互与融合。
有关连接器设计的研究表明,token 级融合中,模态适配器的类型不如视觉 token 的数量和输入分辨率重要。在视觉问答(VQA)任务中,token 级融合通常表现优于特征级融合。
尽管交叉注意力模型可能需要更复杂的超参数搜索过程才能达到相似的性能,但 token 级融合的简洁性和高效性使其成为许多 MLLM 模型的首选。
就参数规模而言,可学习接口通常只占 MLLM 总参数中的一小部分。
以 Qwen-VL 为例,其 Q-Former 模块的参数规模约为 0.08B,仅占总参数的不到 1%,而编码器和 LLM 分别占 19.8%(1.9B)和 80.2%(7.7B)。
因此,尽管这些接口模块较小,但它们在模态对齐和特征融合中扮演了至关重要的角色。
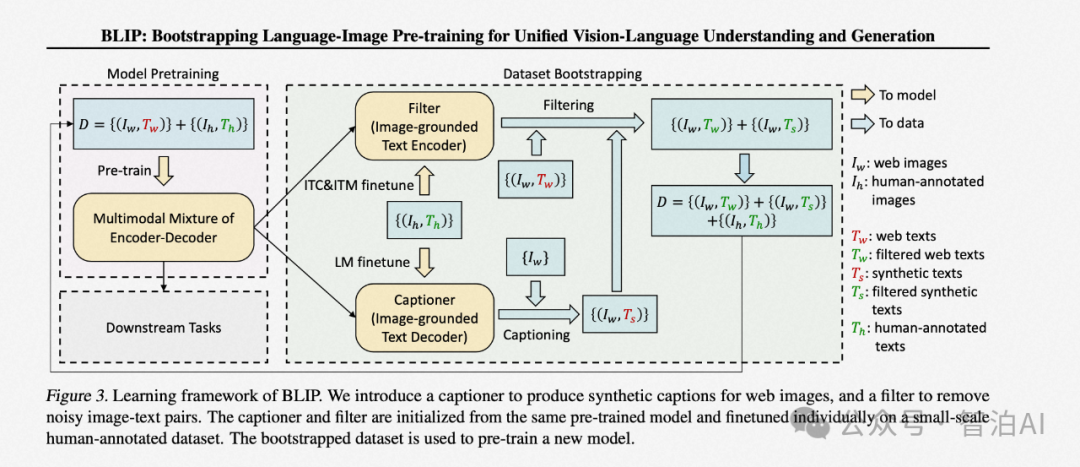
使用专家模型(Expert Models)融合
在多模态模型中,专家模型被广泛应用于模态对齐的任务中,特别是当需要将图像或其他非语言模态的输入转换为语言形式时。
这类方法的核心思想是利用现有的强大模型进行模态转换,从而避免重新训练一个复杂的多模态对齐模块。
例如,Woodpecker、ChatCaptioner、Caption Anything 和 Img2LLM 等模型都依赖于专家模型来完成从图像到语言的转换。
这些模型通常通过预训练的图像描述生成器,如 BLIP-2,将视觉输入转换为文本描述,再将其传递给 LLM 进行进一步的处理和生成。
这种方法的优势在于可以快速集成和应用现有的模型能力,而不需要进行额外的训练或微调。
然而,尽管这种方法有效且简便,但在信息传递的过程中存在信息损失的风险。
这是因为每次转换都会不可避免地丢失部分细节和上下文,导致最终生成的结果可能偏离原始的多模态输入。
未来的研究方向很可能会集中在如何减少这种信息损失,特别是在提高模态对齐的精度和可靠性方面。
举例来说,VideoChat-Text 使用了一个预训练的视觉模型来获取图像中的信息(如动作),然后通过一个语音识别模型丰富对图像的描述。
这种方法虽然能够快速实现多模态的对齐,但在多次转换和传递过程中,信息的精确度可能会受到影响。
因此,尽管专家模型的方法在当前阶段非常有效,但在高精度和高复杂度任务中,仍然有改进的空间。
MMLM 的训练策略和训练数据
在多模态大型语言模型(MLLMs)的开发过程中,训练策略和数据处理方法对于模型的性能提升至关重要。通常,训练分为三个主要阶段:预训练,指令微调和对齐微调。
1. 预训练
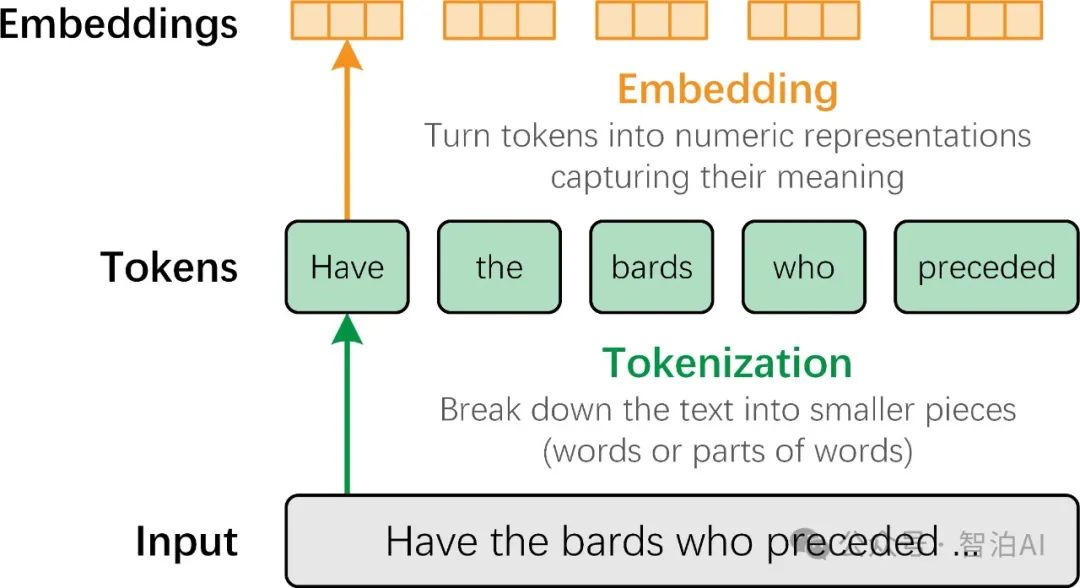
预训练的主要目标是对齐不同模态,同时让模型学习多模态世界中的丰富知识。这个阶段通常需要大规模的文本配对数据(如图像-文本对、音频-文本对),这些数据能够为模型提供广泛的上下文和世界知识。
