







 R-FCN是一种基于Region-based Fully Convolutional Network的目标检测方法,旨在解决Faster R-CNN中ROI层后结构不共享导致的效率问题。通过引入Position-sensitive score map增强平移可变性,实现全卷积架构的共享计算,提高检测速度。在Pascal VOC上,R-FCN在速度和性能上表现出色,同时利用空洞技巧(Atrous)提高分辨率,提升了mAP。
R-FCN是一种基于Region-based Fully Convolutional Network的目标检测方法,旨在解决Faster R-CNN中ROI层后结构不共享导致的效率问题。通过引入Position-sensitive score map增强平移可变性,实现全卷积架构的共享计算,提高检测速度。在Pascal VOC上,R-FCN在速度和性能上表现出色,同时利用空洞技巧(Atrous)提高分辨率,提升了mAP。
R-FCN: Object Detection via Region-based Fully Convolutional Network
原文:R-FCN: https://arxiv.org/abs/1605.06409
Github链接: https://github.com/daijifeng001/r-fcn(https://github.com/daijifeng001/r-fcn)
what
本文是基于region based framework的一种新的detection方法,主要目的是通过移除最后的fc层进行加速。同时通过本篇论文,很好的将RCNN,faster rcnn进行了一个general的总结。本文目前是Pascal voc上面速度和performance结合的最好的方法,并且用到了最新的residual network(好吧,也过去好久了其实)。
唯一美中不足的是,没有其他网络,比如VGG16和GoogleNet的baseline,所以和不少其他的方法没有比较。
why
首先,region base detection framework有一个问题,就是多多少少会有subnet的重复计算。
