







简介
论文地址:https://arxiv.org/abs/1411.4038
发表于:CVPR 2015
背景
语义分割(Semantic Segmentation)的目的是对图像中每一个像素点进行分类,与普通的分类任务只输出某个类别不同,语义分割任务输出是与输入图像大小相同的图像,输出图像的每个像素对应了输入图像每个像素的类别。
比如下图:

图像语义分割的意思就是机器自动分割并识别出图像中的内容,比如给出一个人骑摩托车的照片,机器判断后应当能够生成右侧图,红色标注为人,绿色是车,黑色表示背景。
传统使用CNN在做语义分割存在的问题:
- 存储开销大
- 计算量大
- 限制感受野大小
先总结一下FCN
主要成就:端到端、像素到像素训练方式下的卷积神经网络超过了现有语义分割方向最先进的技术.
核心思想:搭建了一个全卷积网络,输入任意尺寸的图像,经过有效推理和学习得到相同尺寸的输出.
主要方法:将当前分类网络(ALexNet、VGGNet和GoogleNet)改编成全卷积网络,并进行微调;设计了跳跃连接结构,将全局信息和局部信息连接起来
作者将其全连接层均替换为卷积层,输出空间映射而不是分类分数。这些映射由小步幅卷积上采样(又称转置卷积)得到,来产生密集的像素级别的标签。该工作被视为里程碑式的进步,因为它阐释了CNN如何可以在语义分割问题上被端对端的训练,而且高效的学习了如何基于任意大小的输入来为语义分割问题产生像素级别的标签预测。本方法在标准数据集如PASCAL VOC分割准确率上相对于传统方法取得了极大的进步,且同样高效。由于上述及更多显著的贡献,FCN成为了深度学习技术应用于语义分割问题的基石。
FCN结构
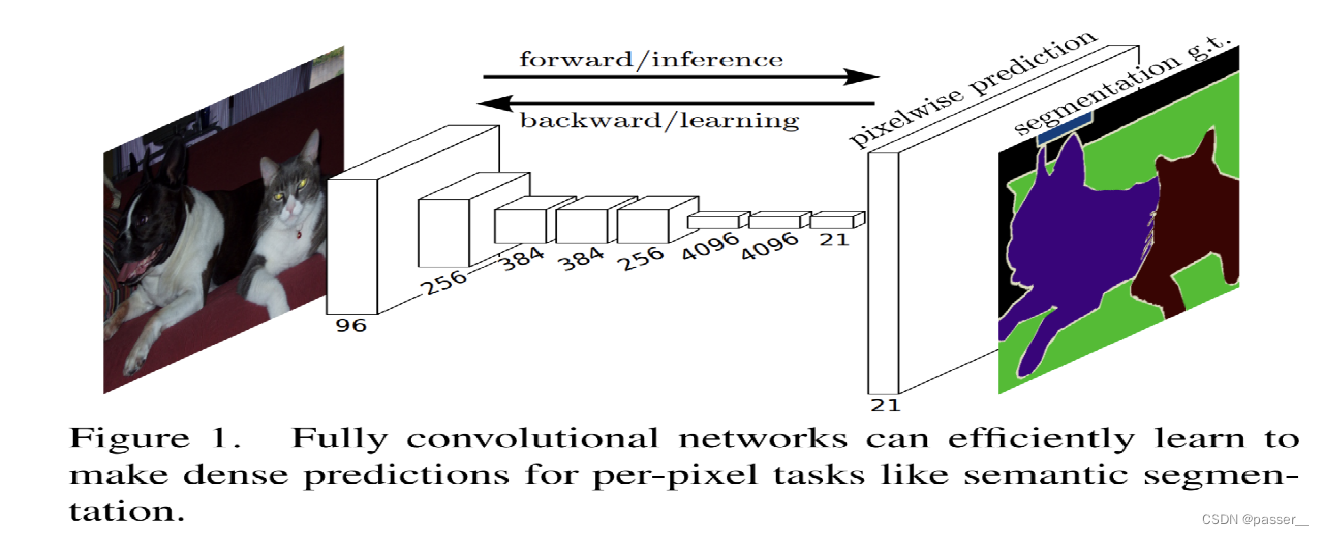
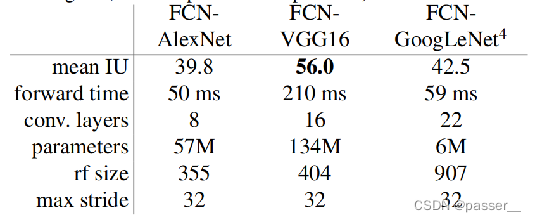
作者对比了VGG16、AlexNet和GoogleNet都将他们的全连接层换成了卷积层,然后进行效果对比发现VGG16得到的效果的是最好的。
FCN的创新点
全连接层替换成卷成层
论文作者认为全连接层让目标的位置信息消失了,只保留了语义信息,因此将全连接操作更换为卷积操作可以同时保留位置信息及语义信息,达到给每个像素分类的目的。
FCN用卷积层替换掉原来的全连接层,不再限制输入的大小,对于上采样过程是采用双线性插值初始化的转置卷积。
CNN和FCN进行对比:
CNN最后使用全连接层,将二维压缩成一维,丢失了空间信息,只能预测出来一张图的概率,而不能对于图中的物体进行具体的预测分割
FCN输出的是热图,是每个像素点对应的相关类型的概率。
双线性差值
推荐参考博客:https://blog.csdn.net/qq_37541097/article/details/112564822
以下是将上述博客做了一个简短的总结。