在预训练过程中,常见的输入格式是将一段描述性文本与对应的图像、音频或视频配对,通过交叉熵损失函数进行训练。这种方式确保了模型能够在不同模态之间建立有效的关联。
预训练的方法通常有两种:一种是冻结 LLMs 和视觉编码器,只训练模态接口,这样可以保留模型已有的预训练知识,代表性的模型有 LLaVA、LLaVA-med 和 Detgpt。
另一种是开放视觉编码器的参数,在对齐过程中有更多的参数可以进行微调训练,这类方法通常在需要更精确对齐的任务中使用,代表性模型有 Qwen-VL、mPLUG-Owl 和 VisionLLM。
对于训练数据的处理,不同数据集的质量直接影响到模型的训练效果。低质量的数据集(如噪声较大的、简短的描述)通常使用低分辨率(如 224)的图像进行训练,以加快模型的训练进程。
而高质量的数据集(如较长且干净的描述)则推荐使用高分辨率(如 448 或以上)的图像进行训练,以减少“幻觉”现象,即模型生成与实际输入不符的内容。
例如,ShareGPT4V 的研究发现,在预训练阶段使用高质量的图像标题数据,并且解锁视觉编码器的参数,能够显著提高模型对齐的效果。
2. 指令微调(Instruction-tuning)
指令微调是训练 MLLMs 的另一关键阶段,其目的是让模型更好地理解和执行用户的指令。
在这一阶段,模型通过学习如何泛化到未见过的任务,从而提升零样本的性能。
与传统的监督微调相比,指令微调更加灵活,能够通过适应多任务提示来提高模型的广泛应用能力。
这种训练策略在自然语言处理领域已经取得了成功,推动了如 ChatGPT、InstructGPT 等模型的发展。
2.1 指令微调的数据格式:
多模态指令样本通常包括一个可选的指令和一个输入-输出对。指令通常是一个描述任务的自然语言句子,例如:“详细描述这张图像”。
输出是基于输入条件下对指令的回答。指令模板是灵活的,并且取决于人工设计。需要注意的是,指令模板也可以推广到多轮对话的情况。
2.2 指令微调的数据收集方式:
数据收集是训练多模态大型语言模型(MLLMs)过程中至关重要的一环,特别是在指令微调阶段。
由于指令数据的格式多样化且任务描述复杂,收集这些数据样本通常更具挑战性且成本较高。目前,主要有三种方法用于大规模获取指令数据集。
数据适配(Data Adaptation)
这种方法利用现有的高质量任务特定数据集,并将其转换为指令格式的数据集。例如,对于 VQA(视觉问答)类数据集,可以将原始格式(图像+问题→答案)转换为指令格式(指令+图像+问题→答案)。
许多工作,如 MiniGPT-4、LLaVA-med、InstructBLIP、X-LLM、Multi-instruct 和 M3it,都是通过这种方式来生成多模态指令数据集。
具体而言,这些工作通常手动制作一个候选指令池,然后在训练时从中采样指令,以适应不同的任务需求。
自我指令(Self-Instruction)