最早的RCNN,每一个proposal都会独立经历一次CNN网络抽取feature,那么这个时候,这个subnet就是整个网络,非常非常慢。后来的fast rcnn,先把整张image进行卷积计算,然后在最后一层通过ROI pooling把每一个proposal变成一个大小一致的map,对于每一个map,经过若干次fc层然后得到结果,在这个时候,这个subnet指的就是那若干层fc层。假如一幅图片的proposal有N个,所以这样经历subnet的计算也会有N次,subnet越深计算的效率越低。本文的想法就是不用这些subnet,让所有的计算都可以共享。(见下图的总结)

随着网络深度的提高,网络对于location的敏感度越来越低,也就是所谓的translation-invariance,但是在detection的时候,需要对位置信息有很强的的敏感度。
ResNet论文的检测流程将RoI池化层插入到卷积中—特定区域的操作打破了平移不变性,当在不同区域进行评估时,RoI后卷积层不再是平移不变的。然而,这个设计牺牲了训练和测试效率,因为它引入了大量的区域层
一方面,图像级别的分类任务有利于平移不变性——图像内目标的移动应该是无差别的。因此,深度(全)卷积架构尽可能保持平移不变,这一点可以从ImageNet分类[9,24,26]的主要结果中得到证实。另一方面,目标检测任务的定位表示需要一定程度上的平移可变性。例如,在候选框内目标变换应该产生有意义的响应,用于描述候选框与目标的重叠程度。我们假设图像分类网络中较深的卷积层对平移不太敏感。
在ResNet论文中,Faster R-CNN检测器的RoI池层不自然地插入在两组卷积层之间——这创建了更深的RoI子网络,其改善了精度,由于非共享的RoI计算,因此是以更低的速度为代价。
R-FCN要解决的根本问题是Faster R-CNN检测速度慢的问题,速度慢是因为ROI层后的结构对不同的proposal是不共享的,试想下如果有300个proposal,ROI后的全连接网络就要计算300次,这个耗时就太吓人了。所以作者把ROI后的结构往前挪来提升速度,但光是挪动下还不行,ROI在conv5后会引起上节提到的平移可变性问题,必须通过其他方法加强结构的可变性,所以作者就想出了通过添加Position-sensitive score map来达到这个目的。
Approach/Idea