转置卷积
推荐博客参考:https://blog.csdn.net/tsyccnh/article/details/87357447
暂时留坑
跳跃连接
推荐视频:https://www.bilibili.com/video/BV1J3411C7zd/?spm_id_from=333.999.0.0
论文作者给了这个图可能不太好理解它的直接意思,下边借用B站作者的一些图
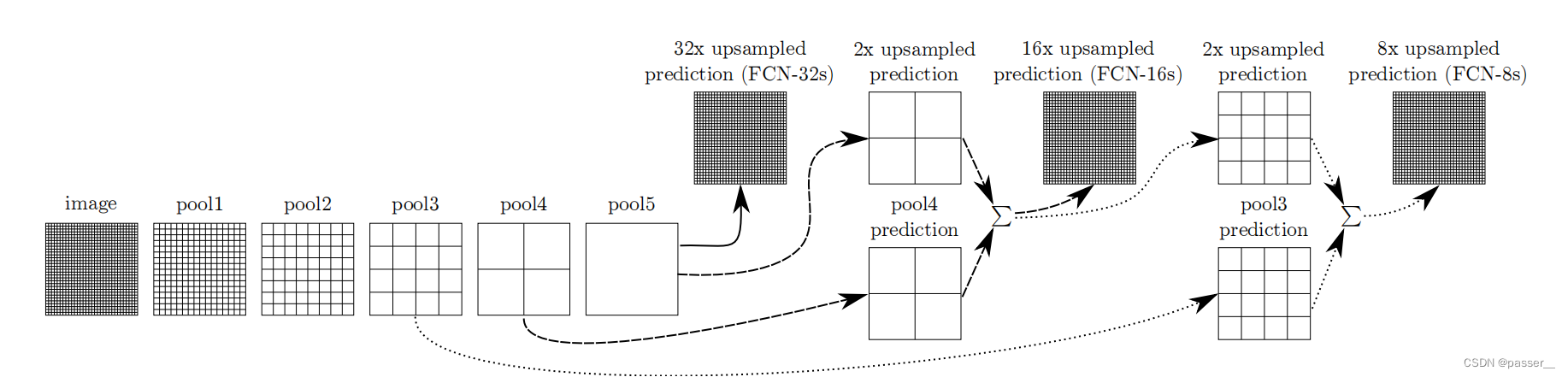
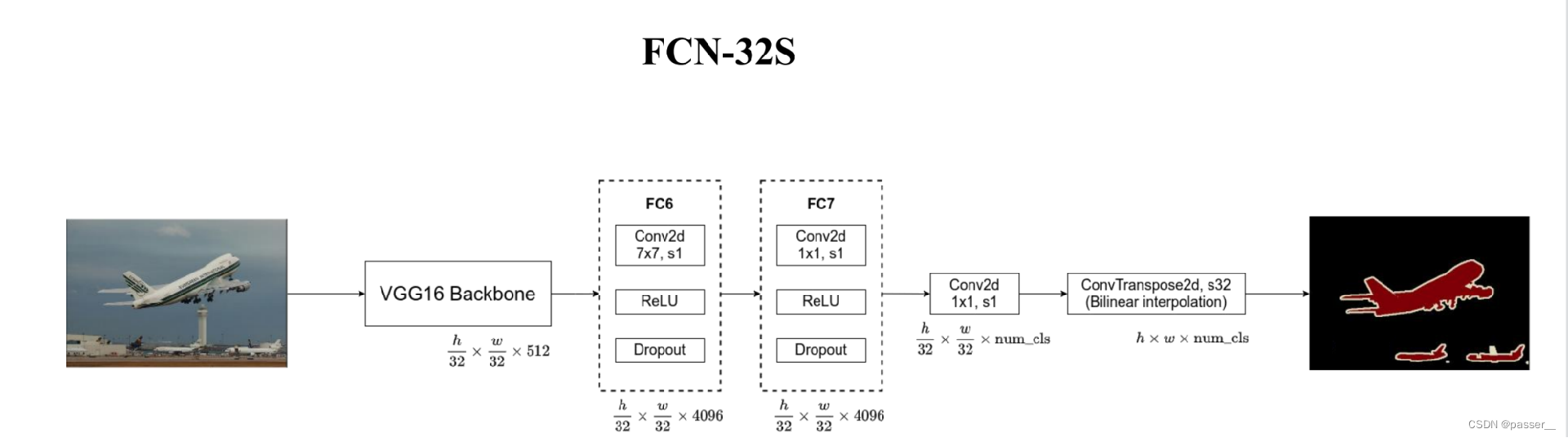