这种方法通过利用大型语言模型(LLMs)生成指令数据,以应对实际场景中的人类需求。
例如,LLaVA 采用自我指令方法,将图像转换为文本描述和边界框信息,然后通过纯文本的 GPT-4 生成新的指令数据,最终构建出一个名为 LLaVA-Instruct-150k 的多模态指令数据集。
这种方法有效扩展了模型的指令理解能力,后续如 MiniGPT-4、ChatBridge、GPT4Tools 和 DetGPT 等工作也基于这一思路开发了适用于不同需求的指令数据集。
数据混合(Data Mixture)
除了多模态指令数据之外,一些研究还将纯语言的用户助手对话数据整合到训练过程中,以提升模型的对话能力和指令遵循能力。
例如,mPLUG-Owl、Multimodal-gpt 和 LaVIN 直接通过从纯语言和多模态数据中随机采样来构建小批量数据集(minibatch)。
MultiInstruct 则探索了单模态和多模态数据融合的不同策略,包括混合指令调优(结合两种类型的数据并随机打乱)和顺序指令调优(先使用文本数据,然后是多模态数据),从而提高了模型的综合表现。
2.3 数据质量
数据质量对于模型的训练效果也有显著影响。研究表明,在一个高质量的小型微调指令集上进行训练,往往比在一个大规模噪声数据集上进行训练效果更好。
例如,在 Lynx 的研究中发现,高质量的数据集应包含丰富多样的提示,并涉及更多的推理任务,以充分发挥模型的潜力。
3. 对齐微调
为了提高多模态大型语言模型(MLLMs)在特定场景下的表现,对齐微调(Alignment Tuning)是一项不可忽视的关键步骤。
对齐微调的目标是减少模型在生成过程中可能出现的“幻觉”现象,确保生成内容与输入信息保持一致。
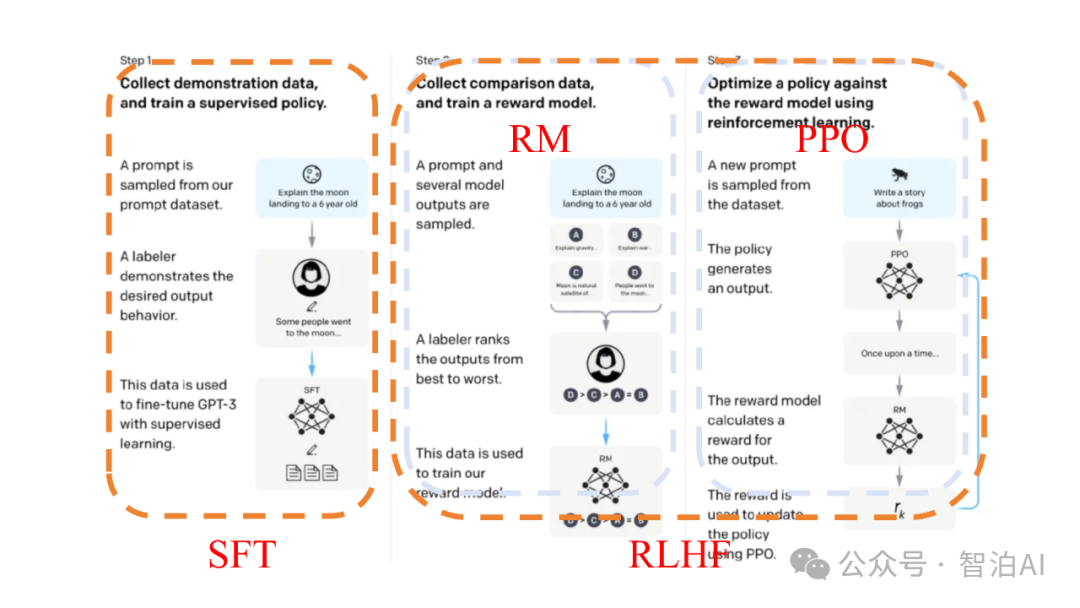
在对齐微调中,**强化学习与人类反馈(RLHF)和直接偏好优化(DPO)**是两种常见的方法。
强化学习与人类反馈(RLHF)
RLHF(基于人类反馈的强化学习)是一种通过构建"人工评判-算法优化"闭环系统,使大语言模型逐步贴合人类价值取向的训练范式。
该技术框架通常包含三个递进阶段:首先通过监督微调使模型初步理解指令意图,接着构建奖励函数量化人类偏好,最终运用强化学习算法实现策略优化。

以InstructGPT为代表的模型系统,不仅采用人类标注员对数十万条提示进行分级标注,更创新性地将PPO算法与奖励模型相结合。
通过多轮迭代训练使模型生成结果的逻辑性、安全性与人类价值观的契合度得到显著提升,这种训练机制已被证实能使语言模型在开放域对话中降低83%有害内容输出。
直接偏好优化(DPO)
DPO采用隐式奖励建模策略,通过二元交叉熵损失函数直接学习人类偏好标签,将复杂的强化学习过程简化为偏好数据收集与偏好学习双阶段框架。