在本文中,作者开发了一个称为基于区域的全卷积网络(R-FCN)框架来进行目标检测。网络由共享的全卷积架构组成,就像FCN一样。为了将平移可变性并入FCN,作者通过使用一组专门的卷积层作为FCN输出来构建一组位置敏感的分数图。这些分数图中的每一个都对关于相对空间位置(的位置信息进行编码例如,“在目标的左边”)。在这个FCN之上,添加了一个位置敏感的RoI池化层,它从这些分数图中获取信息,并且后面没有权重(卷积/fc)层。整个架构是端到端的学习。所有可学习的层都是卷积的,并在整个图像上共享,但对目标检测所需的空间信息进行编码。图1说明了关键思想,表1比较了基于区域的检测器方法。
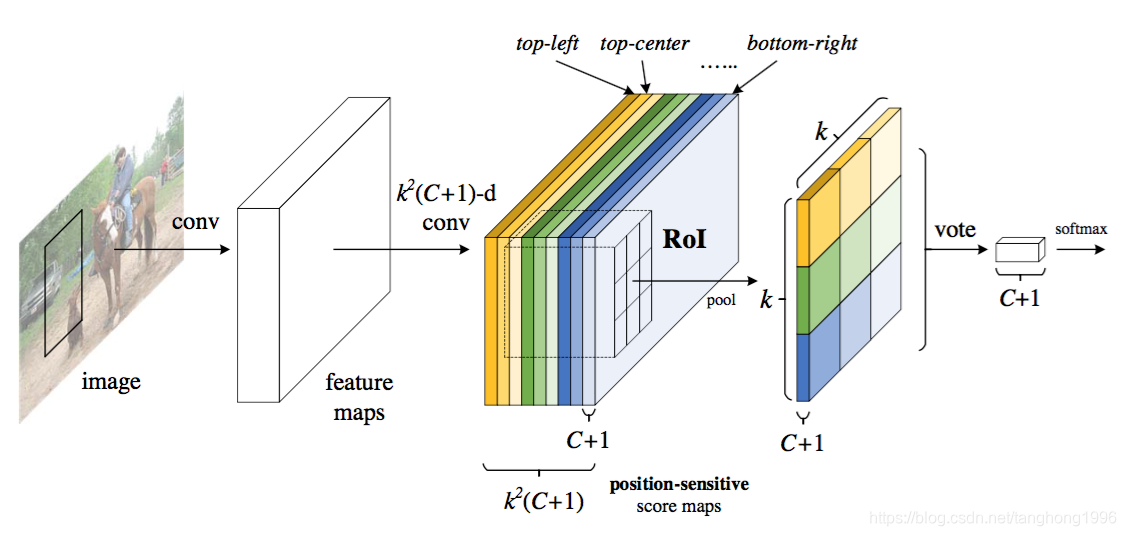
利用最后一层网络通过FCN构成一个position-sensitive的feature map。
具体而言,每一个proposal的位置信息都需要编码,那么先把proposal分成k*k个grid,
然后对每一个grid进行编码。
在最后一层map之后,再使用卷积计算产生一个k*k*(C+1)的map
(k*k代表总共的grid数目,C代表class num,+1代表加入一个背景类)。
Position-sensitive score map对于平移可变性的本质 https://blog.csdn.net/qq_30622831/article/details/81459407
k
2
∗
(
C
+
1
)
k^2*(C+1)
k2∗(C+1)个feature map的物理意义:共有
k
2
k^2
k2=9个颜色,每个颜色的立体块(WH(C+1))表示的是不同位置存在目标的概率值(第一块黄色表示的是左上角位置,最后一块淡蓝色表示的是右下角位置)。共有
k
2
∗
(
C
+
1
)
k^2*(C+1)
k2∗(C+1)个feature map。每个feature map,z(i,j,c)是第i+k(j-1)个立体块上的第c个map(1<= i,j <=3)。(i,j)决定了9种位置的某一种位置,假设为左上角位置(i=j=1),c决定了哪一类,假设为person类。在z(i,j,c)这个feature map上的某一个像素的位置是(x,y),像素值是value,则value表示的是原图对应的(x,y)这个位置上可能是人(c=‘person’)且是人的左上部位(i=j=1)的概率值。
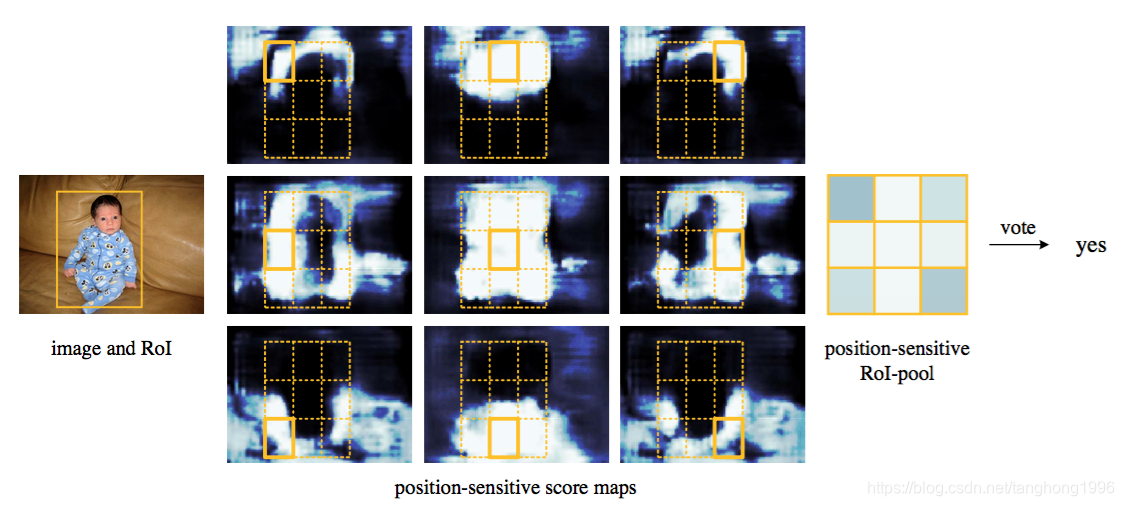

Result