对于FCN-32S就是按照论文卷积池化的操作不断的将图片缩小,最后缩小为原图像的1/32,最后通过转置卷积直接将图像直接扩大为输入图片的尺寸的大小。
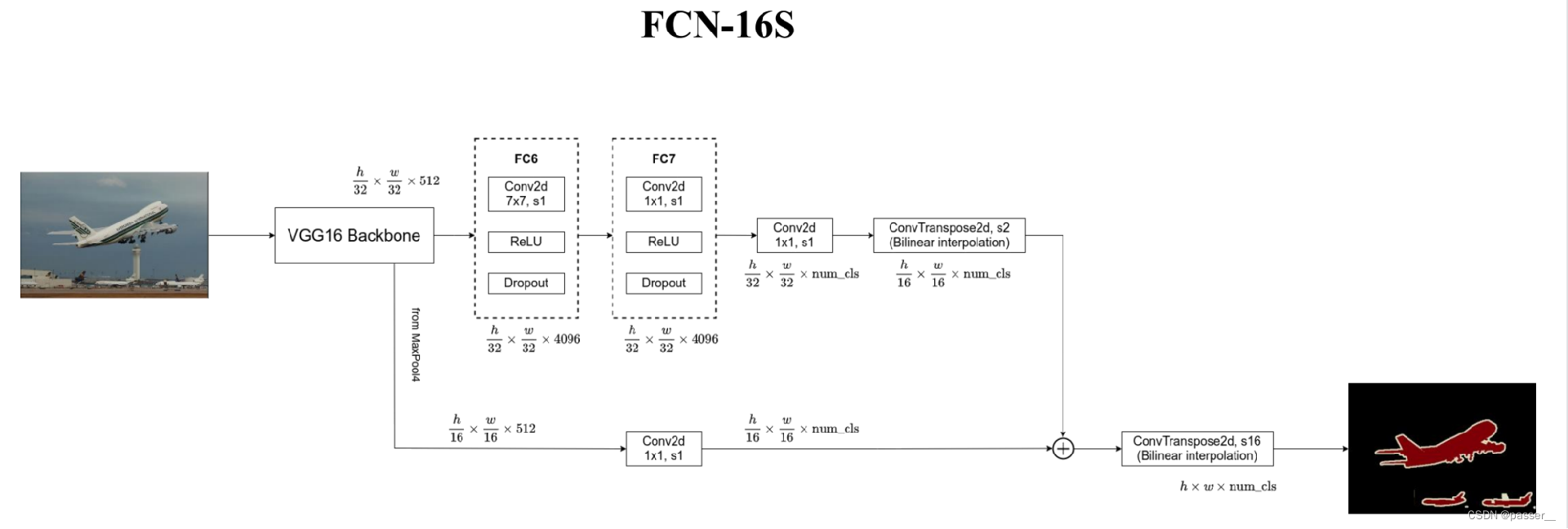

同理可以得到对于其他不同的上采样的情况,作者也尝试将更加前边的网络上采样相加,得到的结果并不理想甚至会下降,而且参数还会增加。
实验结果















 29万+
29万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









