







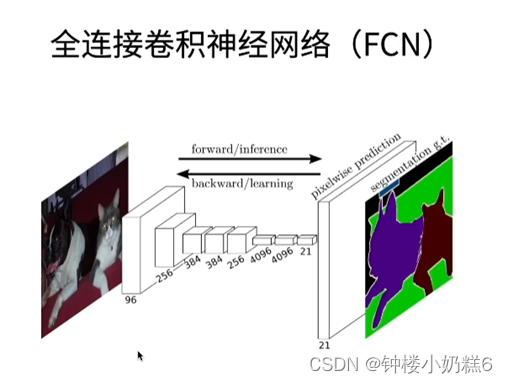
1.FCN有关知识:
①FCN是用深度神经网络来做语义分割的奠基性工作
②它用转置卷积层来替换CNN最后的全连接层,从而可以实现每个像素的预测
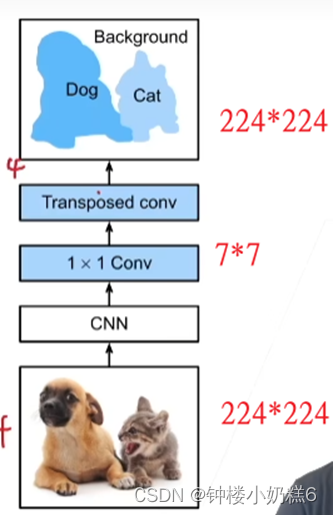
CNN模型最后两层:全连接层(label语义信息)和全局平均池化层(全连接层将224*224的图片变成7*7,全局平均池化把7*7变成平均1*1),图片分类没问题。但是需要空间信息效果不好了。
FCN新加的:
①1*1 Conv:
Ⅰ通过1*1卷积层将通道数变换为类别个数
Ⅱ不会变换空间信息,来降低通道数,减少计算量
②转置卷积:
ⅠCNN把图片缩小,转置卷积把图片放大。将特征图的高和宽变换为输入图像同样的尺寸,输出通道包含空间位置像素的类别预测。
Ⅱ K*224*224 K代表多少类别 每一个像素类别预测存在通道里面
【总结】
①全连接卷积网络FCN首先使用卷积神经网络抽取图像特征,然后通过1*1卷积层将通道数变换为类别数,最后通过转置卷积层将特征图的高宽放大为输入图像的尺寸
②在全连接卷积网络,可以将转置卷积层初始化为双线性插值的上采样
【代码实现】
引入包
import torch
import torchvision
from torch import nn
from torch.nn import functional as F
from d2l import torch as d2l①使用ImageNet数据集上预训练的模型ResNet-18模型提取图像特征
pretrained_net = torchvision.models.resnet18(pretrained=True)②后面的全连接层和平均池化层不需要,创建一个全卷积网络net,缩小32
net = nn.Sequential(*list(pretrained_net.children())[:-2])③使用1*1卷积层将输出通道转换为数据集的类数(21类),转置卷积将要素图的高宽增加32
num_classes = 21
net.add_module('final_conv', nn.Conv2d(512, num_classes, kernel_size=1))
net.add_module(
'transpose_conv',
nn.ConvTranspose2d(
num_classes, num_classes, kernel_size=64, padding=16, stride=32
)
)④初始化转置卷积层--双线性插值
def bilinear_kernel(in_channels, out_channels, kernel_size):
factor = (kernel_size + 1) // 2
if kernel_size % 2 == 1:
center = factor - 1
else:
center = factor - 0.5
og = (torch.arange(kernel_size).reshape(-1, 1),
torch.arange(kernel_size).reshape(1, -1))
filt = (1 - torch.abs(og[0] - center) / factor) * \
(1 - torch.abs(og[1] - center) / factor)
weight = torch.zeros((in_channels, out_channels,
kernel_size, kernel_size))
weight[range(in_channels), range(out_channels), :, :] = filt
return weight⑤初始化转置卷积参数
W = bilinear_kernel(num_classes, num_classes, kernel_size=64)
net.transpose_conv.weight.data.copy_(W)⑥ 读取数据集
batch_size, crop_size = 32, (320, 480)
train_iter, test_iter = d2l.load_data_voc(batch_size, crop_size)⑦训练
# 训练
def loss(inputs, targets):
return F.cross_entropy(inputs, targets, reduction='none').mean(1).mean(1)
num_epochs, lr, wd, devices = 5, 0.01, 1e-3, d2l.try_gpu()
trainer = torch.optim.SGD(net.parameters(), lr=lr, weight_decay=wd)
d2l.train_ch13(net, train_iter, test_iter, loss, trainer, num_epochs, devices)














 7468
7468











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