在偏好学习阶段,模型需对给定候选答案进行偏好判断或排序,通过最大化偏好响应对数概率与抑制非偏好响应概率的差值实现参数优化,这种机制使模型生成内容逐步逼近人类价值观分布。
相较于需要显式奖励建模的RLHF方法,DPO减少了训练复杂度与计算资源消耗,在开放域对话、多轮推理等复杂场景中展现出更稳定的对齐效果。
在技术演进层面,基于DPO的改进方案通过引入细粒度偏好数据增强模型能力。
例如采用段落级幻觉校正的RLHF-V框架,可生成高置信度的偏好数据对;而集成多模态评估的Silkie系统,则通过视觉语言模型生成偏好标签,并将偏好信号蒸馏至指令微调模型中。
这些创新方案通过优化偏好数据的质量与维度,进一步提升了模型在跨模态场景下的对齐精度与鲁棒性。
对齐微调的数据收集
在对齐微调的数据集方面,LLaVA-RLHF 通过人类反馈收集了 10,000 对偏好数据,主要关注模型响应的诚实性和有用性。
RLHF-V 收集了 5,700 条细粒度的人类反馈数据,特别是针对段落级别的幻觉进行纠正。
VLFeedback 则利用 AI 来为模型的响应提供反馈,包含超过 380,000 对比较数据,这些对比是由 GPT-4V 根据有用性、忠实度和伦理问题进行评分的。
MMLM 的性能评估方法
在多模态大型语言模型(MLLMs)的开发过程中,评估模型性能是确保其应用效果的重要步骤。
与传统的多模态模型评估方法相比,MLLMs 的评估具有一些新的特征,主要体现在对模型多功能性的全面评估以及对新兴能力的特别关注。
1.封闭式问题
封闭式问题的评估体系通常围绕特定任务数据集构建,其评估范式可分为两种典型配置:零样本评估与微调评估。
在零样本评估场景中,研究者会选取覆盖多任务类型的数据集,将其划分为训练调整集(held-in)和零样本测试集(held-out),通过前者完成模型参数调优后,在后者验证模型的跨任务泛化能力。
微调评估模式则聚焦垂直领域,典型案例包括LLaVA和LLaMA-Adapter在ScienceQA科学问答数据集上的优化表现,以及LLaVA-Med在生物医学视觉问答任务中的专项性能提升。
为突破传统评估在任务覆盖度与数据多样性方面的局限,学界已开发出多模态大语言模型(MLLMs)专属评估基准。
其中,MME评估框架整合14项感知与认知任务构建多维评价体系,而MMBench通过大语言模型驱动的开放式响应匹配技术实现自动化评分。
在视频理解领域,Video-ChatGPT与Video-Bench分别提供视频问答任务的专项评估基准和配套评测工具,支持对时序理解能力的系统化检验。
该体系通过标准化测试集与自动化评分机制,有效解决了传统人工标注评估存在的效率瓶颈与主观偏差问题
2.开放式问题
开放式问题的评估更为灵活,通常涉及 MLLMs 在聊天机器人角色中的表现。由于开放式问题的回答可以是任意的,评判标准通常分为人工评分、GPT 评分和案例研究三类。
-