本文采用的一些方法比faster rcnn的baseline提高了3个点,并且是原来faster rcnn更快(因为全部计算都共享了)。但是和改进过的faster rcnn相比(roi pooling提前那种)提高了0.2个点,速度快了2.5倍。所以目前为止这个方法的结果应该是所有方法中速度和performance结合的最好的。
Experiments
Atrous and stride(空洞和步长)
作者的全卷积架构享有FCN广泛使用的语义分割的网络修改的好处[15,2]。特别的是,我们将ResNet-101的有效步长从32像素降低到了16像素,增加了分数图的分辨率。conv4阶段[9](stride = 16)之前和之后的所有层都保持不变;第一个conv5块中的stride=2操作被修改为stride=1,并且conv5阶段的所有卷积滤波器都被“hole algorithm”[15,2](“Algorithm atrous”[16])修改来弥补减少的步幅。为了进行公平的比较,RPN是在conv4阶段(与R-FCN共享)之上计算的,就像[9]中Faster R-CNN的情况那样,所以RPN不会受空洞行为的影响。下表显示了R-FCN的消融结果(k×k=7×7,没有难例挖掘)。这个空洞窍门提高了2.6点的mAP。
caffe卷积层延伸:卷积核膨胀详细解析
https://blog.csdn.net/jiongnima/article/details/69487519
设置不同的k(空洞技巧)
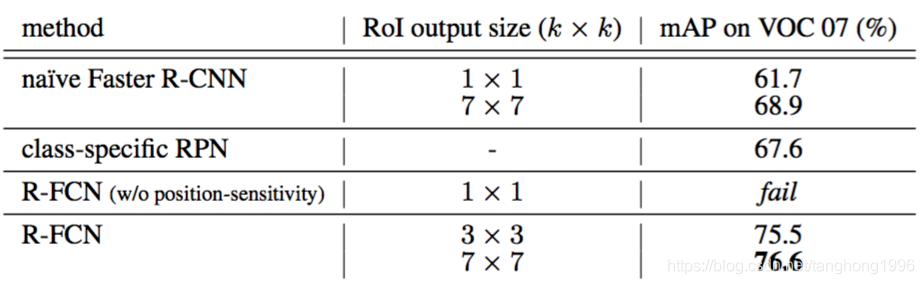 类别特定的RPN具有67.6%(表2)的mAP,比标准Faster R-CNN的76.4%低约9个百分点。这个比较符合[6,12]中的观测结果——实际上,类别特定的RPN类似于使用密集滑动窗口作为提议的一种特殊形式的Fast R-CNN[6],如[6,12]中所报道的较差结果。
类别特定的RPN具有67.6%(表2)的mAP,比标准Faster R-CNN的76.4%低约9个百分点。这个比较符合[6,12]中的观测结果——实际上,类别特定的RPN类似于使用密集滑动窗口作为提议的一种特殊形式的Fast R-CNN[6],如[6,12]中所报道的较差结果。
详细可以在R-CNN minus R论文中了解
https://blog.csdn.net/tanghong1996/article/details/88060173
不同的Rols