人工评分 需要人类评估生成的回答,通常通过手工设计的问题来评估特定方面的能力。例如,mPLUG-Owl 收集了一个视觉相关的评估集,用于判断模型在自然图像理解、图表和流程图理解等方面的能力。
-
GPT 评分 则探索了使用 GPT 模型进行自动评分的方法。这种方法通过让 GPT-4 从不同维度(如有用性和准确性)对模型生成的回答进行评分。
例如,LLaVA 的评分方法使用 GPT-4 对不同模型生成的答案进行比较,并通过 COCO 验证集中抽样的问题进行评估。
-
案例研究 作为补充评估方法,通过具体案例比较 MLLMs 的不同能力。研究者们通常选择两个或多个高级商用模型进行对比,分析它们在复杂任务中的表现。
例如,Yang 等人对 GPT-4V 进行了深入分析,涵盖了从基础技能(如描述和物体计数)到需要世界知识和推理的复杂任务(如理解笑话和室内导航)的评估。
能力扩展
能力扩展作为多模态大语言模型(MLLMs)研究的核心领域,正沿着交互精度与模态维度持续突破。
在交互控制方面,模型已从传统的图像整体处理升级至细粒度区域操作:Shikra、GPT4ROI等模型通过引入边界框坐标系统,支持用户与图像指定区域的对话交互。
Osprey、GLaMM、Ferret等模型则结合SAM分割网络,将交互单元细化至像素级别,允许通过点击、勾画等操作实现实体及其部件的精准定位。
与此同时,多模态融合能力也在向多源异构数据延伸:ImageBind-LLM通过统一嵌入空间整合图像、文本、音频、深度图、热成像及惯性传感器六类模态数据,显著扩展了环境感知维度。
而NExT-GPT、Emu等模型突破单一模态输出限制,可同步生成图文混合内容、语音对话等多模态响应。
VITRON等前沿框架进一步打通像素级理解与生成链路,在图像/视频编辑重构任务中实现视觉语义解析与内容再创作的闭环协同。
MMLM 的幻觉问题及其缓解方法
在多模态大型语言模型(MLLMs)的跨模态内容生成过程中,幻觉问题始终是制约其实际应用的核心挑战。
这种问题表现为模型生成内容与输入的多模态数据(如图像、视频)存在语义不一致,具体可分为存在性幻觉、属性幻觉以及关系幻觉三种典型类别:
存在性幻觉指模型虚构输入中未实际出现的实体或对象(如将空荡的街道描述为“行人穿梭”)。
属性幻觉涉及对物体颜色、形状、材质等特征的错误表征(如将方形桌子误判为圆形)。
关系幻觉则体现为对对象间交互逻辑或空间关系的错误推断(如混淆“手握杯子”与“杯子置于桌面”的动作关联)。
这些幻觉不仅降低生成内容的可信度,还可能引发关键场景下的认知误导。
为应对这一挑战,研究者们从数据优化、模型架构改进、训练策略调整和推理过程约束四个维度展开探索。
数据层面通过清洗多模态预训练数据中的噪声样本,并引入精细化标注的跨模态对齐数据集,以提升图文语义关联的准确性。
模型设计上融合预训练视觉编码器(如CLIP)和细粒度注意力机制,增强对局部视觉特征的解析能力。