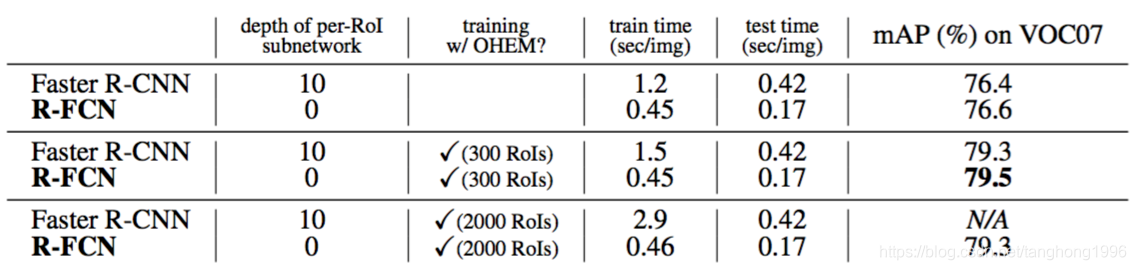
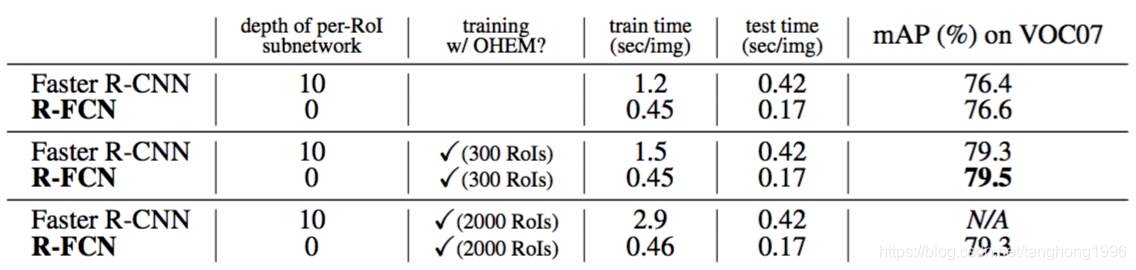 在测试时使用300个RoI,Faster R-CNN每张图像花费0.42s,比我们的R-FCN慢了2.5倍,R-FCN每张图像只有0.17s(在K40 GPU上,这个数字在Titan X GPU上是0.11s)。R-FCN的训练速度也快于Faster R-CNN。此外,难例挖掘没有增加R-FCN的训练成本(表3)。当从2000个RoI挖掘时训练R-FCN是可行的,在这种情况下,Faster R-CNN慢了6倍(2.9s vs. 0.46s)。但是实验表明,从更大的候选集(例如2000)中进行挖掘没有好处
在测试时使用300个RoI,Faster R-CNN每张图像花费0.42s,比我们的R-FCN慢了2.5倍,R-FCN每张图像只有0.17s(在K40 GPU上,这个数字在Titan X GPU上是0.11s)。R-FCN的训练速度也快于Faster R-CNN。此外,难例挖掘没有增加R-FCN的训练成本(表3)。当从2000个RoI挖掘时训练R-FCN是可行的,在这种情况下,Faster R-CNN慢了6倍(2.9s vs. 0.46s)。但是实验表明,从更大的候选集(例如2000)中进行挖掘没有好处
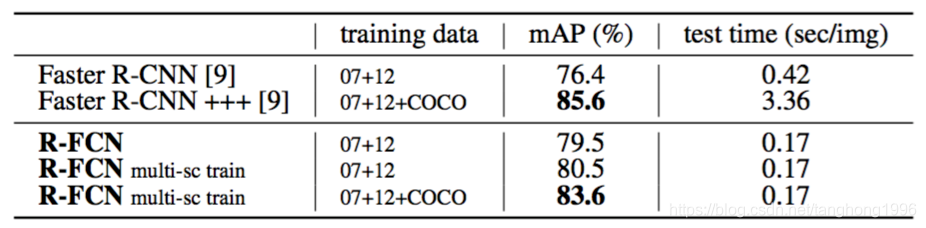
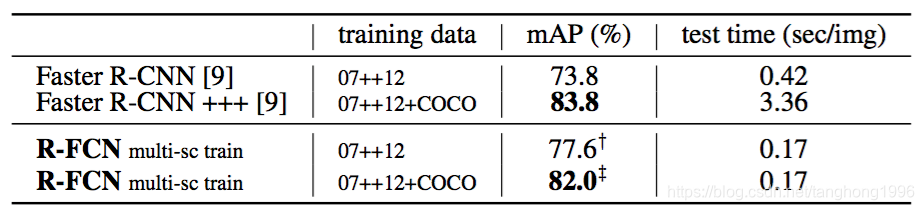
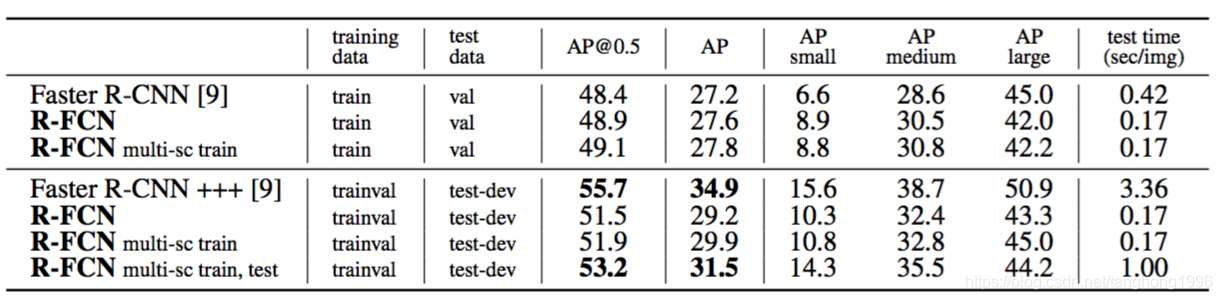
MS COCO上的实验
Conclusion
作者的方法实现了与Faster R-CNN对应网络相比更具竞争力的准确性,但是在训练和推断上都快得多。
应该可以通过扩展,提高精度。(后续的light-head RCNN貌似是根据R FCN而来的)
https://blog.csdn.net/u012361214/article/details/51507590
https://blog.csdn.net/weixin_37203756/article/details/80199225

















 338
338

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