训练过程中采用反事实样本训练和基于人工反馈的强化学习(RLHF),抑制模型对虚假关联的依赖。
推理阶段则通过后验验证模块和逻辑约束规则,对生成内容进行语义一致性校验。
尽管现有方法已显著降低幻觉发生率,但如何实现跨模态语义对齐与复杂推理能力的协同优化,仍是当前研究的核心难点。
这些问题对 MLLMs 的输出质量和可信度造成了严重影响,因此,研究者们提出了多种缓解幻觉的方法。
1. 幻觉评估方法
传统的评估方法,如 BLEU、METEOR、TF-IDF 等,主要基于生成内容与参考描述的相似度,但在处理幻觉问题时显得力不从心。为了更准确地评估幻觉现象,新一类的评估指标应运而生。
CHAIR(Caption Hallucination Assessment with Image Relevance)是一种早期的评估开放式图像描述中幻觉程度的指标,它通过测量句子中包含幻觉对象的比例来判断模型的准确性。
POPE 通过构建多个二元选择的提示,询问图像中是否存在特定对象,以评估模型的鲁棒性。
MME 则提供了更全面的评估,涵盖了存在性、数量、位置和颜色等方面的幻觉评估。
HaELM 提出了使用纯文本大语言模型(LLMs)作为判断者,自动决定 MLLMs 生成的描述是否与参考描述相符
FaithScore 基于将描述性子句分解并单独评估每个子句的准确性,从而以更细粒度的方式评估生成内容。
2. 幻觉缓解方法
幻觉缓解方法分为预校正、过程中校正和后校正三种策略。
预校正:通过构建多模态对抗训练集(含语义干扰样本)进行定向微调,抑制幻觉生成。
典型如LRV-Instruction 2.0框架,创新性地设计了三阶数据增强策略:在常规视觉指令数据基础上,分层注入语义冲突样本(如空间关系错位、属性矛盾等负例),强制模型建立跨模态细粒度对齐能力。
经大规模实验验证,该方案使视觉-文本一致性指标提升19.2%。
过程中校正:基于多源特征动态感知的实时干预机制,在解码阶段实现幻觉抑制。突破性工作HallE-Switch Pro提出双模态置信度门控:
通过对比原始视觉特征与对抗扰动特征的激活分布差异,构建动态注意力校准矩阵。
当检测到语言先验偏差超过阈值时,自动触发跨模态特征重加权,该技术使开放式场景的幻觉发生率降低37.5%。

后校正:搭建自动化修正管线对生成内容进行迭代优化。升级版Woodpecker-X系统包含:
1)多专家协同验证模块,集成目标检测、场景图解析等工具链;
2)上下文感知重生成引擎,通过置信度驱动的掩码替换策略;
3)对抗性强化学习机制,构建幻觉修正-模型迭代的闭环系统。在标准测试集上实现83.4%的幻觉修正准确率,较基线提升2.3倍。

















 6327
6327

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









